







 本文介绍了一个使用Hadoop组件(包括Python、Flume、MapReduce、Sqoop和Hive)处理巨型日志的系统。通过分析日志格式,保留关键字段,并展示统计结果,如主要页面访问量、爬虫记录和访问时间段分布。
本文介绍了一个使用Hadoop组件(包括Python、Flume、MapReduce、Sqoop和Hive)处理巨型日志的系统。通过分析日志格式,保留关键字段,并展示统计结果,如主要页面访问量、爬虫记录和访问时间段分布。
转载请注明地址
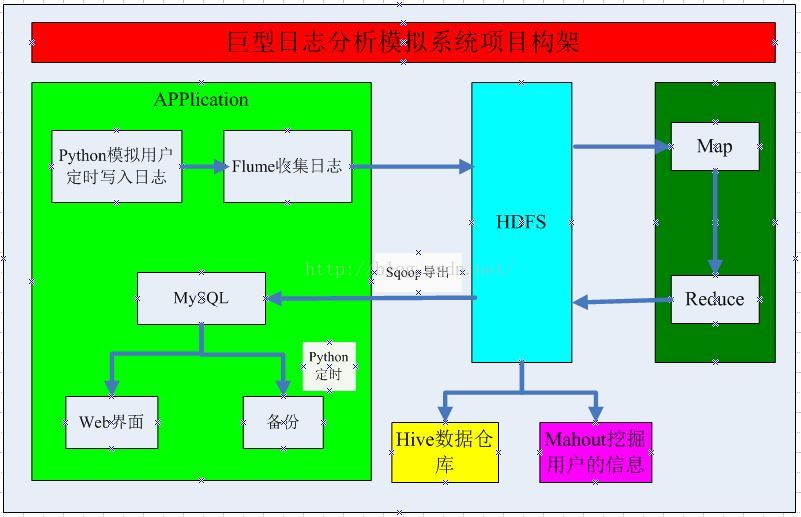
本次模拟系统,是利用Hadoop等组件来模拟巨型日志的处理系统,包括Python定时、Flume收集日志、MR处理日志、Sqoop导出数据、Hive的简单统计等,具体的架构如下:
一、项目架构
二、数据源下载
数据源我也是从csdn上下载的日志数据,想要的可以留下邮箱!
【注意:如何搞定时间不同,复制的文件也不同】
from datetime import date, time, datetime, timedelta
import os
def work(i):
if i>13:
data_path='/home/hadoop/LogModel/data/ex0412'+str(i)+'.log'
os.system("sudo cp "+data_path2+" /home/hadoop/LogModel/source/")
if i<10:
data_path='/home/hadoop/LogModel/data/ex05010'+str(i)+'.log'
os.system("sudo cp "+data_path2+" /home/hadoop/LogModel/source/")
if i>9 or i<14:
data_path1='/home/hadoop/LogModel/data/ex0412'+str(i)+'.log'
os.system("sudo cp "+data_path1+" /home/hadoop/LogModel/source/")
data_path2='/home/hadoop/LogModel/data/ex0501'+str(i)+'.log'
os.system("sudo cp "+data_path2+" /home/hadoop/LogModel/source/")
def runTask(func, day=0, hour=0, min=0, second=0):
# Init time
now = datetime.now()
strnow = now.strftime('%Y-%m-%d %H:%M:%S')
print("now:",strnow)
# First next run time
period = timedelta(days=day, hours=hour, minutes=min, seconds=second)
next_time = now + period
strnext_time = next_time.strftime('%Y-%m-%d %H:%M:%S')
print("next run:",strnext_time)
i=12
while(i<31):
# Get system current time
iter_now = datetime.now()
iter_now_time = iter_now.strftime('%Y-%m-%d %H:%M:%S')
if str(iter_now_time) == str(strnext_time):
i=i+1
# Get every start work time
print("start work: %s" % iter_now_time)
# Call task func
func(i)
print("task done.")
# Get next iteration time
iter_time = iter_now + period
strnext_time = iter_time.strftime('%Y-%m-%d %H:%M:%S')
print("next_iter: %s" % strnext_time)
# Continue next iteration
continuerunTask(work, min=0.5)
1、日志分布情况:
机子slave1上有个日志文件:/home/hadoop/LogModel/source1
机子slave2上有个日志文件:/home/hadoop/LogModel/source2
2、日志汇总:
机子hadoop上在HDFS中有个日志汇总文件:/LogModel/source
3、具体实现:
对于slave1主机:
#agent1
a1.sources=sc1
a1.sinks=sk1
a1.channels=ch1
#source1
a1.sources.sc1.type=spooldir
a1.sources.sc1.spoolDir=/home/hadoop/LogModel/source1
a1.sources.sc1.channels=ch1
a1.sources.sc1.fileHeader = false
#channel1
a1.channels.ch1.type=file
#a1.channels.ch1.checkpointDir=/home/hadoop/flume/tmp
a1.channels.ch1.dataDirs=/home/hadoop/flume/data_tmp
#sink1
a1.sinks.sk1.type=avro
a1.sinks.sk1.hostname=hadoop
a1.sinks.sk1.port=23004
a1.sinks.sk1.channel=ch1:#agent2
a2.sources=sc2
a2.sinks=sk2
a2.channels=ch2
#source2
a2.sources.sc2.type=spooldir
a2.sources.sc2.spoolDir=/home/hadoop/LogModel/source2
a2.sources.sc2.channels=ch2
a2.sources.sc2.fileHeader = false
#channel2
a2.channels.ch2.type=file
#a2.channels.ch2.checkpointDir=/home/hadoop/flume/tmp
a2.channels.ch2.dataDirs=/home/hadoop/flume/data_tmp
#sink2
a2.sinks.sk2.type=avro
a2.sinks.sk2.hostname=hadoop
a2.sinks.sk2.port=41414
a2.sinks.sk2.channel=ch2a3.sources=sc1 sc2
a3.channels=ch1 ch2
a3.sinks=sk1 sk2
a3.sources.sc1.type = avro
a3.sources.sc1.bind=0.0.0.0
a3.sources.sc1.port=23004
a3.sources.sc1.channels=ch1
a3.channels.ch1.type = file
a3.channels.ch1.checkpointDir=/home/hadoop/flume/checkpoint
a3.channels.ch1.dataDirs=/home/hadoop/flume/data
a3.sinks.sk1.type=hdfs
a3.sinks.sk1.channel=ch1
a3.sinks.sk1.hdfs.path=hdfs://hadoop:9000/LogModel/source
a3.sinks.sk1.hdfs.filePrefix=ent-
a3.sinks.sk2.hdfs.fileType=DataStream
a3.sinks.sk2.hdfs.writeFormat=TEXT
a3.sinks.sk1.hdfs.round=true
a3.sinks.sk1.hdfs.roundValue=5
a3.sinks.sk1.hdfs.roundUnit=minute
a3.sinks.sk1.hdfs.rollInterval=30
a3.sinks.sk1.hdfs.rollSize=0
a3.sinks.sk1.hdfs.rollCount=0
a3.sources.sc2.type = avro
a3.sources.sc2.bind=0.0.0.0
a3.sources.sc2.port=41414
a3.sources.sc2.channels=ch2
a3.channels.ch2.type = file
a3.channels.ch2.checkpointDir=/home/hadoop/flume/checkpoint2
a3.channels.ch2.dataDirs=/home/hadoop/flume/data2
a3.sinks.sk2.type=hdfs
a3.sinks.sk2.channel=ch2
a3.sinks.sk2.hdfs.path=hdfs://hadoop:9000/LogModel/source
a3.sinks.sk2.hdfs.fileType=DataStream
a3.sinks.sk2.hdfs.writeFormat=TEXT
a3.sinks.sk2.hdfs.filePrefix=ent-
a3.sinks.sk2.hdfs.round=true
a3.sinks.sk2.hdfs.roundValue=5
a3.sinks.sk2.hdfs.roundUnit=minute
a3.sinks.sk2.hdfs.rollInterval=30
a3.sinks.sk2.hdfs.rollSize=0
a3.sinks.sk2.hdfs.roll 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









