







CVPR Oral | 谷歌&斯坦福(李飞飞组)提出TIRG,用组合的文本和图像来进行图像检索
【写在前面】
在本文中,作者研究图像检索的任务,其中输入查询以图像的形式指定,加上一些描述对输入图像的期望修改的文本。例如,可能会呈现埃菲尔铁塔的图像,并要求系统找到视觉上相似但经过小幅修改的图像,例如在夜间而不是白天拍摄。为了解决这个任务,作者嵌入了查询(参考图像加上修改文本)和目标(图像)。图像文本查询的编码函数学习一种表示,使得与目标图像表示的相似度很高。作者提出了一种通过残差连接来组合图像和文本的新方法,该方法专为此检索任务而设计。作者展示了这在 3 个不同的数据集上优于现有方法,即 Fashion-200k、MIT-States 和基于 CLEVR 创建的新合成数据集。作者还表明,本文的方法可用于使用组合新颖的标签执行图像分类,并且在此任务上优于以前在 MIT-States 上的方法。
1. 论文和代码地址

Composing Text and Image for Image Retrieval - An Empirical Odyssey
代码地址:https://github.com/google/tirg
2. 动机
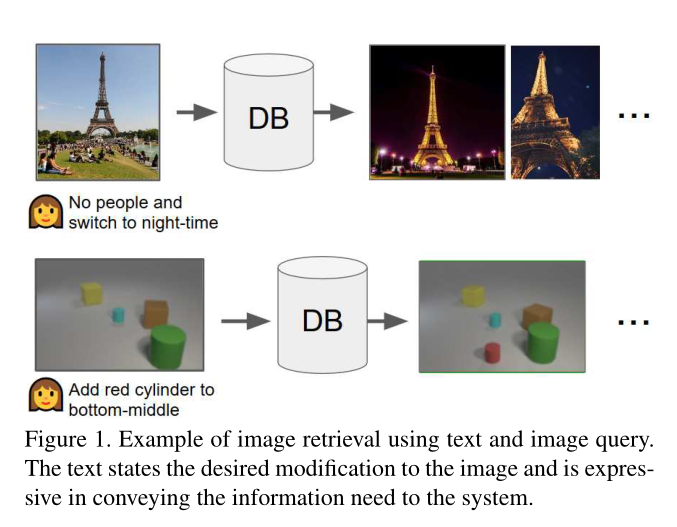
图像检索的一个核心问题是用户心中有一个“概念”,他们想要找到它的图像,但他们需要以某种方式将该概念传达给系统。有几种方法可以将概念表述为搜索查询,例如文本字符串、类似的图像,甚至是草图,或者上述的某种组合。在这项工作中,作者考虑将查询表述为输入图像加上描述对图像的一些期望修改的文本字符串的情况。这代表了会话搜索中的一个典型场景:用户可以使用已经找到的图像作为参考,然后用文本表达差异,目的是检索相关图像。这个问题与基于属性的产品检索密切相关,但不同之处在于文本可以是多词,而不是单个属性。
我们可以使用标准的深度度量学习方法,例如三元组损失来计算搜索查询和候选图像之间的相似度。本文研究的主要问题是当有两种不同的输入方式时,如何表示查询,即输入图像和文本。换句话说,如何为查询学习有意义的跨模态特征组合以找到目标图像。
文本和图像之间的特征组合已经在视觉和语言领域得到了广泛的研究,特别是在视觉问答(VQA)中。在对图像(例如,使用卷积神经网络或 CNN)和文本(例如,使用递归神经网络或 RNN)进行编码后,已经使用了各种特征组合方法。这些范围从简单的技术(例如,连接或浅层前馈网络)到高级机制(例如,关系或参数散列)。这些方法也已成功地应用于查询分类、组合学习等相关问题。
目前,尚未研究使用哪种图像/文本特征组合进行图像检索的问题。在本文中,作者比较了几种现有的方法,并提出了一种新的方法。**新方法背后的关键思想是文本应该修改查询图像的特征,但作者希望得到的特征向量仍然“存在”与目标图像相同的空间。**通过门控残差连接让文本修改图像特征来实现这一目标,称之为“文本图像残留门控”(或简称 TIRG)。
作者在三个基准上对这些方法进行了实验上比较:Fashion-200k 数据集、MIT-States 数据集 以及用于图像检索的新合成数据集,作者称之为“CSS”(颜色、形状和大小),基于关于 CLEVR 框架。提出的特征组合方法在所有三种情况下都优于现有方法。
总而言之,本文的贡献是三方面的:
-
作者系统地研究了图像检索的特征组合,并提出了一种新方法。
-
作者创建了一个新的数据集 CSS,它支持使用文本和图像查询进行图像检索的受控实验。
-
作者在两个公共基准 Fashion-200K 和 MIT-States 上改进了图像检索和合成图像分类的先前最先进的结果。
3. 方法
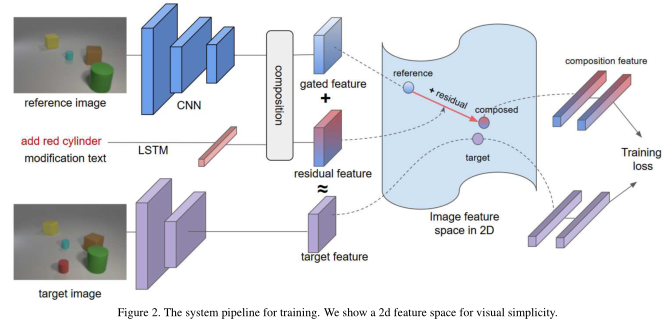
本文的目标是为文本+图像查询和目标图像学习一个嵌入空间,以便匹配(查询、图像)对接近。
首先,作者使用 ResNet-17 CNN 对查询(或参考)图像 x 进行编码以获得 2d 空间特征向量 f img ( x ) = ϕ x ∈ R W × H × C f_{\text {img }}(x)= \phi_{x} \in \mathbb{R}^{W \times H \times C} fimg (x)=ϕx∈RW×H×C,其中 W 是宽度,H 是高度,并且C = 512 是特征通道的数量。作者使用标准 LSTM 对查询文本 t 进行编码。将 f t e x t ( t ) = ϕ t ∈ R d f_{\mathrm{text}}(t)=\phi_{t} \in \mathbb{R}^{d} ftext(t)=ϕt∈Rd定义为大小 d 为 512 的最后时间步的隐藏状态。作者希望使文本编码器尽可能简单。其他编码器对文本进行编码,例如bi-LSTM 或 LSTM 注意力绝对是可行的,但超出了论文的范围。最后,作者结合这两个特征来计算 ϕ x t = f combine ( ϕ x , ϕ t ) \phi_{x t}=f_{\text {combine }}\left(\phi_{x}, \phi_{t}\right) ϕxt=fcombine (ϕx,ϕt)。
3.1. Summary of existing combination methods
在本文中,作者研究了以下特征组合方法。为了公平比较,作者使用相同的pipeline训练所有方法,包括本文的方法,唯一的区别在于组合模块。
-
仅图像:设置 ϕ x t = ϕ x \phi_{x t}=\phi_{x} ϕxt=ϕx。
-
纯文本:设置 ϕ x t = ϕ t \phi_{x t}=\phi_{t} ϕxt=ϕt。
-
连接计算 ϕ x t = f M L P ( [ ϕ x , ϕ t ] ) \phi_{x t}=f_{\mathrm{MLP}}\left(\left[\phi_{x}, \phi_{t}\right]\right) ϕxt=fMLP([ϕx,ϕt])。这种简单的方法已在各种应用中证明是有效的。特别是,使用带有 RELU 的两层 MLP,batch-norm 和 0.1 的 dropout 率。
-
Show and Tell。在这种方法中,我们训练一个 LSTM 来编码图像和文本,首先输入图像特征,然后是文本中的单词;该 LSTM 的最终状态用作表示 ϕ x t \phi_{x t} ϕxt。
-
Attribute as Operator 将每个文本嵌入为转换矩阵 T t T_{t} Tt,并将 T t T_{t} Tt应用于 ϕ x \phi_{x} ϕx以创建 ϕ x t \phi_{xt} ϕxt。
-
Parameter hashing是一种用于 VQA 任务的技术。在本文的实现中,编码的文本特征 φt 被散列成一个变换矩阵 T t T_{t} Tt,可以应用于图像特征;它用于替换图像 CNN 中的 fc 层,该层现在输出一个表示 ϕ x t \phi_{xt} ϕxt,该表示同时考虑了图像和文本特征。
-
Relationship是一种在 VQA 任务中捕获关系推理的方法。它首先使用 CNN 从图像中提取 2D 特征图,然后创建一组关系特征,每个关系特征是 2D 特征图中的文本特征 ϕ t \phi_{t} ϕt和 2 个局部特征的串联;这组特征通过 MLP 传递,结果相加得到一个特征。应用另一个 MLP 以获得输出 ϕ x t \phi_{xt} ϕxt。
-
多模态残差网络 (MRN) 是一种 VQA 方法,它使用元素乘法来进行联合残差映射。这里从 ϕ x t 0 = ϕ t \phi_{x t}^{0}=\phi_{t} ϕxt0=ϕt开始,其每个块层定义为 ϕ x t i = ϕ x t i − 1 + f c ( tanh ( ϕ x t i − 1 ) ) ⋅ f c ( tanh ( f c ( tanh ( ϕ x ) ) ) ) \phi_{x t}^{i}=\phi_{x t}^{i-1}+f c\left(\tanh \left(\phi_{x t}^{i-1}\right)\right) \cdot f c\left(\tanh \left(f c\left(\tanh \left(\phi_{x}\right)\right)\right)\right) ϕxti=ϕxti−1+fc(tanh(ϕxti−1))⋅fc(tanh(fc(tanh(ϕx))))。最后一个特征进行线性变换,得到图文合成输出。
-
FiLM是另一种 VQA 方法,其中文本特征也被注入到图像 CNN 中。更详细地说,文本特征 ϕ t \phi_{t} ϕt用于预测调制特征: γ i , β i ∈ R C \gamma^{i}, \beta^{i} \in \mathbb{R}^{C} γi,βi∈RC,其中 i 索引层,C 是特征或特征图的数量。然后它执行图像特征的逐特征仿射变换, ϕ x t i = γ i ⋅ ϕ x i + β i \phi_{x t}^{i}=\gamma^{i} \cdot \phi_{x}^{i}+\beta^{i} ϕxti=γi⋅ϕxi+βi。FiLM 层仅处理简单的操作,例如缩放、否定或阈值化特征。为了执行复杂的操作,它必须用于 CNN 的每一层。相比之下,作者只修改了图像特征图的一层,使用门控残差连接来做到这一点。
3.2. Proposed approach: TIRG
作者提出使用以下方法组合图像和文本特征,称之为文本图像残差门控(或简称 TIRG):
ϕ x t r g = w g f gate ( ϕ x , ϕ t ) + w r f res ( ϕ x , ϕ t ) \phi_{x t}^{r g}=w_{g} f_{\text {gate }}\left(\phi_{x}, \phi_{t}\right)+w_{r} f_{\text {res }}\left(\phi_{x}, \phi_{t}\right) ϕxtrg=wgfgate (ϕx,ϕt)+wrfres (ϕx,ϕt)
其中 f gate , f res ∈ R W × H × C f_{\text {gate }}, f_{\text {res }} \in \mathbb{R}^{W \times H \times C} fgate ,fres ∈RW×H×C是门控和残差特征。 w g , w r w_{g}, w_{r} wg,wr是可学习的权重来平衡它们。门控连接由下式计算:
f gate ( ϕ x , ϕ t ) = σ ( W g 2 ∗ RELU ( W g 1 ∗ [ ϕ x , ϕ t ] ) ⊙ ϕ x f_{\text {gate }}\left(\phi_{x}, \phi_{t}\right)=\sigma\left(W_{g 2} * \operatorname{RELU}\left(W_{g 1} *\left[\phi_{x}, \phi_{t}\right]\right) \odot \phi_{x}\right. fgate (ϕx,ϕt)=σ(Wg2∗RELU(Wg1∗[ϕx,ϕt])⊙ϕx
其中 σ 是 sigmoid 函数,⊙ 是元素乘积,∗ 表示带有BatchNorm的 2d 卷积, W g 1 W_{g 1} Wg1和 W g 2 W_{g 2} Wg2是 3x3 卷积滤波器。作者沿高度和宽度维度广播 ϕ t \phi_{t} ϕt,以便其形状与图像特征图 ϕ x \phi_{x} ϕx兼容。残差连接由下式计算:
f res ( ϕ x , ϕ t ) = W r 2 ∗ RELU ( W r 1 ∗ ( [ ϕ x , ϕ t ] ) ) f_{\text {res }}\left(\phi_{x}, \phi_{t}\right)=W_{r 2} * \operatorname{RELU}\left(W_{r 1} *\left(\left[\phi_{x}, \phi_{t}\right]\right)\right) fres (ϕx,ϕt)=Wr2∗RELU(Wr1∗([ϕx,ϕt]))
直觉是想要“修改”查询图像特征,而不是传统的“特征融合”,即从现有特征中创建新特征。 ResBlock 设计促进了这一点:门控将输入图像特征建立为对输出合成特征的参考,就好像它们在同一个有意义的图像特征空间中一样;那么添加的残差连接代表了这个特征空间中的修改。
在训练时,它基本上从一个工作图像到图像检索系统开始,然后逐渐学习有意义的修改。不同的是,其他方法将从随机检索结果开始。
上图显示了应用于 CNN 卷积层的修改。但是,作者也可以对全连接层(其中 W = H = 1)进行修改,以改变表示的非空间属性。在本文的实验中,作者修改了 Fashion200k 和 MIT-States 的最后一个FC 层,因为修改更加全局和抽象。对于 CSS,作者在池化之前修改最后一个 2D 特征图(最后一个 conv 层)以捕获图像内部的低级和空间变化。选择要修改的层是该方法的超参数,可以根据验证集进行选择。
3.3. Deep Metric Learning
本文的训练目标是拉近“修改”图像和目标图像的特征,同时拉开不相似图像的特征。作者为此任务使用分类损失。更准确地说,假设有 B 个查询的训练mini-batch,其中 ψ i = f combine ( x i q u e r y , t i ) \psi_{i}=f_{\text {combine }}\left(x_{i}^{q u e r y}, t_{i}\right) ψi=fcombine (xiquery,ti)是图像文本查询的最终修改表示(来自最后一层),并且 ϕ i + = f i m g ( x i target ) \phi_{i}^{+}=f_{\mathrm{img}}\left(x_{i}^{\text {target }}\right) ϕi+=fimg(xitarget )是该查询的目标图像的表示。作者创建了一个集合 N i \mathcal{N}_{i} Ni,由一个正例 ϕ i + \phi_{i}^{+} ϕi+和 K-1 个负例 ϕ 1 − , … , ϕ K − 1 − \phi_{1}^{-}, \ldots, \phi_{K-1}^{-} ϕ1−,…,ϕK−1−组成。重复 M 次,记为 N i m \mathcal{N}_{i}^{m} Nim ,以评估每个可能的集合。然后使用以下 softmax 交叉熵损失:
L = − 1 M B ∑ i = 1 B ∑ m = 1 M log { exp { κ ( ψ i , ϕ i + ) } ∑ ϕ j ∈ N i m exp { κ ( ψ i , ϕ j ) } } L=\frac{-1}{M B} \sum_{i=1}^{B} \sum_{m=1}^{M} \log \left\{\frac{\exp \left\{\kappa\left(\psi_{i}, \phi_{i}^{+}\right)\right\}}{\sum_{\phi_{j} \in \mathcal{N}_{i}^{m}} \exp \left\{\kappa\left(\psi_{i}, \phi_{j}\right)\right\}}\right\} L=MB−1i=1∑Bm=1∑Mlog{∑ϕj∈Nimexp{κ(ψi,ϕj)}exp{κ(ψi,ϕi+)}}
其中 κ 是一个相似核,在本文的实验中被实现为点积或负 l2 距离。当使用 K = 2 的最小值时,方程 可以很容易地改写为:
L = 1 M B ∑ i = 1 B ∑ m = 1 M log { 1 + exp { κ ( ψ i , ϕ i , m − ) − κ ( ψ i , ϕ i + ) } } L=\frac{1}{M B} \sum_{i=1}^{B} \sum_{m=1}^{M} \log \left\{1+\exp \left\{\kappa\left(\psi_{i}, \phi_{i, m}^{-}\right)-\kappa\left(\psi_{i}, \phi_{i}^{+}\right)\right\}\right\} L=MB1i=1∑Bm=1∑Mlog{1+exp{κ(ψi,ϕi,m−)−κ(ψi,ϕi+)}}
因为每个集合 N i m \mathcal{N}_{i}^{m} Nim都包含一个负例。这相当于 使用的基于soft triplet的损失。当使用 K = 2 时,作者选择 M = B - 1,因此将每个示例 i 与所有可能的负数配对。
如果使用较大的 K,则每个示例都会与一组其他负例进行对比;有了最大值 K = B,那么 M = 1,所以函数简化为:
L = 1 B ∑ i = 1 B − log { exp { κ ( ψ i , ϕ i + ) } ∑ j = 1 B exp { κ ( ψ i , ϕ j + ) } } L=\frac{1}{B} \sum_{i=1}^{B}-\log \left\{\frac{\exp \left\{\kappa\left(\psi_{i}, \phi_{i}^{+}\right)\right\}}{\sum_{j=1}^{B} \exp \left\{\kappa\left(\psi_{i}, \phi_{j}^{+}\right)\right\}}\right\} L=B1i=1∑B−log{∑j=1Bexp{κ(ψi,ϕj+)}exp{κ(ψi,ϕi+)}}
根据本文的实验,这种情况更具辨别力,拟合速度更快,但更容易受到过度拟合的影响。因此,为 Fashion200k 设置 K = B,因为它更难以收敛,而对于其他数据集,设置 K = 2。
4.实验
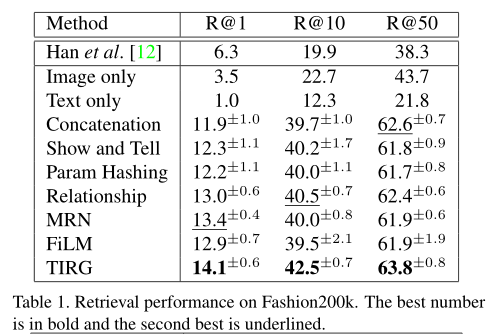
从上表可以看出,即使使用不同类型的组合机制,本文的pipeline也优于他们的方法。

上图展示了可视化的检索结果。

上图展示了MIT-States上的可视化检索结果。
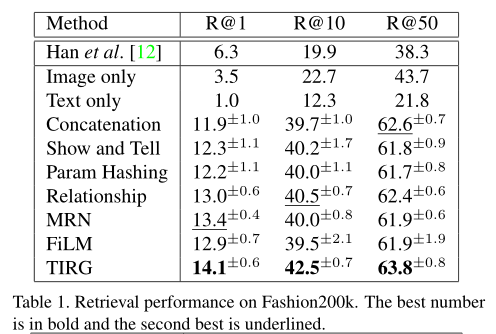
上表展示了MIT-States上的定量结果。
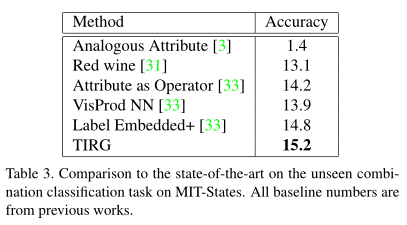
上图展示了与 MIT-States 上未见组合分类任务的最新技术进行比较。

作者使用 CLEVR 工具包创建了一个新数据集,用于在 3×3 网格场景中生成合成图像。我们渲染具有不同颜色、形状和大小 (CSS) 占用的对象。每个图像都有一个简单的 2D blob 版本和一个 3D 渲染版本。示例如上图所示。
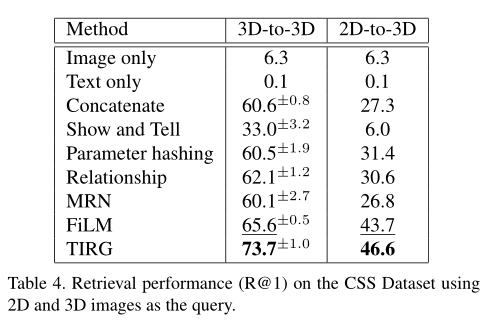
上表总结了 R@1 在 CSS 数据集上的检索性能。
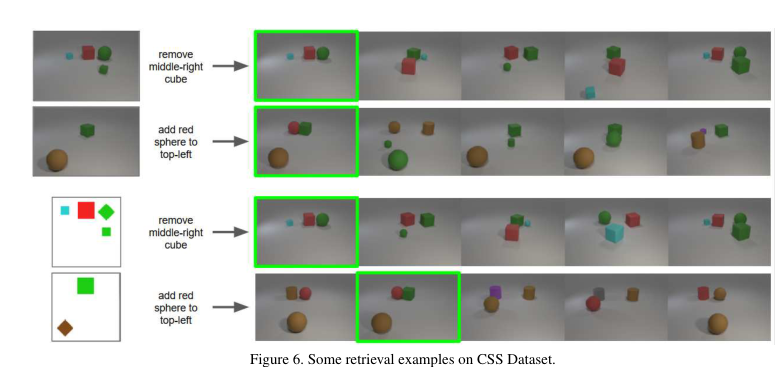
上图展示了CSS数据集上的定性可视化结果。

上图显示了三种方法的合成特征的重建图像。
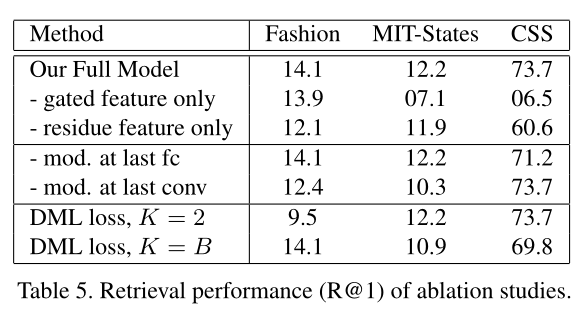
上图展示了本文方法消融实验的结果。
5. 总结
在这项工作中,作者在图像检索的背景下探索了图像和文本的组合。作者通过实验评估了几种现有方法,并提出了一种新方法,该方法在三个基准数据集上提供了改进的性能。
【技术交流】
已建立深度学习公众号——FightingCV,关注于最新论文解读、基础知识巩固、学术科研交流,欢迎大家关注!!!
推荐加入FightingCV交流群,每日会发送论文解析、算法和代码的干货分享,进行学术交流,加群请添加小助手wx:FightngCV666,备注:地区-学校(公司)-名称
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向科研小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

【赠书活动】
为感谢各位老粉和新粉的支持,FightingCV公众号将在9月10日包邮送出4本**《深度学习与目标检测:工具、原理与算法》来帮助大家学习,赠书对象为当日阅读榜和分享榜前两名。想要参与赠书活动的朋友,请添加小助手微信FightngCV666**(备注“城市-方向-ID”),方便联系获得邮寄地址。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









