






论文:《YOLO-World: Real-Time Open-Vocabulary Object Detection》
代码:https://github.com/AILab-CVC/YOLO-World
1.Abstract
我们介绍了YOLO World,这是一种创新的方法,通过在大规模数据集上进行视觉语言建模和预训练,增强YOLO的开放词汇检测能力。具体而言,我们提出了一种新的可重新参数化的视觉-语言路径聚合网络(RepVL-PAN)和区域文本对比损失,以促进视觉和语言信息之间的交互。我们的方法可以以zero-shot方式高效检测各种物体。
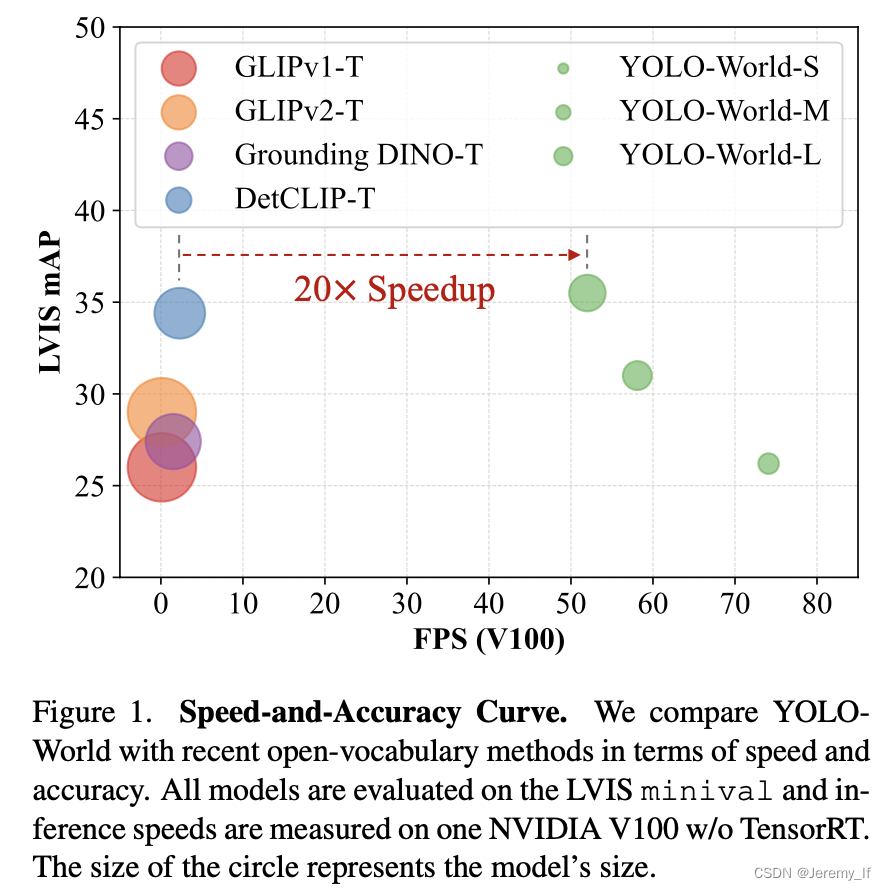
YOLO World遵循标准YOLO架构[20],并利用预先训练的CLIP[39]文本编码器对输入文本进行编码。我们进一步提出了可重新参数化的视觉语言路径聚合网络(RepVL-PAN)来连接文本特征和图像特征,以获得更好的视觉语义表示。在推理过程中,可以移除文本编码器,并将文本嵌入重新参数化为RepVL PAN的权重,以实现高效部署。对于实际应用,一旦我们训练了检测器,即YOLO World,我们就可以对提示或类别进行预编码,以构建离线词汇表,然后将其无缝集成到检测器中。

2.Related Work
传统的目标检测方法可以简单地分为三类,即基于区域region-based的方法、基于像素pixel-based的方法和基于查询query-based的方法。
3. Method
3.1. Pre-training Formulation: Region-Text Pairs
传统的对象检测方法,包括YOLO系列[20],使用实例注释Ω={Bi,ci}Ni=1,其由边界框{Bi}和类别标签{ci}组成。在本文中,我们将实例注释重新表述为区域-文本对Ω={Bi,ti}Ni=1,其中ti是区域Bi的对应文本。具体而言,**文本ti可以是类别名称、名词短语或对象描述。**此外,YOLO World采用图像I和文本T(一组名词)作为输入和输出预测框{Bõk}和相应的对象嵌入{ek}(ek∈RD)。
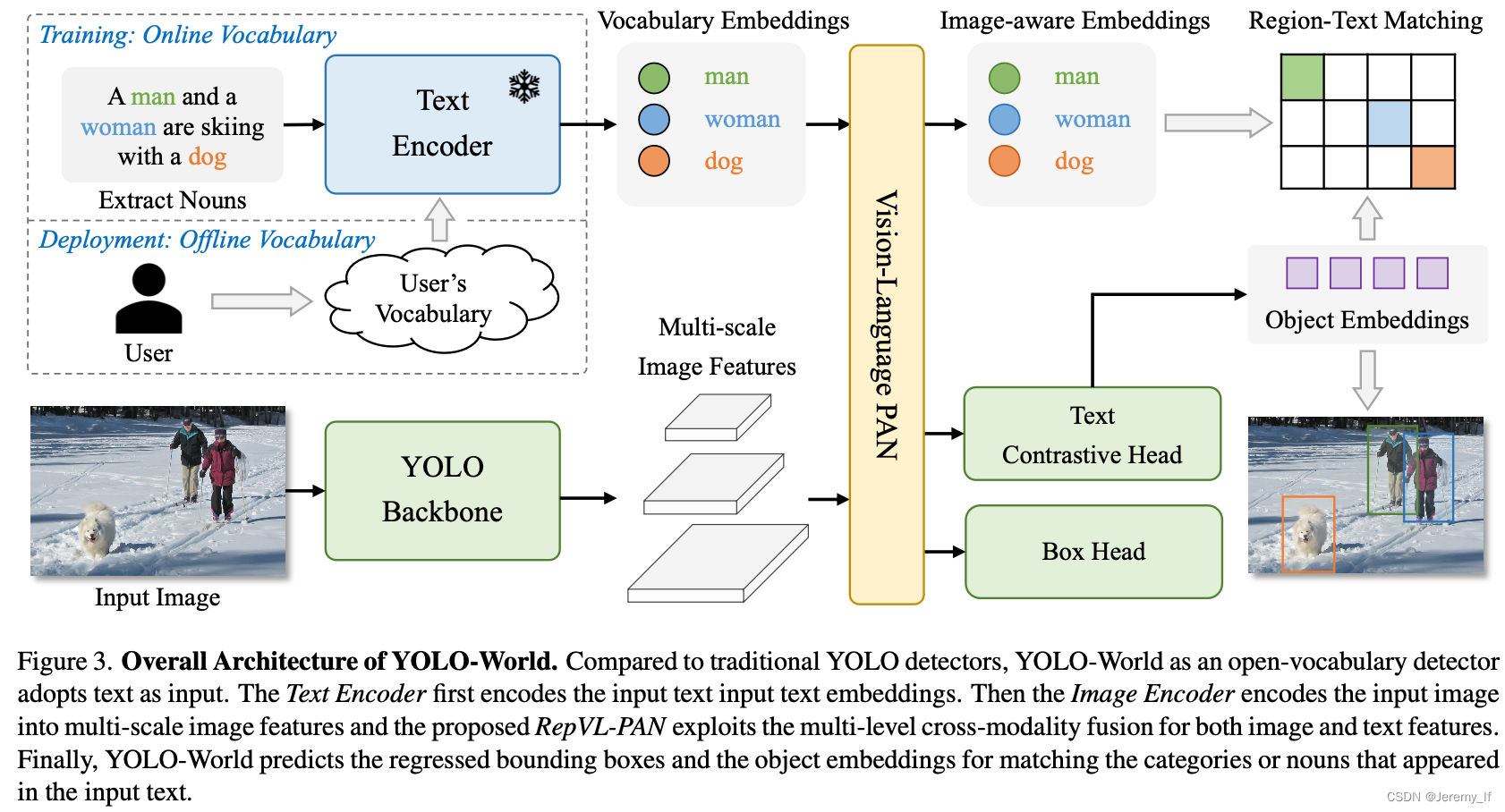
所提出的YOLO World的总体架构如图所示。3,它由YOLO检测器、文本编码器和可重新参数化的视觉语言路径聚合网络(RepVL PAN)组成。给定输入文本,YOLO World中的文本编码器将文本编码为文本嵌入。YOLO检测器中的图像编码器从输入图像中提取多尺度特征。然后,我们利用RepVL PAN,通过利用图像特征和文本嵌入之间的跨模态融合来增强文本和图像表示。
YOLO Detector。YOLO World主要基于YOLOv8[20]开发,其中包含作为图像编码器的Darknet backbone[20,43]、用于多尺度特征金字塔的路径聚合网络(PAN)以及用于边界框回归和object embeddings的head。
Text-Enocder。给定文本T,我们采用CLIP[39]预先训练的Transformer文本编码器来提取相应的文本嵌入W=TextEncoder(T)∈RC×D,其中C是名词的数量,D是embeding维数。与纯文本语言编码器相比,CLIP文本编码器提供了更好的视觉语义功能,可以将视觉对象与文本连接起来[5]。当输入的文本是描述或引用表达式时,我们采用简单的n-gram算法提取名词短语,然后将其输入到文本编码器中。
3.3. Re-parameterizable Vision-Language PAN
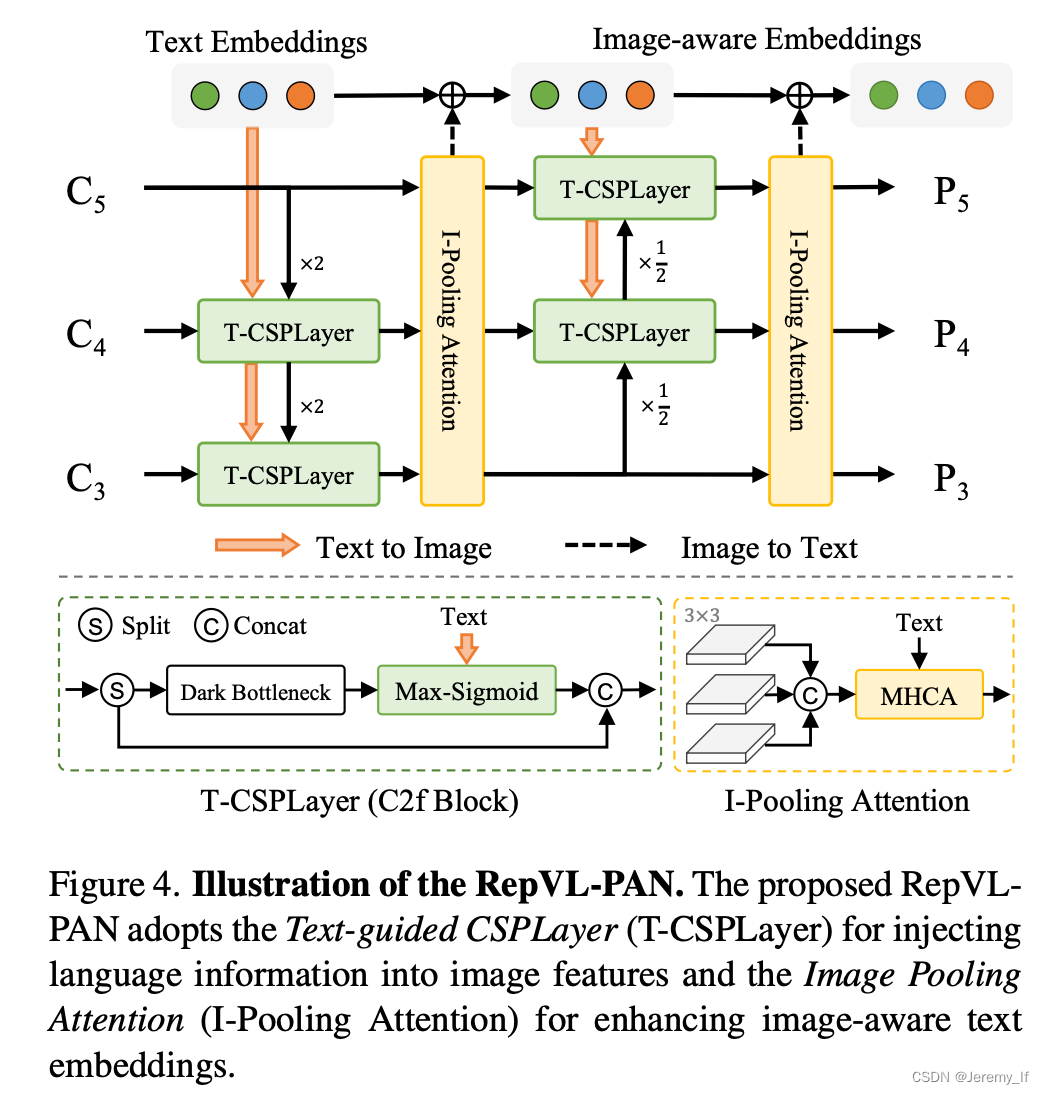
Text-guided CSPLayer. 如图4所示,跨阶段部分层(CSPLayer)是在自上而下或自下而上的融合之后使用的。我们通过将文本引导合并到多尺度图像特征中来扩展[20]的CSPLayer(也称为C2f),以形成文本引导的CSPLyer。具体地说,给定文本嵌入W和图像特征Xl∈RH×W×D(l∈{3,4,5}),我们在最后一个bottleneck之后采用max-sigmoid attention将文本特征聚合为图像特征: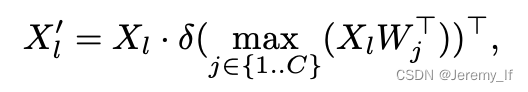
Image-Pooling Attention。为了增强具有图像感知信息的文本嵌入,我们通过提出图像池注意来聚合图像特征以更新文本嵌入。我们不是直接在图像特征上使用交叉注意力,而是利用多尺度特征上的最大池化来获得3×3个区域,从而产生总共27个补丁标记X∈R27×D。然后通过以下方式更新文本嵌入:W ′ = W + MultiHead-Attention(W, X ̃, X ̃)
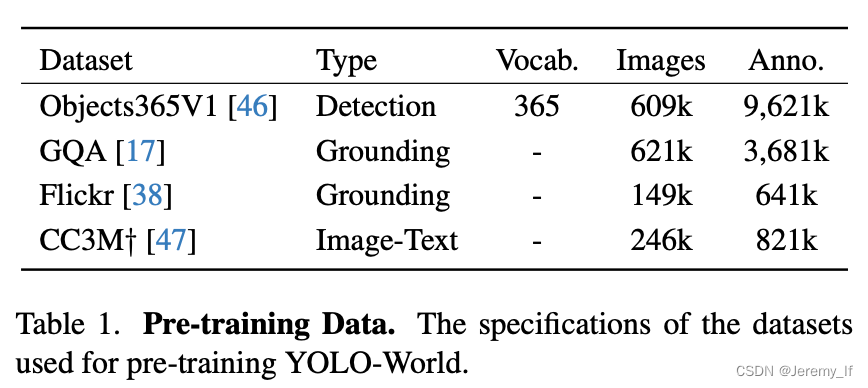
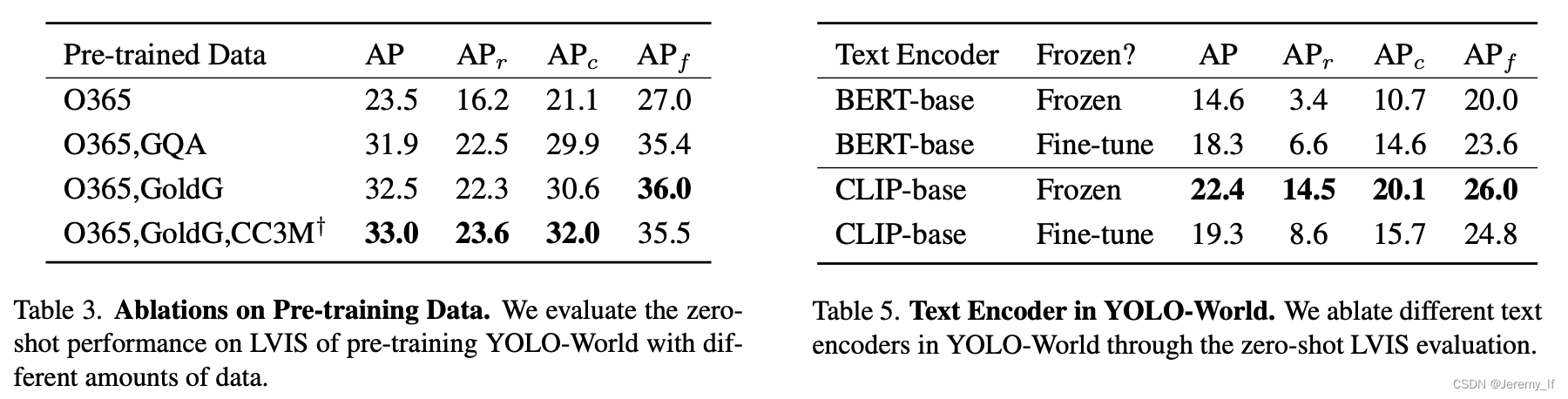
Pre-training data。对于预训练YOLO-World,我们主要采用检测或grounding数据集,包括Ob-Projects365(V1)[46]、GQA[17]、Flickr30k[38],如表1所示。根据[24],我们从GoldG[21](GQA和Flickr30k)中的COCO数据集中排除图像。用于预训练的检测数据集的注释包含边界框和类别或名词短语。此外,我们还用图像-文本对扩展了预训练数据,即CC3M†[47],我们已经通过第3.4节中讨论的伪标记方法标记了246k个图像。
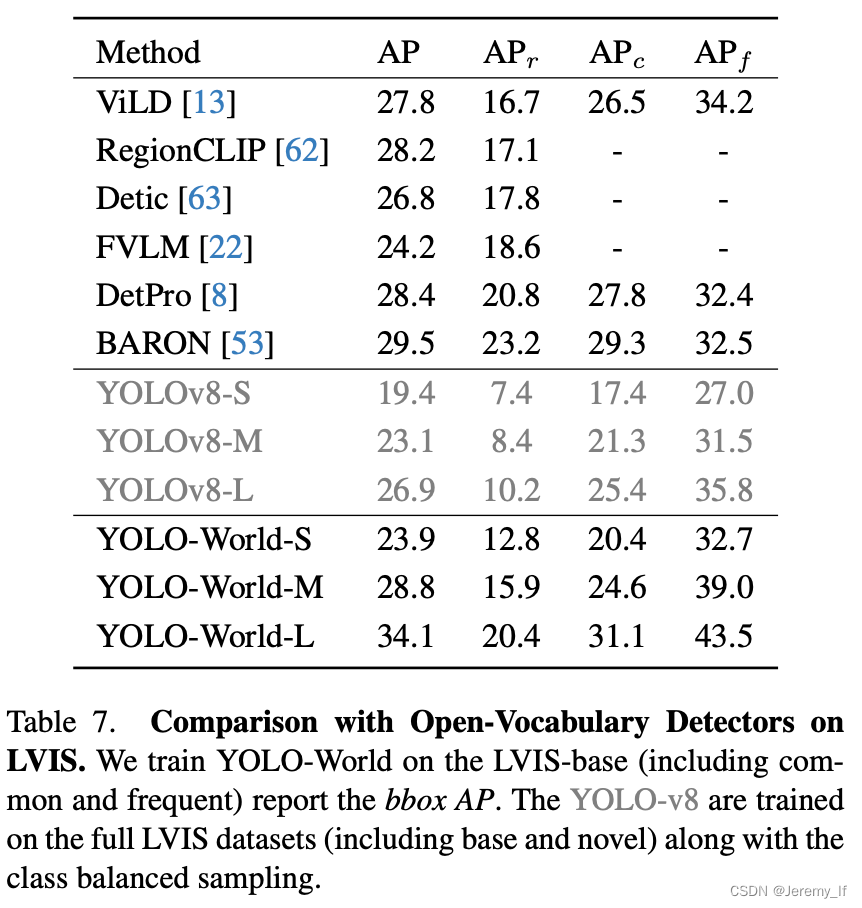
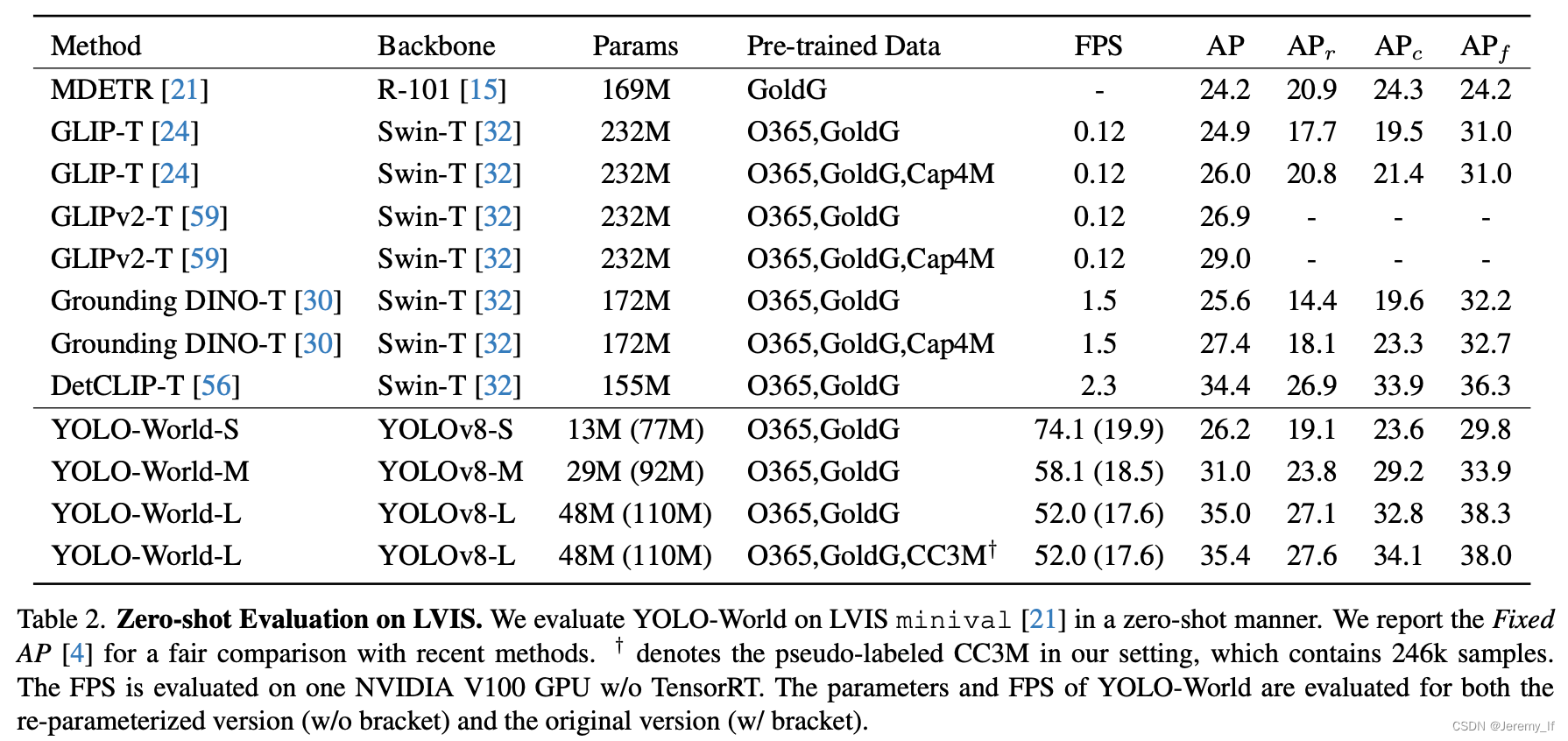
Grounding数据集通常用于计算机视觉和自然语言处理的联合任务,特别是Visual Grounding任务。这类数据集包含图像以及与之相关的物体描述,目标是定位描述中提及的物体。以下是Grounding数据集格式的详细介绍,并通过举例说明:
一、数据集格式
Grounding数据集一般由以下几个部分组成:
图像(Images): 数据集包含一系列图像,这些图像中包含了需要被定位的物体。
描述(Descriptions): 针对每张图像,数据集提供了相应的描述,这些描述可能是一个句子、短语或者是一个物体名称,用于指明需要定位的物体。
标注框(Bounding Boxes): 对于描述中提及的每个物体,数据集都提供了一个或多个标注框,这些标注框用坐标表示物体在图像中的位置。
类别标签(Category Labels) (可选): 某些数据集还可能包含物体的类别标签,以便于分类和识别。
二、举例说明
以Flickr30k Entities数据集为例,这是一个常用的Visual Grounding数据集:
图像: 数据集包含31783张图像。
描述: 每张图像对应5个不同的caption(描述),总共有158915个caption。
标注框: 数据集提供了244035个phrase-box标注,即针对特定短语的标注框。例如,如果一个caption是“A man in a red shirt is riding a bike”,那么“man”、“red shirt”和“bike”都可能有对应的标注框。
类别标签: 数据集中的phrase还会被细分为people, clothing, body parts, animals, vehicles, instruments, scene, other等八个不同的类别。
在RefCOCO、RefCOCO+、RefCOCOg等数据集中,格式类似,但可能包含更多的交互性和复杂性,例如在RefCOCO+中,查询不包含绝对的方位词,要求模型更智能地理解上下文来定位物体。
总的来说,Grounding数据集的格式是为了训练模型能够准确理解语言描述,并在图像中定位相应物体的能力。通过大量的图像、描述和标注框的组合,模型可以学习到如何从复杂的视觉和语言信息中提取关键特征,实现准确的物体定位。















 59
59

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









