







 本文详细介绍了PostgreSQL中的排名窗口函数,如ROW_NUMBER,RANK,DENSE_RANK,PERCENT_RANK,CUME_DIST和NTILE,以及如何在按部门排序员工月薪时使用这些函数。特别关注了CUME_DIST的累积分布和NTILE的等分功能。
本文详细介绍了PostgreSQL中的排名窗口函数,如ROW_NUMBER,RANK,DENSE_RANK,PERCENT_RANK,CUME_DIST和NTILE,以及如何在按部门排序员工月薪时使用这些函数。特别关注了CUME_DIST的累积分布和NTILE的等分功能。
postgresql 分类排名
排名窗口函数
排名窗口函数用于对数据进行分组排名。常见的排名窗口函数包括:
• ROW_NUMBER,为分区中的每行数据分配一个序列号,序列号从 1 开始分配。
• RANK,计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会
产生跳跃。
• DENSE_RANK,计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的
排名也是连续的值。
• PERCENT_RANK,以百分比的形式显示每行数据在其分区中的名次;如果存在名次相
同的数据,后续的排名将会产生跳跃。
• CUME_DIST,计算每行数据在其分区内的累积分布,也就是该行数据及其之前的数据
的比率;取值范围大于 0 并且小于等于 1。
• NTILE,将分区内的数据分为 N 等份,为每行数据计算其所在的位置。
排名窗口函数不支持动态的窗口大小(frame_clause),而是以当前分区作为分析的窗口。
示例
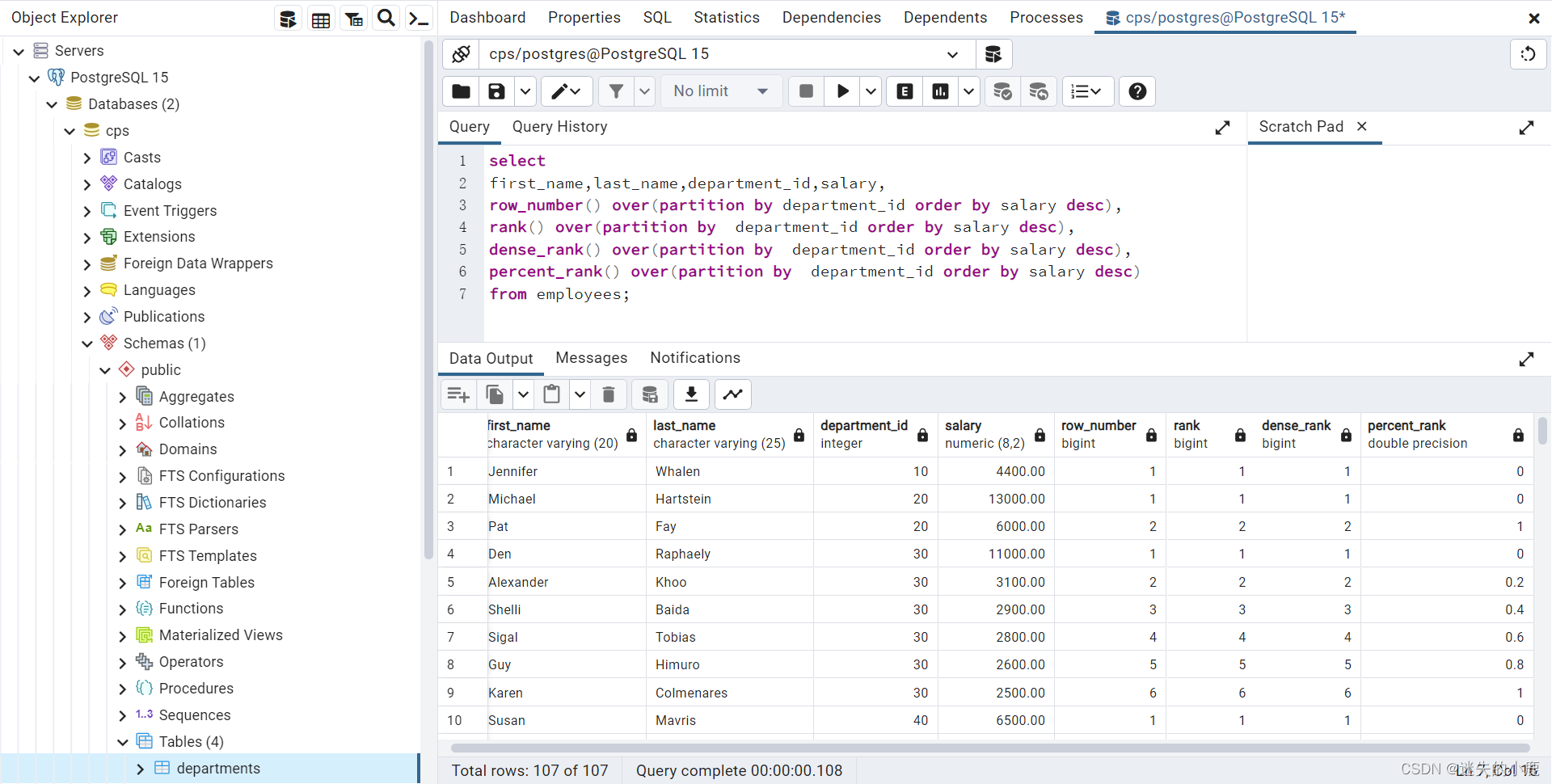
按照部门为单位,计算员工的月薪排名:
select
first_name,last_name,department_id,salary,
row_number() over(partition by department_id order by salary desc),
rank() over(partition by department_id order by salary desc),
dense_rank() over(partition by department_id order by salary desc),
percent_rank() over(partition by department_id order by salary desc)
from employees;
以上示例中 4 个窗口函数的 OVER 子句完全相同,此时可以采用一种更简单的写法:
select
first_name,last_name,department_id,salary,
row_number() over w,
rank() over w,
dense_rank() over w,
percent_rank() over w
from employees
window w as (partition by department_id order by salary desc);
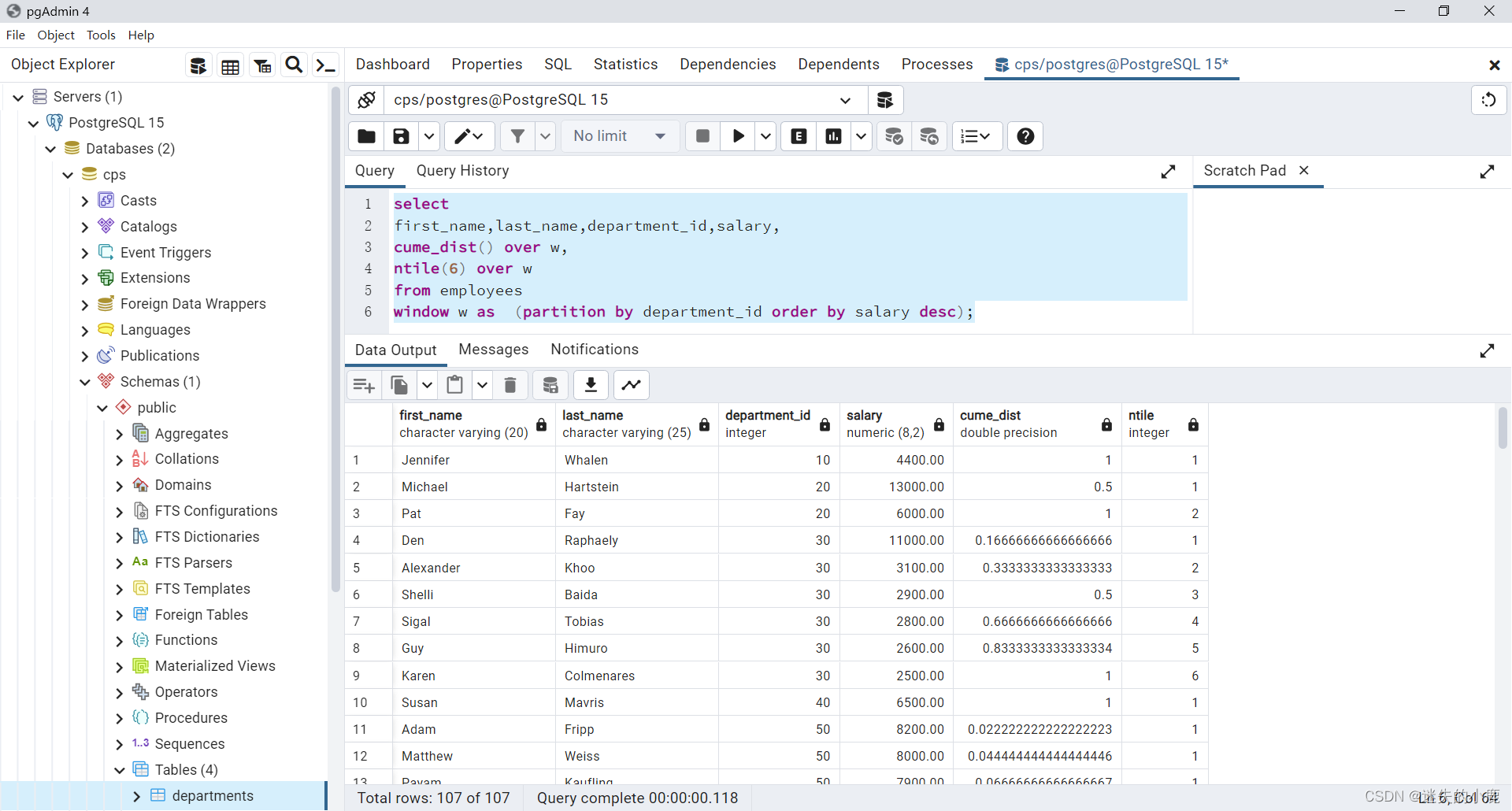
CUME_DIST 和 NTILE
select
first_name,last_name,department_id,salary,
cume_dist() over w,
ntile(6) over w
from employees
window w as (partition by department_id order by salary desc);
















 3887
3887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









