






HashMap 13道题
1.HashMap底层数据结构是什么?1.7和1.8有什么区别?
①1.7 数据结构
数组 + 链表
②1.8数据结构
数组 + 链表|红黑树
2.HashMap存储元素的流程
①、当使用put方法存储key value数据
②、首先会获取key的hashCode
③、对hashCode进行二次hash
④、对hash值取模数组的长度,得到数组索引(桶下标)
⑤、将key value存入到指定索引的链表或者红黑树中
为什么要采用这种存储方案;
提高查找效率
时间复杂度可以达到0(1)
3.HashMap链表什么时候转化红黑树
数组长度>=64 并且 链表长度超过树化阈值8
4.HashMap什么时候扩容
①capacity 即数组容量,默认16
②loadFactor 加载因子,默认是0.75
③threshold 阈值。阈值=容量*加载因子
④当hashMap中元素个数超过阈值,就会触发扩容,每次扩容一倍
5.HashMap桶中为什么不直接存放红黑树
①链表短的时候和红黑树性能差不多;
4个元素的链表
4个元素的红黑树
②红黑树一个节点占用的内存要比链表一个节点占用内存大(数据结构)
③如果hash值很随机,按照罗松分布,长度超过8的链表概率为 0.00000006
红黑树防止恶意DOS(Denial Of Service)攻击(伪造数据让数据的hashCode一样)
6.红黑树什么时候退化成链表
① 情况1:
数组扩容,导致树的拆分
并且拆分后的节点<=6个
②情况2:
红黑树元素被删除
如果根节点的左子树,右子树,左孙子,右孙子,有一个为null; 再次删除一个节点,退化成链表
7.索引如何计算
①.调用hashCode方法获取key的hashCode
②对hashCode再调用hashMap的hash方法进行二次hash运算
hashCode ^ (hashCode >> 16)
③最后使用hash % 数组长度得到索引
hash & (数组长度-1)
注意:等价运算有个要求,数组长度必须是2的n次方

8.索引计算为何要进行二次hash的结果计算索引
①将hash的分布更均匀
将添加的元素,更能平均的分配到hash表中;
不至于某些桶中元素过多;
9.HashMap数组长度为何是2的n次幂
①、计算索引的时候,可以不用取模运算,采用位运算提高效率
②、扩容的时候hash & 原始容量=0的时候留在源位置,否则新位置=原始位置+原始容量
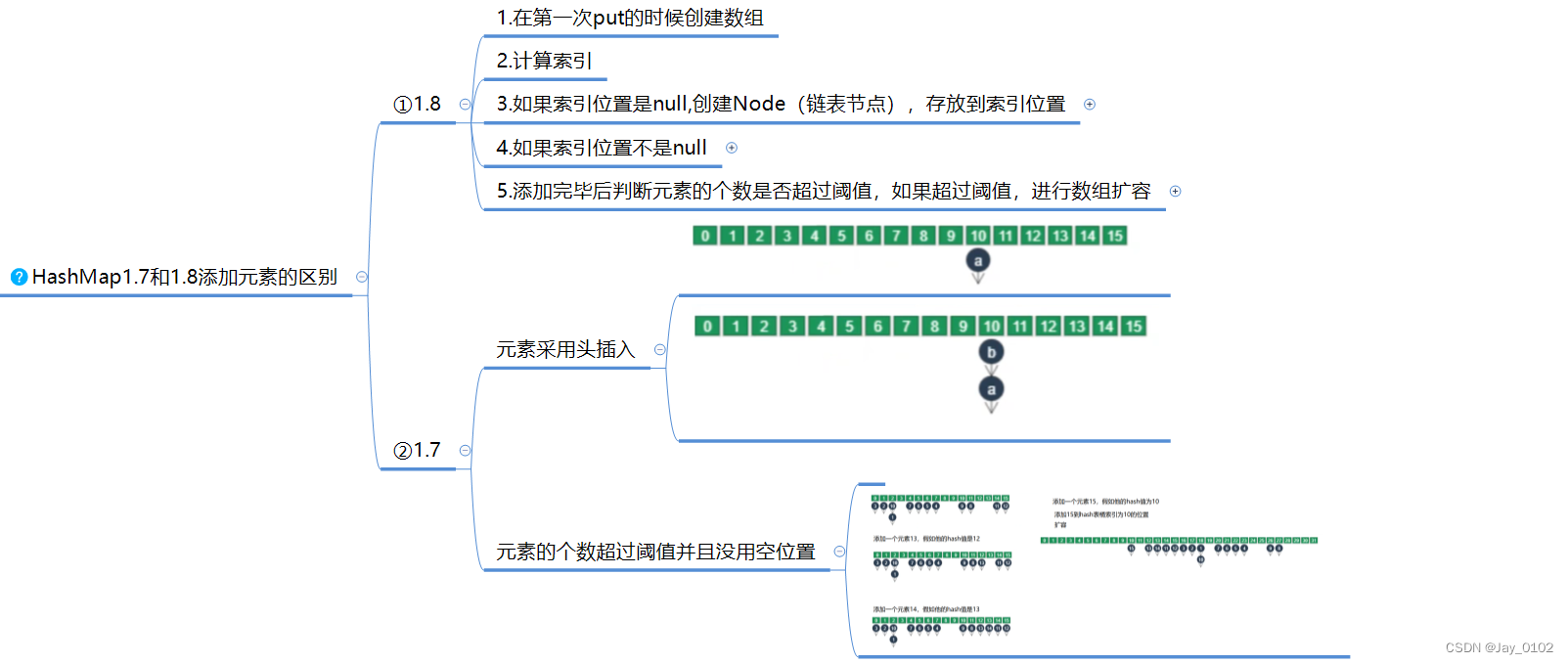
10.HashMap1.7和1.8添加元素的区别
①1.8
1.在第一次put的时候创建数组
2.计算索引
3.如果索引位置是null,创建Node(链表节点),存放到索引位置
4.如果索引位置不是null
如果是TreeNode,走红黑树添加的逻辑
如果是Node,走链表添加的逻辑,如果链表长度超过8,走树化逻辑
5.添加完毕后判断元素的个数是否超过阈值,如果超过阈值,进行数组扩容
②1.7
元素采用头插入
元素的个数超过阈值并且没用空位置
11.扩容因子为何是0.75
①大于该值节省空间,但是链表长度可能会比较长
②小于该值,扩容比较频繁,占用内存空间较大
12.多线程下操作hashMap会引发什么问题
①1.8 数据丢失
后面添加的数据将前面添加的数据覆盖;
13.HashMap为什么要求key重写hashCode和equals方法
①重写的目标
2个对象equals,hashCode一定相同
2个对象hashCode相同不一定equals,
②为什么
Map要求Key不能相同;
提高判断对象是否相等的效率
③不重写或者重写其中一个
2个属性完全相同对象,但是引用不同的2个对象,也会存入HashMap
















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









