






Xpath是python爬虫过程中,非常重要的一种用来定位的语法。
PART
01
开始使用
首先我们需要得到一个 HTML 源代码,用来模拟爬取网页中的源代码。
先下载lxml 包。
pip install lxml
准备HTML源代码。
from lxml import etree
doc='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
html = etree.HTML(doc)
result = etree.tostring(html)
print(str(result, 'utf-8'))
PART
02
节点、元素、属性、内容
xpath的思想是通过路径表达去寻找节点。节点包括元素,属性,和内容。
2.1 路径表达式
/ 根节点,节点分隔符,
// 任意位置
. 当前节点
.. 父级节点
@ 属性
2.2 通配符
* 任意元素
@* 任意属性
node() 任意子节点(元素,属性,内容)
2.3 谓语
使用中括号来限定元素,称为谓语
//a[n] n为大于零的整数,代表子元素排在第n个位置的<a>元素
//a[last()] last()代表子元素排在最后个位置的<a>元素
//a[last()-] 和上面同理,代表倒数第二个
//a[position()<3] 位置序号小于3,也就是前两个,这里我们可以看出xpath中的序列是从1开始
//a[@href] 拥有href的<a>元素
//a[@href='www.baidu.com'] href属性值为'www.baidu.com'的<a>元素
//book[@price>2] price值大于2的<book>元素
PART
03
定位
3.1 匹配多个元素,返回列表
from lxml import etree
if __name__ == '__main__':
doc='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(doc)
print(html.xpath("//li"))
print(html.xpath("//p"))
print(etree.tostring(html.xpath("//li[@class='item-inactive']")[0]))
print(html.xpath("//li[@class='item-inactive']")[0].text)
print(html.xpath("//li[@class='item-inactive']/a")[0].text)
print(html.xpath("//li[@class='item-inactive']/a/text()"))
print(html.xpath("//li[@class='item-inactive']/.."))
print(html.xpath("//li[@class='item-inactive']/../li[@class='item-0']"))
3.2 contains
有的时候,class作为选择条件的时候不合适@class=‘…’ 这个是完全匹配,当网页样式发生变化时,class或许会增加或减少像active的class。用contains就能很方便。
from lxml import etree
if __name__ == '__main__':
doc='''
<div>
<ul>
<p class="item-0 active"><a href="link1.html">first item</a></p>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
html = etree.HTML(doc)
print(html.xpath("//li[@class='item']"))
print(html.xpath("//*[contains(@class,'item')]"))
3.3 starts-with
包含某个属性的第一个节点。
from lxml import etree
if __name__ == '__main__':
doc='''
<div>
<ul class='ul items'>
<p class="item-0 active"><a href="link1.html">first item</a></p>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
html = etree.HTML(doc)
print(html.xpath("//*[contains(@class,'item')]"))
print(html.xpath("//*[starts-with(@class,'ul')]"))
3.4 text、last
from lxml import etree
if __name__ == '__main__':
doc='''
<div>
<ul class='ul items'>
<p class="item-0 active"><a href="link1.html">first item</a></p>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
html = etree.HTML(doc)
print(html.xpath("//li[last()]/a/text()"))
3.5 获取内容
上面已经提到过,可以使用.text和text()的方式来获取元素的内容。
from lxml import etree
if __name__ == '__main__':
doc='''
<div>
<ul class='ul items'>
<li class="item-0 active"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
html = etree.XML(doc)
print(html.xpath("//a/text()"))
print(html.xpath("//a")[0].text)
print(html.xpath("//ul")[0].text)
print(len(html.xpath("//ul")[0].text))
print(html.xpath("//ul/text()"))
3.6 获取属性
print(html.xpath("//a/@href"))
print(html.xpath("//li/@class"))
PART
04
使用Xpath爬取豆瓣
import requests
from lxml import etree
def main():
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
baseurl = "https://movie.douban.com/top250?start="
res = requests.get(url=baseurl, headers=head).text
data = etree.HTML(res)
# 电影排行榜
txt = data.xpath('//*[@id="content"]/div/div[1]/ol/li')
list = []
for i in txt:
vidow = {
"title": "",
"year": '',
"score": 0,
"num": 0
}
title_list = i.xpath('./div/div[2]/div[1]/a/span/text()')
for item in title_list:
vidow['title'] += item.replace("\n", "").replace("\xa0", " ")
vidow['year'] = i.xpath('./div/div[2]/div[2]/p[1]/text()')[1].split("/")[0].replace("\n", "").replace("\xa0", " ").replace(" ", "")
vidow['score'] = i.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
vidow['num'] = i.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0].replace("人评价", "")
list.append(vidow)
print(list)
if __name__ == '__main__':
main()
如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
😝朋友们如果有需要的话,可以V扫描下方二维码免费领取🆓
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
 #### **一、Python学习路线**
#### **一、Python学习路线**

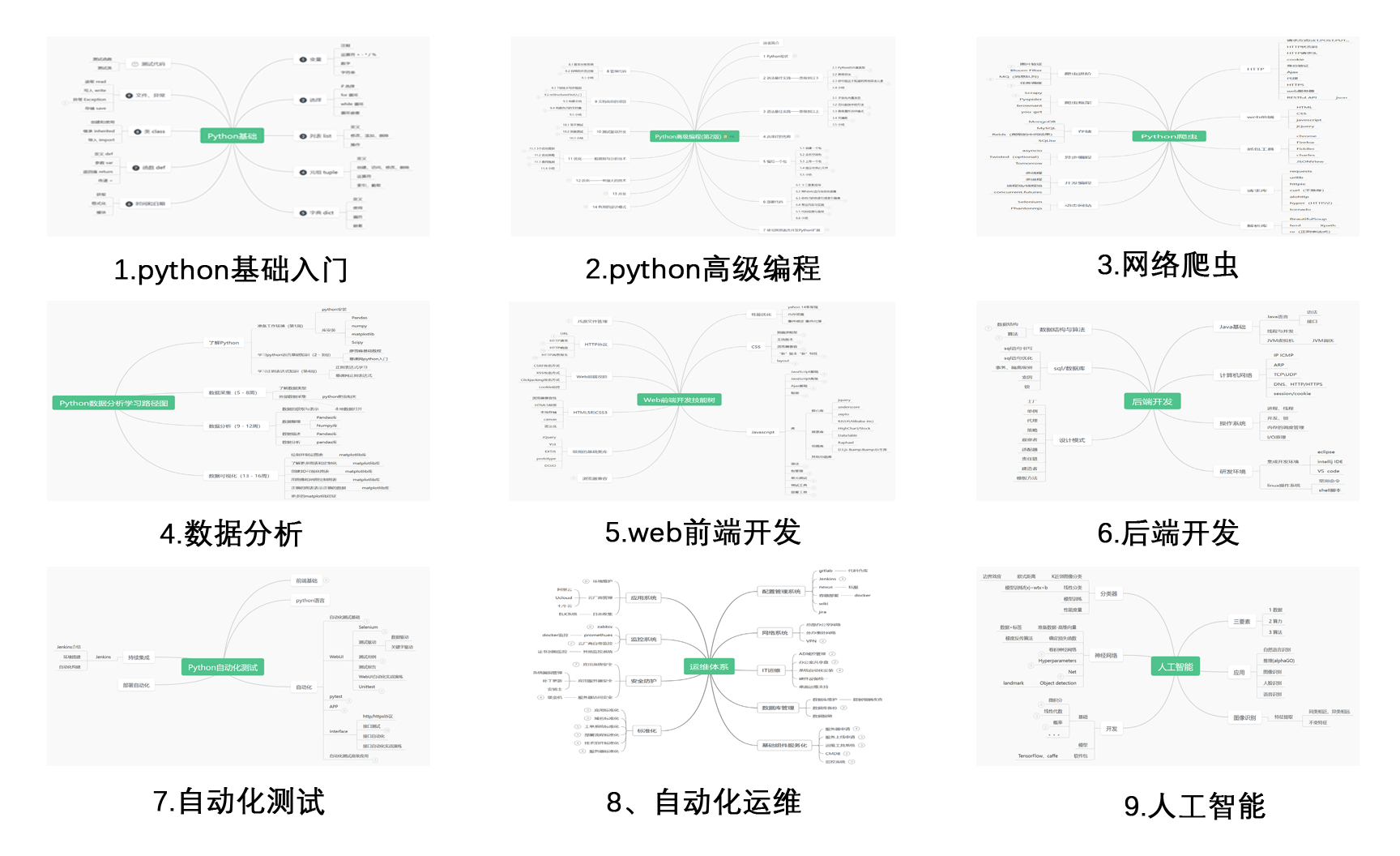
二、Python基础学习
1. 开发工具
2. 学习笔记
3. 学习视频
三、Python小白必备手册

四、数据分析全套资源

五、Python面试集锦
1. 面试资料


2. 简历模板
**
因篇幅有限,仅展示部分资料,添加上方即可获取**















 1123
1123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









