







 本文介绍了在快速迭代的互联网背景下,如何进行系统接口迁移以确保系统稳定性。提出了可灰度、可回滚的接口迁移方案,包括单条数据查询、多条数据查询、数据更新和数据插入的处理逻辑,并通过代理分发和切面拦截实现接口的平稳切换。在实践中,通过门店id的灰度列表进行粒度化的控制,确保系统升级的安全性。
本文介绍了在快速迭代的互联网背景下,如何进行系统接口迁移以确保系统稳定性。提出了可灰度、可回滚的接口迁移方案,包括单条数据查询、多条数据查询、数据更新和数据插入的处理逻辑,并通过代理分发和切面拦截实现接口的平稳切换。在实践中,通过门店id的灰度列表进行粒度化的控制,确保系统升级的安全性。
在快速迭代的互联网背景下,系统为了实现快速上线,常常会选择最快的开发模式,例如我们常见的mvp版本迭代。大部分的业务系统对于未来业务的发展是不确定的,因此随着时间的推移,往往会遇到各种各样的瓶颈,例如系统性能、无法适配业务逻辑等问题,这时可能就涉及到系统架构的升级。系统升级往往包含最基础的两个部分:接口迁移重构和数据迁移重构,在系统架构升级的过程中,最重要的是需要保证系统稳定性,即用户不感知。因此文本的目的是提供一种可灰度、回滚的设计思路,实现稳定的架构升级。
场景
在我们系统迭代过程中,往往涉及到重构、数据源切换、接口迁移等场景,为了保障系统平稳上线,因此在接口迁移过程中应该保证可回滚、可灰度。接口迁移可能也涉及到数据迁移,两者的先后顺序应该不影响到系统的稳定性。总结一下,接口迁移的目标:
- 可灰度,即使用新老接口是能够控制的。
- 可回滚,如使用新接口异常,能够快速回滚到老接口。
- 不入侵业务逻辑,不改动原来的业务逻辑代码,等迁移完毕后再整体下线,防止直接侵入修改造成不可逆的影响。
- 老接口在系统平稳运行后收口,即对老的数据源访问、老的接口能够平稳下线
迁移方案
本文主要为 接口迁移和数据迁移 提供了一种思路,在第3节里会有实践的核心代码实现。(代码只是提供思路,并不是能够直接运行的代码)
1. 总体迁移方案
下图表示了接口迁移的思路,参考了cglib的jdk的代理方式。假设你有一个待迁移接口类(目标类),那么你需要重新写一个代理类作为迁移后的接口。目标类和代理类的选择通过开关去控制,开关涉及到两个层面:
- 总开关:用于控制是否全量切换新接口,当接口迁移稳定上线 且 数据迁移完毕(如有)
- 灰度开关:可以设置一个灰度开关列表,用于控制你的那些接口/数据需要走代理接口
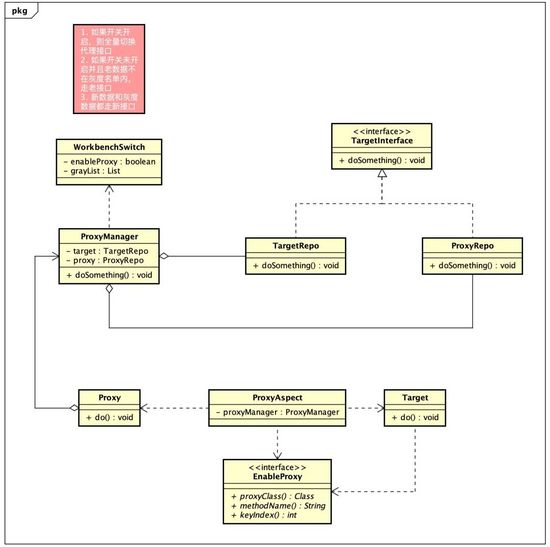
针对不同的接口逻辑,代理接口实现逻辑会有差异,具体场景如下文所述。
2. 单条数据查询
针对单条数据,可以通过数据源来判断来源。基于可灰度和回滚的原则,目标类和代理类的路由规则如下:
- 优先判断总开关,如果总控制开关已打开,则说明迁移已完成并且验证校验完毕,此时走代理接口,这样可以实现接口、数据的收口,达到我们的迁移目标。
- 如果数据不存在于老数据表中,那么无论这条数据有没有存在于新表中,我们都可以直接走代理接口,收拢新数据的接口逻辑。
- 如果数据存在于老数据表中,但是不在灰度名单内,此时使用目标类(回滚时可这么操作),走原来的接口方法,即老逻辑,这是不会影响到系统功能。
- 如果数据存在于老数据表中,但是在灰度名单内,说明这条数据已经迁移完成待验证,此时可以使用代理类(灰度时可这么操作)走新的接口逻辑。
3. 多条数据查询
不同于单条数据的查询,我们需要查询中新表、老表中所有符合条件的数据,多条数据查询涉及到数据重复的问题(即数据会同时存在于老表和新表中),因此需要对数据进行去重,然后再合并返回结果。
4. 数据更新
因为在数据迁移后到系统灰度的过程中存在中间时间,所以在数据更新时我们应该通过双写来保持新、老表数据的一致性。同时为了对接口和数据进行收口,我们也要先判断总控开关是否开启,如果总开关已经打开,则数据更新只需要更新新表即可。
5. 数据插入
对数据和接口收口,我们需要对增量数据进行切换,因此直接使用代理类并将数据插入到新表中,控制老表的数据增量,在数据迁移的时候只需要考虑存量数据即可。
实践
例如在零售场景中,每个门店都有唯一的身份标识门店id,那么我们的灰度列表就可以存放门店id列表,按门店维度进行灰度,来粒度化影响范围。
1. 代理分发逻辑
分发逻辑是核心逻辑,数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2091
2091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









