










1. 伪装你的爬虫
在开始探险之前,记得穿上“隐身衣”——修改User-Agent。这样可以减少被网站识别的风险。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get('http://example.com', headers=headers)
print(response.text)
这段代码告诉网站,我们是来自一个流行的浏览器,而非机器人。
2. 处理Cookies,像真的访客一样
有些网站需要登录才能访问数据,这时我们可以使用Cookies。
from requests import session
s = session()
s.get('http://login.com/login', data={'username': 'you', 'password': 'secret'})
response = s.get('http://example.com/protected')
print(response.text)
通过会话管理,保持登录状态,畅通无阻。
3. 动态内容的捕捉
很多网站使用JavaScript动态加载数据,直接请求URL可能拿不到数据。Selenium来帮忙!
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://dynamic-content.com')
data = driver.page_source
driver.quit()
print(data)
Selenium模拟浏览器操作,动态内容不再是难题。
4. 速率控制,温柔爬取
别急,太快可能会被封。用time.sleep()做个深呼吸。
import time
for _ in range(10):
# 爬虫操作...
time.sleep(1) # 每次请求后暂停1秒
优雅地爬取,对服务器友好,也是自我保护。
5. 错误处理,从容不迫
遇到404或网络问题?别慌,try-except来救场。
try:
response = requests.get('http://nonexistent.com')
response.raise_for_status() # 强制检查状态码
except requests.exceptions.HTTPError as errh:
print(f"HTTP Error: {errh}")
except requests.exceptions.ConnectionError as errc:
print(f"Error Connecting: {errc}")
优雅地处理错误,让程序更健壮。
6. 数据解析的艺术
BeautifulSoup和lxml,解析HTML的两大神器。
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
links = soup.find_all('a') # 找到所有链接
for link in links:
print(link.get('href'))
就像在网页中寻找宝藏,轻松提取所需信息。
7. 正则表达式,精准捕获
对于特定模式的数据,正则表达式是不二之选。
import re
pattern = r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'
urls = re.findall(pattern, response.text)
print(urls)
复杂模式的文本提取,正则帮你一网打尽。
8. 异步请求,速度与激情
对于大量请求,asyncio和aiohttp是加速器。
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://example.com')
print(html)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
并发请求,让数据飞起来!
9. 分页爬取,一网打尽
遇到分页?循环来帮忙,一页一页拿下。
base_url = 'http://example.com/page/'
for i in range(1, 11):
url = f"{base_url}{i}"
# 进行爬取操作...
耐心翻页,数据全收进口袋。
10. 持久存储,数据不丢失
爬取的数据,存入CSV或数据库,安全又方便。
import csv
with open('data.csv', mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['Column1', 'Column2']) # 头部
for item in data_list:
writer.writerow(item)
简单几步,数据就有了长久的家。
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
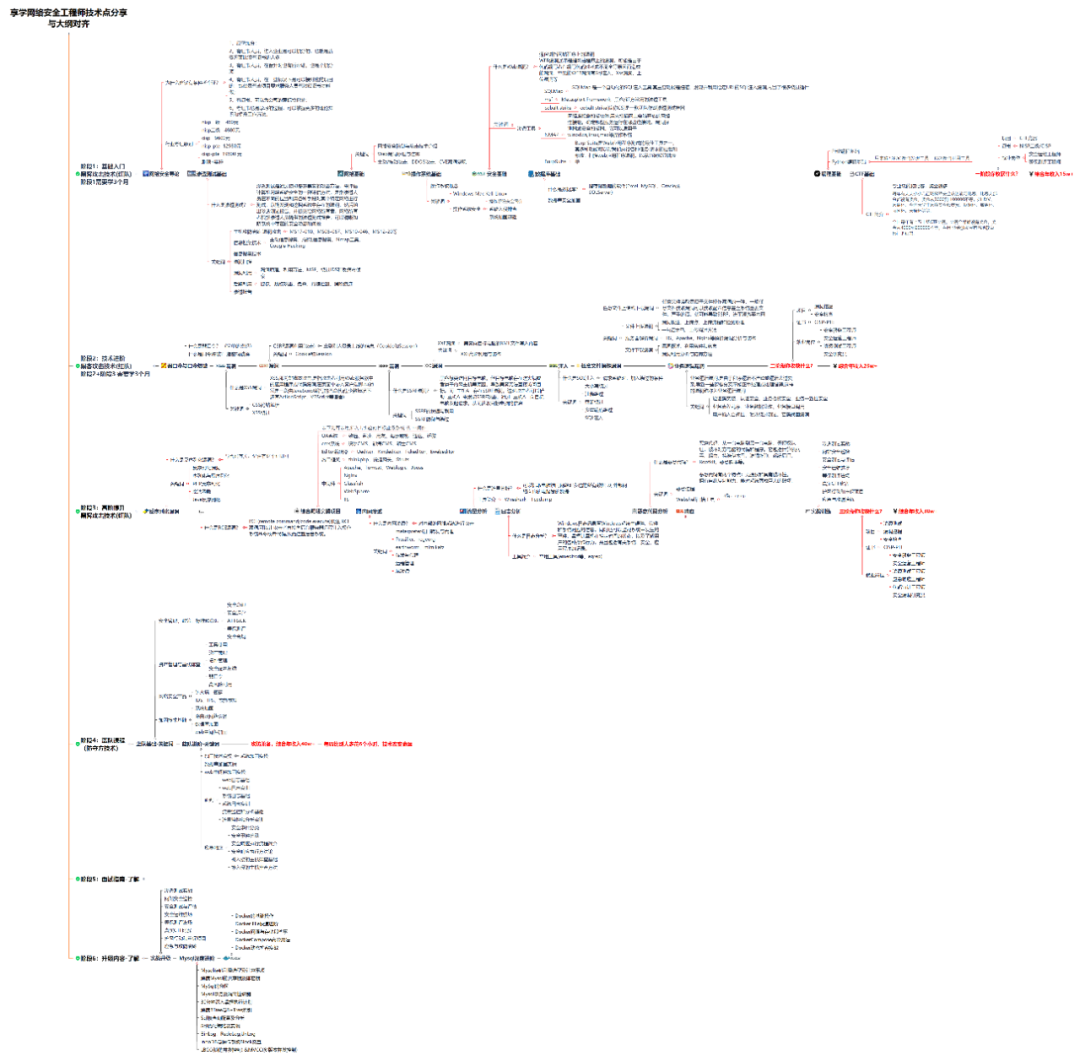
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。

(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取















 2461
2461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









