







在“M-P神经元模型”中,神经元接收到来自![]() 个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出。常用Sigmoid函数作为激活函数。
个其他神经元传递过来的输入信号,这些输入信号通过带权重的连接进行传递,神经元接收到的总输入值将与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出。常用Sigmoid函数作为激活函数。
把许多个这样的神经元按一定额层次结构连接起来,就得到了神经网络。事实上,从计算机科学的角度看,我们可以先不考虑神经网络是否真的模拟了生物神经网络,只需将一个神经网络视为包含了许多参数的数学模型,这个模型是若干个函数,例如![]() 相互嵌套而得。
相互嵌套而得。
感知机由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,亦称“阈值逻辑单元”。感知机能容易实现与、或、非运算,但它不能解决异或这样简单的非线性可分问题。
要解决非线性可分问题,需要考虑使用多层功能神经元,其输入层与输出层之间的层神经元称为隐层,隐层和输出层神经元都是拥有激活函数的功能神经元。这样的神经网络结构通常称为“多层前馈神经网络”。神经网络的学习过程,就是根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的阈值;换言之,神经网络“学”到的东西,蕴涵在连接权与阈值中。
多层网络的训练通常采用误差逆传播算法(BP)。假定有输入实例由![]() 个属性描述,输出
个属性描述,输出![]() 维实值向量,含
维实值向量,含![]() 个隐层神经元的单隐层前馈网络,其中输出层第
个隐层神经元的单隐层前馈网络,其中输出层第![]() 个神经元的阈值用
个神经元的阈值用![]() 表示,隐层第
表示,隐层第![]() 个神经元的阈值用
个神经元的阈值用![]() 表示;输入层第
表示;输入层第![]() 个神经元与隐层第
个神经元与隐层第![]() 个神经元之间的连接权为
个神经元之间的连接权为![]() ,隐层第
,隐层第![]() 个神经元与输出层第
个神经元与输出层第![]() 个神经元之间的连接权为
个神经元之间的连接权为![]() 。
。
记隐层第![]() 个神经元接收到的输入为
个神经元接收到的输入为
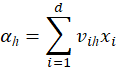
其中![]() 表示样本
表示样本![]() 的第
的第![]() 个属性值;
个属性值;
输出层第![]() 个神经元接收到的输入为
个神经元接收到的输入为
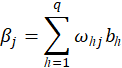
其中![]() 为隐层第
为隐层第![]() 个神经元的输出,假设隐层和输出层神经元都是用Sigmoid函数作为激活函数。即
个神经元的输出,假设隐层和输出层神经元都是用Sigmoid函数作为激活函数。即![]() ,
,![]() 表示Sigmoid函数。
表示Sigmoid函数。
对训练例![]() ,
,![]() ,假定神经网络模型的预测输出为
,假定神经网络模型的预测输出为![]() ,脚标和上标分别表示样例属性向量的维数、样本序号,即
,脚标和上标分别表示样例属性向量的维数、样本序号,即
![]()
则网络在训练例上的均方误差为
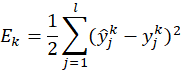
这里有![]() 个参数需确定:输入层到隐层的
个参数需确定:输入层到隐层的![]() 个权值、隐层到输出层的
个权值、隐层到输出层的![]() 个权值、
个权值、![]() 个隐层神经元的阈值、
个隐层神经元的阈值、![]() 个输出层神经元的阈值。
个输出层神经元的阈值。



其中![]() 表示学习率,它控制着算法每一轮迭代中的更新步长,若太大则容易振荡,太小则收敛速度又会过慢。还要特别注意理解上述画波浪线的句子。
表示学习率,它控制着算法每一轮迭代中的更新步长,若太大则容易振荡,太小则收敛速度又会过慢。还要特别注意理解上述画波浪线的句子。
对每个训练样例,BP算法执行以下操作:先将输入示例提供给输入层神经元,然后逐层将信号前传,直到产生输出层的结果;然后计算输出层的误差,再将误差逆向传播至隐层神经元,最后根据隐层神经元的误差来对连接权和阈值进行调整。这个迭代过程循环进行,直到达到某些停止条件为止,如训练误差已达到一个很小的值。
一点需要注意的是,更新公式中的![]() 不需要赋初值,因为只要给各层权值和阈值赋初值之后,再输入样例,自然就能得到
不需要赋初值,因为只要给各层权值和阈值赋初值之后,再输入样例,自然就能得到![]() 的值了,并且它只起到一个中介作用。
的值了,并且它只起到一个中介作用。
另一点需要注意的是BP算法的目标是要最小化训练集![]() 上的累积误差
上的累积误差
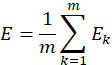
也就是说,上述“标准BP算法”的更新规则是基于单个的![]() 推导而得。累积BP算法与标准BP算法都很常用。一般来说,标准BP算法每次更新至针对单个样例,参数更新得非常频繁,而且对不同样例进行更新的效果可能出现“抵消”现象。因此,为了达到同样的累积误差极小值点,标准BP算法往往需进行更多次数的迭代。累积BP算法直接针对累积误差最小化,它在读取整个训练集
推导而得。累积BP算法与标准BP算法都很常用。一般来说,标准BP算法每次更新至针对单个样例,参数更新得非常频繁,而且对不同样例进行更新的效果可能出现“抵消”现象。因此,为了达到同样的累积误差极小值点,标准BP算法往往需进行更多次数的迭代。累积BP算法直接针对累积误差最小化,它在读取整个训练集![]() 一遍后才对参数进行更新,其参数更新频率低得多。但在很多任务中,累积误差下降到一定程度后,进一步下降会非常缓慢,这时标准BP往往会更快获得较好得解。它们得区别类似于随机梯度下降(SGD)与梯度下降(GD)之间的区别。
一遍后才对参数进行更新,其参数更新频率低得多。但在很多任务中,累积误差下降到一定程度后,进一步下降会非常缓慢,这时标准BP往往会更快获得较好得解。它们得区别类似于随机梯度下降(SGD)与梯度下降(GD)之间的区别。
可以证明,只需一个包含足够多神经元的隐层,多层前馈前馈网络就能以任意精度逼近任意复杂度的连续函数。正是由于其强大的表示能力,BP神经网络经常遭遇过拟合,其训练误差持续降低,但测试误差却可能上升。有两种策略常用来缓解BP网络的过拟合。第一种策略是“早停”:将数据分成训练集和验证集,训练集用来计算梯度、更新连接权和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则停止训练,同时返回具有最小验证集误差的连接权和阈值。第二种策略是“正则化”,其基本思想是在代价函数中增加一个“惩罚项”,这样训练过程将会偏好比较小的参数项,使得网络输出更加“光滑”,从而对过拟合有所缓解。
若代价函数仅有一个局部极小值点(此式的代价函数为凸函数),那么找到的局部极小值点也就是全局最小值点;然而,如果误差函数具有多个局部极小值点,则不能保证找到的解是全局最小值点。在现实任务中,我们通常采用以下策略来“跳出”局部极小:
· 以多组不同参数值初始化多个神经网络,按标准方法训练后,取其中误差最小的解作为最终参数。这相当于从多个不同的初始点开始搜索,这样就可能陷入不同的局部极小,从中进行选择有可能获得更接近全局最小的结果。
· 使用“模拟退火”技术。
· 使用随机梯度下降。
· 使用“遗传算法”。
其他常见的神经网络主要有RBF网络、ART网络、SOM网络、级联相关网络、Elman网络、Boltzmann机等。
典型的深度学习模型就是很深层的神经网络,训练时往往不用BP算法,而采用“预训练+微调”或“权共享”的方式,这有效地节省了训练开销。从另一个角度讲,深度学习是通过多层处理,逐渐将“底层”特征表示转化为“高层”特征表示,最后用“简单模型”来完成复杂的分类等学习任务。
















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











