










StableDiffusion是一款开源、免费的应用程序,因为其生态开放且发展迅速,所以不同时期的安装、配置方式可能都会有所变化。如果遇到什么安装上的问题可以评论提出,帮你解答。

预告:Stable Diffusion安装包已放至文末,需要的可以自提
关于Stable Diffusion
Stable
Diffusion(简称SD)是2022年发布的一个深度学习文本到图像生成模型,由慕尼黑大学的CompVis研究团体首先提出,并与初创公司Stability
AI、Runway(不是runwsh哈)合作开发,同时得到了EleutherAI和LAION的支持。
它可以实现的功能有很多,可以根据文本的描述生成指定内容的图片(图生图),也可以用于已有图片内容的转绘(图生图),还可以用作图像的局部重绘、外补扩充、高清修复,甚至是视频的“动画化”生成。
SD的源代码是开源发布在网上的,这意味着任何人都可以免费、不限量地使用它进行AI绘画生成操作。有开发者使用它的源代码制作了易于用户使用的图形化界面(GUI),于是便有了今天我们大多数人手里可以使用的Stable
Diffusion WebUI(SD Web UI)。

【电脑配置的必要条件】
Stable Diffusion 不要求配置高,但是要求着显卡的性能及显存的大小!
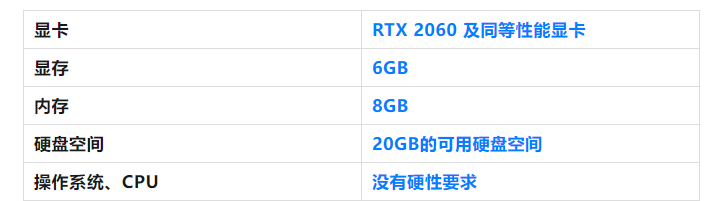
最低配置要求:
在此配置条件下,约1-2分钟一张图,可绘制分辨率512 512像素。
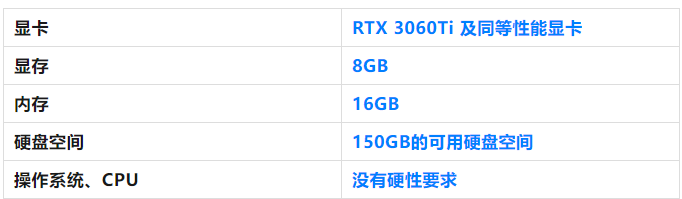
较为推荐的配置:
在此配置条件下,约10-30秒一张图,可绘制分辨率1024 1024像素。
不知道自己显卡对应的等同性能是什么水平。可以参考:桌面显卡性能天梯图。
// 桌面显卡性能天梯图
https://www.mydrivers.com/zhuanti/tianti/gpu/
Q&A
Q:Mac能用Stable Diffusion吗?显卡用N卡好还是A卡好?
A:问就是都能用,但目前,Nvidia(英伟达、N卡)显卡是AIGC应用公认的最优解。
Q:我想买一台新电脑来跑图,应该怎么选?
A:非要这么问的话,购置一台N卡台式机是最佳的选择。
安装方式1:整合包安装Stable Diffusion
“整合包”一般指开发者对Automatic1111制作的Stable Diffusion
WebUI进行打包并使其程序化的一种方式。使用整合包,一般可以省去一些自主配置环境依赖、下载必要模型的功夫。首先推荐使用整合包,以下是一些我推荐的整合包:
秋葉aaaki
公认最适合新手使用的整合包之一,支持一键启动,含可调节多种程序参数的启动器,方便更新管理。

安装方式2:自主安装部署Stable Diffusion
—windows
-
安装Python 3.10.6(勾选Add to PATH)和git
-
从搜索栏打开命令提示符,然后键入
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
- 双击webui-user.bat
—Linux
(基于 Debian)
输入以下命令,这会将 webui 安装到您的当前目录:
sudo apt install git python3.10-venv -y
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui && cd
stable-diffusion-webui
python3.10 -m venv venv
安装并运行:
./webui.sh {你的参数}
其他版本
// Red Hat-based
sudo dnf install git python3 -y && git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui && cd stable-diffusion-webui && ./webui.sh
// Arch-based
sudo dnf install git python3 -y && git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui && cd stable-diffusion-webui && ./webui.sh
* 1
* 2
* 3
* 4
* 5
* 6
* 7
备注:Python 3.10
Installing Python 3.10
cd stable-diffusion-webui
sudo pacman -S pyenv
pyenv install 3.10.6
pyenv local 3.10.6
python -m venv venv
* 1
* 2
* 3
* 4
* 5
* 6
* 7
* 8
* 9
* 10

* 8
* 9
* 10
这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
这份完整版的SD整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
想要原版100款插件整合包的小伙伴,可以来点击下方插件直接免费获取
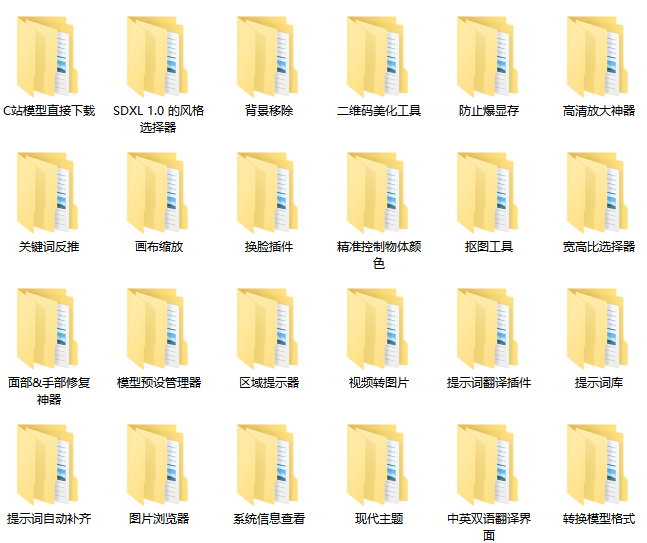
100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
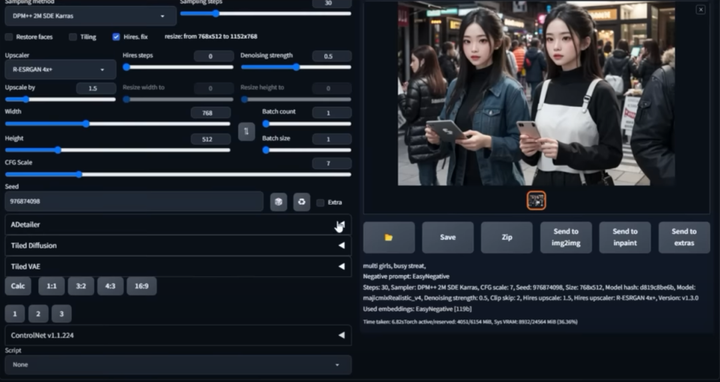
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
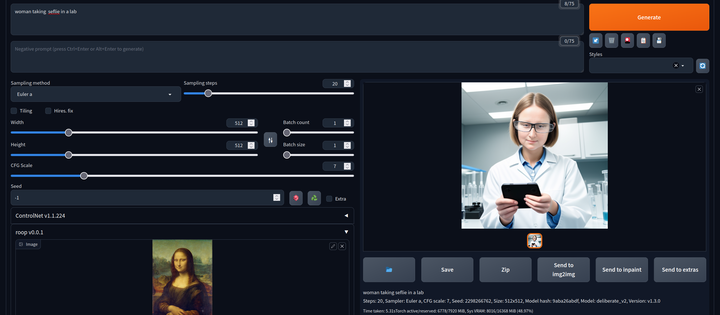
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
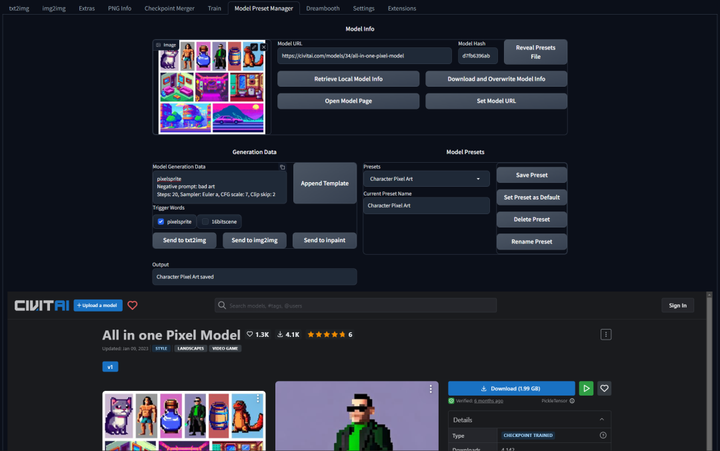
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
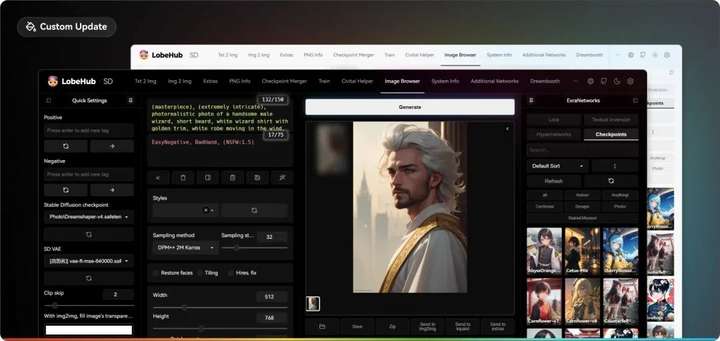
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
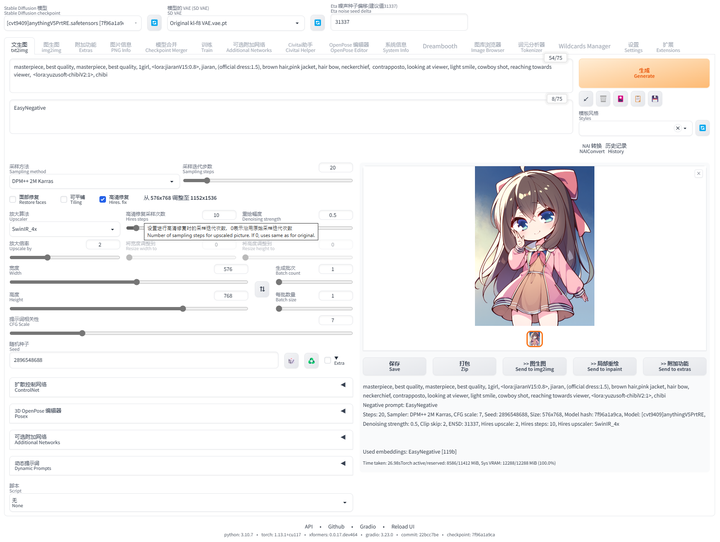
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中

提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
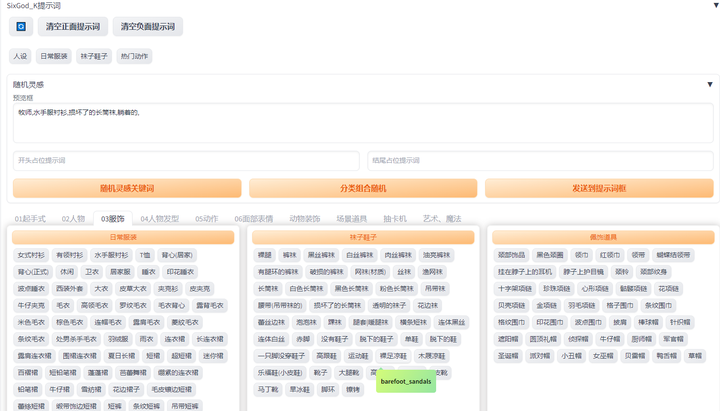
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
这份完整版的SD整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









