







线程是一个进程的实体,是由表示程序运行状态的寄存器(如程序计数器、栈指针)以及堆栈组成,它是比进程更小的单位。
线程是程序中的一个执行流。一个执行流是由CPU运行程序代码并操作程序的数据所形成的。因此,线程被认为是以CPU为主体的行为。
线程不包含进程地址空间中的代码和数据,线程是计算过程在某一时刻的状态。所以,系统在产生一个线程或各个线程之间切换时,负担要比进程小得多。
线程是一个用户级的实体,线程结构驻留在用户空间中,能够被普通的用户级函数直接访问。
一个线程本身不是程序,它必须运行于一个程序(进程)之中。因此,线程可以定义为一个程序中的单个执行流。
多线程是指一个程序中包含多个执行流,多线程是实现并发的一种有效手段。一个进程在其执行过程中,可以产生多个线程,形成多个执行流。每个执行流即每个线程也有它自身的产生、存在和消亡的过程。
多线程程序设计的含义就是可以将程序任务分成几个并行的子任务。
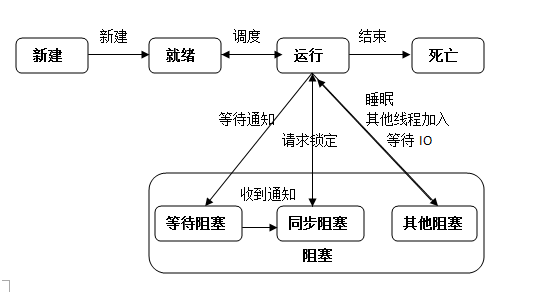
线程的状态图:
Python中常使用的线程模块
- thread(低版本使用的),threading
- Queue
- multiprocessing
threading
thread模块是Python低版本中使用的,高版本中被threading代替了。threading模块提供了更方便的API来操作线程。
threading.Thread
Thread是threading模块中最重要的类之一,可以使用它来创建线程。创建新的线程有两种方法:
- 方法一:直接创建threading.Thread类的对象,初始化时将可调用对象作为参数传入。
- 方法二:通过继承Thread类,重写它的run方法。
Thread类的构造方法:
__init__(group=None, target=None, name=None, args=(), kwargs=None, verbose=None)- 1
参数说明:
group:线程组,目前还没有实现,库引用中提示必须是None。
target:要执行的方法;
name:线程名;
args/kwargs:要传入方法的参数。
Thread类拥有的实例方法:
isAlive():返回线程是否在运行。正在运行指的是启动后,终止前。
getName(name)/setName(name):获取/设置线程名。
isDaemon(bool)/setDaemon(bool):获取/设置是否为守护线程。初始值从创建该线程的线程继承而来,当没有非守护线程仍在运行时,程序将终止。
start():启动线程。
join([timeout]):阻塞当前上下文环境的线程,直到调用此方法的线程终止或到达指定的等待时间timeout(可选参数)。即当前的线程要等调用join()这个方法的线程执行完,或者是达到规定的时间。
直接创建threading.Thread类的对象
实例:
from threading import Thread
import time
def run(a = None, b = None) :
print a, b
time.sleep(1)
t = Thread(target = run, args = ("this is a", "thread"))
#此时线程是新建状态
print t.getName()#获得线程对象名称
print t.isAlive()#判断线程是否还活着。
t.start()#启动线程
t.join()#等待其他线程运行结束
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
执行结果:
Thread-1
False
this is a thread
- 1
- 2
- 3
- 4
注意:
t = Thread(target = run, args = ("this is a", "thread"))- 1
这句只是创建了一个线程,并未执行这个线程,此时线程处于新建状态。
t.start()#启动线程- 1
启动线程,此时线程扔为运行,只是处于准备状态。
自定义函数run(),使我们自己根据我们需求自己定义的,函数名可以随便取,run函数的参数来源于后面的args元组。
通过继承Thread类
实例:
from threading import Thread
import time
class MyThread(Thread) :
def __init__(self, a) :
super(MyThread, self).__init__()
#调用父类的构造方法
self.a = a
def run(self) :
print "sleep :", self.a
time.sleep(self.a)
t1 = MyThread(2)
t2 = MyThread(4)
t1.start()
t2.start()
t1.join()
t2.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
执行结果:
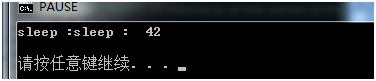
由于创建了两个并发执行的线程t1和t2,并发线程的执行时间不定,谁先执行完的时间也不定,所以执行后打印的结果顺序也是不定的。每一次执行都有可能出现不同的结果。
注意:
继承Thread类的新类MyThread构造函数中必须要调用父类的构造方法,这样才能产生父类的构造函数中的参数,才能产生线程所需要的参数。新的类中如果需要别的参数,直接在其构造方法中加即可。
同时,新类中,在重写父类的run方法时,它默认是不带参数的,如果需要给它提供参数,需要在类的构造函数中指定,因为在线程执行的过程中,run方法时线程自己去调用的,不用我们手动调用,所以没法直接给传递参数,只能在构造方法中设定好参数,然后再run方法中调用。
针对join()函数用法的实例:
# encoding: UTF-8
import threading
import time
def context(tJoin):
print 'in threadContext.'
tJoin.start()
# 将阻塞tContext直到threadJoin终止。
tJoin.join()
# tJoin终止后继续执行。
print 'out threadContext.'
def join():
print 'in threadJoin.'
time.sleep(1)
print 'out threadJoin.'
tJoin = threading.Thread(target=join)
tContext = threading.Thread(target=context, args=(tJoin,))
tContext.start()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
执行结果:
in threadContext.
in threadJoin.
out threadJoin.
out threadContext.
- 1
- 2
- 3
- 4
- 5
解析:
主程序中这句tJoin = threading.Thread(target=join)执行后,只是创建了一个线程对象tJoin,但并未启动该线程。
tContext = threading.Thread(target=context, args=(tJoin,))
tContext.start()
- 1
- 2
- 3
上面这两句执行后,创建了另一个线程对象tContext并启动该线程(打印in threadContext.),同时将tJoin线程对象作为参数传给context函数,在context函数中,启动了tJoin这个线程,同时该线程又调用了join()函数(tJoin.join()),那tContext线程将等待tJoin这线程执行完成后,才能继续tContext线程后面的,所以先执行join()函数,打印输出下面两句:
in threadJoin.
out threadJoin.
- 1
- 2
- 3
tJoin线程执行结束后,继续执行tContext线程,于是打印输出了out threadContext.,于是就看到我们上面看到的输出结果,并且无论执行多少次,结果都是这个顺序。但如果将context()函数中tJoin.join()这句注释掉,再执行该程序,打印输出的结果顺序就不定了,因为此时这两线程就是并发执行的。
multiprocessing.dummy
Python中线程multiprocessing模块与进程使用的同一模块。使用方法也基本相同,唯一不同的是,from multiprocessing import Pool这样导入的Pool表示的是进程池;
from multiprocessing.dummy import Pool这样导入的Pool表示的是线程池。这样就可以实现线程里面的并发了。
线程池实例:
import time
from multiprocessing.dummy import Pool as ThreadPool
#给线程池取一个别名ThreadPool
def run(fn):
time.sleep(2)
print fn
if __name__ == '__main__':
testFL = [1,2,3,4,5]
pool = ThreadPool(10)#创建10个容量的线程池并发执行
pool.map(run, testFL)
pool.close()
pool.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
执行结果:
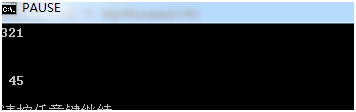
这里的pool.map()函数,跟进程池的map函数用法一样,也跟内建的map函数一样。















 3388
3388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









