







在实际的项目中,服务高可用非常重要,如,当Redis作为缓存服务使用时, 缓解数据库的压力,提高数据的访问速度,提高网站的性能 ,但如果使用Redis 是单机模式运行 ,只要一个服务器宕机就不可以提供服务,这样会可能造成服务效率低下,甚至出现其相对应的服务应用不可用。
因此为了实现高可用,Redis 提供了哪些高可用方案?
- Redis主从复制
- Redis持久化
- 哨兵集群
- ...
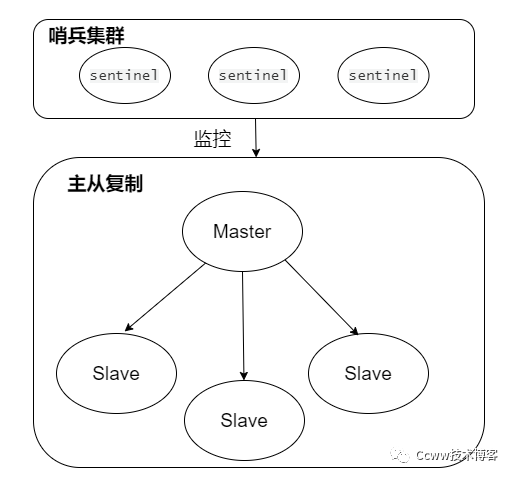
Redis基于一个Master主节点多Slave从节点的模式和Redis持久化机制,将一份数据保持在多个实例中实现增加副本冗余量,又使用哨兵机制实现主备切换, 在master故障时,自动检测,将某个slave切换为master,最终实现Redis高可用 。
Redis主从复制
Redis主从复制,主从库模式一个Master主节点多Slave从节点的模式,将一份数据保存在多Slave个实例中,增加副本冗余量,当某些出现宕机后,Redis服务还可以使用。

但是这会存在数据不一致问题,那redis的副本集是如何数据一致性?
Redis为了保证数据副本的一致,主从库之间采用读写分离的方式:
- 读操作:主库、从库都可以执行处理;
- 写操作:先在主库执行,再由主库将写操作同步给从库。
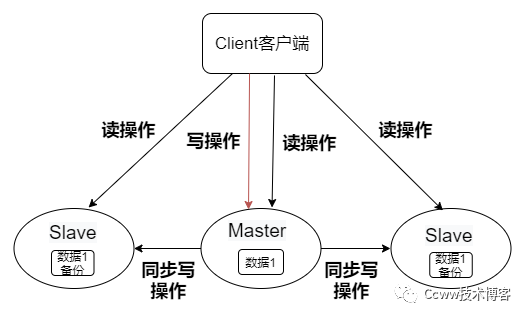
使用读写分离方式的好处,可以避免当主从库都可以处理写操作时,主从库处理写操作加锁等一系列巨额的开销。
采用读写分离方式,写操作只会在主库中进行后同步到从库中,那主从库是如何同步数据的呢?
主从库是同步数据方式有两种:
- 全量同步:通常是主从服务器刚刚连接的时候,会先进行全量同步
- 增量同步 :一般在全同步结束后,进行增量同步,比如主从库间网络断开后,再进行数据同步。
全量同步
主从库间第一次全量同步,具体分成三个阶段:
- 当一个从库启动时,从库给主库发送 psync 命令进行数据同步(psync 命令包含:主库的 runID 和复制进度 offset 两个参数),
- 当主库接收到psync 命令后将会保存RDB 文件并发送给从库&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









