








Longformer: The Long-Document Transformer
Abstract
BERT-base无法处理长文本序列,因此注意力操作与序列长度成平方关系,本文提出了一种新的注意力计算方法用于解决这个问题,使得平方关系变成线性关系,能够处理更长的文本序列,具体来说,通过空洞卷积的思想将局部窗口注意力和全局注意力结合,本文称之为Longformer。
1 Introduction
Transformer的成功在一定程度上归功于自注意力的计算,能够使网络从整个序列中捕获上下文信息,但是也存在一个弊端,注意力的计算随着文本序列长度的增加对内存和计算能力的要求越来越高,这使得处理长文本序列的成本比较高,为了解决这一问题,本文对transformer进行改进,提出了一种随着序列长度呈线性增加的自注意力操作,以适用于长文本。
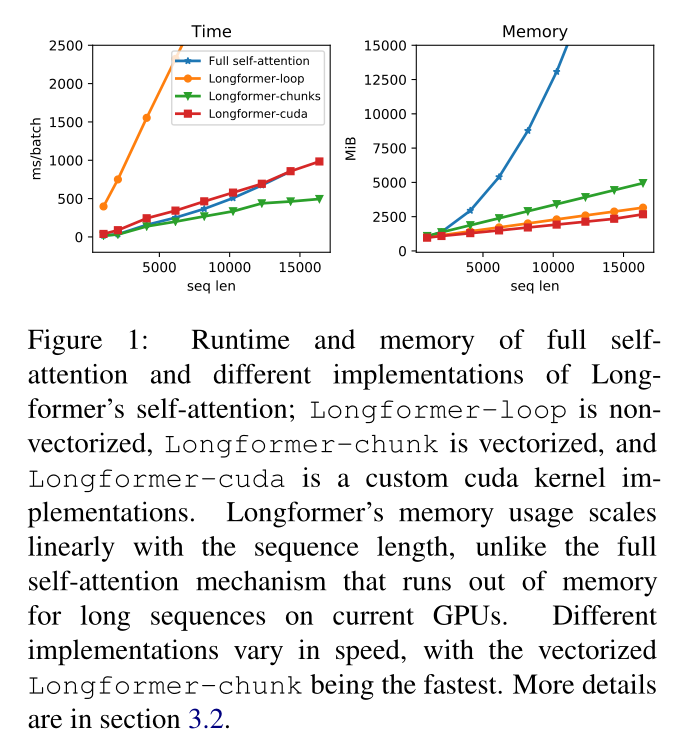
现有的方法处理长文本是通过将上下文分割或缩小为较小的序列,然后通过BERT学习序列表示,但是这种分割会潜在的导致重要的跨块信息丢失,为了缓解这个问题,现有的方法通过复杂的体系结构来增强块与块之间的交互,本文提出的Longformer是能够使用多个attention层构建整个上下文的上下文表示,从而减少复杂的体系结构的设计。
Longformer的注意机制是有窗口的local-context自注意力和end task motivated global attention的组合,这种注意力机制编码了对任务的归纳bias。作者通过消融试验发现,local-context注意力主要用于构建上下文表征,而global attention构建用于预测的full sequence表征。
2 LongFormer
2.1 Attention Pattern
2.1.1 Sliding Window
本文的注意力模式在每个token周围使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1075
1075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











