






本文章将会创建一个streamlit模板,关于streamlit,请访问:
该模板可以访问MySql数据库,稍作更改后也可以访问其他数据库用于内容展示。
模板样式
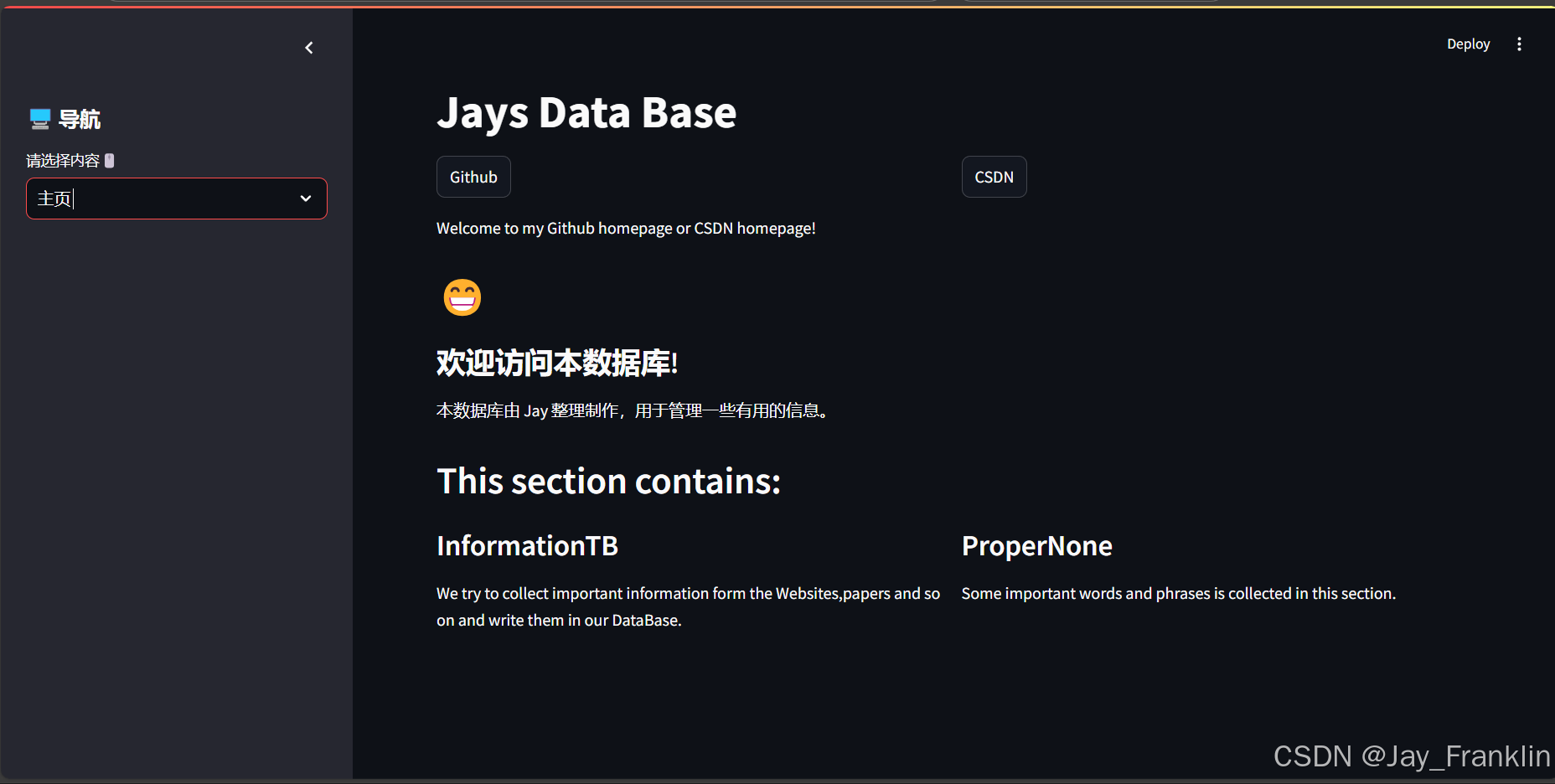
代码实现
为了代码清晰,文中使用两个py文件,主程序命名为app.py,具体页面放置在pages.py中,通过函数封装。
app.py
# app.py
import streamlit as st
import time
from pages import home_page,data_display_page,plot_page,information_tb
# 页面设置
st.set_page_config(
page_title="Jays Data Base",
page_icon="🖥️",
layout="wide",
initial_sidebar_state="expanded"
)
# 显示加载中的占位符
def display_loading(message="页面加载中..."):
with st.spinner(message):
time.sleep(1.5) # 模拟加载过程
#-----------------------------------------------
#以下为展示内容---
#-----------------------------------------------
# 边栏导航
st.sidebar.header("🖥️ 导航")
page = st.sidebar.selectbox("请选择内容🖱️", ["主页", "数据展示", "图形绘制",'信息展示'])
# 根据页面选择显示相应的内容
if page == "主页":
display_loading("主页加载中...")
home_page()
elif page == "数据展示":
data_display_page()
elif page == "图形绘制":
display_loading("绘图页面加载中...")
plot_page()
elif page == '信息展示':
display_loading("绘图页面加载中...")
information_tb()
#-----------------------------------------------
#以上为展示内容---
#-----------------------------------------------
# 自定义CSS样式
st.markdown("""
<style>
.css-18e3th9 {
font-size: 20px;
font-weight: 600;
}
.css-1aumxhk {
font-size: 18px;
}
.css-1q8dd3e {
font-size: 16px;
}
.css-10trblm {
padding: 20px;
}
</style>
""", unsafe_allow_html=True)pages.py
# pages.py
import pandas as pd
import plotly.express as px
import time
import streamlit as st
from sqlalchemy import create_engine
# 创建数据库引擎
def get_engine():
return create_engine('mysql+mysqlconnector://username:yourpassword@localhost/your database name')
# 显示加载中的占位符
def display_loading(message="页面加载中..."):
with st.spinner(message):
time.sleep(2) # 模拟加载过程
#-----------------------------------------------
#以上内容为如无特别需要无需修改(初始化时需要配置数据库)
#-----------------------------------------------
# 主页内容
def home_page():
st.markdown('# Jays Data Base')
col1, col2 = st.columns(2)
st.write('Welcome to my Github homepage or CSDN homepage!')
with col1:
st.link_button('Github',url='https://github.com/JaysDataBase') # 链接你的相关主页,这里的网址仅为示例网址
with col2:
st.link_button('CSDN',url='https://blog.csdn.net/JaysDataBase')
st.markdown('''
## 😁
### 欢迎访问本数据库!
本数据库由 Jay 整理制作,用于管理一些有用的信息。
## This section contains:
''')
col1, col2 = st.columns(2)#填入需要的列,使用with调用各列,如:
with col1:
st.markdown('### InformationTB')
st.write('We try to collect important information '
'form the Websites,papers and so on and write them in our DataBase.')
with col2:
st.markdown('### ProperNone')
st.write('Some important words and phrases is collected in this section.')
# 数据展示页面内容
def data_display_page():
st.markdown('''
# ⚛️ 数据
''')
table_names = ["table1", "table2", "table3"]
selected_table = st.selectbox("选择要显示的数据表:", table_names)
# 显示加载进度条
progress_bar = st.progress(0)
try:
# 创建 SQLAlchemy 引擎
engine = get_engine()
query = f"SELECT * FROM {selected_table}"
# 模拟加载过程,逐步更新进度条
for i in range(10):
time.sleep(0.1)
progress_bar.progress(i * 10)
# 读取数据到 DataFrame
df = pd.read_sql(query, engine)
# 显示行数和数据框
st.metric(label="💽本数据表包含的数据量为:", value=len(df))
st.markdown(f"## 以下是来自 `{selected_table}` 表的数据:")
st.dataframe(df)
except Exception as e:
st.error(f"发生错误: {e}")
progress_bar.empty()
st.success("数据加载完成!")
# 绘图页面内容
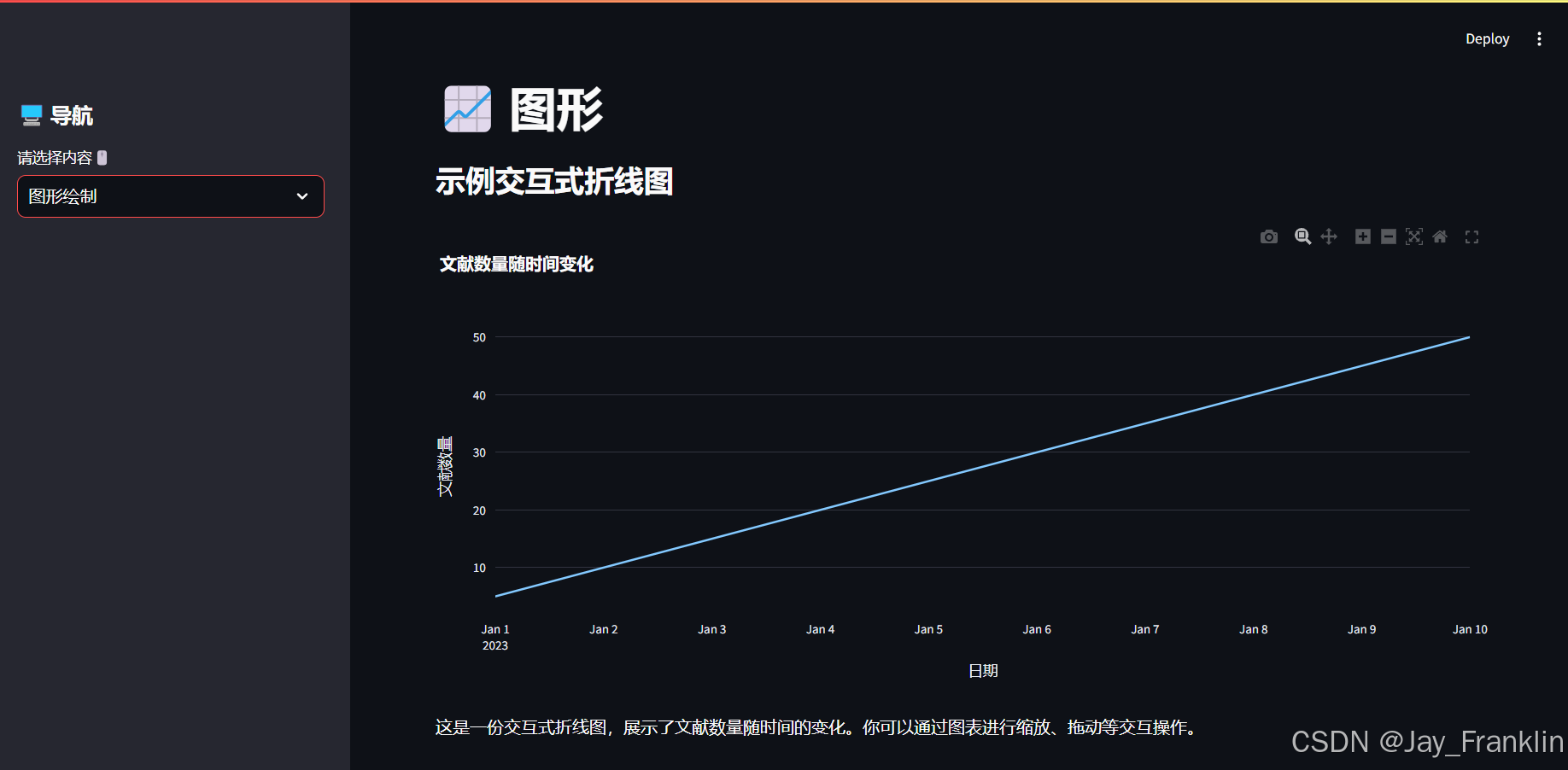
def plot_page():
st.markdown('''
# 📈 图形
''')
# 示例交互式折线图
st.markdown("### 示例交互式折线图")
# 创建一个示例数据集
sample_data = {
'日期': pd.date_range(start='2023-01-01', periods=10, freq='D'),
'文献数量': [5, 10, 15, 20, 25, 30, 35, 40, 45, 50],
}
df_plot = pd.DataFrame(sample_data)
# 使用 plotly 绘制交互式图表
fig = px.line(df_plot, x='日期', y='文献数量', title='文献数量随时间变化')
fig.update_layout(
title='文献数量随时间变化',
xaxis_title='日期',
yaxis_title='文献数量',
template='plotly_dark',
)
# 显示交互式图表
st.plotly_chart(fig, use_container_width=True)
st.markdown("""
这是一份交互式折线图,展示了文献数量随时间的变化。你可以通过图表进行缩放、拖动等交互操作。
""")
# InformationTB
def information_tb():
st.markdown('''
# 🔬 InformationTB
## 🖱️Please choose the item:
''')
table = 'your table name'
query = f"SELECT * FROM {table}"
try:
# 创建 SQLAlchemy 引擎
engine = get_engine()
df = pd.read_sql(query, engine)
# 创建一个 selectbox,其选项是 DataFrame 的第一列
selected_option = st.selectbox('Please choose:', df['the column you need'])
# 根据用户的选择从 DataFrame 中找到对应的值
corresponding_value = df.loc[df['the column you need'] == selected_option, 'content'].iloc[0]
col1,col2 = st.columns(2)
with col1:
st.metric("**The number of entries recorded in this database is**:",value=len(df))
with col2:
st.markdown(f'''
**The current selection is**:
{selected_option}
''')
current_df = df[df['the column you need'] == selected_option][['column1', 'column2', 'column3', 'column4']]
st.table(current_df)
st.markdown('<hr>', unsafe_allow_html=True)
# 输出选中的值
st.markdown('## 🛢️Details:')
st.markdown(corresponding_value)
except Exception as e:
st.error(f"发生错误: {e}")代码说明
本文使用 Streamlit 创建了一个 Web 应用程序,它集成了多个页面和功能,用于展示数据、绘制图表、以及从数据库中提取信息。下面是代码的主要部分及其解释:
导入库和设置
- 导入了必要的库,如 `streamlit` 用于创建Web应用,`time` 用于模拟加载过程中的延迟。
- 设置了页面配置,包括页面标题、图标、布局等。
显示加载中的占位符
- 定义了一个名为 `display_loading` 的函数,用于在页面加载时显示一个旋转的加载图标,并可自定义加载信息。
边栏导航
- 使用 `st.sidebar.selectbox` 创建了一个选择框,用户可以从中选择要访问的页面(主页、数据展示、图形绘制、信息展示)。
根据页面选择显示相应的内容
- 根据用户在边栏的选择,调用相应的页面函数 (`home_page`, `data_display_page`, `plot_page`, `information_tb`) 来展示内容。
自定义CSS样式
- 通过 `st.markdown` 和 HTML `<style>` 标签插入了一些自定义CSS,以改变Streamlit组件的默认样式。
主页内容 (`home_page` 函数)
- 显示欢迎信息,包含两个链接按钮指向外部网站(GitHub 和 CSDN),并介绍数据库的内容。
数据展示页面内容 (`data_display_page` 函数)
- 提供了一个下拉菜单让用户选择要查看的数据表,并展示了所选表格的数据。
绘图页面内容 (`plot_page` 函数)
- 创建了一个交互式的折线图,用来展示示例数据随时间的变化情况。
信息展示页面 (`information_tb` 函数)
- 从数据库中读取特定表格的数据,并允许用户选择不同的选项来查看对应的详细信息。
请注意,代码中的某些地方使用了占位符文本(例如数据库连接字符串中的用户名、密码和数据库名),你需要将其替换为实际值才能让应用程序正常工作。

















 118
118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









