









ElasticSearch笔记
前言
本文原创博主为本人,csdn博客地址https://blog.csdn.net/Jay_Chou345,转载请注明出处
csdn博客地址
本文所有代码在gitee仓库中,地址:https://gitee.com/ifyyf/elasticsearch-study
gitee仓库地址
6.x和7.x的版本区别很大!本教程(看到狂神)用的ElasticSearch7.6.1
下载的路径切记不能有空格,不然后面会出现各种无法启动的bug
下载地址
本教程讲解什么
以前我们使用sql的like模糊查询,如果数据量很大时效率很低,时间很慢
如果使用索引,效率也不足够,且%在索引前会失效
后通配 走索引
前通配 走全表
所以需要ElasticSearch,本质就是:全文检索
ELK:ElasticSearch——Logstash——Kibana
ElasticSearch负责数据的挖掘检索
Logstash采集日志数据
Kibana负责可视化分析数据
如果需要使用复杂的搜索时,在mysql中很难实现,而es中则很简单(在大数据量的情况下使用)
ES的概述
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene
ES的安装
最低要求jdk1.8
ES客户端、界面工具Kibana
对应版本的maven依赖
SpringBoot默认的版本较低,需要手动调设版本
解压就可使用了
- 因为es默认启动内存为1G甚至更高,配置不足时需要去config文件夹中的jvm.options修改-Xms256m和-Xmx256m(有些服务器可能内存只有1G,根据实际修改即可)
- config文件夹中的elasticsearch.yml文件中可以看见默认端口为9200,也可以自定义修改
es的启动
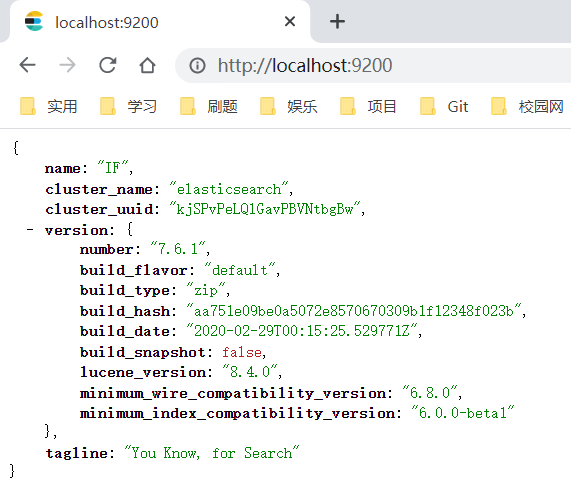
进入bin目录启动elasticsearch.bat即可开启服务,出现cmd并访问localhost:9200看见json返回证明成功
es-head插件是什么
ElasticSearch-head就是一款能连接ElasticSearch搜索引擎,并提供可视化的操作页面对ElasticSearch搜索引擎进行各种设置和数据检索功能的管理插件
需要node.js环境
下载
下载慢的话可以clone我导入的gitee仓库
安装
- git 拉取项目
- 进入目录
- npm install
- npm run start
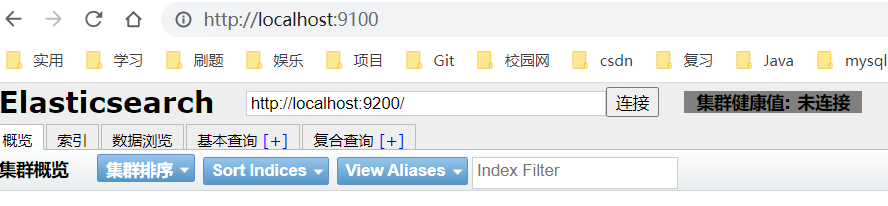
如果和我一样出现Fatal error: Port 9100 is already in use by another process.是表示默认的9100端口被占用了
在cmd中输入netstat -aon|findstr "9100"查看占用9100端口的pid
我这是PID为5536占用了

那输入tasklist|findstr "5536"

可以看见被lghub_updater.exe进程占用了
我们可以手动输入taskkill /T /F /PID 5536关闭进程,但是我这罗技的更新服务又自动启动了
所以我去服务里把更新服务给停止了
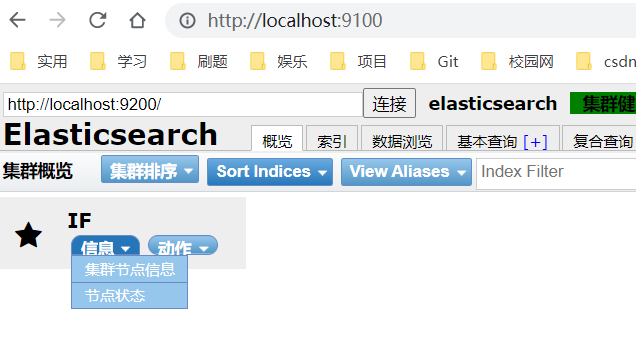
然后再启动es-head,访问http://localhost:9100成功启动
但是连接es时,控制台报跨域错误
Failed to load resource: net::ERR_FAILED
localhost/:1 Access to XMLHttpRequest at ‘http://localhost:9200/_nodes’ from origin ‘http://localhost:9100’ has been blocked by CORS policy: Response to preflight request doesn’t pass access control check: No ‘Access-Control-Allow-Origin’ header is present on the requested resource.
这时我们去es的config文件夹下打开elasticsearch.yml配置跨域,最底下添加
http.cors.enabled: true
http.cors.allow-origin: "*"
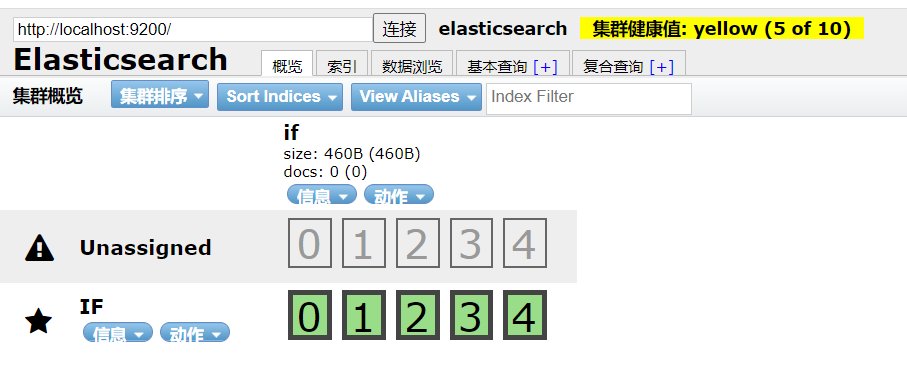
重启es服务,es-head连接es,连接成功
初学时我们可以把es理解为一个数据库( 可以建立索引(库),文档(库中的文件) )
此时建立一个索引
es-head就当成一个数据展示工具,虽然可以写查询,但是不方便,后面还是会使用kibana
kibana安装
直接下载解压,进入bin目录,双击kibana.bat文件启动,默认端口5601
此时访问es-head可以看见多了3个kibana自带的索引库

es有许多途径进行开发测试,例如postman、es-head等,也可以使用kibana测试
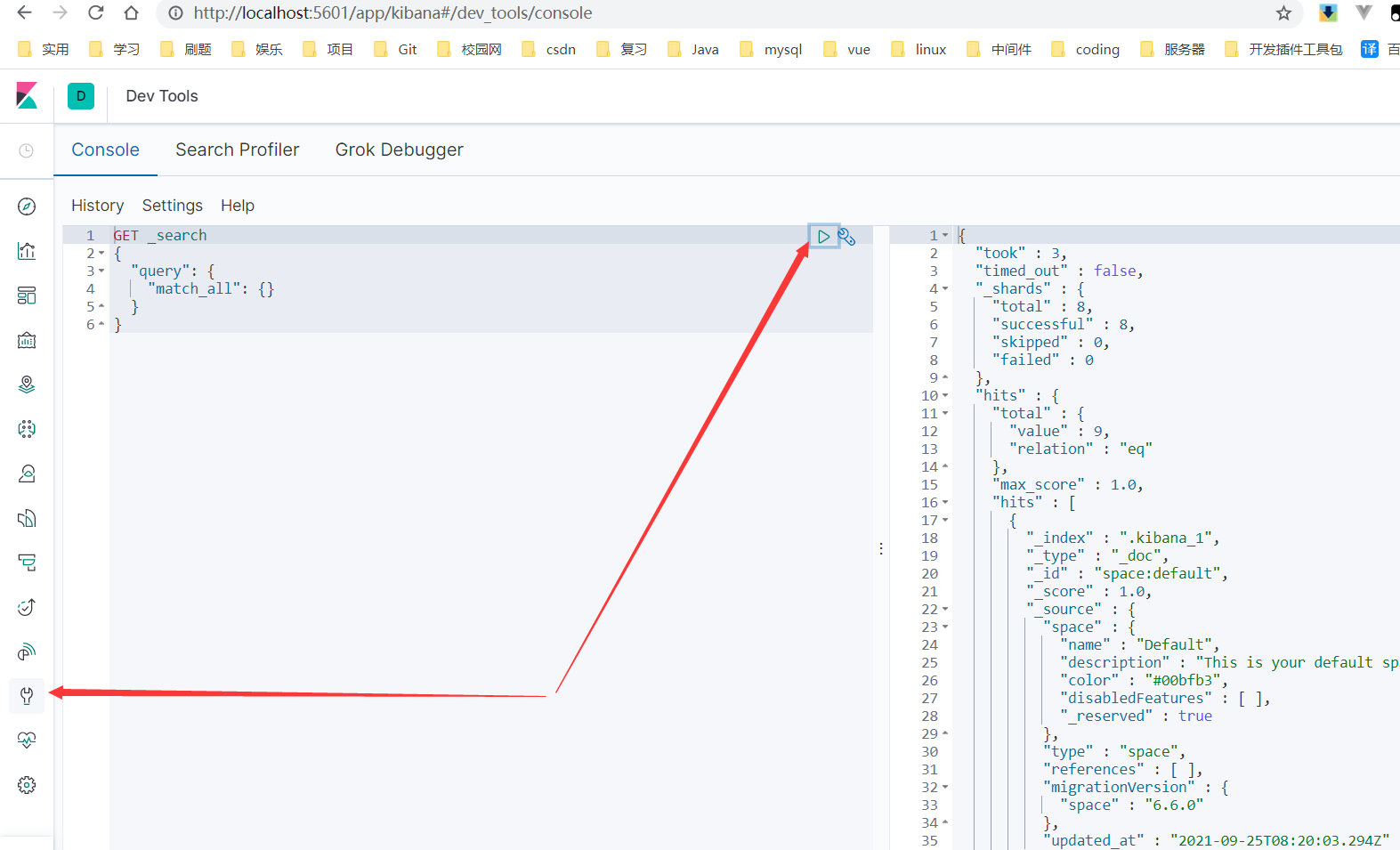
汉化kibana
进入config文件夹,打开kibana.yml文件
最后一行加上i18n.locale: "zh-CN",重启项目,汉化完成
ES的核心概念
elasticsearch面向文档Document,一切都是json
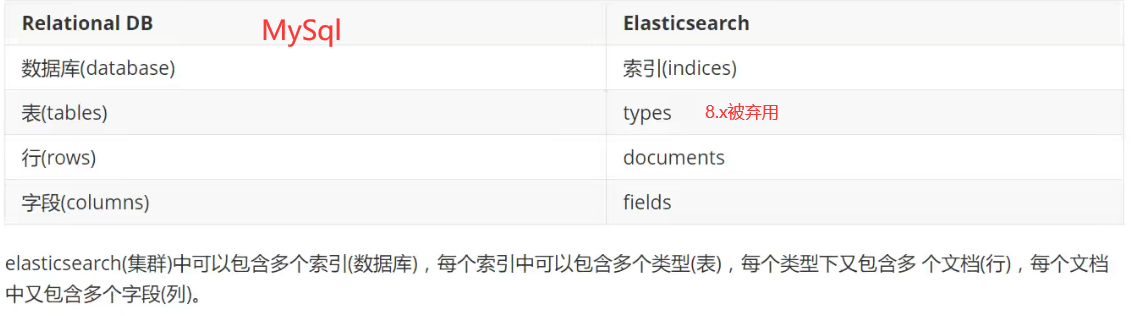
物理设计
一个人就是一个集群,在后台把每个索引划分成了多片,每个分片可以在不同的服务器间迁移
之前说到es面向文档,那么意味着索引和搜索数据的最小单位就是文档
文档有几个重要属性:
- 自我包含:键值对,key:value
- 层次型的,{就是一个json对象,java可以用fastjson自动生成}
- 灵活结构:在关系型数据库中需要先定义好字段等结构,而es不需要按照,有时候可以忽略字段或者动态生成字段
但是因为数据类型不同,所以为了安全性,还是提前定义好字段再进行使用
之前说到,es是集群,而一个集群中至少有1个节点,一个节点可以有多个索引,创建索引时,默认会创造5个分片,而主分片和复制分片并不会在同一个节点上,这样有利于一个节点挂了,另一个节点还在,那数据还在
实际上,一个分片就是一个Lucene索引,一个包含倒排索引的文件目录
也就是一个es索引是由多个Lucene索引组成
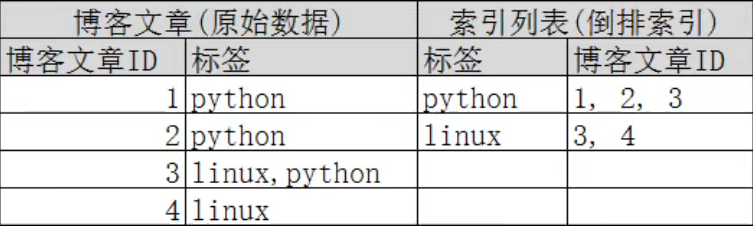
es使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层,这种结构适合快速的全文搜索
一个索引由文档中所有不重复的列表组成,对于每一个词都有包含它的一个文档列表
即:将所有文档拆分成一个个独立的单词(称之为词条或者tokens),然后根据这些词条创建一个了包含了所有词条与之对应的文档且不重复的排序列表
当进行搜索时,会根据词条匹配到对应的文档,当匹配度越高的文档,权重越高,即score越高
IK分词器插件
什么是分词器
分词:即把一-段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行-个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神”会被分为"我",“爱”,“狂”,“神” ,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
如果要使用中文,建议使用IK分词器
IK提供了两个分词算法:ik_smart和ik_max_word,前者为最少切分(只切分一次),后者为最细粒度切分
下载
下载慢的可以去我的gitee下载
下载后放入es的插件文件夹plugins即可
版本要和es对应,因为我的es是7.6.1的,所以ik也是这个版本
[2021-10-02T19:24:40,696][INFO ][o.e.p.PluginsService ] [IF] loaded plugin [analysis-ik]
重新启动运行es,显示这句话证明已经解析插件成功
可以使用elasticsearch-plugin list命令,查看es的插件

ik_max_word和ik_smart 区别
- ik_smart:分词的时候只分一次,句子里面的每个字只会出现一次
例子
GET _analyze
{
“analyzer”: “ik_smart”,
“text”: “中国国歌”
}结果
{
“tokens” : [
{
“token” : “中国国歌”,
“start_offset” : 0,
“end_offset” : 4,
“type” : “CN_WORD”,
“position” : 0
}
]
}
- ik_max_word:句子的字可以反复出现。 只要在词库里面出现过的就拆分出来。如果没有出现的单字。如果已经在词里面出现过,那么这个就不会以单字的形势出现。
例子
GET _analyze
{
“analyzer”: “ik_max_word”,
“text”: “中国国歌”
}结果
{
“tokens” : [
{
“token” : “中国国歌”,
“start_offset” : 0,
“end_offset” : 4,
“type” : “CN_WORD”,
“position” : 0
},
{
“token” : “中国”,
“start_offset” : 0,
“end_offset” : 2,
“type” : “CN_WORD”,
“position” : 1
},
{
“token” : “国歌”,
“start_offset” : 2,
“end_offset” : 4,
“type” : “CN_WORD”,
“position” : 2
}
]
}
可是现在有一个问题,就是我请求的文本为自创的,例如我在看狂神说,这个狂神说是自创词语,字典中识别不出,所以会拆分成“狂”,“神”,“说”,可是这个结果不是我们想看到的
所以类似于这种自创词语,需要我们自己添加到字典
添加IK分词器自定义字典
elasticsearch-7.6.1\plugins\ik-7.6.1\config路径下
- 创建
kuang.dic文件,此文件就是自定义的字典 - 找到
IKAnalyzer.cfg.xml文件,配置修改成<entry key="ext_dict">kuang.dic</entry> - 重启es
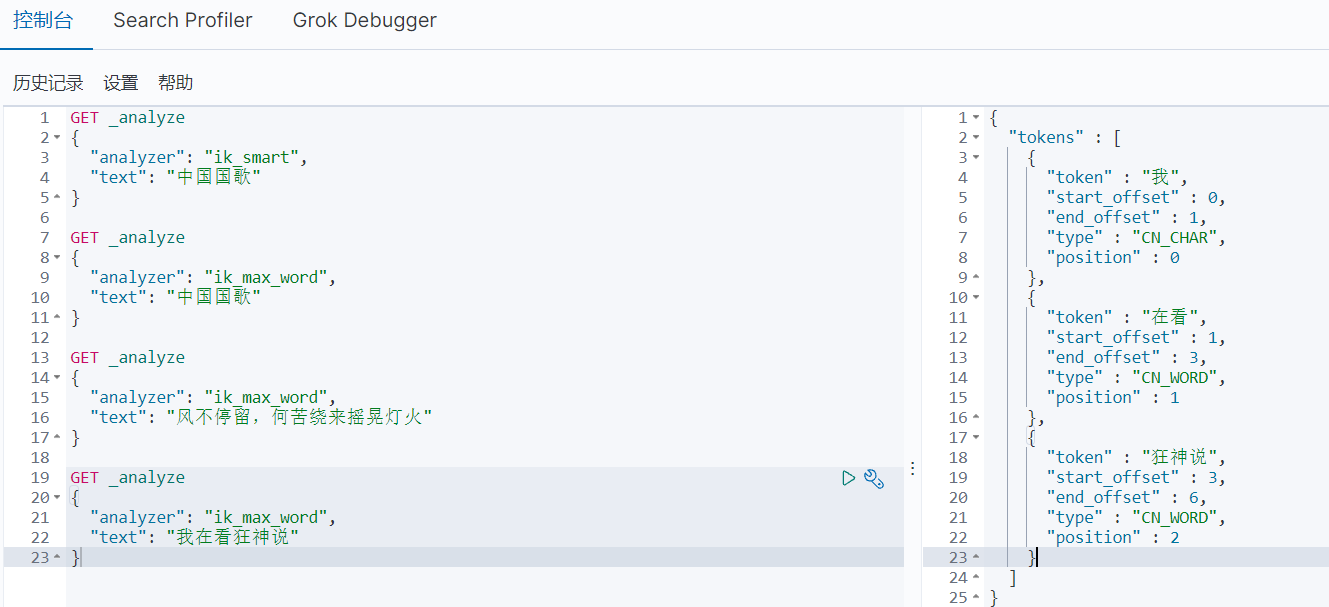
此时可以看见狂神说没有被拆分了
REST风格
旧版方法表格
一种软件架构风格 ,而不是标准,只是提供了- -组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
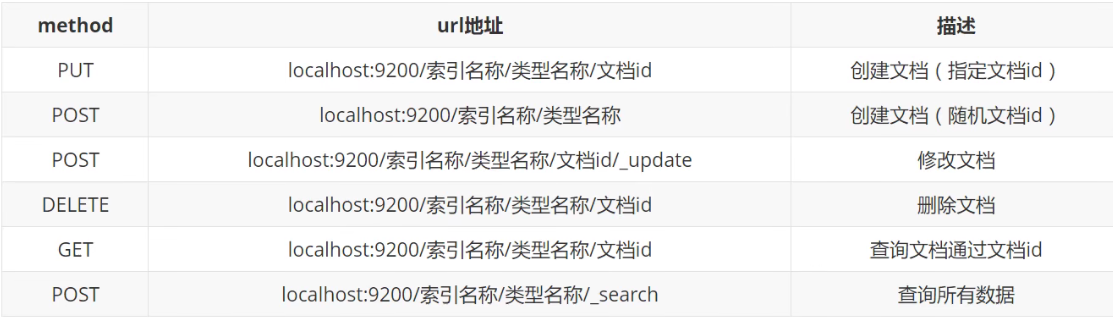
注:现在使用不需要加类型名称了,但是基本上还是需要加上默认的_doc
以下是新版url表格
es的基础使用
新版方法表格
| method | url地址 | 描述 | 作用 |
|---|---|---|---|
| PUT | localhost:9200/索引/_doc/id | 创建文档(指定id) | 增 |
| POST | localhost:9200/索引/_doc | 创建文档(随机id) | 增 |
| POST | localhost:9200/索引/_update/id | 修改文档 | 改 |
| DELETE | localhost:9200/索引/_doc/id | 删除文档 | 删 |
| GET | localhost:9200/索引/_doc/id | 根据id查询文档 | 查 |
| POST/GET | localhost:9200/索引/_search | 条件查询文档 | 查 |
_search为空参数时默认查询所有
基础测试
创建索引并插入文档数据
类似于/库名/表名/id格式
类型名为_doc时是默认
如果没有指定索引里字段的类型,则es会自动分配类型
PUT /索引名/类型名/文档id
{
json请求体
}
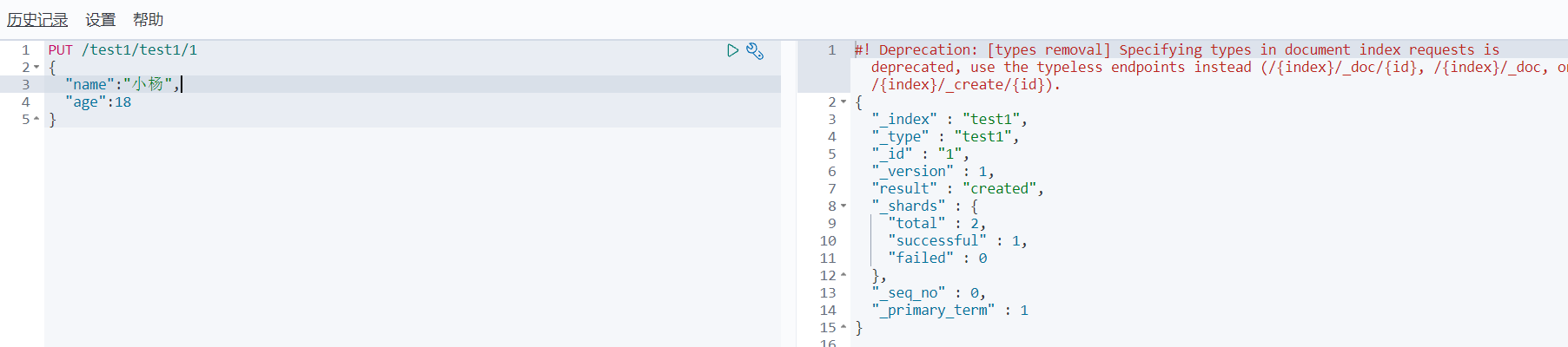
如果请求超时了需要修改kibana配置elasticsearch.requestTimeout: 90000
请求完成后可以去es-head中查看
完成了索引的创建,也同时完成了数据的插入
==注:==也可以使用POST,id是随机的(类似于I6V8QXwBpnE32i3joaCR的乱码)
POST /test1/_doc
{
“name”:“test”,
“age”:10
}
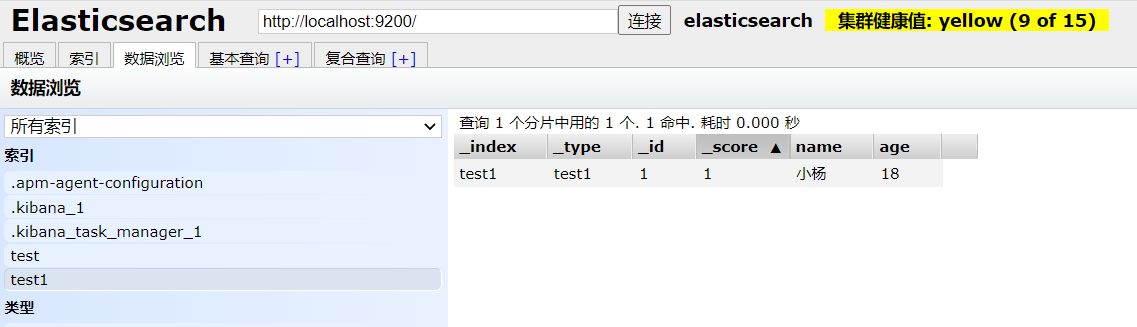
创建指定类型的索引
如果我们想要创建索引的时候,指定type中字段的类型呢?
PUT /test2
{
“mappings”: {
“properties”: {
“name”:{ //name字段
“type”: “text” //text类型
},
“age”:{ //age字段
“type”: “integer” //integer类型
},
“birthday”:{ //birthday字段
“type”: “date” //date类型
}
}
}
}

获取信息
通过GET请求获得索引具体的信息
GET test2
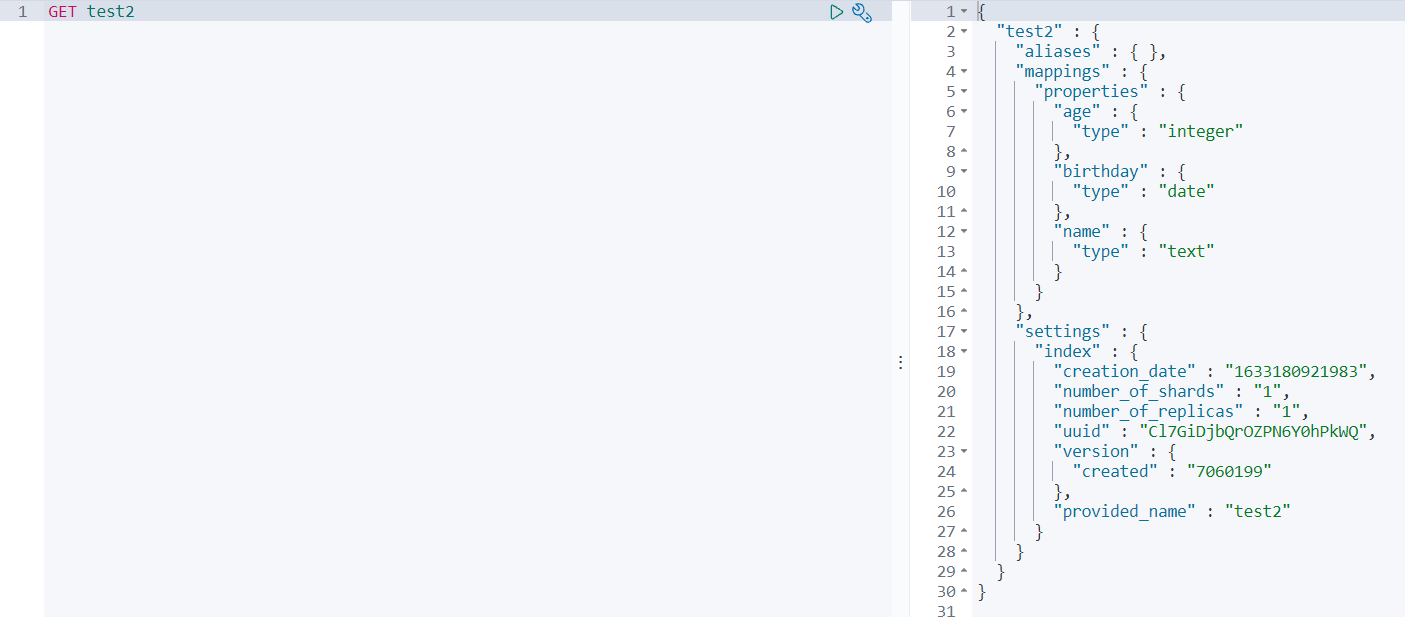
根据id值获取文档
GET /test1/_doc/1

####修改信息
旧版方法:直接使用put覆盖
和之前添加使用一样的格式即可
缺点:每个属性都要覆盖到,不然没覆盖到的属性会直接为空!
PUT /test1/_doc
{
“name”:“test”,
“age”:10
}
返回的数据中_version会自增(因为被修改了),version就代表被更新的次数,初始为1
result会从created变为updated
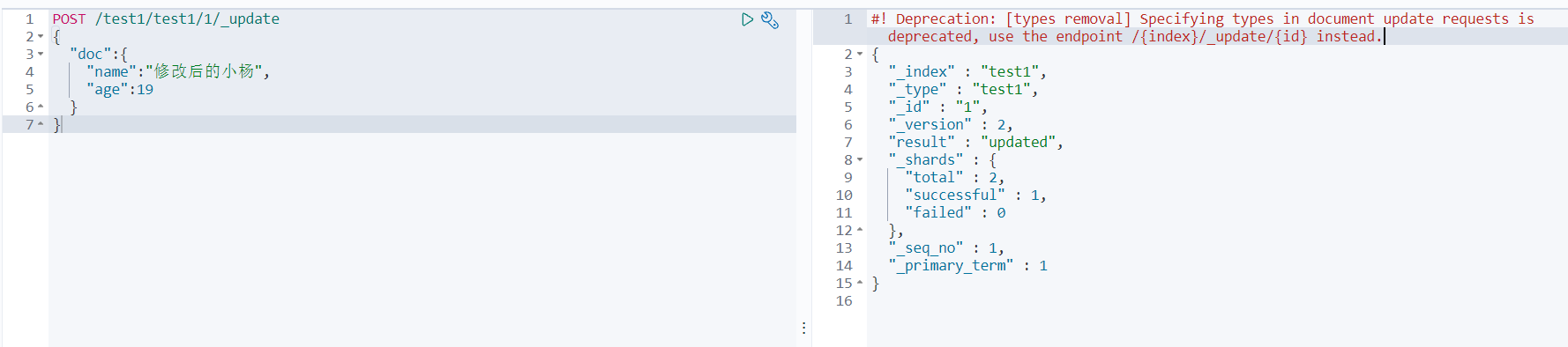
新版方法:使用POST
POST /test1/_update/1
{
“doc”:{
“name”:“修改后的小杨”,
“age”:19
}
}
优点:属性可以只写明需要修改的属性
删除
一律使用delete
DELETE test1 //表示删库
DELETE /test1/_doc/1 //表示删除某一文档
复杂一点的查询
单条件带参查询
之前是根据具体的id进行的查询
如果想模糊查询呢?
GET /test1/_search?q=name:小杨
则将带有小杨的查询出来
注意:
如果这个字段的类型是keyword话,默认是一个整体,一个单词
如果是text,就可以拆分读取
也可以采取带body参数格式
GET /test1/_search
{
“query”: {
“match”: {
“name”: “小”
}
}
}
返回的参数说明

结果过滤
但是现在默认返回的结果是包含了所有字段的,如果想要返回某几个字段的话,查询时使用_source参数
GET /test1/_search
{
“query”: {
“match”: {
“name”: “小杨”
}
},
“_source”: [“name”,“age”]
}
就可以让结果只显示name属性
注:之后在java中操作es时,这些key实际上都是对象或者方法
结果排序
使用sort参数对象
GET /test1/_search
{
“query”: {
“match”: {
“name”: “小杨”
}
},
“_source”: “age”,
“sort”: [
{
“age”: {
“order”: “desc”
}
}
]
}
↑上述方法表示
- 查询获取test1索引中
- name包括“小杨”
- 返回值仅为age字段
- 且根据"age"字段倒序排序的结果集
分页查询
如果我们只想查询出来一条或者两条结果呢?
使用from和size参数
GET /test1/_search
{
“from”: 0,
“size”: 1
}
- from表示从哪个数据开始,默认0开始
- size表示结果集大小,默认20,则最多返回20条数据
- 相当于limit
多条件查询
must(and),必须条件都满足时才会返回结果
where age=22 and name like '%小杨%'
GET /test1/_search
{
“query”: {
“bool”: {
“must”: [
{
“match”: {
“name”: “小杨”
}
},
{
“match”: {
“age”: “22”
}
}
]
}
}
}
should(or),满足其一即可
where age=22 or name like '%小杨%'
must_not(!=),不等于某个数据
where age!=22
GET /test1/_search
{
“query”: {
“bool”: {
“must_not”: [
{
“match”: {
“age”: “22”
}
}
]
}
}
}
filter过滤
GET /test1/_search
{
“query”: {
“bool”: {
“must_not”: [
{
“match”: {
“age”: “22”
}
}
],
“filter”: {
“range”: {
“age”: {
“gt”: 10,
“lte”: 20
}
}
}
}
}
}
其中在range中,键值对的key为age表示属性字段,value是一个对象,可以包含多个条件
- gt大于
- gte大于且等于
- lt小于
- lte小于且等于
空格多条件查询
如果使用上面的方法会过于繁琐,可以直接在查询的值中用空格分隔表示多条件
GET /test1/_search
{
“query”: {
“match”: {
“name”: “小杨 test”
}
}
}
则会将name中含有小杨或者test的结果返回
也就是说空格多条件查询时是or的方式
当满足条件越多,score权重越高
精确查询
term查询是直接通过倒排索引指定的词条进程精确查询的
所以term效率比match高
但是要注意:term不兼容中文!!!
准确来说并不是无法生效,而是没有查询出数据。首先说一下对于term查询的语义:
term query会去倒排索弓|中寻找确切的term,它并不知道分词器的存在。这种查询适合keyword、numeric. date.
term表示查询某个字段里含有某个关键词的文档,terms表示查询某个字段里合有多个关键词的文档注意:查询某个字段里含有某个关键词的文档,这句话就说明了直接对字段进行term查询实际上还是模糊搜索,区别只不过是不会对搜索的输入字符串进行分词处理而已。如果想通过term查询到数据,那么term查询的字段在索引库中就必须有与term查询条件相同的索引词,否则就是无法查询到结果的。
GET /test1/_search
{
“query”: {
“term”: {
“name”: “小杨”
}
}
}
可以看见,此时没有一条是name只有小杨的结果,所以结果集为空
关于分词
- term:只查询精确的
- match:使用分词器进行解析(先分析文档,再通过分析的文档进行查询)
两个类型text和keyword
- text:自动分词
- keyword:不分词,走term才能精确查询
注:如果是text走term查询时,一样按模糊查询算
结果高亮
highlight可以让搜索出来的结果中包含的关键词用html标签修饰
GET /test1/_search
{
“query”: {
“term”: {
“name”: “test”
}
},
“highlight”: {
“fields”: {
“name”:{}
}
}
}
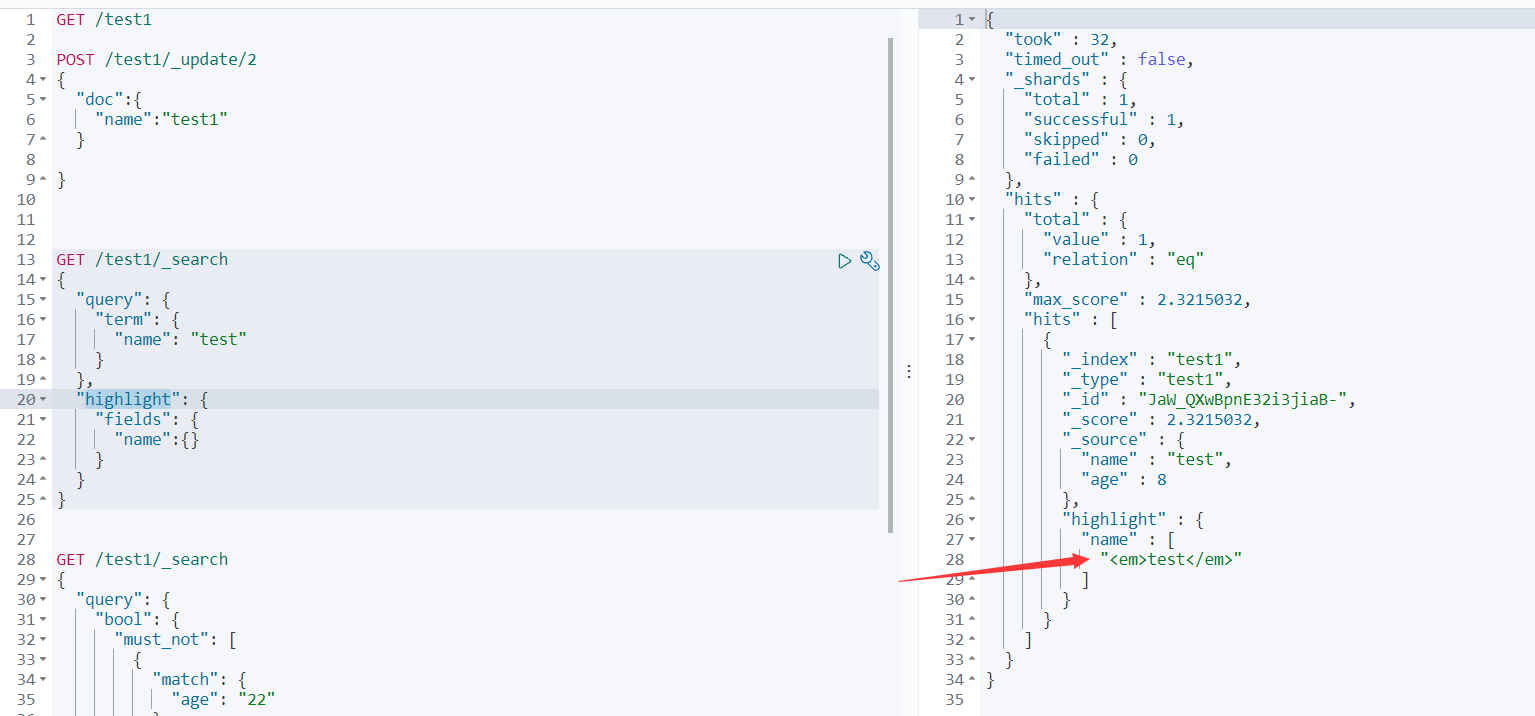
肯定有人会问:这也没高亮呀!
所以我们可以自定义标签内容
“highlight”: {
“pre_tags”: “”,
”,
“post_tags”: “
“fields”: {
“name”:{}
}
}
注:在java代码中也是这么写
springboot集成es
导入依赖
注:我们使用的es的高级客户端依赖elasticsearch-rest-high-level-client
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.1</version>
</dependency>
创建springboot项目
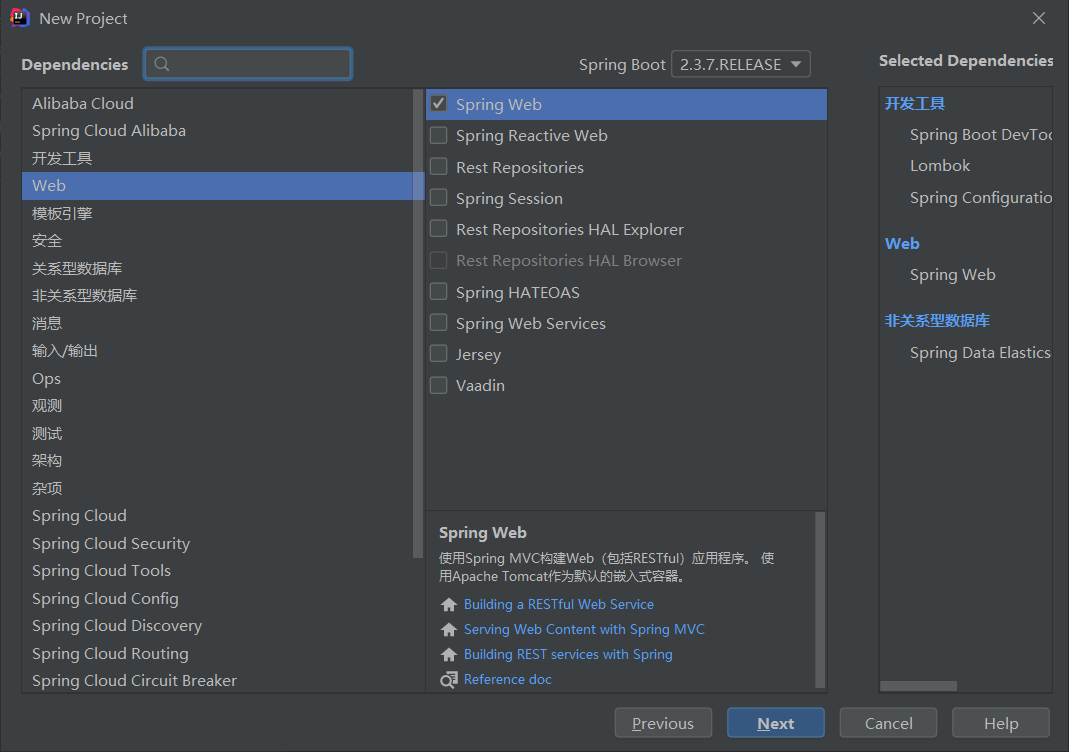
注意,这里我们勾选了springboot默认集成的es
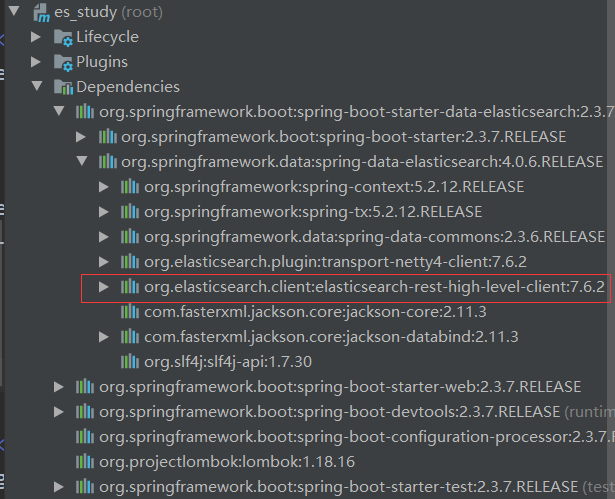
然后maven依赖中其实包含了上文讲到的高版本客户端依赖,但是版本可能和我们实际使用的版本对不上
一定保证导入的依赖和使用的版本一致
寻找对象
通过构建RestHighLevelClient对象,调用api方法(最后client要close)
其实这个client就相当于kabana,只不过kabana使用命令行操作,比较麻烦
java调用api,会容易操作一些
注入RestHighLevelClient到spring容器
如果改了名称的话,可以用@Qualifier(“restHighLevelClient”)注解去指定bean的方法
@Autowired
private RestHighLevelClient restHighLevelClient;
索引api操作
总结
- 对索引的操作全都是获取
xxxIndexRequest - 然后传入
restHighLevelClient.indices()得到的IndicesClient索引客户端 - 索引结果的查看都是
isAcknowledged()
添加索引
/**
* 创建索引
* @throws IOException
*/
@Test
void creatIndex() throws IOException {
//1.创建一个索引客户端
IndicesClient indicesClient = restHighLevelClient.indices();
//2.创建一个creat索引请求
CreateIndexRequest request=new CreateIndexRequest("api_index");
//3.传递request和默认选项进行调用,并得到response响应
CreateIndexResponse createIndexResponse = indicesClient.create(request, RequestOptions.DEFAULT);
//4.判断是否创建成功createIndexResponse.isAcknowledged()被确认
System.out.println(createIndexResponse.isAcknowledged());
}
获取索引
判断索引是否存在
/**
* 获取索引,判断是否存在
*/
@Test
void getIndex() throws IOException {
//1.创建一个索引客户端
IndicesClient indicesClient = restHighLevelClient.indices();
//2.创建一个get索引请求
GetIndexRequest getIndexRequest=new GetIndexRequest("api_index");
//3.判断索引是否存在
System.out.println(indicesClient.exists(getIndexRequest, RequestOptions.DEFAULT));
}
删除索引
/**
* 删除索引
*/
@Test
void deleteIndex() throws IOException {
//1.创建索引客户端
IndicesClient indicesClient = restHighLevelClient.indices();
//2.创建一个delete索引请求
DeleteIndexRequest deleteIndexRequest=new DeleteIndexRequest("api_index");
//3.执行删除请求,得到AcknowledgedResponse响应
AcknowledgedResponse response = indicesClient.delete(deleteIndexRequest, RequestOptions.DEFAULT);
//4.判断是否删除成功response.isAcknowledged()被确认
System.out.println(response.isAcknowledged());
}
文档api操作
总结
- 文档的操作都是创建
xxxRequest - 然后直接使用
restHighLevelClient高级客户端进行index、get、update等操作 - 文档返回的结果查看都是
status()方法
添加文档
/**
* 添加文档
* 将实体类转json传入request
* @throws IOException
*/
@Test
void addDocument() throws IOException {
//1.创建实体类对象
User user=new User("if",18);
//2.获取index请求(连接数据库)
IndexRequest indexRequest=new IndexRequest("api_index");
//3.规则:PUT /api_index/_doc/1
//设置id为1
indexRequest.id("1")
//过期时间默认是1s
.timeout("1s")
//用fastjson将实体类转json
.source(JSON.toJSONString(user), XContentType.JSON);
//4.直接使用restHighLevelClient.index传入request调用
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
//5.返回结果(有"total":2,"successful":1,"failed":0之类的信息)
System.out.println(indexResponse.toString());
//6.此时响应状态为CREATED(如果是更新就是UPDATE)
System.out.println(indexResponse.status());
}
判断文档是否存在
/**
* 根据id判断文档是否存在
* @throws IOException
*/
@Test
void isExistDocument() throws IOException {
//1.指定索引和id
GetRequest getRequest=new GetRequest("api_index","1");
//2.查询是否存在此id的文档
System.out.println(restHighLevelClient.exists(getRequest,RequestOptions.DEFAULT));
}
获取文档信息
/**
* 根据id获取文档信息
* @throws IOException
*/
@Test
void getDocument() throws IOException {
//1.指定索引和id
GetRequest getRequest=new GetRequest("api_index","1");
//2.传入getRequest获得响应
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//3.查看文档全部信息
System.out.println(getResponse.toString());
//4.得到具体信息
//索引库
System.out.println("getResponse.getIndex() = "+getResponse.getIndex());
//文档id
System.out.println("getResponse.getId() = "+getResponse.getId());
//json格式的String形式实体类信息
System.out.println("getResponse.getSourceAsString() = "+getResponse.getSourceAsString());
//Map形式实体类信息
Map<String, Object> source = getResponse.getSource();
for (String s : source.keySet()) {
System.out.println(s+" : "+source.get(s));
}
}
更新文档
/**
* 根据id更新文档
* 使用updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
*/
@Test
void updateDocument() throws IOException {
//1.获取updateRequest
UpdateRequest updateRequest=new UpdateRequest("api_index","1");
//2.创建实体类
User user=new User("修改后的if",16);
//3.封装updateRequest
updateRequest.timeout("1s")
//因为put更新时需要用到doc参数
.doc(JSON.toJSONString(user),XContentType.JSON);
//4.放入客户端执行
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
//5.查看结果OK
System.out.println(updateResponse.status());
}
删除文档
/**
* 根据id删除文档
* @throws IOException
*/
@Test
void deleteDocument() throws IOException {
//1.获取deleteRequest
DeleteRequest deleteRequest=new DeleteRequest("api_index","1");
//2.传入restHighLevelClient客户端
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
//3.查看响应结果
System.out.println(deleteResponse.status());
}
循环处理数据
以循环插入为例
使用BulkRequest,然后循环添加各种类型的request,最后一次性提交到restHighLevelClient.bulk
/**
* 批量处理数据(本质上还是循环)
*/
@Test
void batchInsertDocument() throws IOException {
//1.创建BulkRequest
BulkRequest bulkRequest=new BulkRequest();
bulkRequest.timeout("10s");
//2.创建大量数据List
List<User> userList=new ArrayList<>();
for(int i=0;i<5;i++){
userList.add(new User(""+i,i*10));
}
//3.循环add进入bulkRequest
for(int i=0;i<5;i++){
bulkRequest.add(
new IndexRequest("api_index")
.id(""+i)
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
//4.提交一次(可能就不需要循环提交了,效率就高一点点了)
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
//5.查看状态和是否失败
System.out.println(bulkResponse.status()+"-"+bulkResponse.hasFailures());
}
条件查询
- TermQueryBuilder参数封装到SearchSourceBuilder
- 再传入SearchRequest,提交到客户端restHighLevelClient
- 返回SearchResponse
- searchResponse.getHits().getHits()是具体数据,以Map<String, Object>形式返回
/**
* 条件查询
* TermQueryBuilder参数封装到SearchSourceBuilder
* 再传入SearchRequest,提交到客户端restHighLevelClient
* 返回SearchResponse
* searchResponse.getHits().getHits()是具体数据,以Map<String, Object>形式返回
* @throws IOException
*/
@Test
void search() throws IOException {
SearchRequest searchRequest=new SearchRequest("api_index");
//1.构建搜索条件类
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
//2.查询条件类,使用QueryBuilders
//3.QueryBuilders.termQuery()精确查询
//term不兼容中文!但是将查询字段后加上.keyword即可,例如name.keyword
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name.keyword", "小杨同学");
//4.QueryBuilders.matchAllQuery()匹配所有
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
//5.提交查询条件进行构建
searchSourceBuilder.query(termQueryBuilder)
//6.设置60秒超时
.timeout(new TimeValue(60, TimeUnit.SECONDS));
//7.将builder提交到request
searchRequest.source(searchSourceBuilder);
//8.将请求提交到client获得结果
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//9.获得结果转为json
SearchHits searchHits = searchResponse.getHits();
System.out.println(JSON.toJSONString(searchHits));
//10.得到具体数据
for (SearchHit hitsHit : searchHits.getHits()) {
Map<String, Object> map = hitsHit.getSourceAsMap();
System.out.println(map);
}
}
实战:京东搜索
爬取数据:获取页面的数据,然后筛选出我们需要的数据
jsoup包
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
爬取前的准备
查看京东页面元素,通过解析dom对象拿到具体值
创建工具类HtmlParseUtil
package com.ifyyf.es_study.utils;
import com.ifyyf.es_study.pojo.Content;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
/**
* @Author if
* @Description: What is it
* @Date 2021-10-14 下午 08:00
*/
public class HtmlParseUtil {
public static List<Content> searchJd(String keys) throws IOException {
//获取请求地址 https://search.jd.com/Search?enc=utf-8&keyword=java
String url="https://search.jd.com/Search?enc=utf-8&keyword="+keys;
//解析网页,document返回的就是js的dom对象
//所有js中能使用的dom对象的方法,这个对象都能使用
Document document = Jsoup.parse(new URL(url), 30000);
Element jGoodsList = document.getElementById("J_goodsList");
// System.out.println(jGoodsList);
//获取到所有的li标签元素
Elements li = jGoodsList.getElementsByTag("li");
List<Content> list=new ArrayList<>();
for (Element element : li) {
//图片特别的多的网站为了响应速度,图片一般是懒加载的
String imgSrc = element.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = element.getElementsByClass("p-price").eq(0).text();
String title = element.getElementsByClass("p-name p-name-type-2").eq(0).text();
Content content=new Content(title,imgSrc,price);
list.add(content);
}
return list;
}
}
创建ContentService接口和其实现类ContentServiceImpl
通过BulkRequest类将jsoup解析的数据循环插入es中
package com.ifyyf.es_study.service;
/**
* @Author if
* @Description: What is it
* @Date 2021-10-14 下午 08:20
*/
public interface ContentService {
boolean batchInsertFromJd(String key);
}
package com.ifyyf.es_study.service.impl;
import com.alibaba.fastjson.JSON;
import com.ifyyf.es_study.pojo.Content;
import com.ifyyf.es_study.service.ContentService;
import com.ifyyf.es_study.utils.HtmlParseUtil;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @Author if
* @Description: What is it
* @Date 2021-10-14 下午 08:28
*/
@Service
public class ContentServiceImpl implements ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
@Override
public boolean batchInsertFromJd(String key) {
BulkRequest bulkRequest=new BulkRequest();
bulkRequest.timeout("3m");
try{
List<Content> contents = HtmlParseUtil.searchJd("java");
for(int i=0;i<contents.size();i++){
bulkRequest.add(new IndexRequest("jd_search")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulkResponse.hasFailures();
}catch(Exception e){
e.printStackTrace();
}
return false;
}
}
获得结果

模糊搜索
注意一下:from和size是和mysql默认的一样,表示从?开始查?条数据
但是我们的逻辑分页处理是查询第1页的5条数据,给的参数是from=1,size=5
所以我们处理要.from((from-1)*size)和.size(size),表示从第0条数据开始查5条
创建searchByKeyWord方法
@Override
public List<Map<String, Object>> searchByKeyWord(String key,int from,int size) throws IOException {
List<Map<String, Object>> result=new ArrayList<>();
SearchRequest searchRequest=new SearchRequest("jd_search");
SearchSourceBuilder searchSourceBuilder =new SearchSourceBuilder();
//因为中文在精确搜索时有问题,所以用的模糊matchQuery
MatchQueryBuilder termQueryBuilder = QueryBuilders.matchQuery("title",key);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS))
.query(termQueryBuilder)
.from((from-1)*size)
.size(size);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits().getHits()) {
result.add(hit.getSourceAsMap());
}
return result;
}
然后在Test测试类中
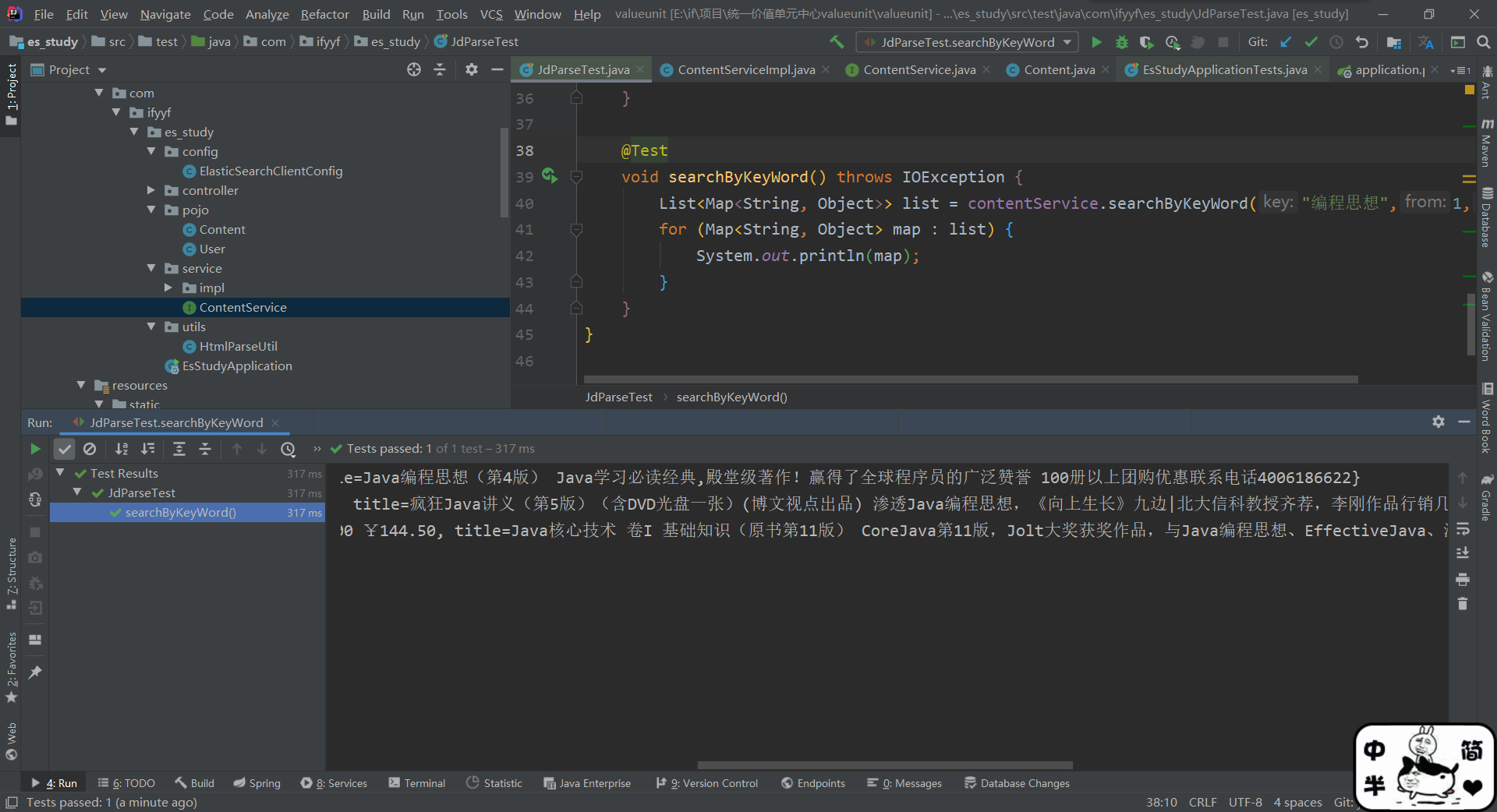
@Test
void searchByKeyWord() throws IOException {
List<Map<String, Object>> list = contentService.searchByKeyWord("编程思想",1,3);
for (Map<String, Object> map : list) {
System.out.println(map);
}
}
得到结果
调用controller
我们将service注入controller层,然后可以通过前端页面调用
这里为了方便就直接url调用了
创建ContentController接口
package com.ifyyf.es_study.controller;
import com.ifyyf.es_study.service.ContentService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
/**
* @Author if
* @Description: What is it
* @Date 2021-10-14 下午 08:19
*/
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/searchByKeyWord/{key}/{page}/{size}")
public List<Map<String,Object>> searchByKeyWord(@PathVariable String key,
@PathVariable int page,
@PathVariable int size) throws IOException {
return contentService.searchByKeyWord(key,page,size);
}
}
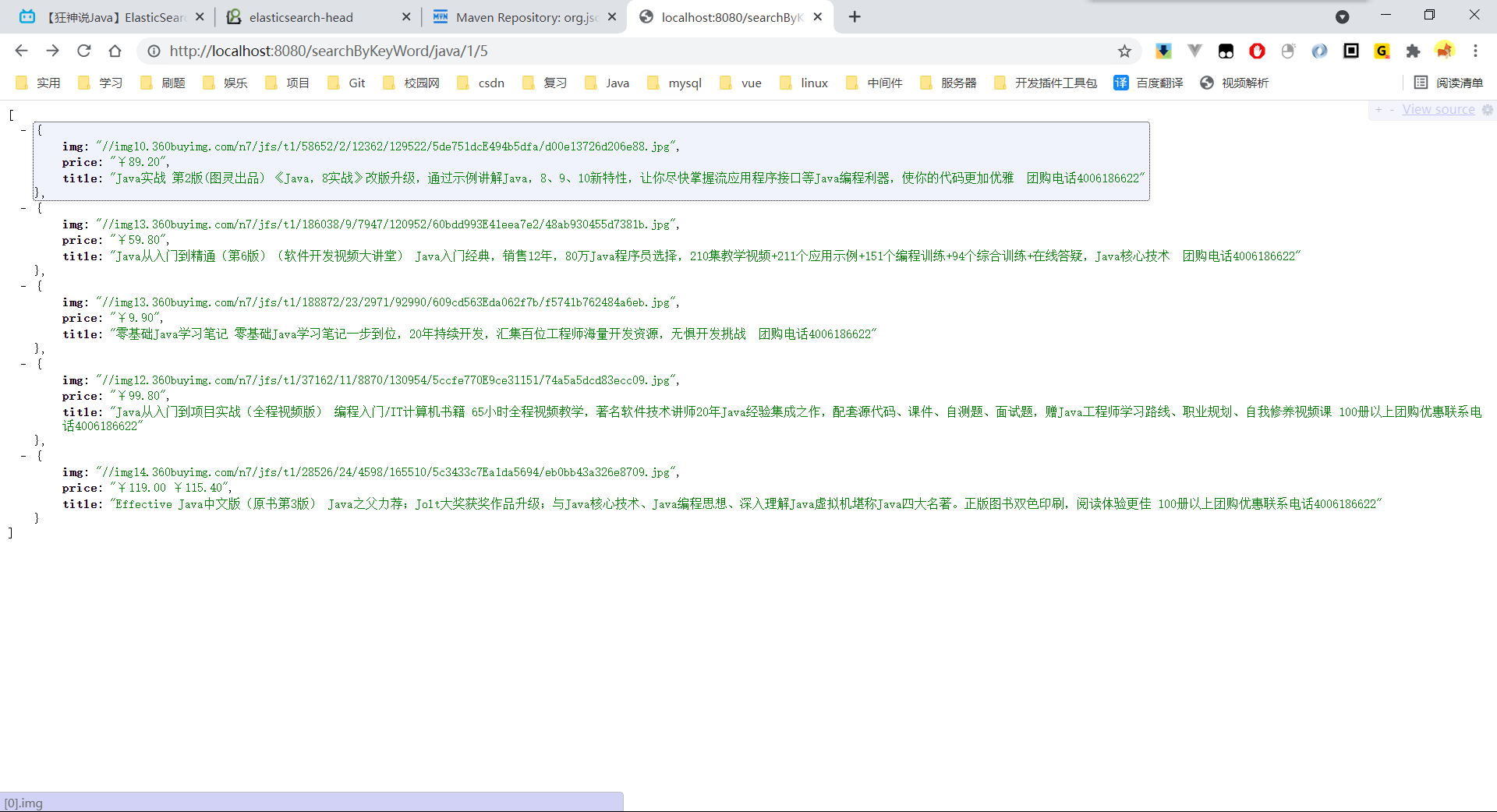
调用http://localhost:8080/searchByKeyWord/java/1/5
获取普通数据
结果高亮
searchHighLight方法
@Override
public List<Map<String, Object>> searchHighLight(String key,int from,int size) throws IOException {
List<Map<String, Object>> result=new ArrayList<>();
SearchRequest searchRequest=new SearchRequest("jd_search");
SearchSourceBuilder searchSourceBuilder =new SearchSourceBuilder();
//因为中文在精确搜索时有问题,所以用的模糊matchQuery
MatchQueryBuilder termQueryBuilder = QueryBuilders.matchQuery("title",key);
//高亮构造器
HighlightBuilder highlightBuilder=new HighlightBuilder();
//是否需要多个参数高亮
highlightBuilder.requireFieldMatch(false);
//设置高亮字段
highlightBuilder.field("title");
//前标签
highlightBuilder.preTags("<strong class='high-light' style='color:red'>");
//后标签闭合
highlightBuilder.postTags("</strong>");
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS))
.query(termQueryBuilder)
.from((from-1)*size)
.size(size)
.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
for (SearchHit hit : searchResponse.getHits().getHits()) {
//得到所有结果
Map<String, Object> source = hit.getSourceAsMap();
//获取高亮的字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField highlightField = highlightFields.get("title");
//解析高亮字段
if(highlightField!=null){
source.put(highlightField.getName(),highlightField.getFragments()[0].toString());
}
result.add(source);
}
return result;
}
因为直接获取的hit.getSourceAsMap()中是es中储存的普通字段,没有添加便签等元素
所以需要通过hit.getHighlightFields().get("title")获取到HighlightField对象
并将被替换了标签的内容highlightField.getFragments()[0].toString()放到map中去
即source.put(highlightField.getName(),highlightField.getFragments()[0].toString());
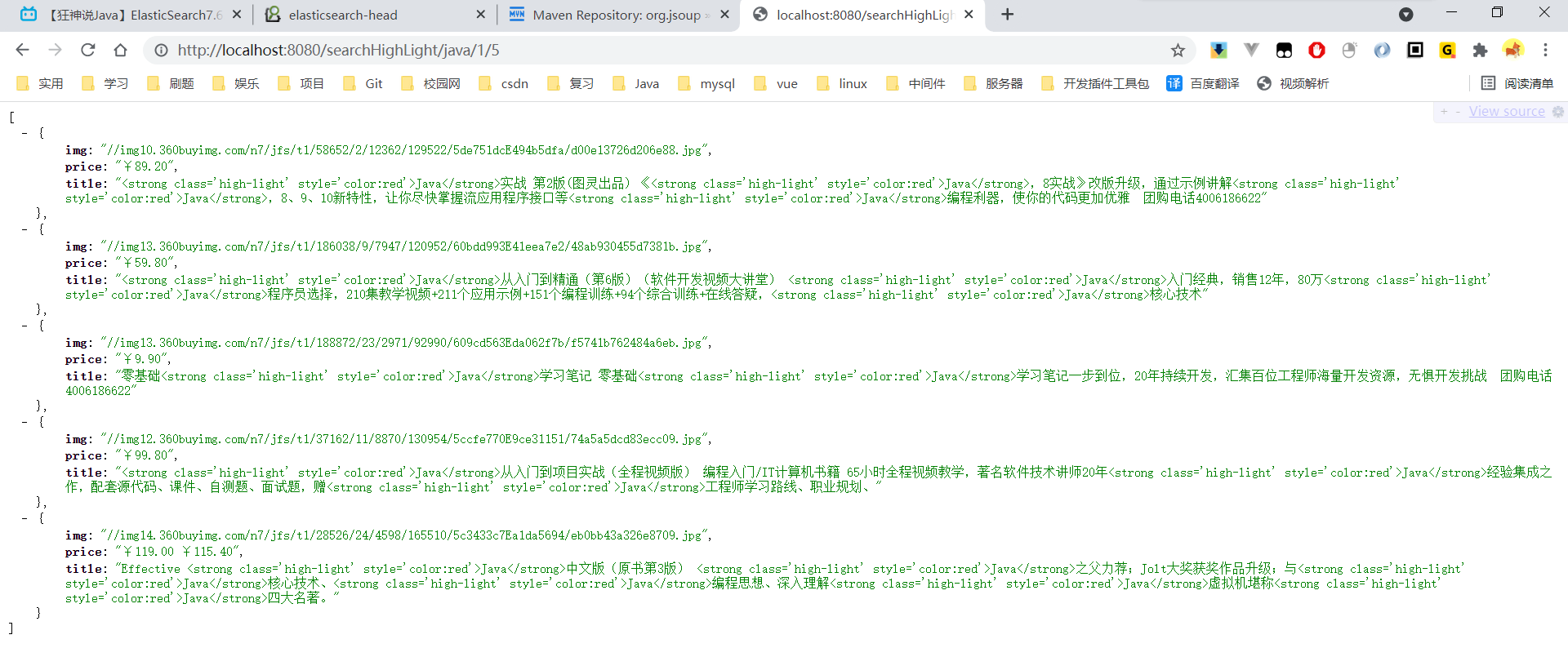
得到结果














 26万+
26万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









