






人工智能是美国发誓要确保领先中国一大步的领域,也是美国极力试图锁住中国进步的前线。所以开年的1月20日,**中国的AI公司推出全新的DeepSeek开源模型,让美方的AI观察家们几近“破防”。****“中国的人工智能越来越好,而且更便宜”,这是他们的惊呼。一个据称是Meta员工发的帖子写道:“DeepSeek最近的一系列动作让Meta的生成式AI团队陷入了恐慌。”**因为在前者的低成本高歌猛进之下,后者无法解释自己超高预算的合理性。
去年12月,这家名为“深度求索”的中国公司推出DeepSeek-V3,在全球AI领域已经引起震动。**它的训练成本极低,甚至不到美国最先进GPT-4o训练成本的二十分之一,但是性能却可与之同处第一梯队。**今年1月DeepSeek推出的R1模型更是获得了业内人士的认可,甚至被认为在推理和数学等领域比美国的大模型更加优秀。
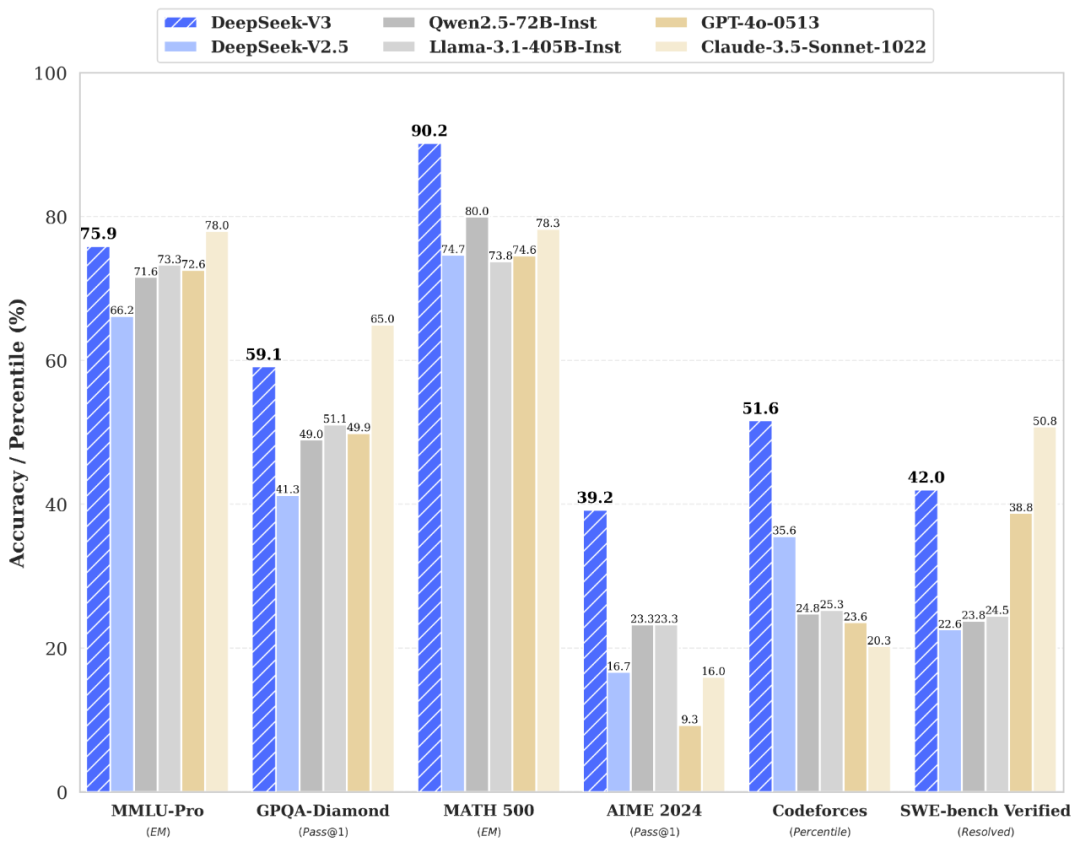
▲Deepseek-V3与多个国内外大模型的测试数据对比。(图源:“Deepseek”公众号)
尤其让美国AI观察家们诧异并且感到沮丧的是,以往为了阻止中国在人工智能领域的发展,美国政府一直在严格限制对中国出口高算力芯片,甚至不断加强努力,防止中国通过第三方获得先进芯片。DeepSeek仅仅用了英伟达为配合出口管制为中国市场量身定制的“阉割版”H800 GPU,但神奇的事情发生了,它们组合出的效果不亚于使用高性能芯片“卷算力”的美国大模型,而且因为它是完全开源的,专业人士可以清晰观察DeepSeek是如何用更有效率的训练方式与细腻的技术手段扬长避短的。
这些也是那名Meta员工“破防”的原因:使用了高算力H100 GPU的Meta Llama 3系列模型,其计算量足可训练DeepSeek-V3至少15次,但是最终表现却不及DeepSeek。美国《财富》杂志毫不掩饰地嘲讽道:美国刚刚承诺投入数千亿美元来捍卫其人工智能领导地位,一家“预算低得可笑”的中国初创公司可能已经破坏了这些希望。
DeepSeek的大胆创新震惊了业内,虽然限于硬件设施以及成本投入等原因,它与美国的先进AI大模型比起来还有点“偏科”,但是却给AI行业带来了不少深度思考,它似乎在开创一条AI发展另辟蹊径的可能路线。

▲扎克伯格2024年7月表示,开源是AI未来的方向,美国要领先中国AI数年的目标不现实。(图源:上观新闻)
大家知道,AI大模型领域的三大要素是算法、数据和算力。算力如同人大脑的神经元,一个成熟的大模型需要训练,理论上说,基础算力越大,大模型就应该越聪明。所以美国各团队之间形成了对基础算力无穷无尽的追求和比拼。马斯克旗下xAI的超级计算数据中心装配了10万颗英伟达H100 GPU芯片,堪称当今世界最强大的AI训练集群之一 。OpenAI创始人奥特曼也不甘示弱,表示将投入1000亿美金,在得州建设10座数据中心,未来4年还要耗资5000亿美金在全美打造20个超算集群。人们形成了一个印象:谁的GPU芯片集群大,谁就将稳操胜券。
然而有一种可能是,基础算力的无穷堆积不排除是阶段性浪费,这种浪费不仅是芯片的过量使用,还有对电力的过量消耗,AI沿着这个路线狂奔,前方究竟是什么,是否存在陷阱和弯路,都是未知数。一个实际情况是,人类的现实需求是有限的,而且是独特的,基础算力应当与算法、数据形成最佳组合,而实现这样的最优解,是真正的考验。
**DeepSeek的意义在于它没有跟着美国AI公司带动的潮流“卷算力”,它也卷不动,但它却在创造组合的最优解方向做出大手笔开拓。**换句话说,**它以极低成本打开了AI探索的一个新方向,展示了新的可能性,在具体落地实现和理论创新之间找到了一个平衡路径。**DeepSeek 大模型的训练成本仅557万美元,价格仅有GPT-4的1%,无论是这样的低成本还是注重细节的技术,都更契合先进科技一边服务现实,一边滚动发展的普世逻辑。

▲在2025年达沃斯论坛上,AI科技初创公司Scale AI创始人亚历山大·王(Alexandr Wang)公开表示,中国人工智能公司DeepSeek的AI大模型性能大致与美国最好的模型相当。(图源:第一财经)
DeepSeek的出现有可能带动一波有规模的仿效,成为算法创新的催化剂。前Open AI联合创始人、Tesla AI团队负责人安德烈·卡帕西在社交平台上发文称,DeepSeek-V3的出现也许意味着不需要大型GPU集群来训练前沿的大语言模型。还有人表示“如果DeepSeek的创新是真的,那AI公司是否真的需要那么多显卡?”
Axios认为,美国限制高端人工智能半导体和技术向中国流动的政策可能有助于美国在人工智能性能曲线的外围保持领先地位,但这也加速了中国更有效地构建高端人工智能的进程。是啊,中国这样已经有了雄厚科技资源储备的国家是不可能被真正压制的,美国从一个方向制裁,只会刺激中国更全面、更有韧性的进步,甚至“弯道超车”。美国的“小院高墙”最终困住的是谁,还说不清呢。
## AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









