






采集规则配置时,主要的问题是如何只采集网页上的有效内容。
现在新一代的采集工具都会先智能自动配置好采集规则,效果与准确性就得看各家采集器的智能算法了。
但如果有特殊的需求,要采集网页上特定区域的内容,智能算法配置的采集规则就得进行修改了,重新定位采集的内容。
一般有以下几种方法可以精准定位要采集的内容:
1. 前后截取:确定开头和结尾都有特定的唯一词,获取两个特定词之间的内容;
2. 正则提取:需要懂正则语法,寻找每篇文章的共同点,编写对应的正则匹配式提取出需要的内容,一般是开发人员才懂;
3. Xpath提取:需要查看html代码,然后编写对应内容区域的xpath路径;
4. 其他特殊方法:不同采集器可能有比较特殊的方法去获取内容,例如简数采集器的可视化鼠标点选自动生成采集规则等,这个就很人性化;
如果除开特殊方法,只说一般采集器都有的方法,我比较推荐使用Xpath提取方法。
因为它只需要找html标签的id或class属性,就可以快速精准定位98%的采集内容区域,简便且快速!
就算不会看html标签,也可以用浏览自带的功能获取获取Xpath路径:
在浏览器中,鼠标右键检查,然后在右侧弹出的html代码窗口,点选要获取的内容,接着又是鼠标右键,选择Copy,然后点击Copy Xpath即可获取到该标签的Xpath路径。
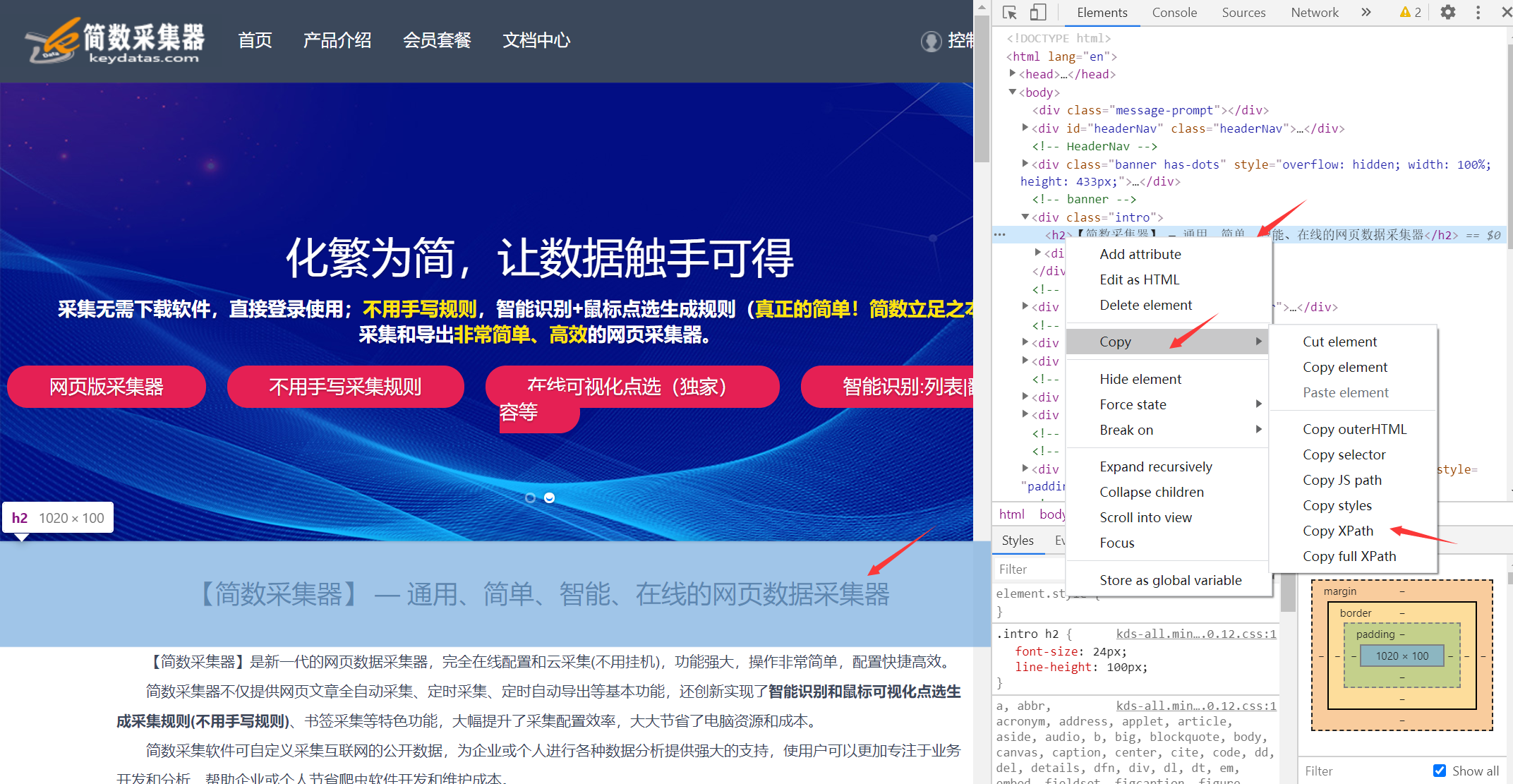
一、Html属性Xpath定位采集内容区域(重点)
语法格式://*[@属性="值"]
属性一般是寻找id或者class,属性是id更好,因为一个id的值只能是唯一值,不允许重复;
例子:

假设我们要获取图中的a标签,它有id属性main,套用语法格式,属性改为id,值改为main,
即Xpath路径应该为//*[@id="main"]
实战练习:
假设我们要获取一个页面的正文部分Xpath
I. 在浏览器中访问这个文章页面,然后鼠标右键检查,进入浏览器开发模式(或叫代码模式);

II. 看看对应正文的html标签有无特殊属性(即id或class),发现有class="m-t-md wzzPd in2",且用ctrl+F5搜索模式发现是唯一的,可以使用该属性作为Xpath定位;
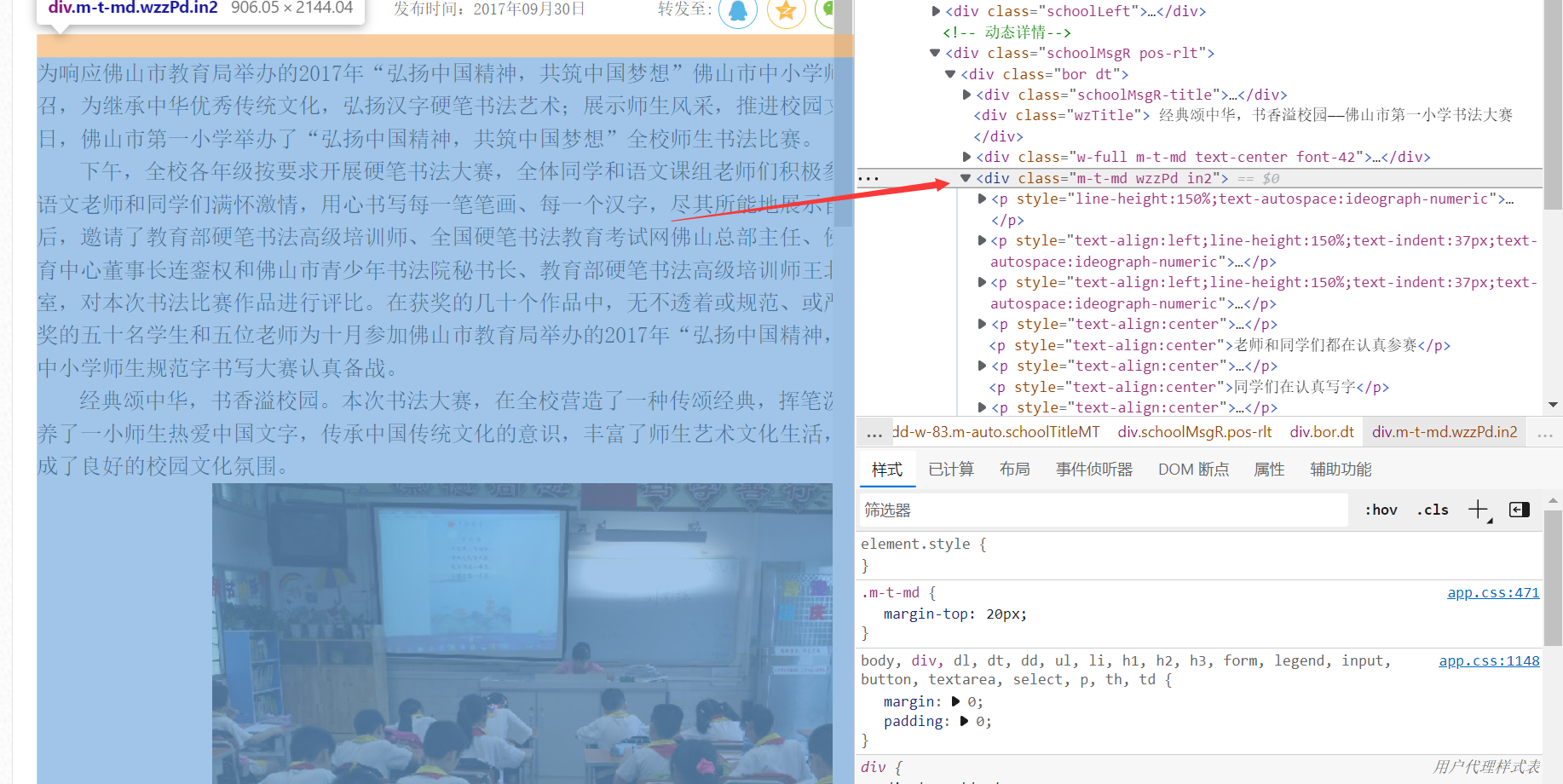
III. 按照XPath的语法://*[@属性="值"],把属性="值"换成已获取的属性class
即//*[@class="m-t-md wzzPd in2"]
将其填写到采集器里对应的Xpath处,就完成了,下图例子为简数采集器。

二、Xpath的其他基础语法
I、选择对应的子标签,即下一层的标签
语法格式:/
下图例子Xpath为:/html/body/p/a
意思是获取html标签下的子标签body,body下的子标签p,p下的子标签a,获取结果是对应下图的第10行a标签;

II、选择对应的子孙标签,即不考虑嵌套位置。
语法格式://
下图例子Xpath为:/html/body/p//a
意思是获取html标签下的子标签body,body下的子标签p,p下的所有标签a,获取结果是对应下图的第10行和12行的a标签;

III、选取第几个标签
语法格式:/[数字]
下图例子Xpath为:/html/body/p/a[2]
意思是获取html标签下的子标签body,body下的子标签p,p下的第二个标签a,获取结果是对应下图的第11行的a标签;
















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









