




说到负载均衡的hash算法,自然会联想起如下这样的算法
hash(object)%nodeTotal而在集群中,机器的动态上下线是常见的情况,如果集群是无状态的,那么上述的算法没有问题.但是如果是缓存之类的集群,节点的动态上下线会导致几乎所有的key的重新映射,这样造成的影响是数据错乱,相同备份的数据同时存在于集群中的多个节点,造成内存空间的浪费
为了解决上述的问题,一致性哈希算法就被提出了
一致性哈希算法的目标是对于K个请求,节点的上下线只会引起K/nodeTotal的key重新映射,而在节点稳定的时候,同一个key的每次请求映射都是一样的
一致性哈希算法实现原理如下
首先将node节点映射到一个圆上(圆的大小是2^32-1),然后将请求object映射到圆上,最后顺时针转动请求,转动的目的是让请求映射到node节点上
原理图如下
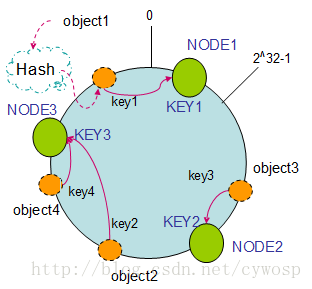
上述的算法在node2被删除的情况下回发生什么呢?
它会造成object3的请求映射到node3节点上,并且对于其他的请求没有发生变化,如图所示
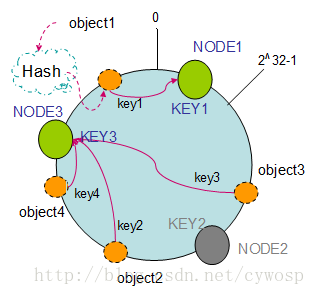
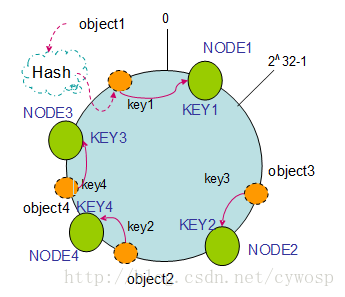
如果添加了node4节点请求又会如何发生变化呢?
变化是object2倍映射到node4上,对于其他的请求没有变化
上述的一致性hash算法满足了单调性(单调性是指对于k个请求,n个node,当一个node上线或者下线时只会引起k/n个请求映射发生变化),上述算法看似完美,但还存在一个问题,比如
对于节点n1,n2.我们有request1,request2,request3,request4四个请求,而四个请求同时落在n2节点上,
为了更好的实现负载均衡,我们需要引入虚拟节点的概念,就是将一个节点虚拟化为多个节点将其中的请求落在N1上,入下图所示
下面是一致性哈希算法的java实现,这里的代码引自xxl-job,jobId就是相当于请求id
首先计算hash,hash在该算法中地位非常重要,它直接影响了node是否能均匀的落在圆上
private static long hash(String key) {
// md5 byte
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
md5.reset();
byte[] keyBytes = null;
try {
keyBytes = key.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Unknown string :" + key, e);
}
//System.out.println(keyBytes.length);
md5.update(keyBytes);
byte[] digest = md5.digest();
//System.out.println(digest.length);
//
long hashCode = ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
long truncateHashCode = hashCode & 0xffffffffL;
return truncateHashCode;
}下面是真正的请求路由,这里的jobId就是相当于requestId
public String route(int jobId, ArrayList<String> addressList) {
//首先是将node定位到圆上,我们以 hash - address方式定位
//因为后面需要获取离jobId最近node所以将数据放入到TreeMap中
TreeMap<Long, String> addressRing = new TreeMap<Long, String>();
for (String address : addressList) {
//将每个node虚拟化为5个节点
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
long addressHash = hash("SHARD-" + address + "-NODE-" + i);
addressRing.put(addressHash, address);
}
}
long jobHash = hash(String.valueOf(jobId));
//这里是顺时针转动jobHash寻找node的策略,其实就是寻找node哈希值大于等于jobId哈希值的最近一个node
SortedMap<Long, String> lastRing = addressRing.tailMap(jobHash);
if (!lastRing.isEmpty()) {
return lastRing.get(lastRing.firstKey());
}
//如果请求落在最大一组hash上,那么就返回第一个node
return addressRing.firstEntry().getValue();
}
















 3076
3076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









