







论文题目:SwiftBrush: One-Step Text-to-Image Diffusion Model with Variational Score Distillation
所属会议:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024)
类型:文生图

一、研究背景
文本到图像扩散模型能够根据文本提示生成高分辨率和多样化的图像,但通常受到迭代采样过程缓慢的影响,限制了其在实时应用中的部署。模型蒸馏是加速这些模型的有效方向之一,但以往的蒸馏方法往往难以在保持生成质量的同时,减少对大量训练图像的依赖。
二、相关工作
2.1文本到图像生成(Text-to-Image Generation)
早期方法:基于GANs:早期的文本到图像模型主要依赖于生成对抗网络(GANs),这些模型通常在小规模的对象中心域(如花卉和鸟类)上表现良好。然而,它们在生成大型、复杂场景或具有丰富细节的图像时存在局限性。
近期进展:大规模数据集与语言模型:随着LAION-5B等大规模文本-图像对数据集以及T5等大型语言模型的出现,文本到图像生成领域取得了显著进展。
扩散模型:特别是文本到图像的扩散模型,结合了语言模型的强大能力和高质量扩散模型的优势,彻底改变了基于文本描述的视觉内容创建方式。这些模型现在能够生成与真实照片难以区分的合成图像。
代表性工作:(1)DALL-E:展示了从零开始创建图像的显著零样本能力。
(2)Stable Diffusion:一个开源的基于扩散的生成器,在艺术家和研究人员中广受欢迎。
(3)GANs的复兴:尽管GANs在生成速度上具有优势,但它们在可扩展性和现实感方面落后于扩散模型。然而,近期的工作如StyleGAN-T和GigaGAN试图通过复杂的技术和辅助模块改进GANs在文本到图像生成中的应用。
2.2文本到3D生成(Text-to-3D Generation)
无3D监督的学习:许多研究工作利用丰富的2D先验知识来进行3D生成任务,而不是直接从3D监督中学习。
代表性方法:(1)Dream Fields:利用CLIP来引导生成的图像,使得从多个相机视角渲染的图像与文本描述高度一致。
(2)DreamFusion和Score Jacobian Chaining (SJC):提出了两种不同的但等效的框架,使用2D文本到图像的生成先验来从文本描述生成3D对象。
(3)Magic3D和ProlificDreamer:通过改进3D资产的生成质量来进一步提升这些文本到3D的方法。
(4)变分得分蒸馏(VSD):在ProlificDreamer中引入,用于提升3D生成的质量。VSD涉及一个额外的教师模型,用于桥接教师模型和3D NeRF之间的差距。这一技术成为SwiftBrush在文本到图像生成中应用的灵感来源。
2.3知识蒸馏(Knowledge Distillation)
定义与背景:知识蒸馏是一种迁移学习方法,其灵感来源于人类学习过程,即知识从更有知识的教师模型传递给知识较少的学生模型。
在扩散模型中的应用:已有多项工作提出了从预训练的扩散教师模型中更快地采样学生模型的方法。这些方法通过各种引导技术避免了蒸馏过程中的长时间采样。
图像依赖的局限性:尽管这些方法在文本到图像的设置中得到了适应,但它们仍然依赖于大量图像数据进行训练。
无图像监督的方法:与SwiftBrush类似,一些并发工作也探索了无需图像监督的训练方法,但SwiftBrush在结果和蒸馏设计的简洁性方面表现出了显著的优势。
三、研究目的
针对现有蒸馏方法的局限性,本研究提出了一种新颖的无图像蒸馏方案SwiftBrush,旨在通过变分分数蒸馏技术,将预训练的多步文本到图像扩散模型蒸馏到一个学生网络中,使其仅需单次推理步骤即可生成高质量图像,同时不依赖任何训练图像数据。
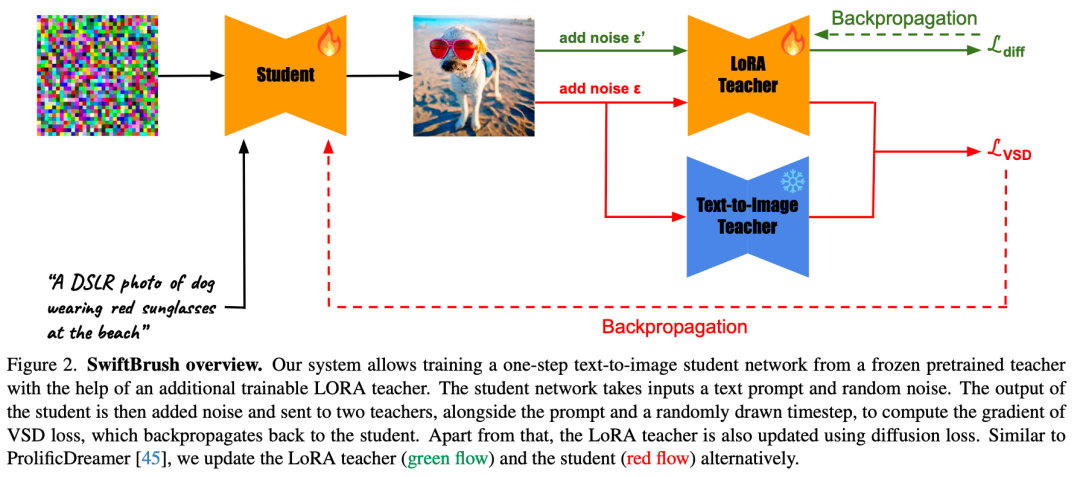
四、提出的方法
1.变分分数蒸馏(Variational Score Distillation, VSD):SwiftBrush从文本到3D合成中汲取灵感,利用预训练的2D文本到图像扩散模型作为先验,通过专门的损失函数优化学生网络。该方法引入了一个额外的LoRA(Low-Rank Adaptation)教师模型,与学生模型交替训练,以提高蒸馏效果。
2.无图像训练:SwiftBrush的训练过程不需要任何真实的训练图像数据,仅依赖文本提示和预训练扩散模型的输出,从而简化了训练流程并降低了数据依赖。
3.单步生成:通过优化学生网络,SwiftBrush实现了仅需单次推理步骤即可生成高质量图像,显著提高了生成速度。
算法流程
(1)初始化:LoRA教师模型和学生模型均初始化为预训练教师模型的权重。(2)交替训练:使用VSD损失和扩散损失交替优化学生模型和LoRA教师模型。(3)推理:学生模型通过一次前向传播即可生成高质量图像。

Student Parameterization. 在我们的例子中,选择的预训练模型是Stable Diffusion,它天生就是为了预测添加的噪声ε而设计的。相比之下,我们的目标是改进学生模型,使其预测一个干净无噪声的x0。因此,这种幼稚的方法导致我们希望学生学习的内容与学生的产出之间存在很大的领域差距。为了便于训练,我们按如下方式重新参数化学生输出:
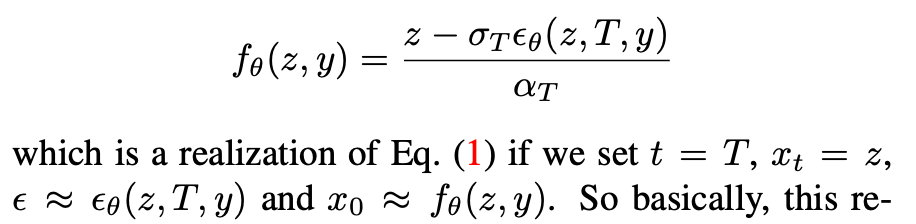
![]()
五、实验与结果
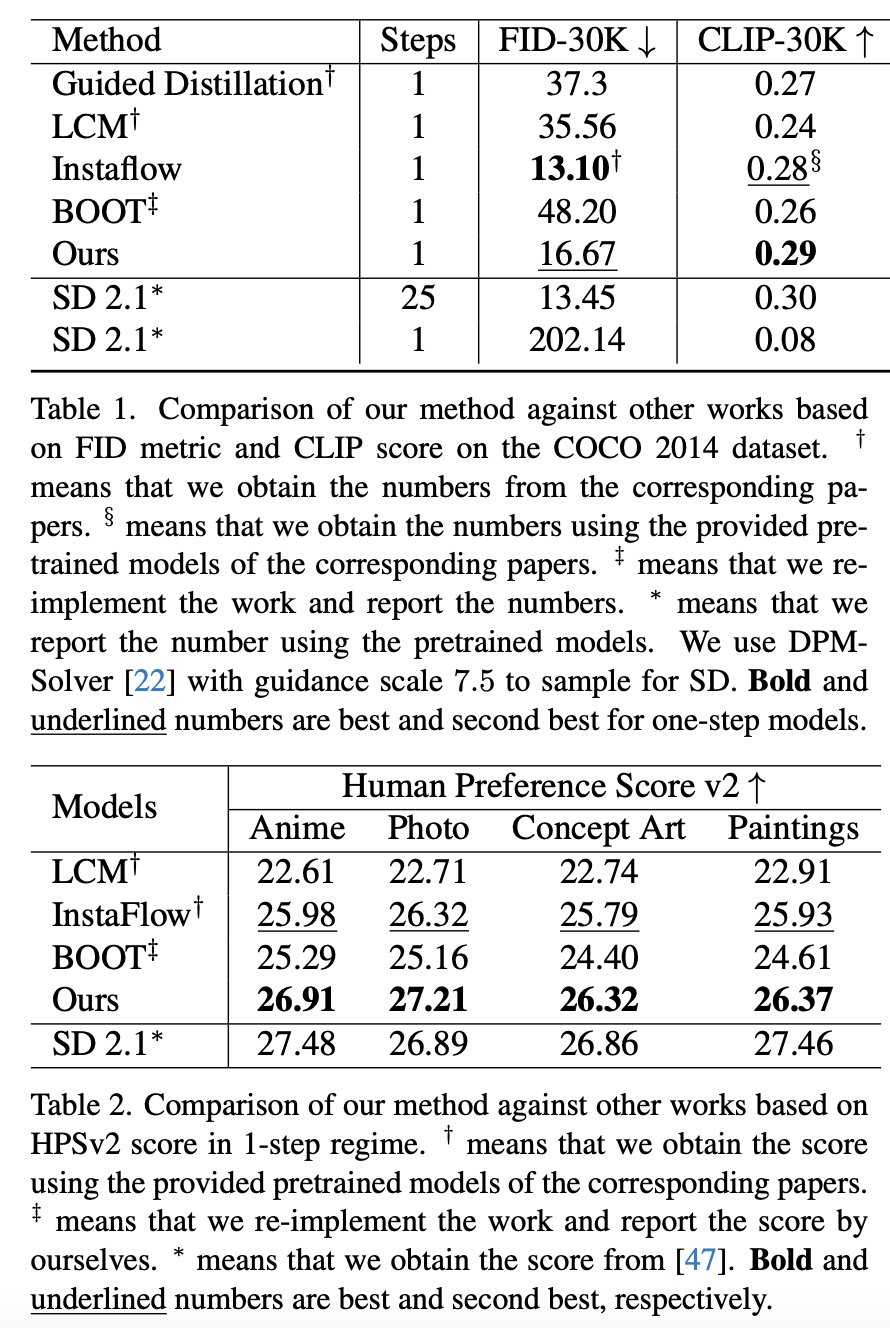
实验设置:研究在MS COCO 2014数据集(30K幅图像)上进行了实验,采用FID(Fréchet Inception Distance)和CLIP分数作为评估指标。
实验结果:SwiftBrush在COCO-30K基准上取得了16.67的FID分数和0.29的CLIP分数,显示出具有竞争力的生成质量。
分析
LoRA教师的重要性:LoRA教师显著提升了学生模型的生成质量,缺少LoRA教师会导致生成图像过于饱和和不现实。
学生参数化的重要性: 重新参数化学生输出对于生成高质量图像至关重要。
与现有的蒸馏技术相比,SwiftBrush在生成质量上有了显著提升,尤其是在不依赖任何训练图像的情况下,实现了高质量的一步式图像生成。

五、贡献与意义
贡献:提出了一种新颖的无图像蒸馏方案SwiftBrush,实现了高效的一步式文本到图像生成。引入了变分分数蒸馏技术,提高了蒸馏效果和学生网络的生成质量。
意义:SwiftBrush的提出为文本到图像生成的加速和简化训练过程提供了新的思路,推动了该领域的发展。其高效的一步式生成能力使得文本到图像扩散模型在更多实时应用中成为可能。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











