






1.常用API
insert()
lower()
upper()
trim()
reverse()
length(字段名)
concat(字段名,“随便的字符”) 用于字段合并展示
substring(字段名,‘’,‘’)
replace(字段名,‘被替换字符’,‘替换字符’)
curdate() 返回当前时间,不带时间
now() 返回当前时间,带时间
sum(可以是字段,也可以是表达式)
if()
例:
IF(windWarningType = '1',1 ,2) 可用于 select 后,也可用于 where子句里
mysql时间加减
SYSDATE()是指当前时间
DATE_SUB()和DATE_ADD()函数,实现日期增减
DATE_SUB(SYSDATE(),INTERVAL 30 MINUTE) 当前时间减30分钟
DATE_SUB(SYSDATE(),INTERVAL 1 day) 当前时间减1天
DATE_SUB(SYSDATE(),INTERVAL 1 hour) 当前时间减1小时
DATE_SUB(SYSDATE(),INTERVAL 1 second) 当前时间减1秒
DATE_SUB(SYSDATE(),INTERVAL 1 week) 当前时间减1星期
DATE_SUB(SYSDATE(),INTERVAL 1 month) 当前时间减1个月
DATE_SUB(SYSDATE(),INTERVAL 1 quarter) 当前时间减1季度
DATE_SUB(SYSDATE(),INTERVAL 1 year) 当前时间减1年
相对DATE_ADD()是加时间
获取今天凌晨时间
获取今日凌晨时间
UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE))
获取昨日凌晨时间
UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE) - INTERVAL 1 DAY)
获取明日凌晨时间
UNIX_TIMESTAMP(CAST(SYSDATE()AS DATE) + INTERVAL 1 DAY)
获取的是时间戳
时间戳转换成datetime, datetime也就是我们说的日期格式 年-月-日 时-分-秒
FROM_UNIXTIME();
语法:from_unixtime(timestamp,date_format)
timestamp:为10位时间戳
date_format:不填写的话,默认为 "%Y-%m-%d %H:%i:%s"格式
datetime转时间戳
UNIX_TIMESTAMP();
2.常问类型
data 年月日 YYY-MM-DD
TIME 时分秒 HH:MM:SS
datatime 年月日时分秒 YYYY-MM-DD HH:MM:SS
TIMESTAME 年月日时分秒 YYYY-MM-DD HH:MM:SS 范围小
3.MySQL常见的两种存储引擎
MyISAM与InnoDB,默认是InnoDB
区别:
1.InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件跟索引是存在一起的,必须要有主键,通过主键索引效率会很高。使用辅助索引的话需要查询两次,先查询到主键,再根据主键去查询数据
2.MyISAM是非聚集索引,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。也就是说InnoDB的叶子节点存的就是数据文件,而MyISAM的叶子节点存储的是指向数据文件的指针
3.当你去创建的时候可以去mysql文件存放位置观察,当你创建的是InnoDB引擎,会有一个.frm 跟.opt文件,当你创建的是MyISAM引擎的话会有 .frm,.MYI.MYD.opt四个文件
4.InnoDB支持事务,而MyISAM不支持事务
5.InnoDB支持外键,而MyISAM不支持
6.InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
7.InnoDB表必须有唯一索引(如主键)(用户没有指定的话会自己找/生产一个隐藏列Row_id来充当默认主键),而Myisam可以没有
4.锁的区别
-
MyISAM采用表级锁(table-level locking)。
-
InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
表级锁和行级锁对比: -
表级锁:是粒度较大的锁,它锁的是整张表,实现简单,资源消耗也比较少,加锁快,不会出现死锁。触发锁冲突的概率高,并发度最低
-
行级锁:是粒度较小的锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突,但加锁的开销也最大,加锁慢,会出现死锁。
5.什么是索引,索引都有哪些
概念:官方的讲,索引是帮助MySQL高效获取数据的数据结构,通俗的讲就是好比一本书的目录,能够加快查询速度。Mysql索引使用的数据结构主要有BTree索引 和 哈希索引,
InnoDB跟MyISAM都是BTree索引,不支持hash索引,memory引擎支持hash索引
优势:能够提高数据检索速度,降低IO成本
缺点:索引是会占据磁盘空间的,所以提高了查询效率,降低了更新表的效率
在MySQL中, 索引有两种分类方式:逻辑分类和物理分类。
按照逻辑分类,索引可分为:
主键索引:一张表只能有一个主键索引,不允许重复、不允许为 NULL;
唯一索引:数据列不允许重复,允许为 NULL 值,一张表可有多个唯一索引,但是一个唯一索引只能包含一列,比如身份证号码、卡号等都可以作为唯一索引;
普通索引:一张表可以创建多个普通索引,一个普通索引可以包含多个字段,允许数据重复,允许 NULL 值插入;
全文索引:让搜索关键词更高效的一种索引。
按照物理分类,索引可分为:
聚集索引:一般是表中的主键索引,如果表中没有显示指定主键,则会选择表中的第一个不允许为 NULL 的唯一索引,如果还是没有的话,就采用 Innodb 存储引擎为每行数据内置的 6 字节 ROWID 作为聚集索引。每张表只有一个聚集索引,因为聚集索引的键值的逻辑顺序决定了表中相应行的物理顺序。聚集索引在精确查找和范围查找方面有良好的性能表现(相比于普通索引和全表扫描),聚集索引就显得弥足珍贵,聚集索引选择还是要慎重的(一般不会让没有语义的自增 id 充当聚集索引);
非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同(非主键的那一列),一个表中可以拥有多个非聚集索引。
使用联合索引需要遵循最佳做前缀法原则
比如建立索引(name,age,sex)
select * from student where name = ‘’ and age = ‘’ and sex = ‘’; 走索引
select * from student where age = ‘’ and name= ‘’; 走索引 (真正执行sql的时候会优化,将name提前)
select * from student where sex = ‘’; 不走索引
6.B+树 哈希树的区别
B+树:是B-树的变体,有着比B-树更好的查询效率,B+树主要有几个特点
1.中间节点不保存数据,只用来做索引
2.叶子节点包含了全部元素信息,并且是有序的,是以自小而大的顺序链接的
3.所有中间节点元素都存在于子节点,并且是子结点中最大的元素
4.数据库的聚集索引中,叶子节点直接包含卫星数据,而非聚集索引中,叶子节点包含的是指向卫星数据的索引。
(卫星数据:索引元素所指向的数据记录)
优势:
1.B+树查询更加稳定,因为都需要遍历到叶子节点获取数据
2.因为叶子节点是有序的,所以更适用于范围查询
3.因为B+树比较矮胖,所以IO次数比较少
哈希树
1.结构简单
2.查找迅速
3.在删除的时候,不做任何结构调整,采取的是一种“见缝插针”的算法
4.最大的缺点就是 非排序性,哈希树不支持排序,没有顺序特性。
7.为什么要使用递增主键?
因为自增ID可以保证每次插入时B+索引是从右边扩展的,可以避免B+树和频繁合并和分裂,如果使用字符串主键和随机主键,会使得数据随机插入,效率比较差。
8.mysql跟oracle的区别
1.宏观上:
(1)mysql是开源的,而oracle是收费的,oralce出了问题可以找售后,mysql出了问题自己百度
(2)mysql是中小型数据库,而oralce是大型数据库
(3)oralce支持大并发
2.微观上:
(1)mysql即支持表级锁,也支持行级锁,而oracle只支持行级锁
(2)oracle的行级锁锁的是数据行,不依赖于索引,所以并发性会更好一些
(3)事务默认的隔离级别不同,mysql默认是可重复读,而oracle默认是读已提交
(4)数据安全问题,mysql默认是自动提交的,而oralce是需要手动提交的,所以如果在更新中,如果发生宕机问题,mysql可能会造成数据丢失问题,而oracle会把提交的sql操作写到在线联机日志文件中,保存到磁盘上,所以即使发生了宕机,也可以根据日志文件去恢复数据
(5)mysql的语句更加灵活,比如分页的话 mysql使用关键字limit,而oracle的分页是通过伪列和子查询完成的
(6)性能诊断方面,oracle有很多调优工具,而mysql只能根据慢查询日志去优化sql
9.大表优化
1.限定数据范围,限制不带任何条件的查询,比如查询历史订单的话限制查询一个月
2.读/写分离: 经典的数据库拆分方案,主库负责写,从库负责读
3.使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
4.垂直分区:根据数据库里面数据表的相关性进行拆分。 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表。
5.水平拆分:是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。水平拆分能够 支持非常大的数据量存储,应用端改造也少,但 分片事务难以解决 ,跨界点Join 性能较差,逻辑复杂。
主要实现有两种方案:
(1)客户端代理: 分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。
(2)中间件代理: 在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。比如Mycat
10.mysql缓存
my.cnf加入以下配置,重启Mysql开启查询缓存
query_cache_type=1
query_cache_size=600000
或执行sql语句开启
set global query_cache_type=1;
set global query_cache_size=600000;
开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此不满足条件的查询不会命中缓存。
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。**因此,开启缓存查询要谨慎,并控制缓存空间的大小。可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:
select sql_no_cache count(*) from usr;
看到最后的帅哥们记得点赞哦!还有想了解的知识点请评论,博主会更新哟
mysql,windows下默认是大小写不敏感的,因此迁移表,会自动将大写改为小写
这个配置为1时,既大小写不敏感

需要在my.ini文件中加如下一句,然后重新初始化一下mysql
# 区分大小写
lower_case_table_names=0
避免回表查询
什么是回表查询?
假如一个表有四个字段,id,name,age,sex然后建立一个联合索引(name,age)
(以下这种会出现回表操作)
select * from student where name = ‘’ and age = ‘’;
现在联合所引树上找到,会拿到主键ID,然后再去index索引树找到并返回所有值,这就叫回表

select name,age from student where name = ‘’ and age = ‘’;
需要的值直接可以在联合索引树上拿到,就不需要再去index索引树上查找
bin.log和redo.log
binlog:(逻辑日志)Service层进行记录,用于记录数据库执行的写入性操作,以二进制的形式保存在磁盘中。binlog是通过追加的方式进行写入的,当文件大小达到给定值后,会生成新的文件来保存日志
使用场景:主从复制和数据恢复
redo.log:(物理日志)包括两部分,一个是内存中的日志缓存,另一个是磁盘上的日志文件,mysql每执行一条DML语句,先将记录写入到redo log buffer,后续某个时间点再一次性将多条操作记录写入到redo log file。这种先写日志,再写磁盘的技术就是mysql里常说的WAL技术
主要区别:
1.redo.log是innoDB引擎特有的;binlog是Mysql的service实现的,所有引擎可以使用
2.redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是记录这个语句的原始逻辑
3.redo log是循环写的,空间固定会用完;binlog是可以追加写入的,“追加写”是指binlog文件到一定大小后会切换下一个,并不会覆盖以前的日志
update的执行过程
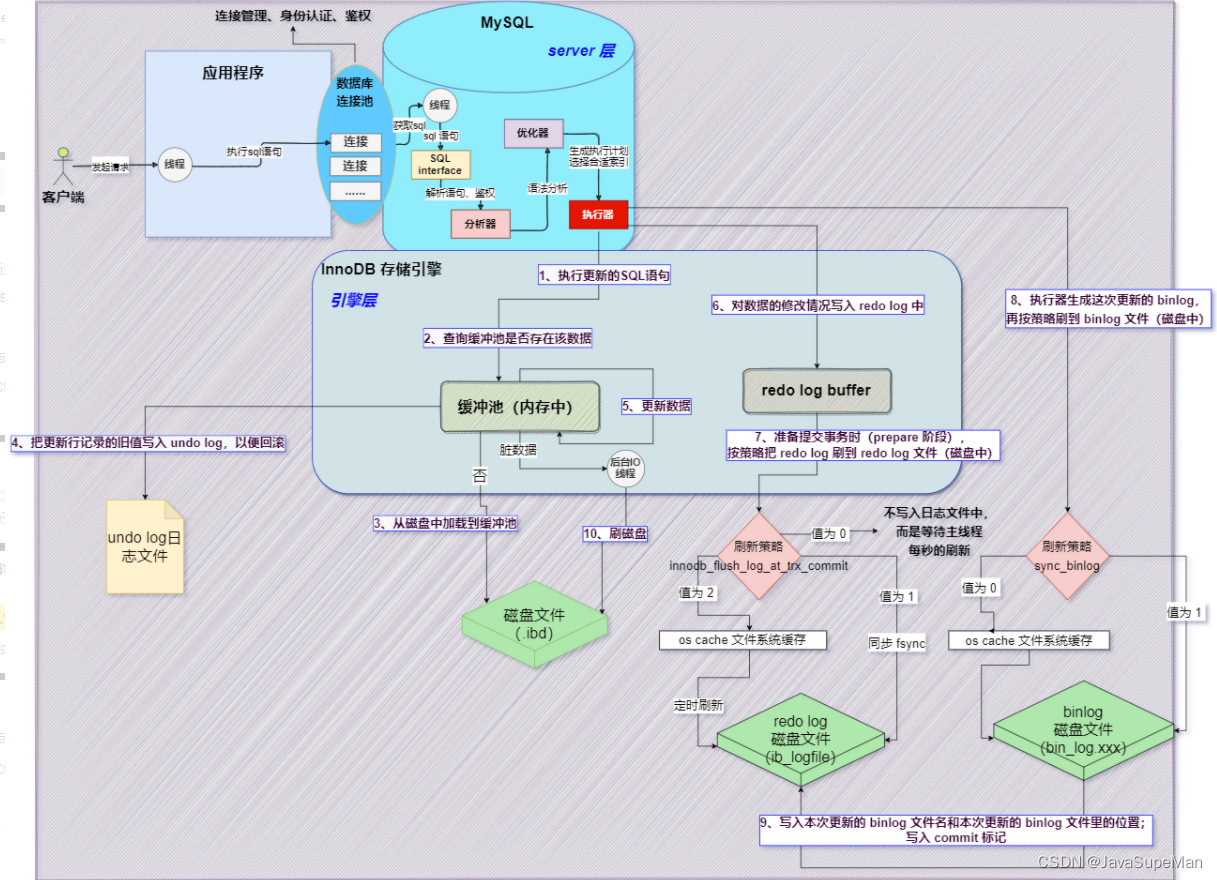
1.首先客户端通过 tcp/ip 发送一条 sql 语句到 server 层的 SQL interface;
2.SQL interface 接到该请求后,先对该条语句进行解析,验证权限是否匹配;
6.验证通过以后,分析器会对该语句分析,是否语法有错误等;
4.接下来是优化器器生成相应的执行计划,选择最优的执行计划;
5.之后会是执行器根据执行计划执行这条语句。
在这一步会去 open table,如果该 table 上有 MDL 则等待。
如果没有,则加在该表上加短暂的 MDL(S)。
(如果 opend_table 太大,表明 open_table_cache 太小。需要不停的去打开 frm 文件);
6.进入到引擎层,首先会去 innodb_buffer_pool 里的 data dictionary (元数据信息) 得到表信息;
7.通过元数据信息,去 lock info 里查出是否会有相关的锁信息,并把这条 update 语句需要的锁信息写入到 lock info 里(锁这里还有待补充);
8.然后涉及到的老数据通过快照的方式存储到 innodb_buffer_pool 里的 undo page 里,并且记录 undo log 修改的 redo(如果 data page 里有就直接载入到 undo page 里,如果没有,则需要去磁盘里取出相应 page 的数据,载入到 undo page 里);
9.在 innodb_buffer_pool 的 data page 做 update 操作。并把操作的物理数据页修改记录到 redo log buffer 里,由于 update 这个事务会涉及到多个页面的修改,所以 redo log buffer 里会记录多条页面的修改信息。因为 group commit 的原因,这次事务所产生的 redo log buffer 可能会跟随其它事务一同 flush 并且 sync 到磁盘上;
10.同时修改的信息,会按照 event 的格式,记录到 binlog_cache 中。(这里注意 binlog_cache_size 是 transaction 级别的,不是 session 级别的参数,一旦 commit 之后,dump 线程会从 binlog_cache 里把 event 主动发送给 slave 的 I/O 线程);
11.之后把这条 sql,需要在二级索引上做的修改,写入到 change buffer page,等到下次有其他 sql 需要读取该二级索引时,再去与二级索引做 merge 。
(随机I/O变为顺序I/O,但是由于现在的磁盘都是SSD,所以对于寻址来说,随机I/O和顺序I/O差距不大);
12.此时 update 语句已经完成,需要 commit 或者 rollback。这里讨论 commit 的情况;
13.commit 操作,由于存储引擎层与 server 层之间采用的是内部 XA (保证两个事务的一致性,这里主要保证 redo log 和 binlog 的原子性),所以提交分为 prepare 阶段与 commit 阶段;
14.prepare 阶段,将事务的 xid 写入,将 binlog_cache 里的进行 flush 以及 sync 操作(大事务的话这步非常耗时);
15.commit 阶段,由于之前该事务产生的 redo log 已经 sync 到磁盘了。所以这步只是在 redo log 里标记 commit;
16.当 binlog 和 redo log 都已经落盘以后,如果触发了刷新脏页的操作,先把该脏页复制到 doublewrite buffer 里,把 doublewrite buffer 里的刷新到共享表空间,然后才是通过 page cleaner 线程把脏页写入到磁盘中。
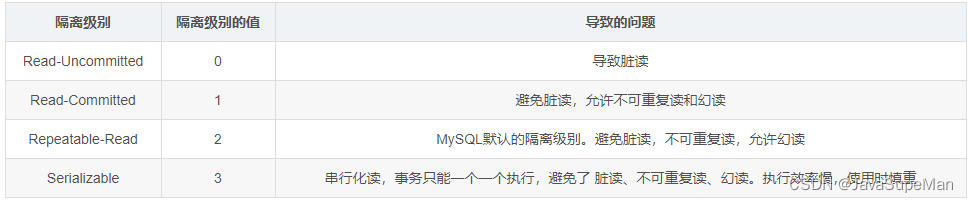
事务隔离级别
事务的传播机制

PROPAGATION_REQUIRED(默认)
如果存在一个事务,则支持当前事务,如果没有则开启事务
PROPAGATION_SUPPORTS
如果存在一个事务,支持当前事务,如果没有事务,则非事务执行
PROPAGATION_MANDATORY
如果存在一个事务,支持当前事务,如果没有一个活动的事务,则抛出异常
PROPAGATION_REQUIRED_NEW
会开启一个新的事务,如果存在一个事务,则先将这个存在的事务挂起
PROPAGATION_NOT_SUPPORTS
总是非事务执行,并挂起任何存在的事务
PROPAGATION_NEVER
总是非事务执行,如果存在一个活动事务,则抛出异常
PROPAGATION_NESTED
如果一个活动的事务存在,则运行在一个嵌套的事务中
事务注解失效原因
1.必须在public修饰的方法上才能生效,因为spring要求被代理方法必须得是public的
2.方法用final修饰,不会生效,因为底层是AOP实现的,被final修饰无法重写方法
3.同一个类中的方法直接内部调用,会导致事务失效
exists和in查询原理的区别
👀 exists : 外表先进行循环查询,将查询结果放入exists的子查询中进行条件验证,确定外层查询数据是否保留
👀 in : 先查询内表,将内表的查询结果当做条件提供给外表查询语句进行比较
结论
通过上面的优化策略分析和exists和in的查询原理的分析,将这两块内容结合起来其实就得出了我们想要的一个结论:
外层小表,内层大表(或者将sql从左到由来看:左面小表,右边大表): exists 比 in 的效率高
外层大表,内层小表(或者将sql从左到由来看:左面大表,右边小表): in 比 exists 的效率
















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











