






转载大佬的记录
EasyEnsemble:一种简单的不平衡数据的建模方法(附测试代码)
![]()
旅居新加坡/AI风控/数据科学/FinTech/码农
102 人赞同了该文章
摘要
虽然我这里洋洋洒洒写了2000字,但实际原理我一句话就能讲完,那就是”通过重复组合正样本与随机抽样的同样数量的负样本,训练若干数量分类器进行集成学习“。但为了让大家对这个算法有深入的了解,还是写一篇详细的文章,顺便跑个数据看看效果。
所有代码已放在kaggle上:
ensemble test- Credit Score model examplewww.kaggle.com
数据不平衡怎么办
机器学习中的一个难题就是遇到数据的标签(label)不平衡(imbalance)的数据,如果不做任何处理就直接训练模型,模型效果一般不是很理想。在实际项目中,这种问题会经常遇到。举两个例子
- 我需要给某银行建立一套反洗钱的解决方案,检测哪些转账有洗钱的嫌疑。但在银行业务里,有洗钱嫌疑的转账毕竟是少数,如果有洗钱嫌疑的标记为1,安全的标记为0,那么这标签1:0的比率通常会在100以上,也就是平均每一百笔转账中,还不到1笔是有洗钱嫌疑的。
- 我需要为某银行设计一套系统,检测哪些客户在逾期后可能还不上款,在历史数据中,还上款的标记为0,没还上的标记为1。一般来说,1:0的比率会在25以上,也就是平均100个逾期客户就有可能4个人还不上钱(这种情况也称坏账)
在这样的情况下,如何预处理数据,如何选择模型,就显得尤为重要。
一般情况下,业界有几种实践方法:
- 欠采样。由于0的标签太多,而我们更关注1的标签,为了让模型在更新权重的时候更多的考虑标签1,我们可以减少一些标签0。例如我有100条记录标签为1,1000条标签为0,那么我可以对标签为0的数据只采样10%,而标签为1的数据100%保留
- 过采样。原理和上面一样。但对标签为1的数据进行重复采样。例如还是1:0的比率还是100:1000,那么我可以对标签1的数据重复10份,使得最终数据比例为1000:1000
- 1和2结合下。由于过度欠采样会造成数据浪费太多,过度过采样(有点绕口)的话并没有引进新信息,所以有的方法把欠采样和过采样结合一下。
- 使用带标签权重的模型。例如XGBoost里有个参数scale_pos_weight,就是用来调节正负样本不均衡问题的,用助于样本不平衡时训练的收敛。
- SMOTE算法。原理也很有意思,就是把少数标签拿出来(例如上面例子里标签1的部分),进行插值,生成新的数据,使得0和1的比例一样,然后去训练模型。
除了以上这几种方法,还有一种方法叫EasyEnsemble [1]
EasyEnsemble原理
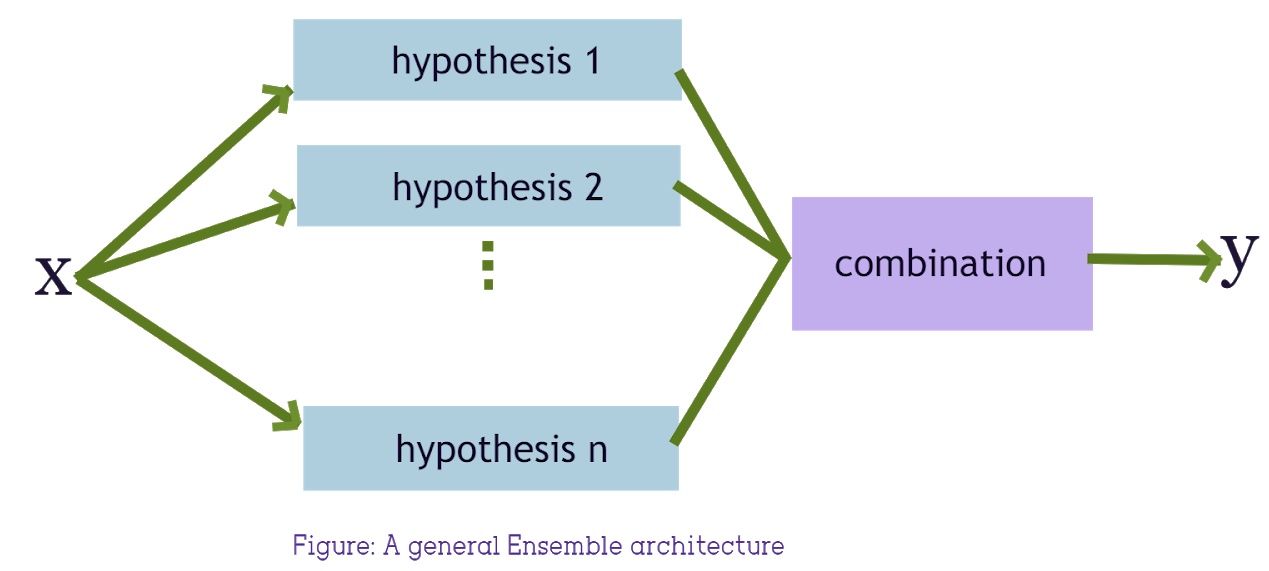
其实是2009年的一篇文章了,但直到今天,依然简单又有效。原理如下图:

满是英文和公式一看就头疼?没关系,这里解释下:
0:论文里没有对sgn函数进行解释,其实sgn函数就是sign函数,由于多个分类器加起来的结果未必是整数,sgn就是把非整数的结果转成两个分类,小于0返回-1,否则返回1。
1:数据中,少数标签的为P,多数标签的N,s_i为P与N在数量上的比例,T为需要采集的subset份数,也可以说是设置的基分类器的个数。H_i为训练基分类器i (默认使用AdaBoost,也可以设置为其他,例如XGBoost)的训练循环次数(iteration)。
2-5: 根据少数标签的为P的数量,对多数标签的N进行随机采样产生N_i,使得采样出来的数量和P的数量一样。
6: 把N_i和P结合起来,然后给基分类器i学习。这里的公式只单个基分类器的训练过程。这里引入了个下标j让你有点疑惑?这里是由于论文里用的基分类器是AdaBoost,而AdaBoost是由N个弱分类器组成的,j就是表示Adaboost基分类器里的第j个弱分类器。如果你Adaboost工作原理感兴趣,那么可以看看我之前写过的
桔了个仔:AdaBoost算法以及公式傻瓜式一步一步超详细讲解带示例zhuanlan.zhihu.com
如果你不想了解,那么只要知道,这一步就是拿第5步里组装好的数据来训练一个基分类器。
7: 重复采样,训练T个这样的基分类器。
8: 对T个基分类器进行ensemble。而这里并非直接取T个基分类的结果(0,1)进行投票,而是把n个基分类器的预测概率进行相加,最后再通过sign函数来决定分类。
EasyEnsemble效果
这里采用我一直都在用的数据集GiveMeSomeCredit。我用这个数据集写过一篇怎么设计信用评分卡的文章,感兴趣的可以参考下
桔了个仔:AI智能风控(二)——风控评分卡全流程建模看这篇就够了zhuanlan.zhihu.com
由于之前那篇有详细的EDA,这次不再详细讲了,只简单概况下数据:
- 标签是SeriousDlqin2yrs
- 标签为1的比率是6.68%
由于论文里用Adaboost,我也用Adaboost吧。为了让比较公平,实验结果可重复,我都把random_state设置为42(随便的一个数字,但全文保持一致)
首先预备个画AUC的函数
def plot_AUC(model,X_test,y_test):
probs = model.predict_proba(X_test)
preds = probs[:,1]
fpr, tpr, threshold = metrics.roc_curve(y_test, preds)
roc_auc = metrics.auc(fpr, tpr)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()分割下训练集验证集:
X_train, X_test, y_train, y_test = train_test_split(df_train.drop(['SeriousDlqin2yrs'],axis=1), df_train['SeriousDlqin2yrs'], test_size=0.2, random_state=42)用AdaBoostClassifier建个模,并在验证集上测试

单个AdaBoostClassifier
前面还讲到SMOTE方法,这里也顺便试试
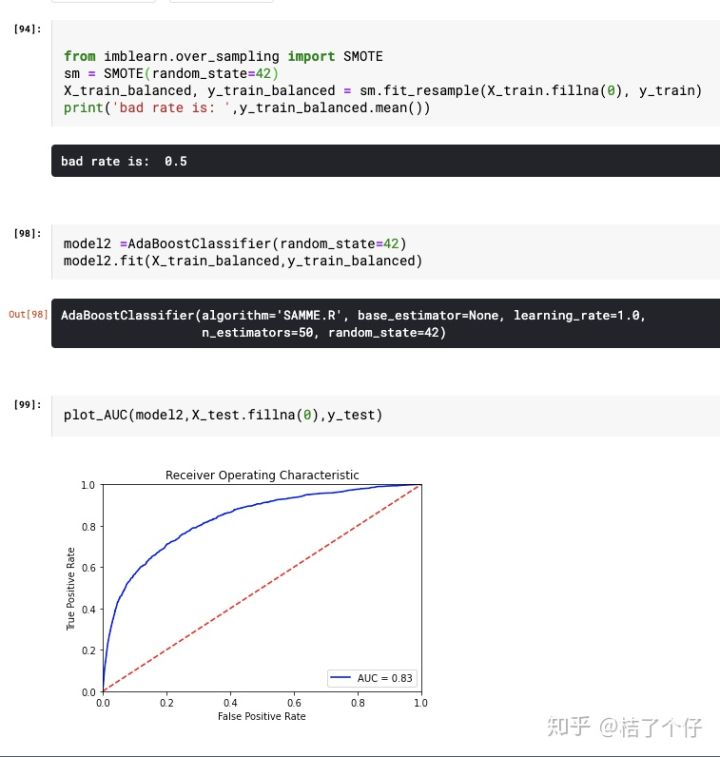
数据SMOTE后再用AdaBoostClassifier
SMOTE算法并没有效果更好,为什么呢?这里就不解释了,懂的小伙伴可以在评论区说说。
当然,我们是重点是EasyEnsemble,一起看看效果如何。

从AUC上并没有改变。难道EasyEnsemble没有用吗?非也。让我们看看confusion matrix。
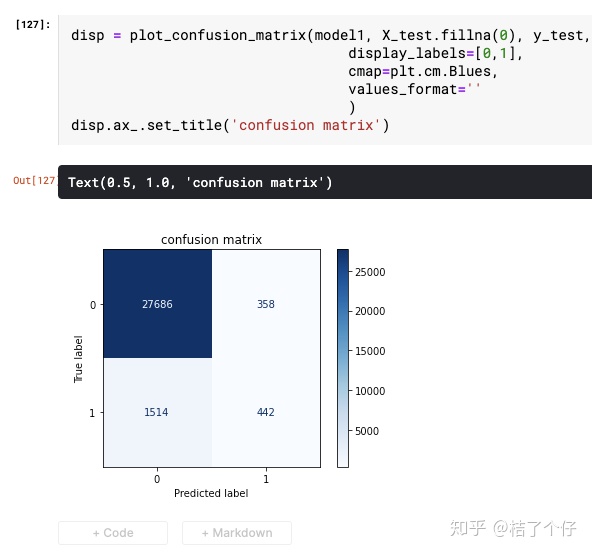
对于第一个模型,confusion matrix如下:
而对于EasyEnsemble模型,confusion matrix如下:
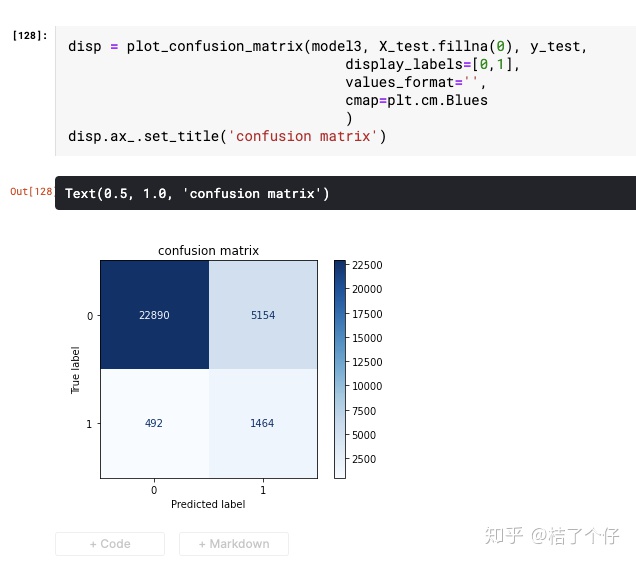
可以看到,EasyEnsemble模型的recall更高(1464/(1464+492)=75%) 也就是对于所有标签为1的数据,EasyEnsemble能比单个分类器抓到更多的坏账。当然,recall并不是唯一的评价指标,不然不用模型了,全部预测为1,recall还100%呢。
不过预测为1的比例占全部预测的(1465+5154)/(1465+5154+22890+5154)=19%,相比起75%,已经是非常好的效果了。关于如何目标函数,是个大学问,有经验的小伙伴可以在评论区分享下。
不过就AUC而言,确实没有展现出更好的功效。但EasyEnsemble的一个特点是:在数据非常不均衡时效果会好些。那我们来加剧数据的skewness,来模拟下数据极度不均衡效果(标签1比例只占约0.35%)。
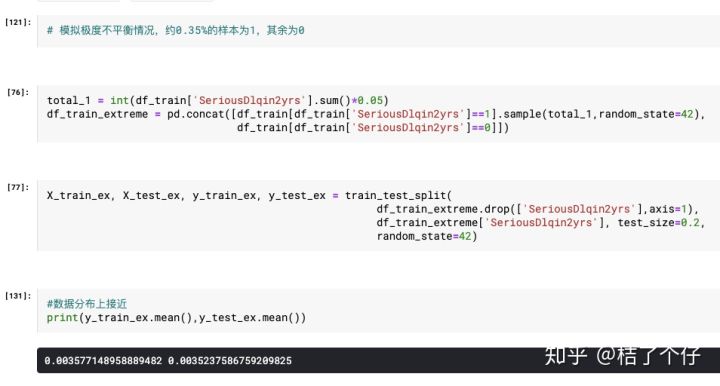
在这种极度不均衡的数据里,看看单个AdaBoostClassifier效果如何
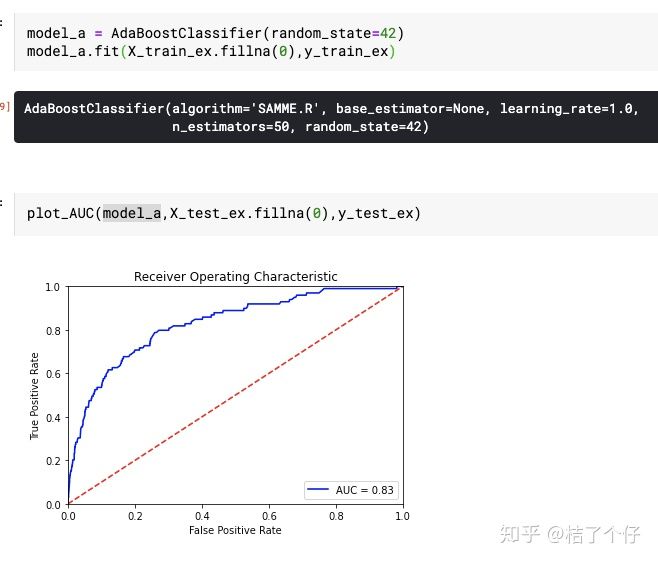
看起来还行?但看看confusion matrix,那一个叫灾难,0%的recall让人感觉心疼。
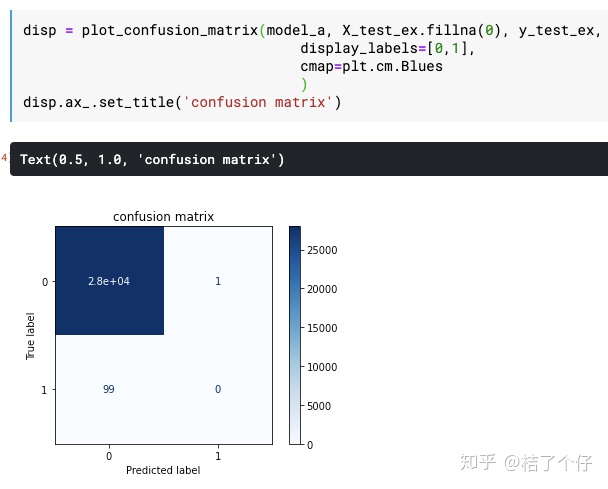
让我们试试EasyEnsemble
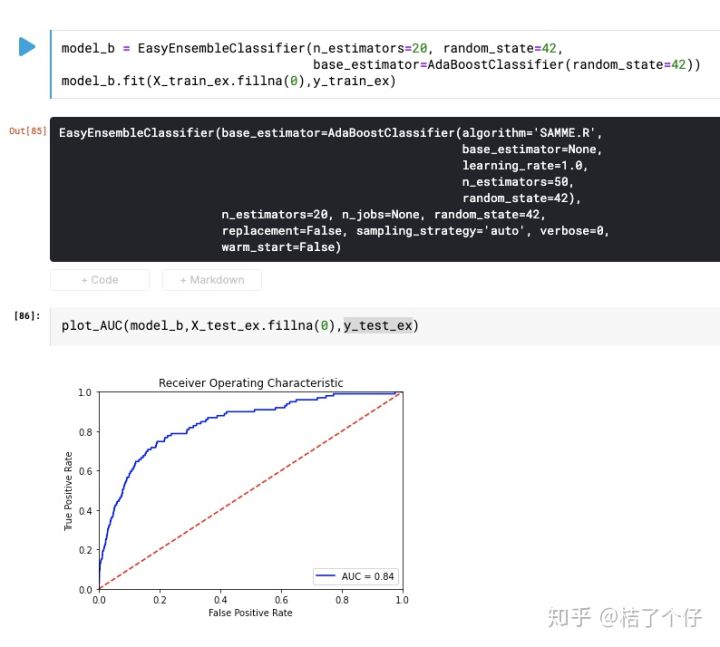
可以看到在极度不平衡的数据上,AUC稍有提升。当然,这点提升并不值得沾沾自喜,能让我们高兴的是confusion matrix
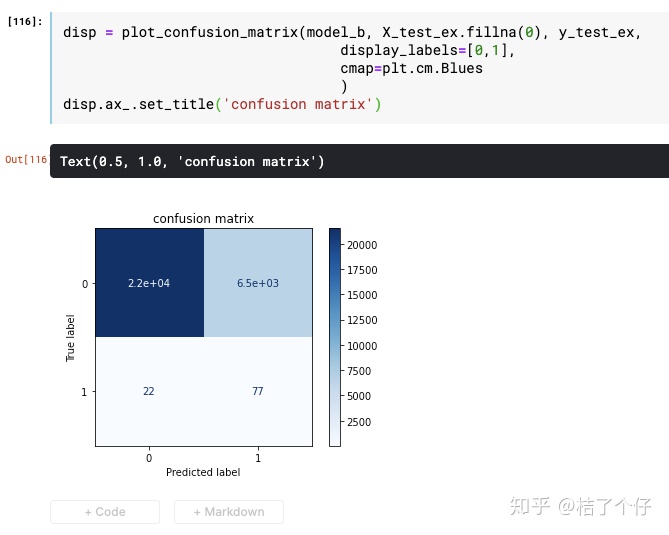
可以看到,recall能达到77%。
总结
虽然对于boosting的算法,单个分类器可以达到很好的效果,但对于数据标签极度不平衡的情况(正样本<1%),EasyEnsemble能展示出更好的预测效果。

















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









