







一、文件操作
使用场景:上传文件 保存日志
1、open 函数
使用格式参数:
def open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True): # known special case of open
file :可以是文件名字,也可以是文件路径,可以是字节文件(图片)、可以是文本文件(记事本),写文件名,必须跟.py 执行文件同级目录中,或者使用相对路径,其余的都需要整体得到文件路径,open必须是文件,不可以是文件夹
mode:模式,是要读取还是写入,所以参数可以是 r 只能读纯文本文件 、w 只能写纯文本文件、 rt 默认不写mode,代表mode=rt 只能读,其中t 是 test mode 、 rb b代表二进制文件,比如图片,所以rb读取字节文件,并且可以读文本文件,底层都是二进制,是万能,但不推荐文本,文本显示二进制,人无法识别,所以还需要转换成人能识别的,而图片等py不支持转换人能识别的、wb 写入字节文件,a 是追加内容,默认 w 、wb 是直接将源文件覆盖,而 a 是在源文件追加,+ 打开一个硬盘文件,用于更新
buffering: 可选整型参数,用于缓存,缓存主要在内存,调节硬件跟cpu之间的缓冲,比如要上传很大的文件,需要使用此参数,让先存入缓存,否则直接给cpu,系统就会由于cpu占导致系统崩溃。并不是越大越好,会影响系统的性能
encoding: 编码,默认py使用 utf-8,但比如有一些文件需要gbk格式才能打开,需要指定encoding = gbk

2、读取文件
注意, \r : 回车, \n : 换行, \t : 制表符 \a 等,是系统的参数,前面加上r 转义

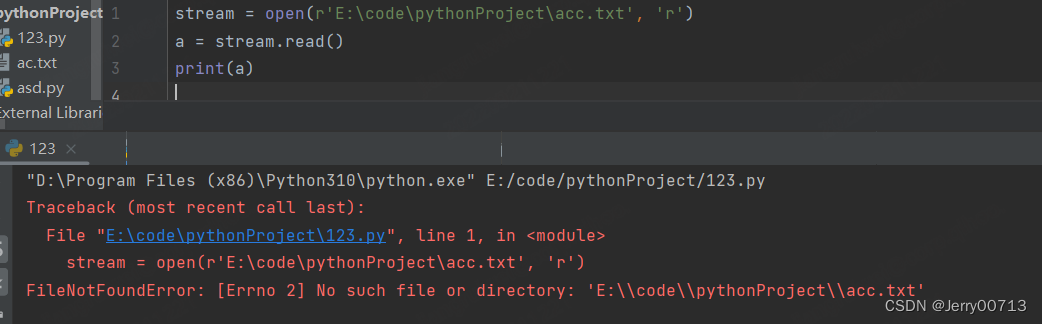
read () 首先需要先使用open 打开这个文件,并设置open打开的用途是 r,通过open打开后是一个字符流,通过字符流就可操作,调用read函数,读取文件
stream = open(r'E:\code\pythonProject\ac.txt') # 默认 mode = rt a = stream.read() print(a)
通过读取read 方法,可以看到使用了装饰器,说明是抽象方法,既然是抽象方法,就需要使用变量取接收,所以使用 a = stream.read()
注意,read 是读,如果文件不存在报错
读取word,会提示使用gbk
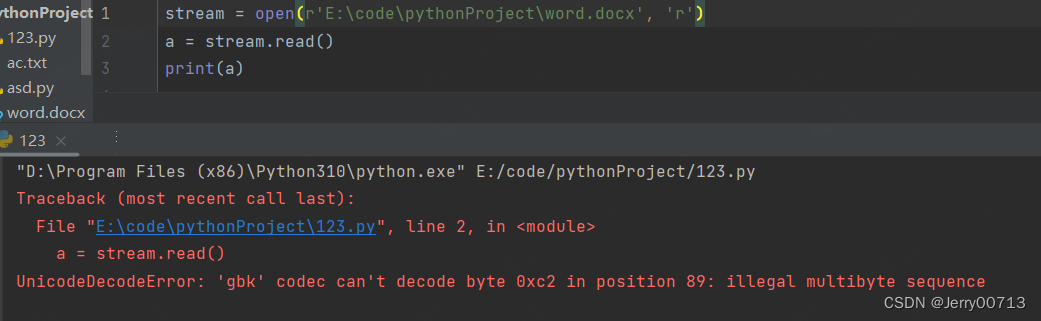
readable() 是不是可读,返回 bool 类型
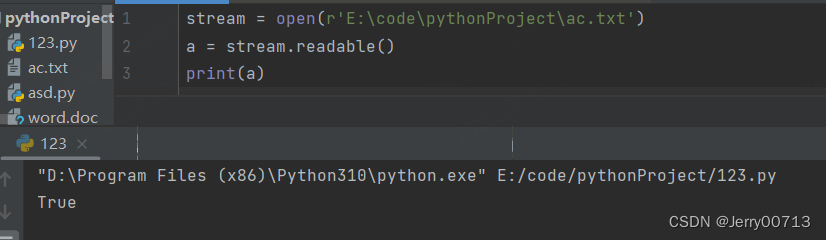
readline() 读取一行
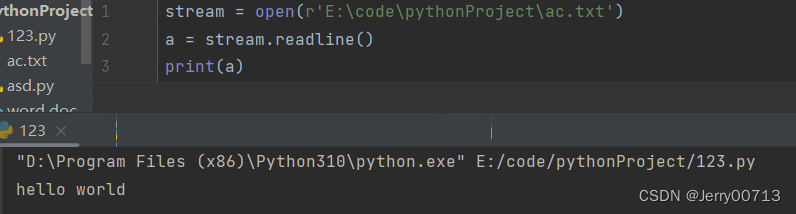
open() 打开一个文件,执行完成后需要执行clone() ,这样才能实现关闭open() ,而且注意,open() 打开一个文件后,在执行read() 或者readline() 读取后,第一次是从file文件的头读到尾部,如果是readline,执行一次读取一行,下此在执行后,会接着这次继续读
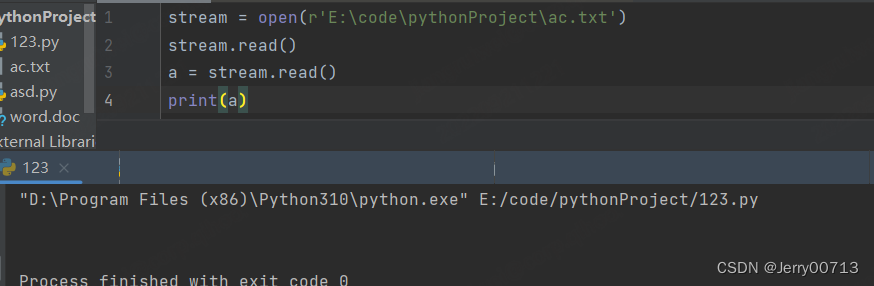
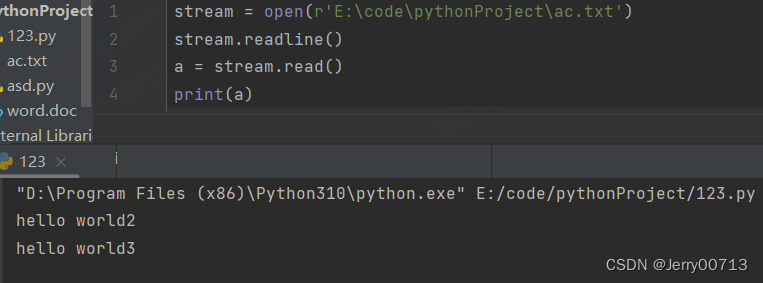
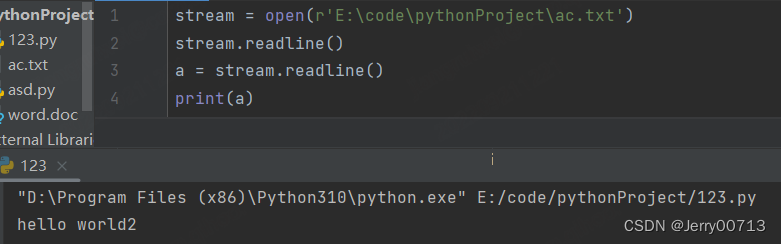
使用 readlin() 读取全部,需要用 for 循环,注意readline 按照行读,读取一次会打印一个\n
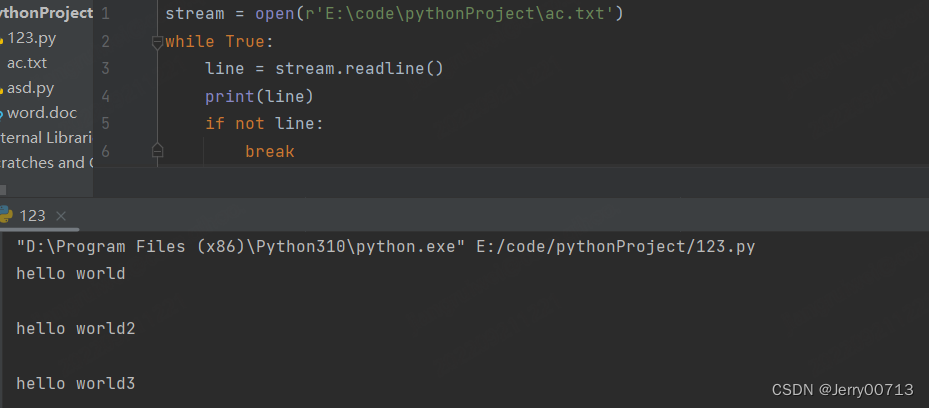
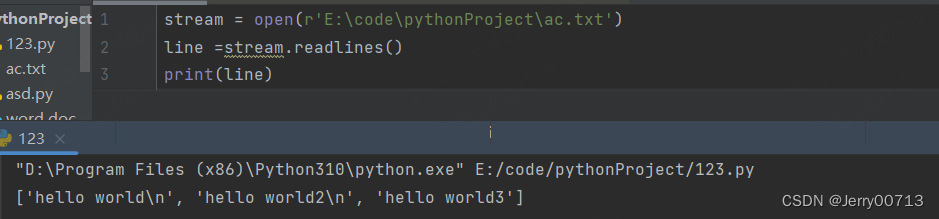
readlins() 读取所有的信息,并存入在列表中,而且每次执行一次readline都会打印一个\n
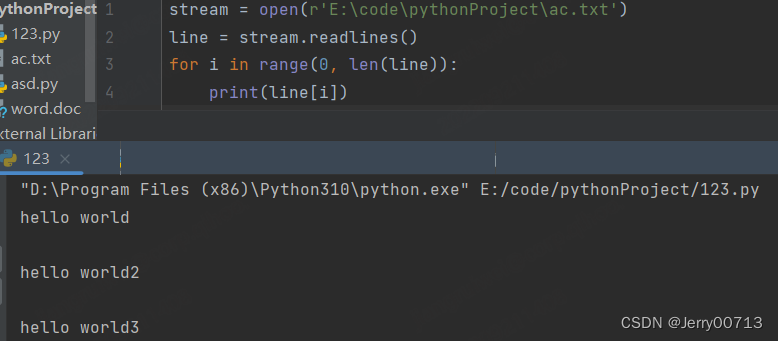
读取图片,不是模式用人的 mode = 'r'
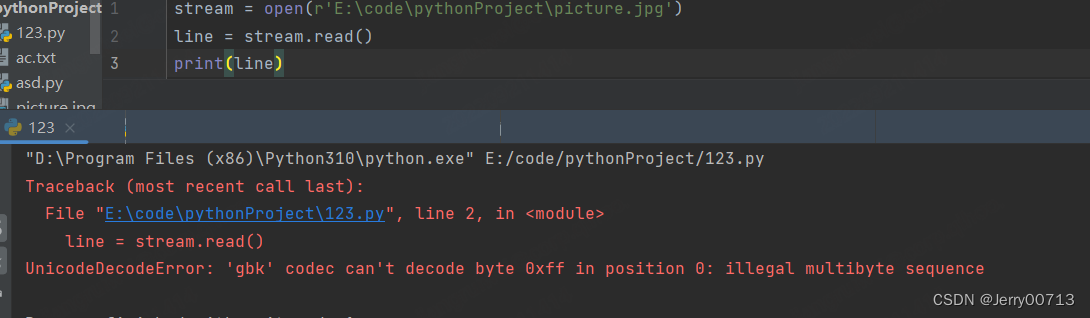
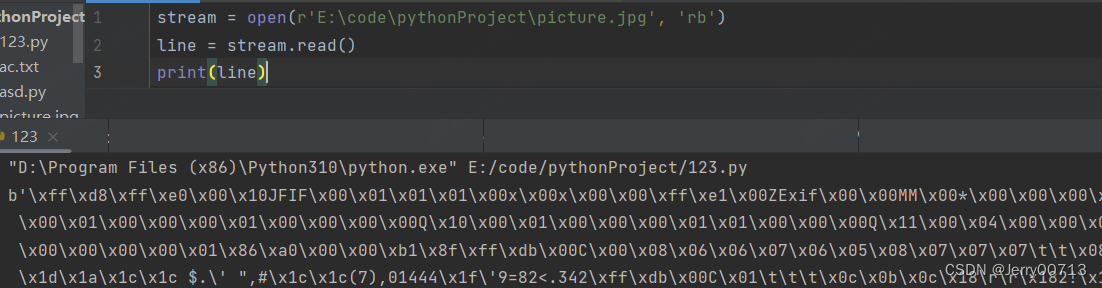
3、写文件
1、写文件,可以写已经存在的或者写不存在的,会创建
2、open 打开的时候 mode = w 或者 wb ,如果是 r rt rb 则不能调 write 等方法,因为打开就是 r 不是为了写3、注意mode = w 使用 write 或者 writeline 是覆盖原数据,只有mode= a 使用 append 是追加
stream = open(r'E:\code\pythonProject\write.txt', 'w') s = """ 你好 世界 送你一个花花 """ result = stream.write(s) # 执行 stream.write(s) 写入文件,返回结果是写入多少字符,注意换行符算一个 print(result) stream.close() # 注意别忘了关闭
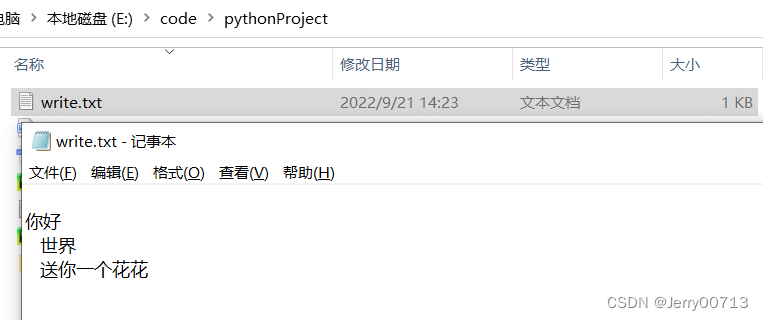
注意:write 写入的默认不会换行
stream = open(r'E:\code\pythonProject\write.txt', 'w') s = """ 你好 世界 送你一个花花 """ a = "在写一行" b = "在写另一行" stream.write(s) stream.write(a) stream.write(b) stream.close()
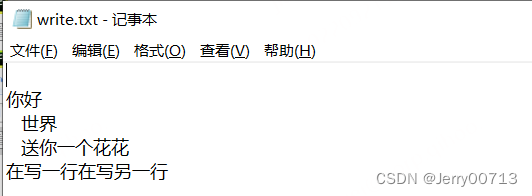
如果要写入的是一个变量,使用
def register():
username = input("输入用户名:")
password = input("输入密码:")
repassword = input("输入确认密码:")
if username == 'admin' and password == '123456':
with open(r'E:\code\dir1\book\user.txt','a') as wstream:
wstream.write('{} {}\n'.format(username,password))
print("用户注册成功")
writelines 一次性写入多行
stream = open(r'E:\code\pythonProject\write.txt', 'w') stream.writelines(['在写一行', '在写另一行']) stream.close()
使用\n 换行
stream = open(r'E:\code\pythonProject\write.txt', 'w') stream.writelines(['在写一行\n', '在写另一行']) stream.close()


4、写文件追加 mode = 'a'
stream = open(r'E:\code\pythonProject\write.txt', 'a') a = "nihao" stream.write(a) stream.close()


5、文件复制
文件复制,先读取一个文件,在将这个文件写入到一个文件
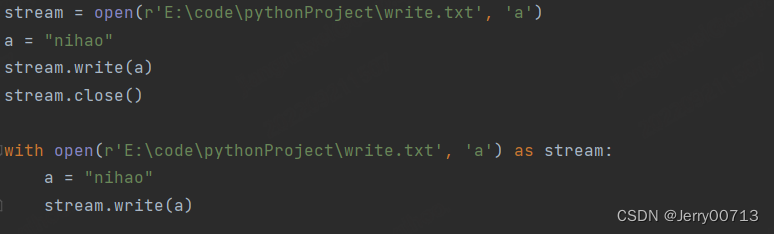
了解一个模板:with open() as ,他的作用跟我们正常使用的一样,但不需要再写clone,自动帮助我们释放资源 。
stream 是 E:\code\pythonProject\write.txt 别名,通过stream.name 查看
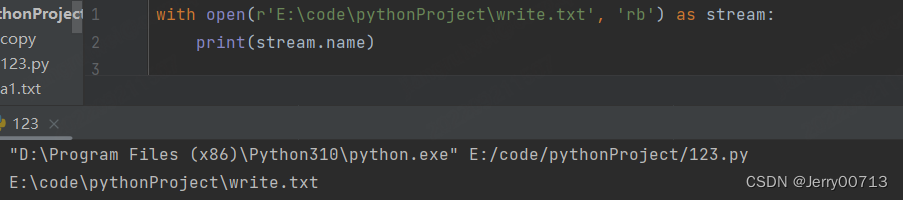
截取E:\code\pythonProject\write.txt的write.txt,主要用于文件上传,你不知到源文件是什么,通过此方式获取文件名字
with open(r'E:\code\pythonProject\write.txt', 'rb') as stream: print(stream.name) file = stream.name # E:\code\pythonProject\write.txt print(file.rfind('\\')) # 通过右find找到最后一个\的index = 21 print(file[file.rfind('\\')+1:]) # 使用截取,从下表 21+1开始,到最后
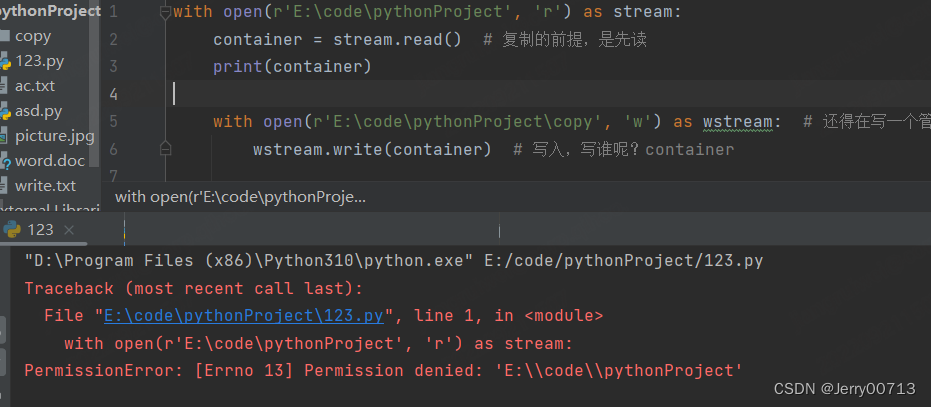
with open(r'E:\code\pythonProject\write.txt', 'rb') as stream: container = stream.read() # 复制的前提,是先读 print(container) with open(r'E:\code\pythonProject\copy\write.txt', 'wb') as wstream: # 还得在写一个管道,因为open mode = rb 只能读,或者 open mode = wb 只能写 wstream.write(container) # 写入,写谁呢?container
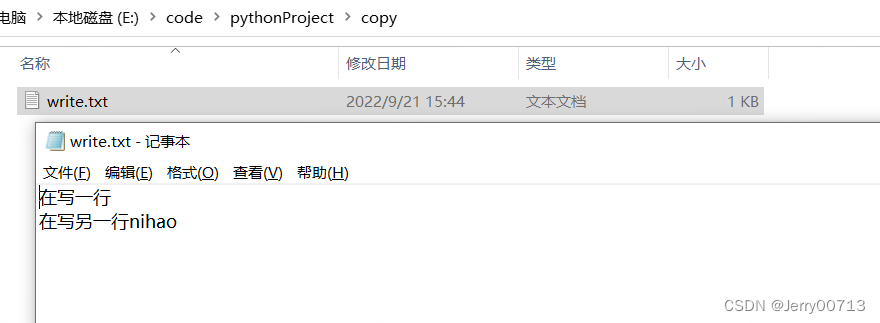
在上述的案例中不能复制文件夹,open必须是文件
2、os 模块
1、os.path
os.path 打印 python 的 路径
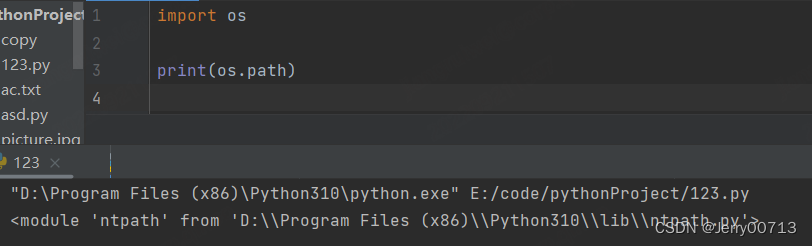
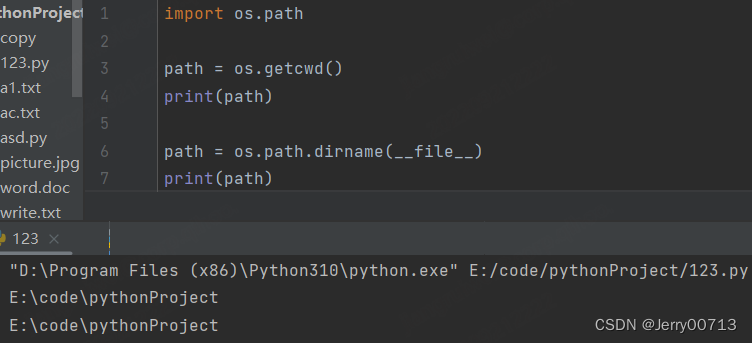
os.path.dirname() 返回当前目录名字,而且是绝对路径
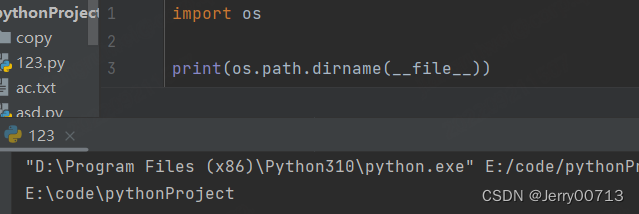
os.path.dirname(__file__) # __file__ 表示当前自己
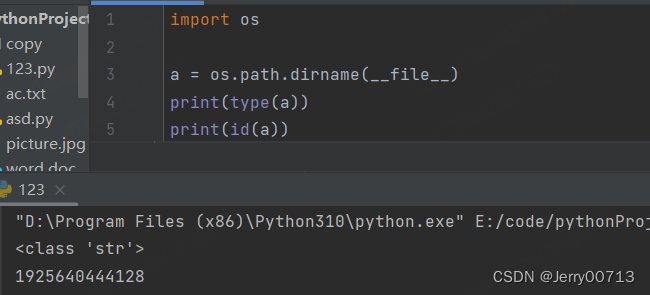
a = os.path.dirname(__file__) print(type(a)) # 这个路径是一个字符串 print(id(a))
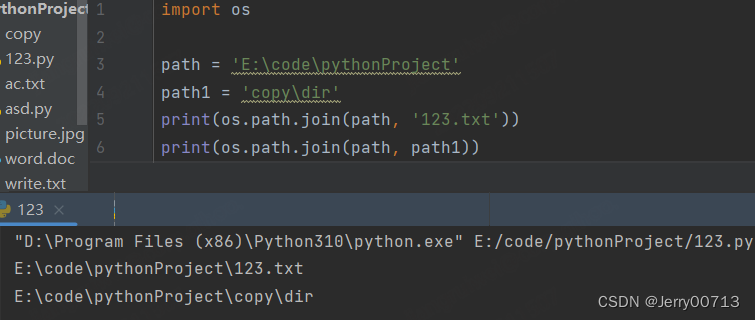
os.path.join() 将路径拼接
path = 'E:\code\pythonProject' path1 = 'copy\dir' print(os.path.join(path, '123.txt')) print(os.path.join(path, path1))
os 实现复制文件
import os.path with open(r'E:\code\pythonProject\write.txt', 'rb') as stream: container = stream.read() path = os.path.dirname(__file__) path1 = os.path.join(path, 'a1.txt') with open(path1, 'wb') as wstream: wstream.write(container)
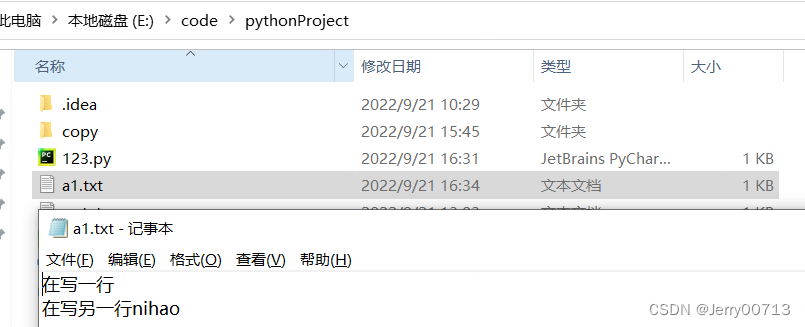
os.absolute 是不是绝对路径
import os.path r = os.path.isabs(r'E:\code\pythonProject\write.txt') print(r) # True 绝对路径 r = os.path.isabs(r'pythonProject\write.txt') print(r) # False 相对路径 r = os.path.isabs(r'..\..\write.txt') # ..\ 上一级目录 print(r) # False
os.path.abspath 给我一个相对路径,返回绝对路径
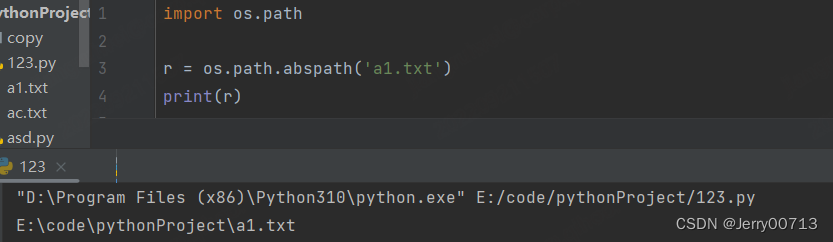
获取当前文件的绝对路径,比如我使用123.py 执行的代码,打印123.py的绝对路径
import os.path r = os.path.abspath(__file__) print(r)
os.path.isfile 是一个文件么? os.path.isdir 是一个目录么?
r = os.path.isfile(os.getcwd()) print(r) # False r = os.path.isdir(os.getcwd()) print(r) #True
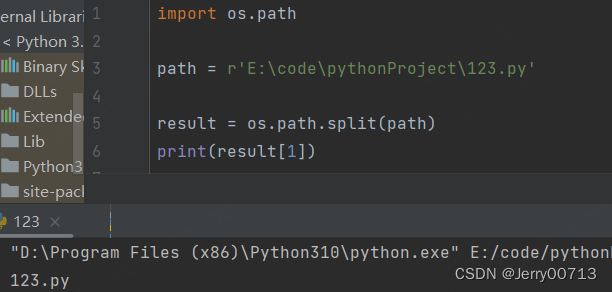
os.path.split 将一个绝对路径的文件进行拆分成两个部分,一个是文件所在路径,一个是文件名,将这两个信息组成一个元组
path = r'E:\code\pythonProject\123.py' result = os.path.split(path) print(result)

获取文件名
方式一:

方式二:
os.path.splitext 将一个绝对路径的文件进行拆分成两个部分,在最后扩展名之前为一个,扩展名一个,将这两个信息组成一个元组,专门分割文件与扩展名
import os.path path = r'E:\code\pythonProject\123.py' result = os.path.splitext(path) print(result)

os.path.getszie 获取文件大小,返回单位是字节个数
import os.path path = r'E:\code\pythonProject\123.py' size = os.path.getsize(path) print(size) # 107
os.path.exists 判断是否有此文件夹或者文件,反会bool
result = os.path.exists(r'E:\code\pythonProject\a1.txt') print(result) # True
2、os.下的函数
os.listdir 指定目录下的所有的文件和文件夹,返回一个列表
import os path = r'E:\code\pythonProject' result = os.listdir(path) print(result)

os.getcwd() 当前文件的文件夹,类似于os.path.dirname(__file__)
os.mkdir 创建目录
import os result = os.mkdir(r'E:\code\p1') print(result) # 返回 None
文件夹已经存在会报错,所以最好创建之前需要判断,建议使用os.path.exists
import os if not os.path.exists(r'E:\code\dir'): result = os.mkdir(r'E:\code\dir') print(result)
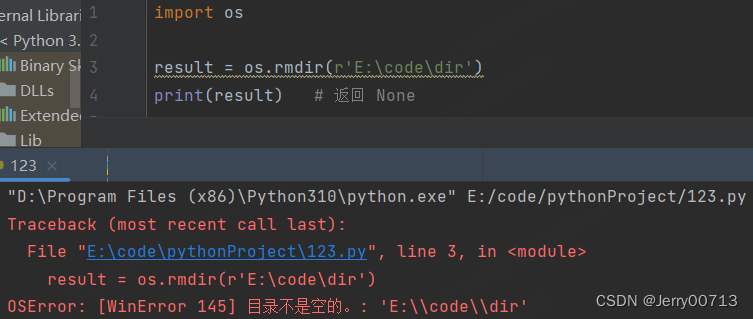
os.rmdir 删除文件夹,只能删除空目录文件夹。不存在目录会报错,所以最好删除之前需要判断,建议使用os.path.exists 。os.removedirs 功能一样
import os result = os.rmdir(r'E:\code\p1') print(result) # 返回 None
注意 os.rmdir os.removedirs 只能删除空目录
如何删除非空目录,个人觉得,傻的一笔
import os
path = r'E:\code\dir'
filelist = os.listdir(path) #
print(filelist)
for file in filelist:
path1 = os.path.join(path.file)
os.remove(path)
else:
os.rmdir(path)
print("删除成功")
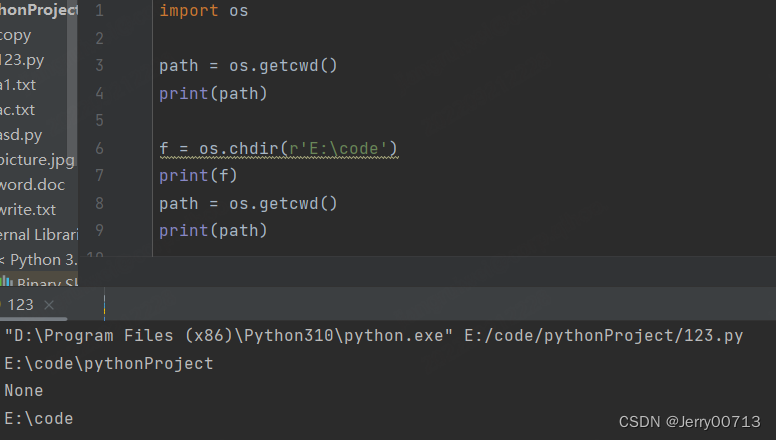
os.chdir() 切换目录
import os path = os.getcwd() print(path) f = os.chdir(r'E:\code') print(f) path = os.getcwd() print(path)
3、复制文件夹
案例:复制文件夹中所有内容到另一个目录中
复制文件夹中所有内容,就是将文件夹中的内容复制到另一个目录中,所以是不是可以使用遍历文件夹中内容,然后一个一个复制到另一个文件夹中。注意到目前未知,我们不能对文件夹进行复制操作
import os src = r'E:\code\dir1' dest = r'E:\code\dir2' def copy(src,dest): if os.path.isdir(src) and os.path.isdir(dest): filelist = os.listdir(src) print(filelist) for file in filelist: path = os.path.join(src,file) with open(path,'rb') as stream: container = stream.read() path1 = os.path.join(dest,file) with open(path1,'wb') as stream1: stream1.write(container) else: print("复制完毕") copy(src,dest)
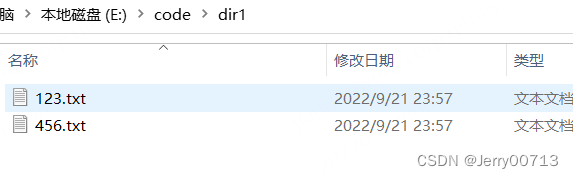
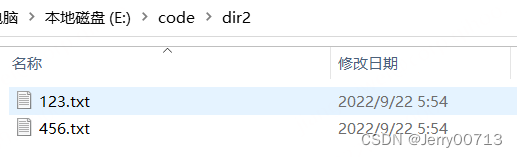

上述中,添加一个文件夹验证,在执行,提示没权限
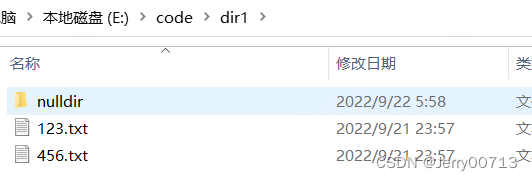
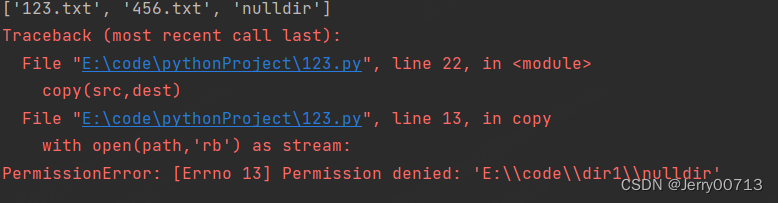
在上述代码中,添加判断,如果是目录进行操作1,不是目录则进行操作2。其中操作 2 不是目录的操作搭建完了,那就考虑是目录,思考如果是目录的话,是不是还是将这个目录中的文件一个一个在复制过去不就行了么,如果在遇到目录,还是将这个目录中的文件一个一个在复制过去不就行了么。·这就是我们的copy函数,典型函数的递归
import os src = r'E:\code\dir1' dest = r'E:\code\dir2' def copy(src,dest): if os.path.isdir(src) and os.path.isdir(dest): filelist = os.listdir(src) for file in filelist: path = os.path.join(src,file) if os.path.isdir(path): # 如果是目录的话,是不是可以进入到此目录中,然后在进行copy,那是不是,跟我们的copy函数的意义一样, # 将文件夹中的内容复制都另一个文件夹中,所以是不是可以是一个函数的递归 dest = os.path.join(dest,file) if not os.path.isdir(dest): os.mkdir(dest) copy(path,dest) else: # 如果不是目录的话 with open(path, 'rb') as stream: container = stream.read() path1 = os.path.join(dest, file) with open(path1, 'wb') as stream1: stream1.write(container) else: print("复制完毕") copy(src,dest)
4、持久化保存
持久化保存,将信息放入文件中或者数据库中,不存在内存中
图书管理系统
# 用户注册
def register():
username = input("输入用户名:")
password = input("输入密码:")
repassword = input("输入确认密码:")
if password == repassword:
with open(r'E:\code\dir1\book\user.txt', 'r') as rstream:
container = rstream.readlines()
# print(container)
for i in range(0,len(container)):
# print(container[i])
a = container[i].find(' ')
# print(a)
# print(container[i][:a])
if container[i][:a] == username:
print("用户已存在")
break
else:
with open(r'E:\code\dir1\book\user.txt', 'a') as wstream:
wstream.write('{} {}\n'.format(username, password))
print("用户注册成功")
else:
print("注册失败,密码不一致")
register()
# 用户登录
def login():
username = input("输入用户名:")
password = input("输入密码:")
with open(r'E:\code\dir1\book\user.txt', 'r') as rstream:
container = rstream.readlines()
for i in range(0, len(container)):
a = container[i].find(' ')
if container[i][:a] == username:
# print(container[i][a+1:])
if container[i][a+1:-1] == password:
print("登录成功")
else:
print("密码错误")
break
else:
print("用户不存在")
# register()
login()
上述的验证用户名跟密码,读取文本成为readlines列表,在通过 for in 取每一个数据,然后通过空格切割,将用户名跟密码切割出来
还有一种,就是将账户和密码组合成 admin 123456 这种形式,对比readlines列表,在通过 for in 取每一个数据
def login():
username = input("输入用户名:")
password = input("输入密码:")
with open(r'E:\code\dir1\book\user.txt', 'r') as rstream:
while True:
line = rstream.readline()
input_user = '{} {}\n'.format(username, password)
print(input_user)
if line == input_user:
print("登录成功")
break
else:
print("登录失败")
break
login()
# 浏览书
def show_books():
print('-----展示图书----')
with open(r'E:\code\dir1\book\books.txt','r') as restream:
books = restream.readlines()
print(books)
for book in books:
print(book,end="")
# register()
show_books()
二、异常机制 try...except
2.1、语法错误、异常
语法错误,如下,number是全局变量,必须通过 gloabl 才能在局部修改,所以报出红色波浪线,这种一般在运行时候,python 能检测语法,程序员可以查看后修改
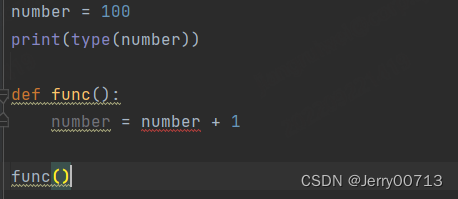
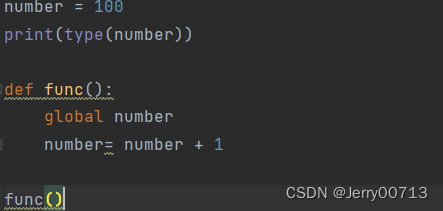
异常:程序员编写时候无任何异常,无报出红色波浪线,但是在真正运行的时候出错,这种程序员不好判断。如下这种,无报出红色波浪线,语法无问题,但是 0 不能作为被除数,数学逻辑不符。而且只要程序出错,出错之下的程序是不会在执行的
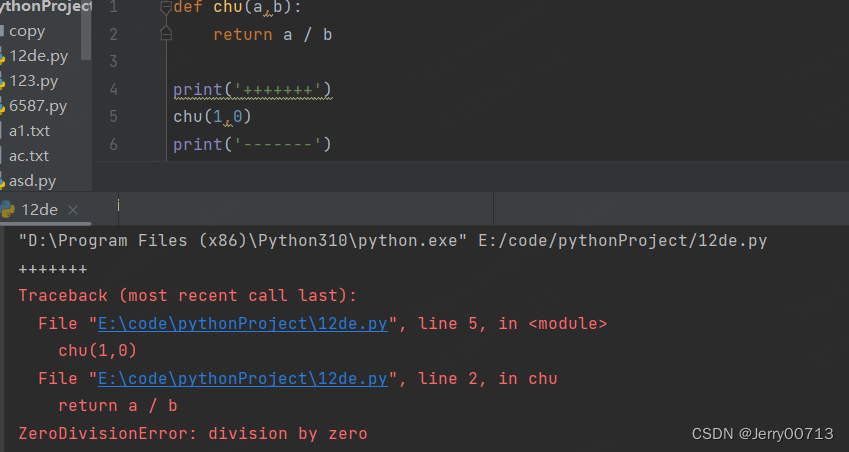
2.2、处理异常格式
格式:try...except....
1、可能出现异常的代码,存在 try 下。在程序运行期间,会执行 try 下代码,如果无任何异常,则不会执行 except.下代码
2、执行 try 下代码,如果此处异常出错,会执行 except.下代码,完成后续的代码
3、try...except.. 缺一不可
try:
# 可能出现的异常代码
except:
# 如果有异常执行的代码
格式:try...except....finally....
4、finally 可有可无,作用无论有没有异常,都会执行的代码
try:
# 可能出现的异常代码
except:
# 如果有异常执行的代码
finally:
# 无论有没有异常,都会执行的代码
2.3、处理异常使用
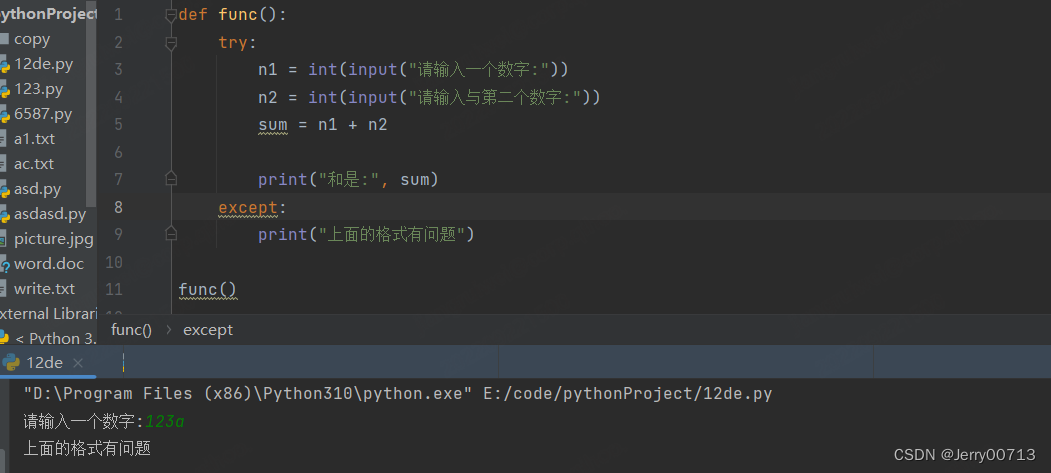
如下,做一个两数相加的代码,会存在一个问题,如果输入的是一个字符串就会报错,在第一步int 就无法将字符串转换成整型
def func(): n1 = int(input("请输入一个数字:")) n2 = int(input("请输入与第二个数字:")) sum = n1 + n2 print("和是:", sum) func()
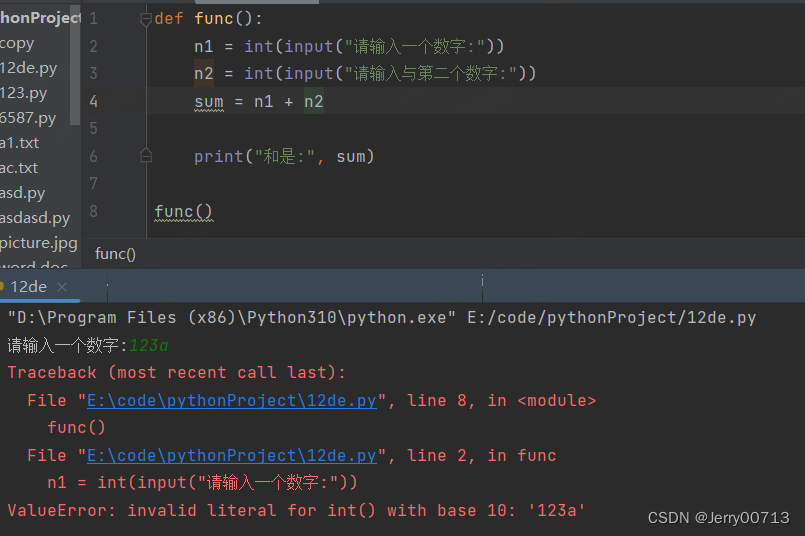
将上述代码加 try except
def func(): try: n1 = int(input("请输入一个数字:")) n2 = int(input("请输入与第二个数字:")) sum = n1 + n2 print("和是:", sum) except: print("上面的格式有问题") func()
思考:一个算数的代码,如果输入了非字符,通过 int 转换失败报错,会执行except,而如果执行除法,但被除数却输入了0,会执行except ,如何区分是 int 转换失败报错,执行了except 还是除法,被除数却输入了0,执行了except
def func():
try:
n1 = int(input("请输入一个数字:"))
n2 = int(input("请输入与第二个数字:"))
per = input("输入运算符号(= - * /):")
num = ''
if per == '+':
result = n1 + n2
num = '加法'
elif per == '-':
result = n1 - n2
num = '减法'
elif per == '*':
result = n1 * n2
num = '乘法'
elif per == '/':
result = n1 / n2
num = '除法'
else:
print("符号输入错误")
print('{}和{}{}结果是:{}'.format(n1, n2, num, result))
except:
print("上面的格式有问题")
func()
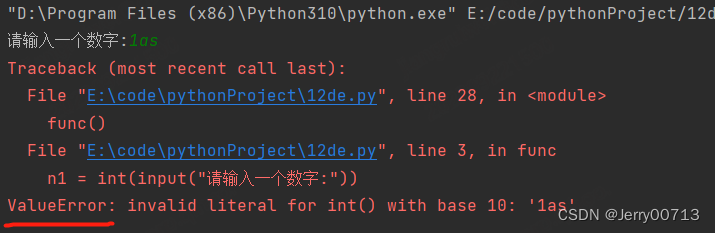
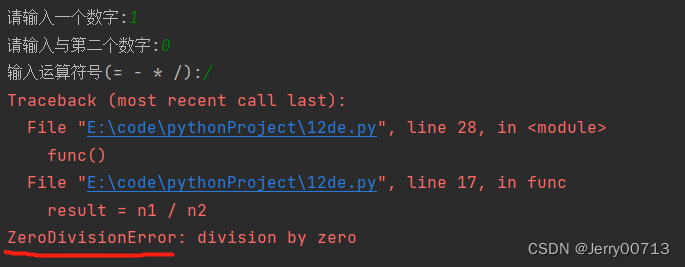
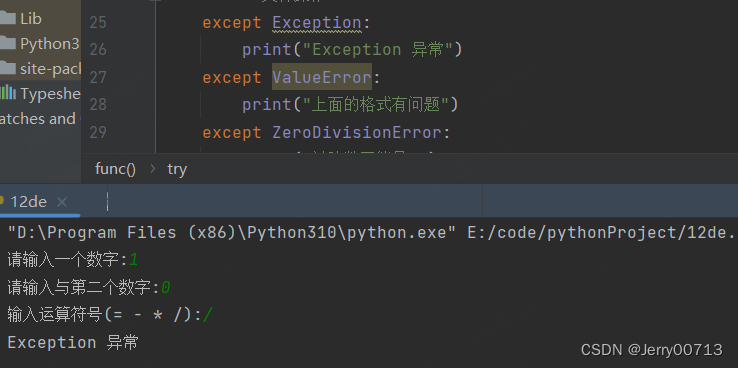
为了解决上述问题,通常需要报错的类型,区分返回那个except
int 转换失败报错 ValueError
被除数却输入了0报错ZeroDivisionError
改写代码
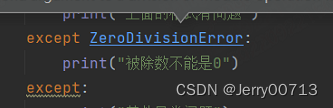
def func(): try: n1 = int(input("请输入一个数字:")) n2 = int(input("请输入与第二个数字:")) per = input("输入运算符号(= - * /):") num = '' if per == '+': result = n1 + n2 num = '加法' elif per == '-': result = n1 - n2 num = '减法' elif per == '*': result = n1 * n2 num = '乘法' elif per == '/': result = n1 / n2 num = '除法' else: print("符号输入错误") print('{}和{}{}结果是:{}'.format(n1, n2, num, result)) except ValueError: print("上面的格式有问题") except ZeroDivisionError: print("被除数不能是0") except: print("其他异常问题") func()


2.4、异常函数归纳
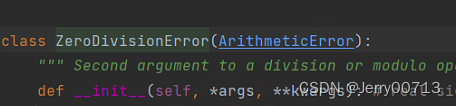
查看 ZeroDivisionError 函数
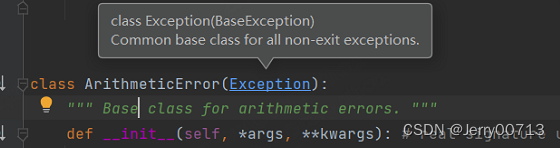
ZeroDivisionError 函数是子类,继承的 ArithmeticError 这个父类
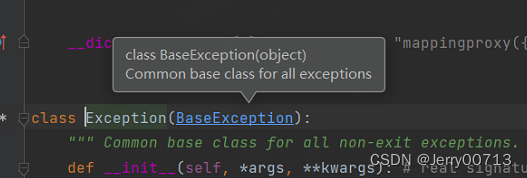
ArithmeticError函数是子类,继承的 Exception 这个父类
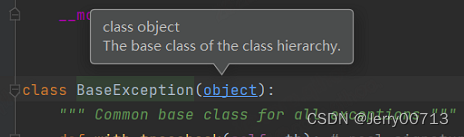
Exception函数是子类,继承的 BaseException 这个父类
BaseException 函数是子类,继承的 object 这个父类
object 类

查看 ValueError 函数
ValueError 函数是子类,继承的 Exception 这个父类
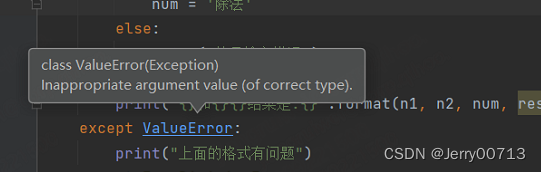
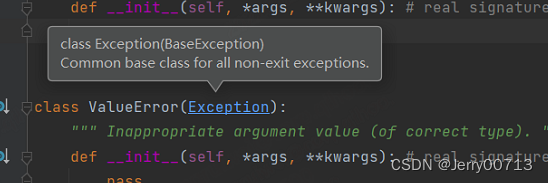
总结:两个函数都继承了 Exception 这个父类,所以所有的...Error都是继承的 Exception 这个父类
注释事项:
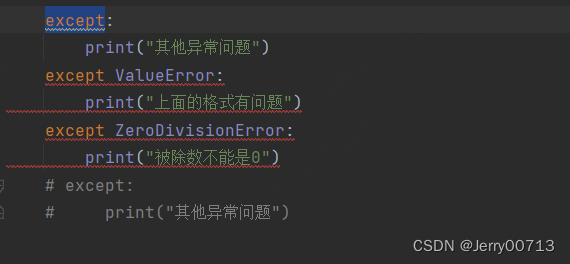
1、因为py是按照顺序执行代码,所以不能将 except 放置最前
2、如果是填写的父进程,按照顺序,就会执行了父进程
所以 Exception 一定要放在子函数的最下面
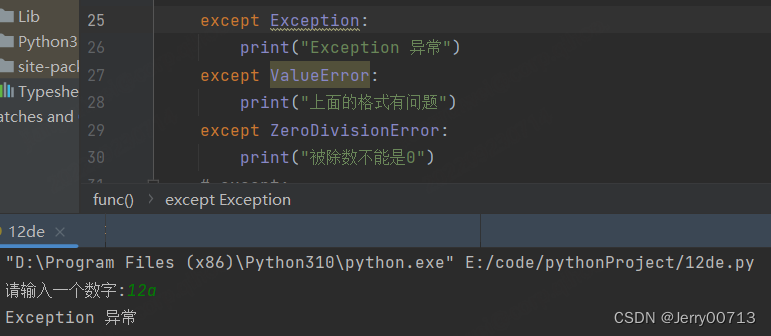
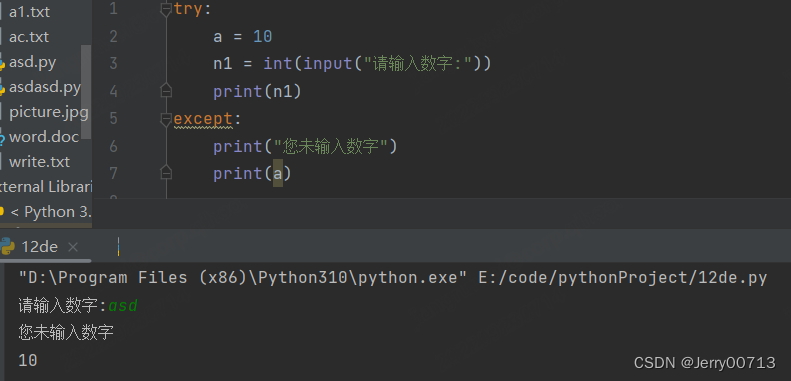
except ValueError: print("上面的格式有问题") except ZeroDivisionError: print("被除数不能是0") except Exception: print("Exception 异常")3、try 中在遇到报错之前的代码是已经加载到内存中的,不影响
try: a = 10 n1 = int(input("请输入数字:")) print(n1) except: print("您未输入数字") print(a)
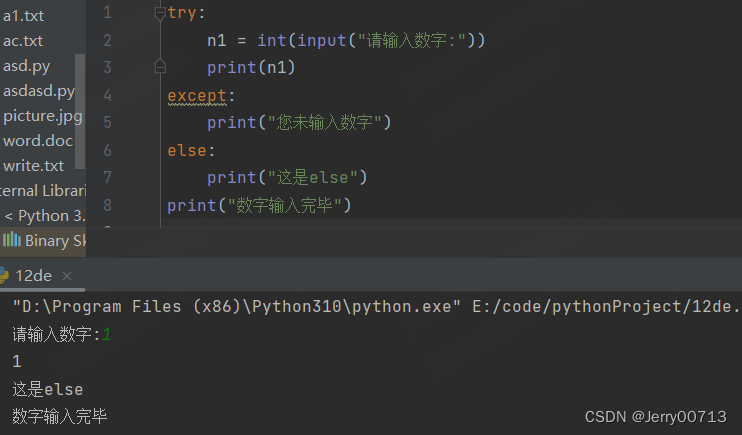
2.5、try...except....else....
1、try 代码无异常,执行 try 代码,不执行 except 代码,执行else 代码,执行后续代码,可以理解 try 是 if ,try 对应的就有 else,而 else 写不写都行
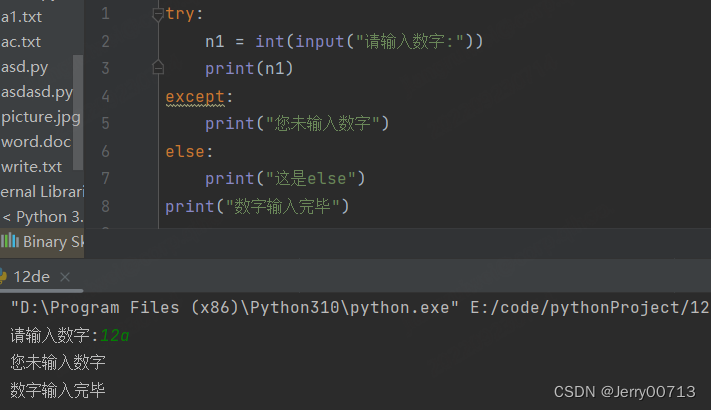
2、try 代码异常,不执行 try 代码,执行 except 代码,不执行 else 代码,执行后续代码
2.6、函数体 try 、except 存在 return
如果 try 中存 return ,则直接退出函数,后续代码无法执行,所以函数体 try 中不能存在 return。
def func(): try: n1 = int(input("请输入数字:")) return 1 except: print("您未输入数字") return 2 else: print("这里是else") print("数字输入完毕") a = func() print(a)
如果 except 中存 return ,会执行return ,但不会执行else,后续代码会继续执行
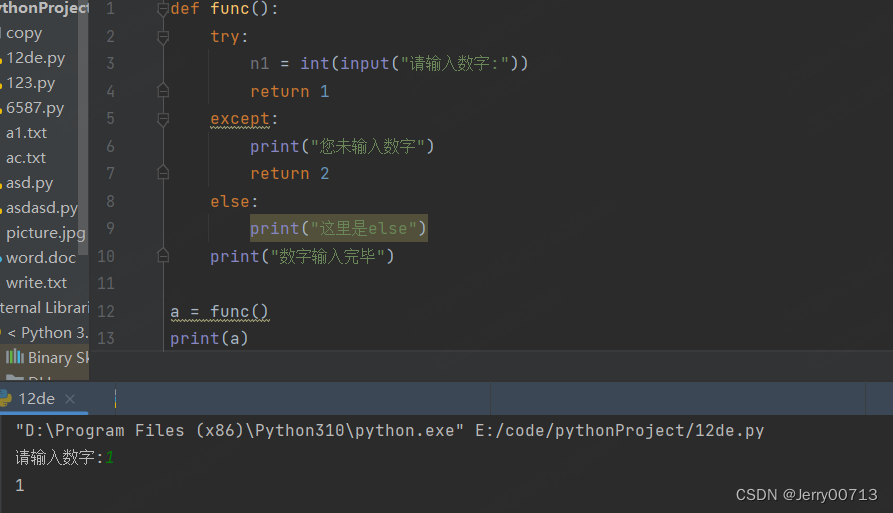
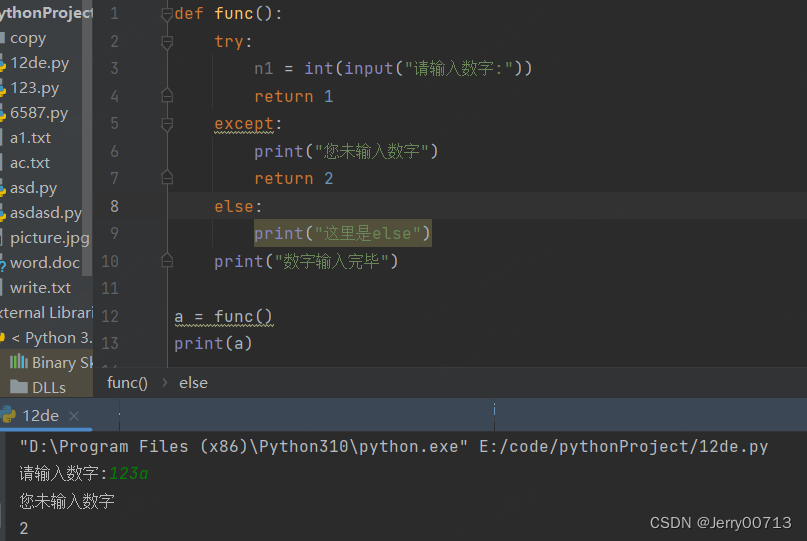
2.7、如何知道错误原因
出错了,如何打印出错原因
except ValueError as err: print("上面的格式有问题" , err)

2.7、try...except....finally....
try:
# 可能出现的异常代码
except:
# 如果有异常执行的代码
finally:
# 无论有没有异常,都会执行的代码
使用场景:如文件操作、数据库操作,都需要clone
文件操作,stream = open(....) streat.read() stream.clone() 打开一个文件,假如打开的时候是mode = r ,但是read的时候是一个图片,会导致无法读取,所以在 try 中需要写 open() 和read()和stream.clone() ,而如果存在异常,则 except 中打印 文件存在异常,还要写stream.clone(),因为在try 中执行了open() ,是后续read()出错
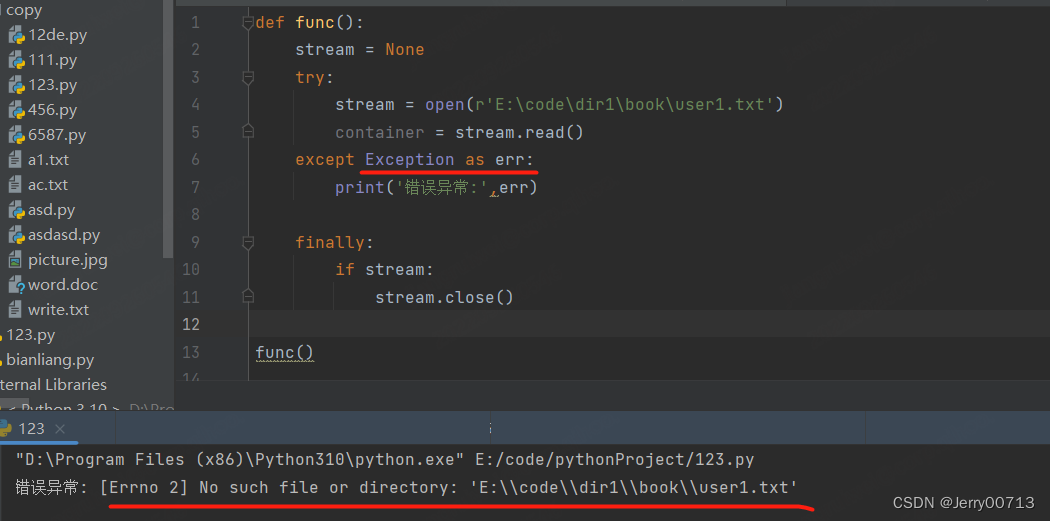
def func(): stream = None try: stream = open(r'E:\code\dir1\book\user1.txt') container = stream.read() print(container) except Exception as err: print(err) finally: print('-----finally------') if stream: stream.close() func()
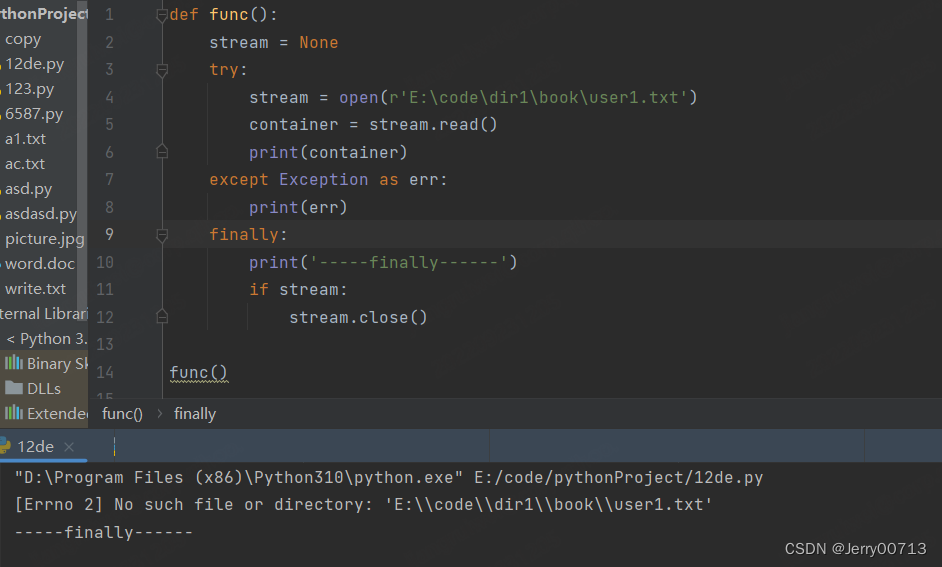
2.8、try...except...esle...finally.... 变量
1、try...except...finally.... 模块中代码相互隔离的,可以理解为是函数,局部函数与局部函数中的代码相互隔离
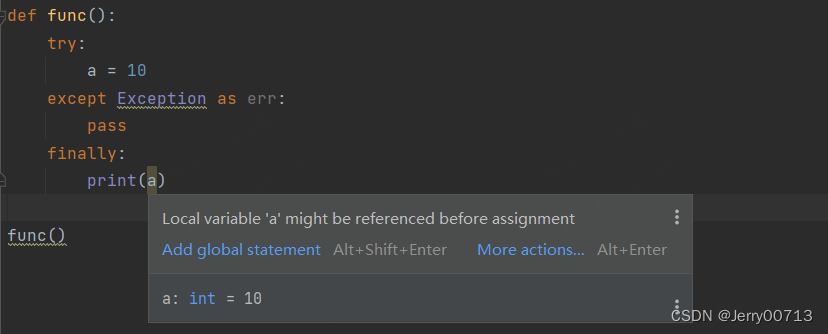
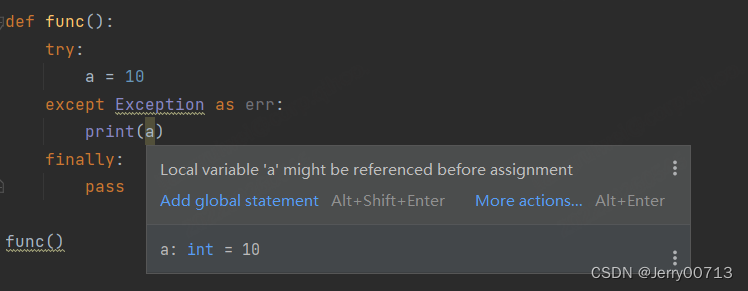
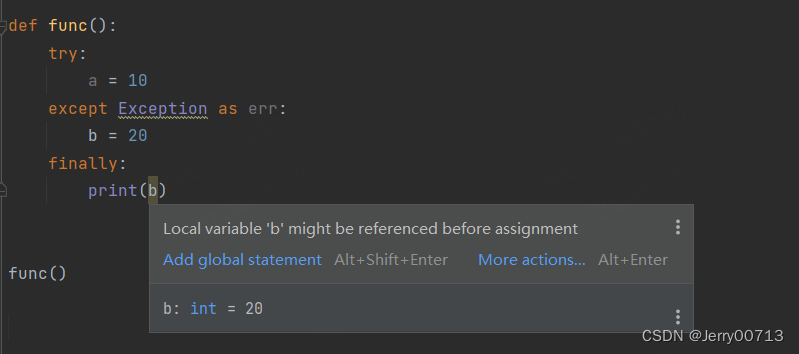
2、try...except...esle...finally....,在上述我们知道,try 代码无异常,执行 try 代码,不执行 except 代码,执行 else 代码,执行 finally 代码,执行后续代码,可以理解 try 是 if ,try 对应的就有 else,而 else 写不写都行,所以 try else 是一个模块。所以try...esle... 下的代码是一块的
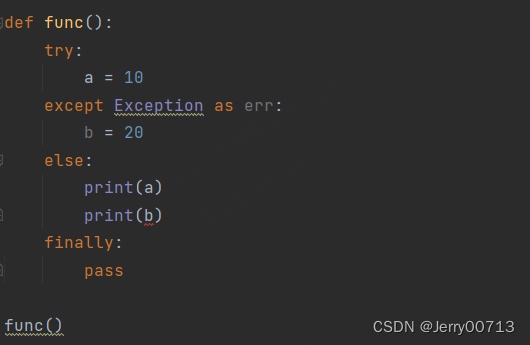
3、最后都会执行 finally ,所以 finally 下的代码并不是不能使用 try 或者 except 下代码中的变量,而且在代码执行之前,finally 并不知道上述执行的是 try 下的代码还是 except 下代码。所以说,finally 是可以引用已经执行的代码中的变量,但是在声明的时候,它并不知道是 try 下的代码还是 except 下代码,所以在声明的时候,可以在全局变量中声明,等代码运行后,在通过局部变量对重新赋值。

案例:1、为什么添加 stream = None 就不会报错,上述阐明,是因为定义的时候,不知道是运行的try 下的代码还是except 下的代码,如果是except 是没有stream的变量,所以先需要声明全局变量。2、需要知道,stream = open(r'E:\code\dir1\book\user1.txt'),如果不存在,open是打不开的,也就是说,如果不存在,在内存中根本无此变量。所以,假如try 执行stream = open(r'E:\code\dir1\book\user1.txt') 报错,在运行finally,if stream 是假,因为现在的 stream 等于全局变量的 None。
def func(): stream = None try: stream = open(r'E:\code\dir1\book\user1.txt') container = stream.read() except Exception as err: print(err) stream = open(r'E:\code\dir1\book\user.txt') container1 = stream.read() else: a = [7, 8] finally: if stream: stream.close() func()
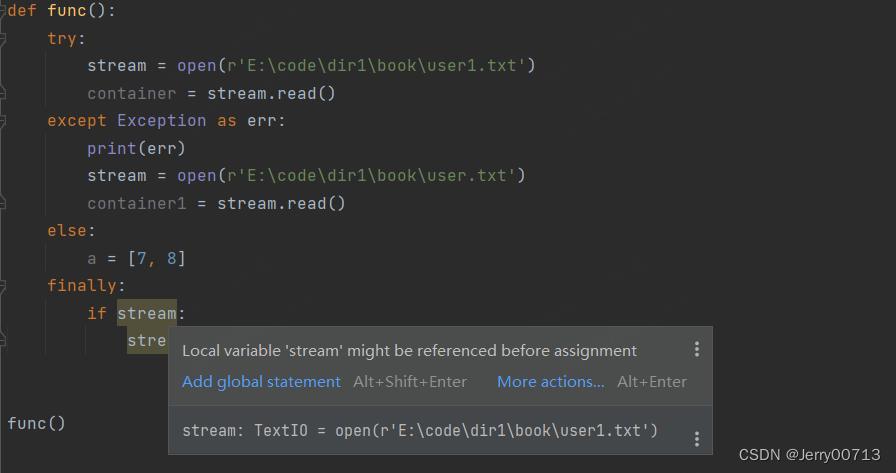
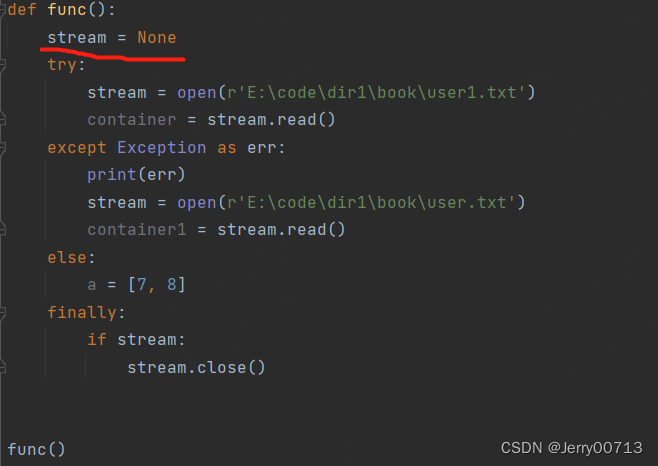
注意:上述我们讲过,finally 下的代码并不是不能使用 try 或者 except 下代码中的变量,而且在代码执行之前,finally 并不知道上述执行的是 try 下的代码还是 except 下代码。所以说你可以忽略他的警告,但是如果确定在 try 中 stream 是存在的,一定会有stream变量,运行到finally后,执行stream.clone() 无任何问题,如果 stream 是不存在的,在 finally 中,不管是 if stream 还是 stream.clone() 都会报错,因为就没有 stream 这个变量,无法判断 和 clone
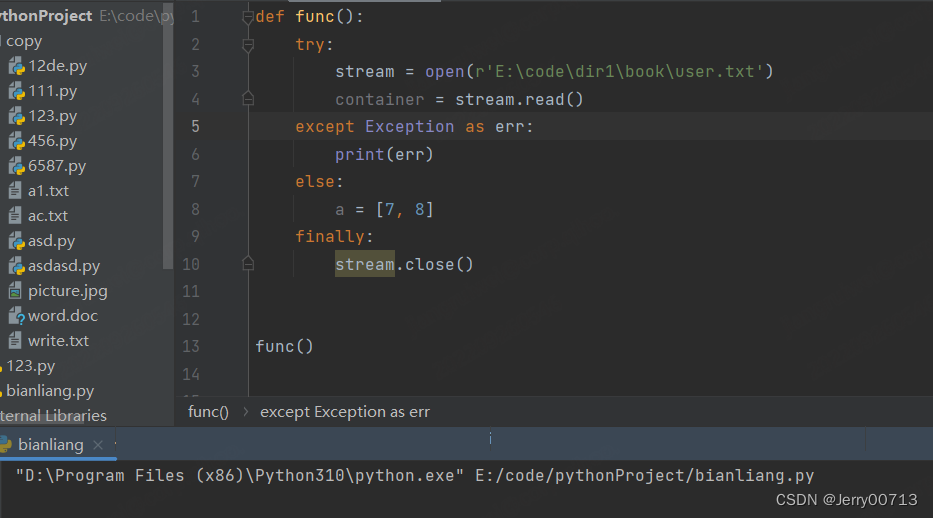
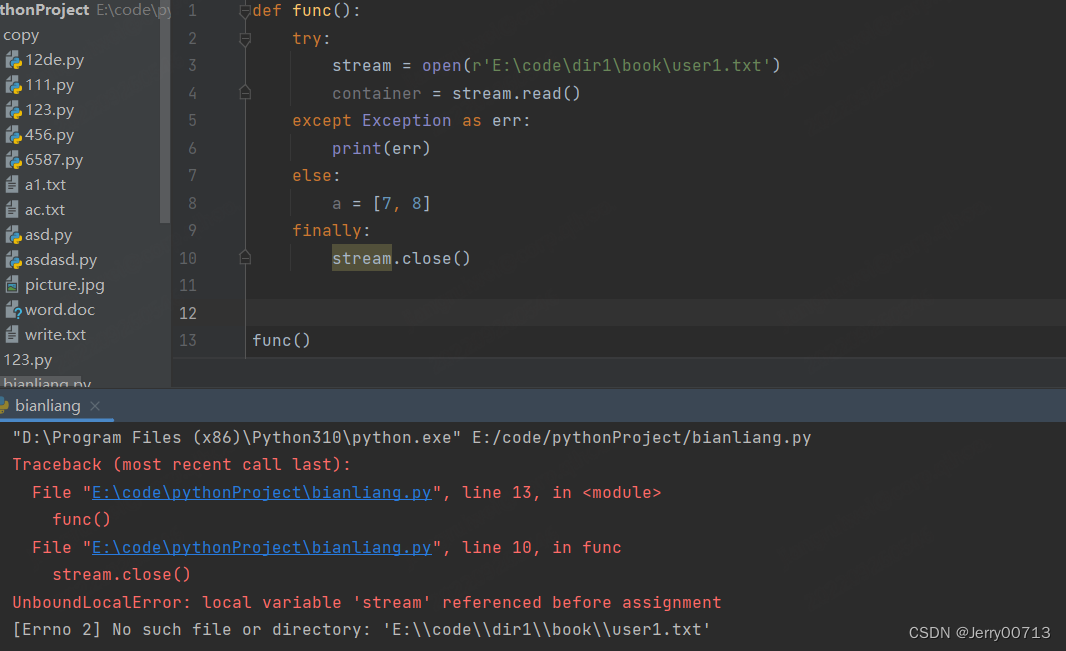
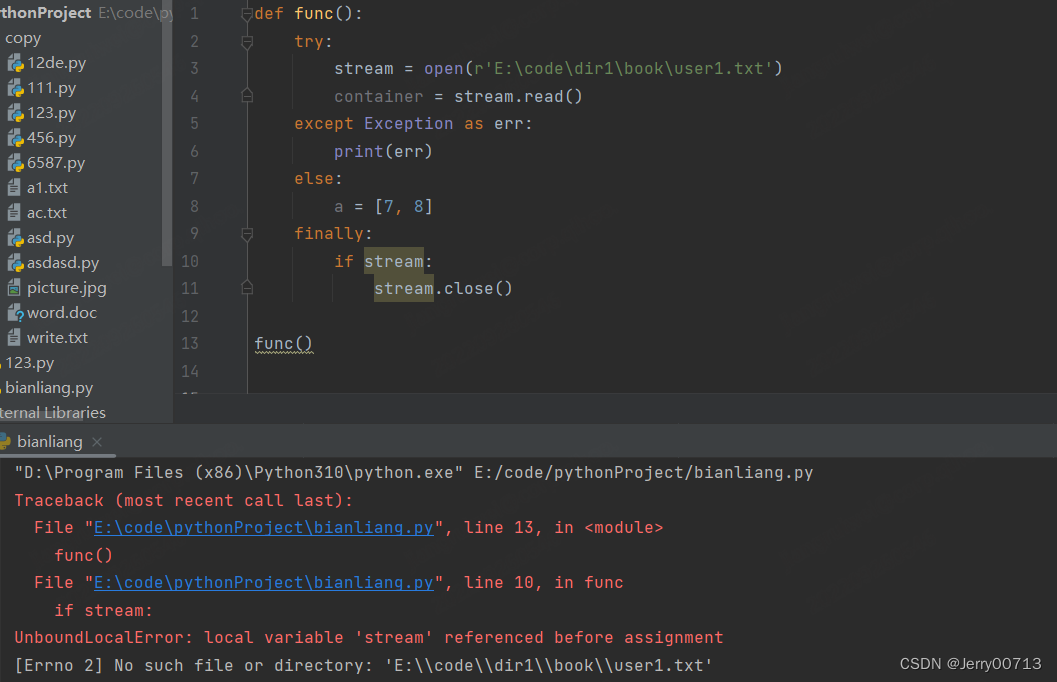
2.9、return 返回数值
1、try else 模块,在 try 下添加 return ,else一定是不运行的
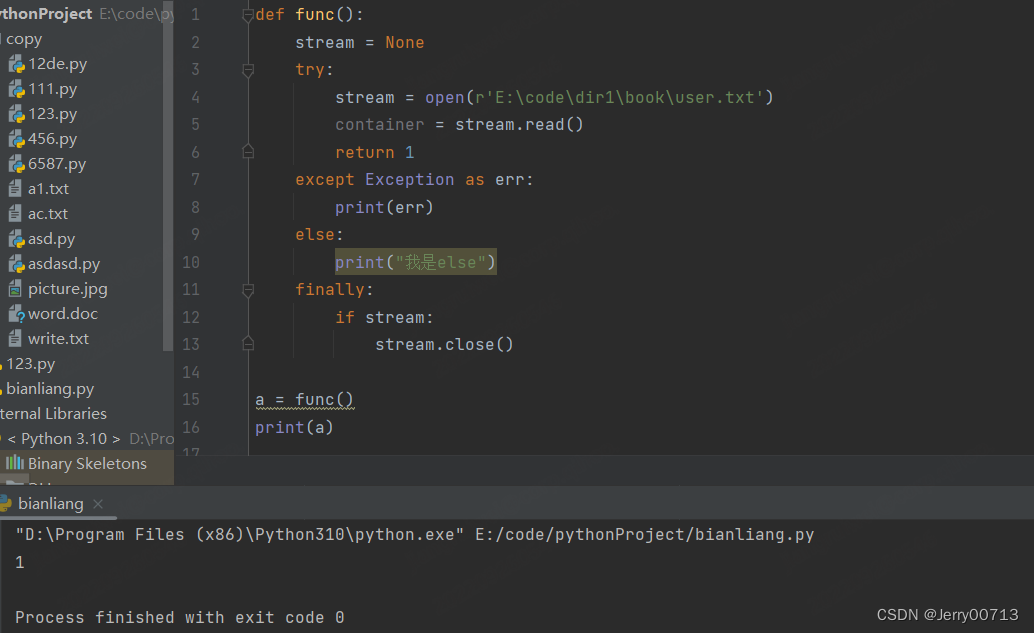
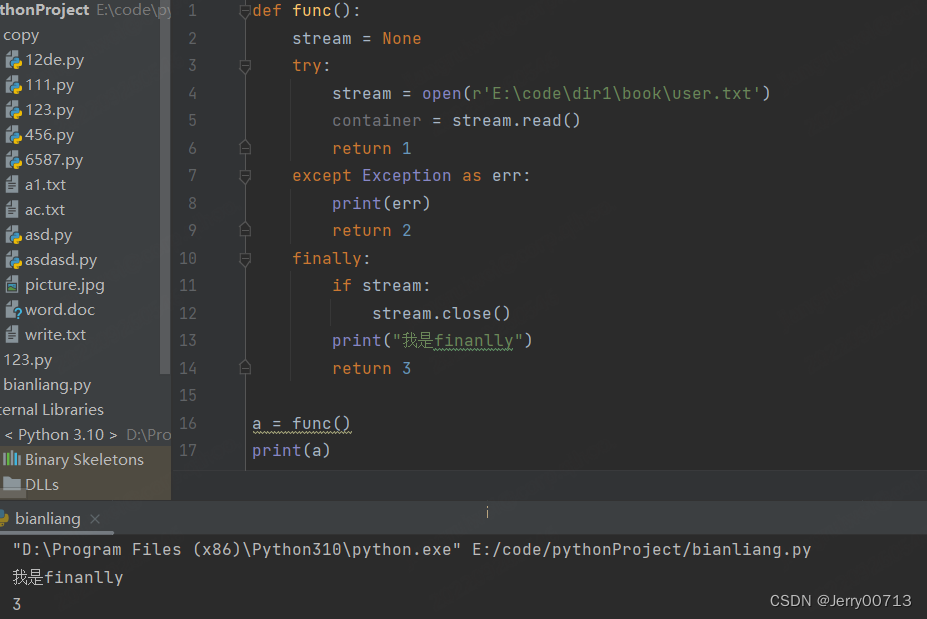
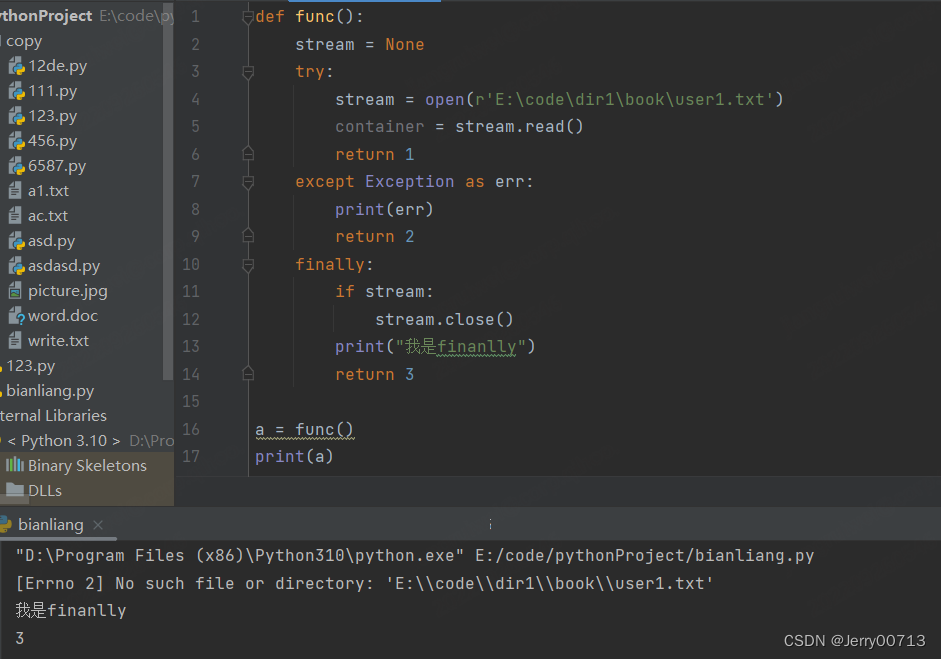
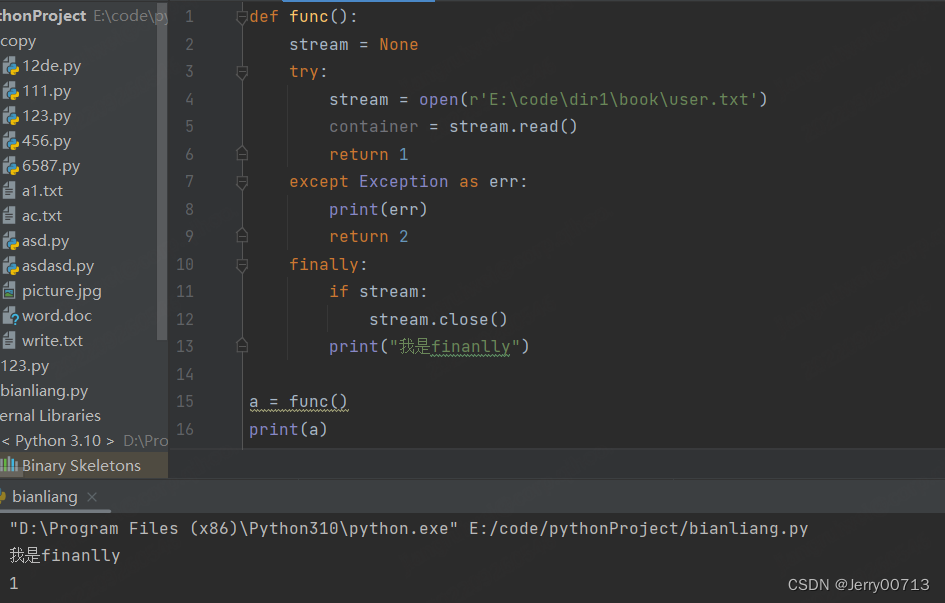
2、程序无问题,执行 try 下的程序遇到 return 1,此时可以理解为 return = 1,但此时并不会直接退出,而且继续运行 finally ,直到结束后遇到了 return 3,将 return = 3。程序报错,执行 except下的程序遇到 return 2,此时可以理解为 return = 2,但此时并不会直接退出,而且继续运行 finally ,直到结束后遇到了 return 3,将 return = 3。
def func(): stream = None try: stream = open(r'E:\code\dir1\book\user.txt') container = stream.read() return 1 except Exception as err: print(err) return 2 finally: if stream: stream.close() return 3 a = func() print(a)
2.10 、抛出异常 raise
raise 为自定义抛出什么样子的异常
# 注册 用户名必须6位 def register(): username = input("请输入用户名:") if len(username) < 6: raise Exception('用户名必须是6位以上') else: print("输入的用户名是:", username) register()
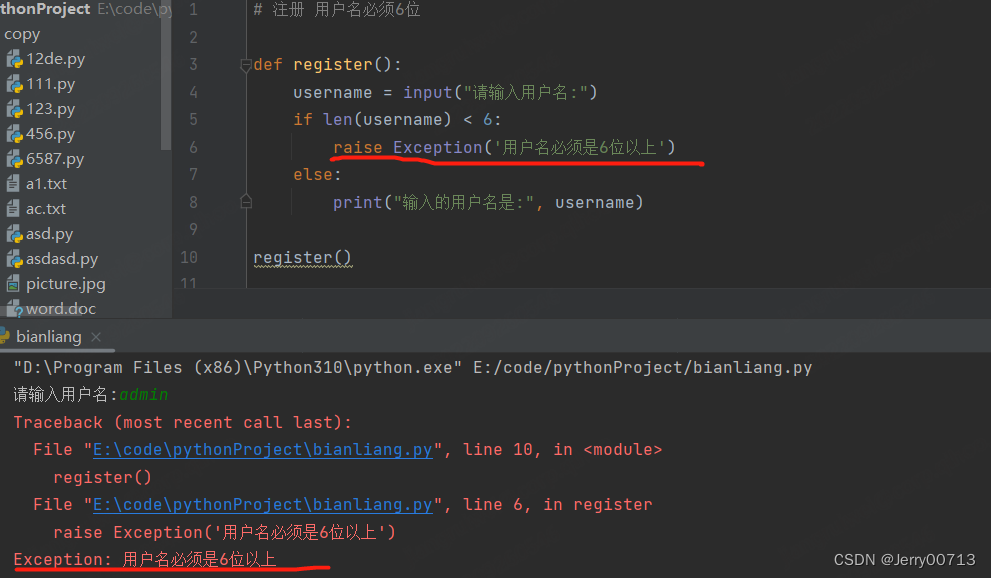
raise 结合 try except ,在之前已经讲述了 except Exception as err: 的作用
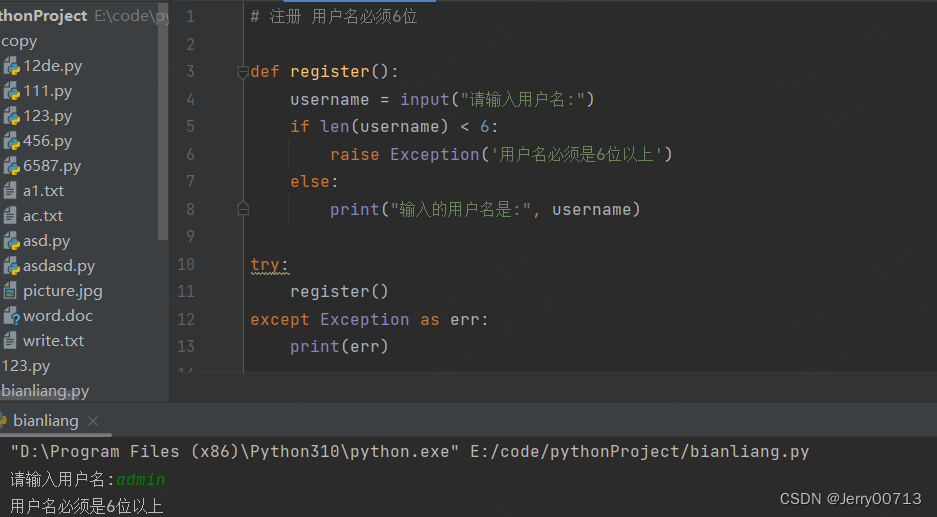
# 注册 用户名必须6位 def register(): username = input("请输入用户名:") if len(username) < 6: raise Exception('用户名必须是6位以上') else: print("输入的用户名是:", username) try: register() except Exception as err: print(err)
三、生成器
什么是生成器:
1、生成器依赖于列表、集合、字典推导式
2、创建一个列表会将所有的列表的信息存入导内存中,但是由于内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面的几个元素,那后面的绝大数元素占用得到空间就浪费了。所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必要创建完整的list,从而节省大大量空间。在python中,这种一边循环一边计算的机制,叫做生成器:generator。使用方法跟列表推导致一致,只不过使用()
3.1、生成一个生成器
newlist = [x*3 for x in range(20)] print(newlist) # [0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48, 51, 54, 57] g = (x*3 for x in range(20)) print(g) # <generator object <genexpr> at 0x0000014B84DB65E0> 打印的是生成器的地址 print(type(g)) # <class 'generator'> 说明是生成器

调用生成器中的内容
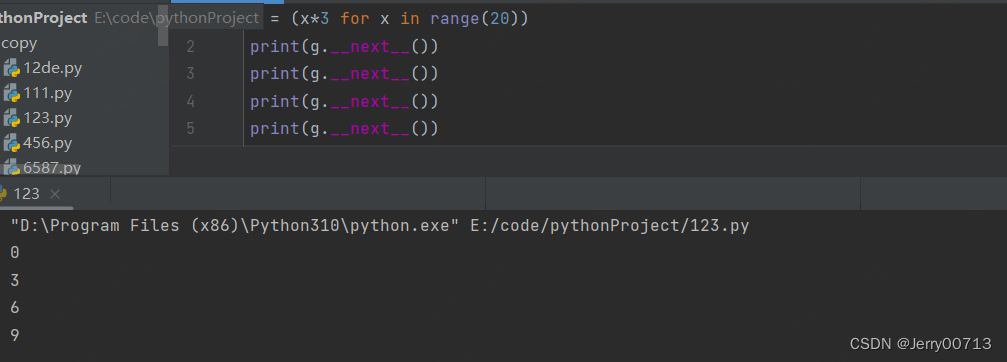
方式一:调用 g.__next__() 执行一次打印一个
g = (x*3 for x in range(20)) print(g.__next__()) print(g.__next__()) print(g.__next__()) print(g.__next__())
方式二:next(g) 执行一次打印一个,此方法是系统内置的
g = (x*3 for x in range(20)) print(next(g)) print(next(g)) print(next(g))
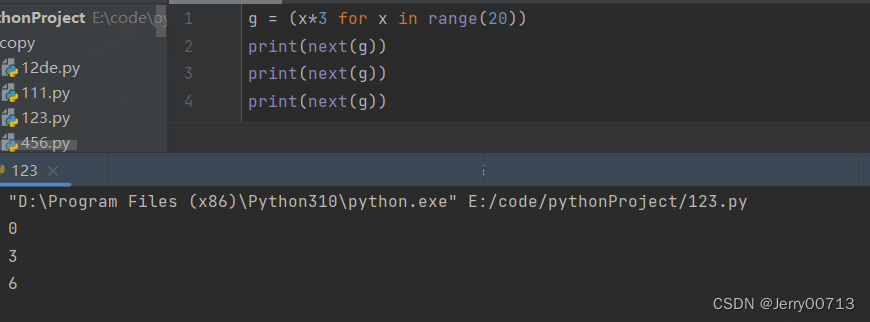
如果超出生成器给出的数值,将会提示 StopIteration
g = (x*3 for x in range(5)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g))
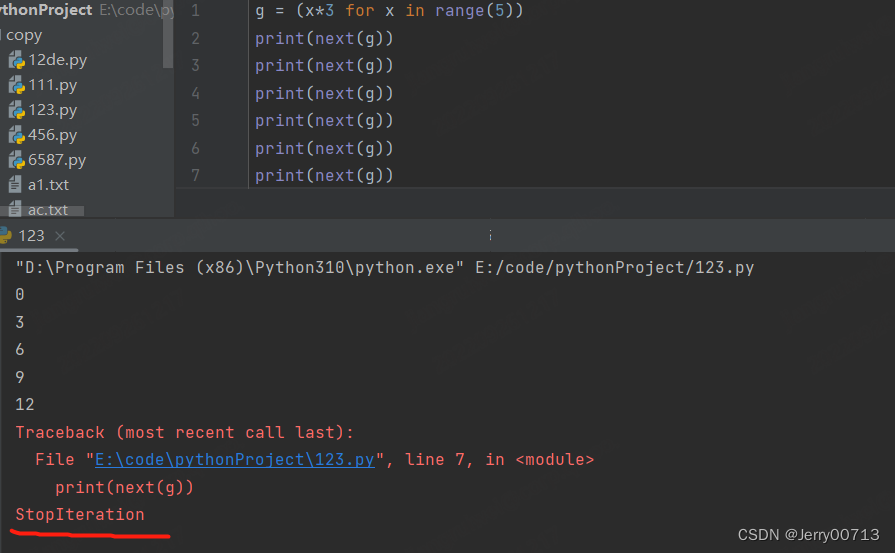
使用 try except 解决 超出生成器给出的数值,将会提示 StopIteration
g = (x*3 for x in range(5)) while True: try: e = next(g) print(e) except: break
3.2、函数生成器
在函数中带有 yield ,则此函数不是函数,而是变成生成器,实现函数的机制,只要需要生成器,直接调用用函数生成器。格式:函数中带有yield,用变量接收调用函数方法,并使用 next() 打印
def func(): n = 0 while True: n += 1 # print(n) yield n a = func() print(a) print(next(a)) print(next(a))

使用debug工具分析
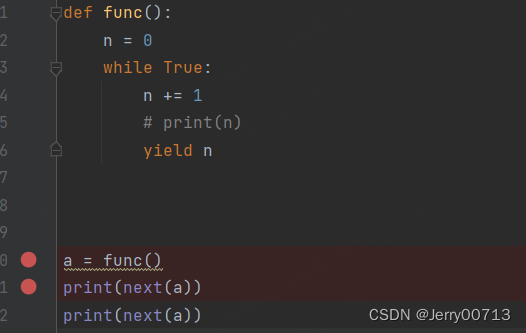
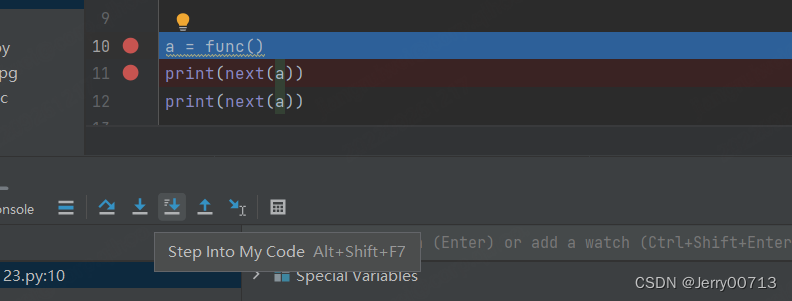
在执行到 a = func() 后,点击进去代码中,发现是不进入生成器
在执行到 print(next(a)) 后,点击进去代码中
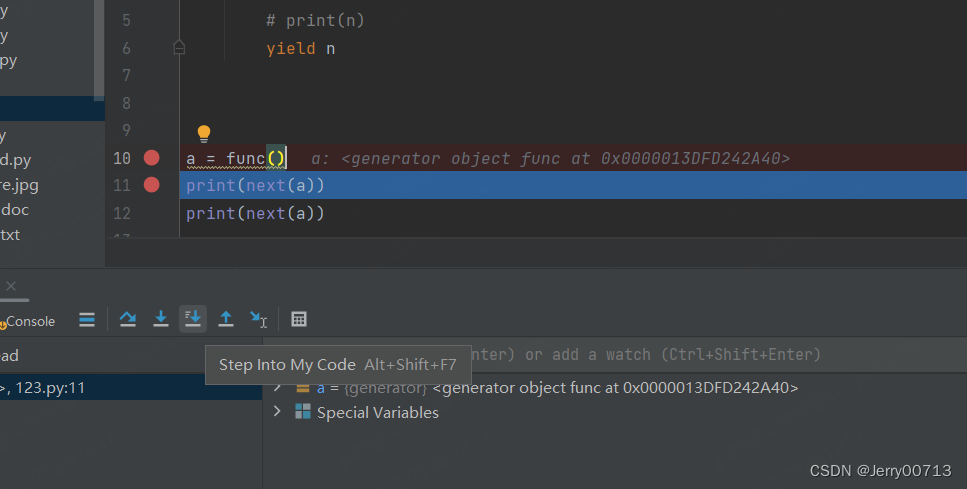
会发现执进制了生成器,所以只有调用 next 后才会进入生成器
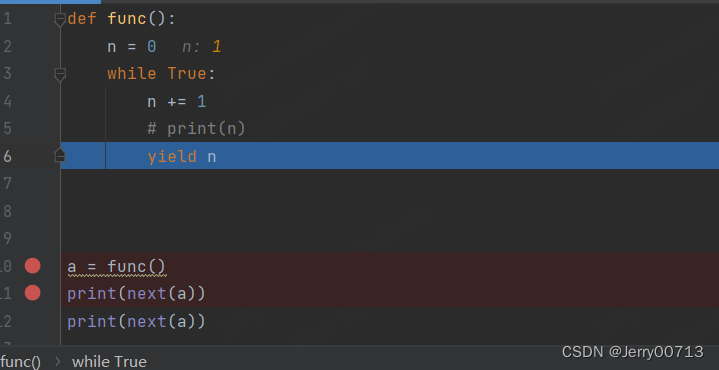
执行 yield 后,发现 n 变成了 1,所以这个 yield 类似 retutn + 暂停,暂停的意思是,停留在这个位置,等下次在调用此生成器的时候,会继续在此基础上在运行
3.3、函数生成器 return
生成器是没有任何数据可以产生了,想给出一个提示,往往添加到 return
def func(a): n = 0 while n < a: n += 1 yield n return "已完毕" a = func(5) print(next(a)) print(next(a)) print(next(a)) print(next(a)) print(next(a)) print(next(a))
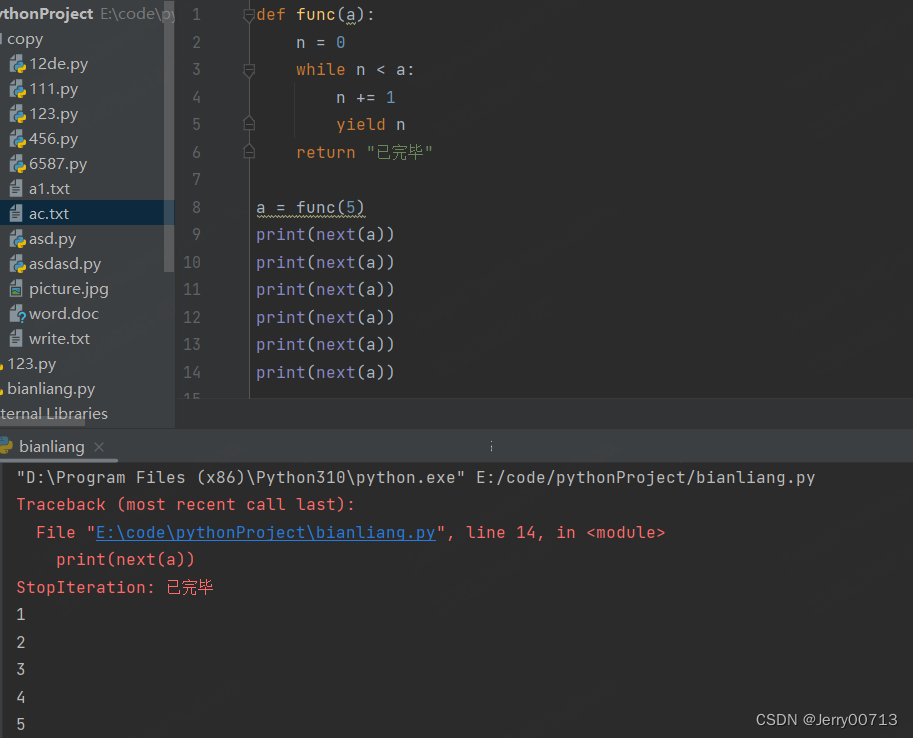
3.4、斐波那切数列+生成器
def lib(len): a, b = 0, 1 n = 0 while n < len: print(b) a, b = b, a + b n += 1 lib(8)
def lib(len): a, b = 0, 1 n = 0 while n < len: yield b a, b = b, a + b n += 1 g = lib(8) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g))

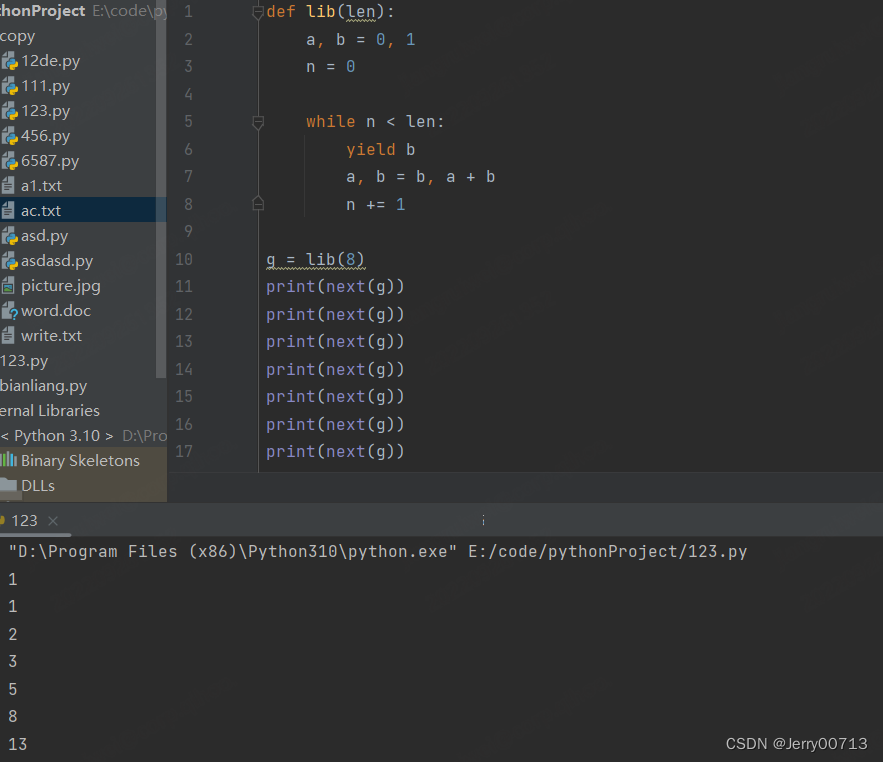
3.5、调用生成器 send()
提示,在你的的生成器开始的时候,不能发送一个非None的值,意思是,第一个数值给None
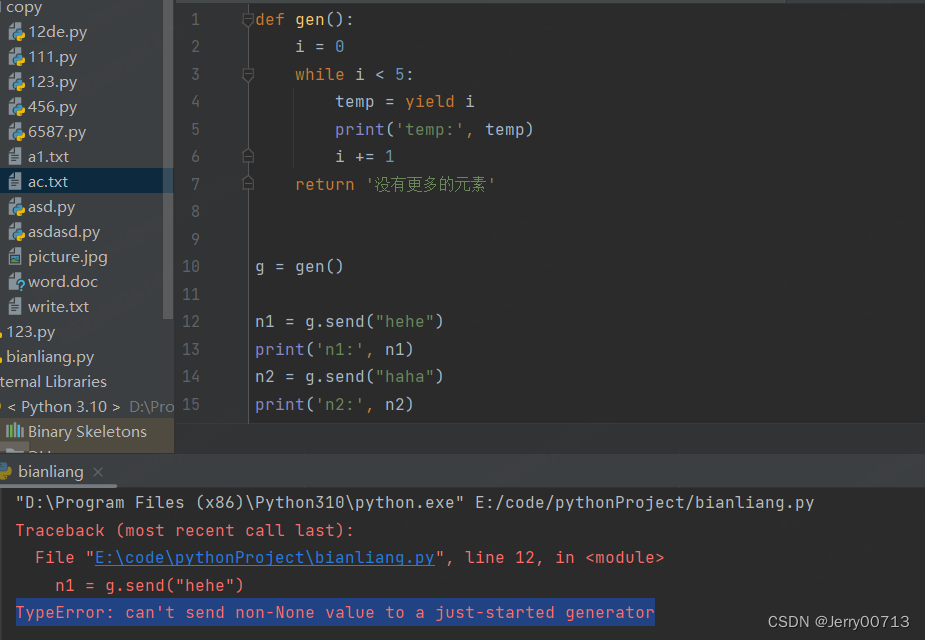
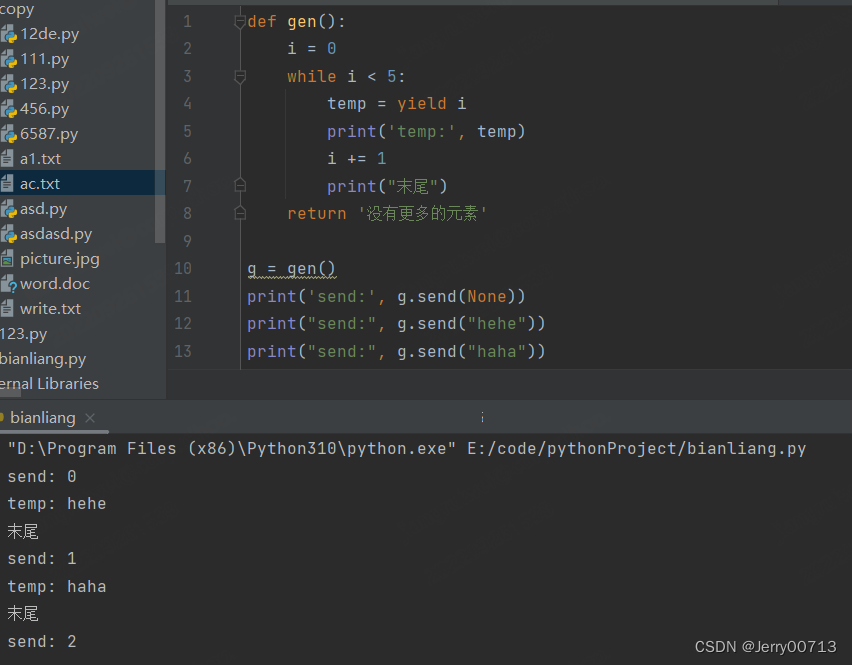
def gen(): i = 0 while i < 5: temp = yield i print('temp:', temp) i += 1 return '没有更多的元素' g = gen() print('send:', g.send(None)) n1 = g.send("hehe") print('n1:', n1) n2 = g.send("haha") print('n2:', n2)

send() 跟 g.__next__() 和 next(g) 的区别就是,每次可以传递一个参数,生成器中使用temp = yield i ,使用 temp 去接收传递的参数
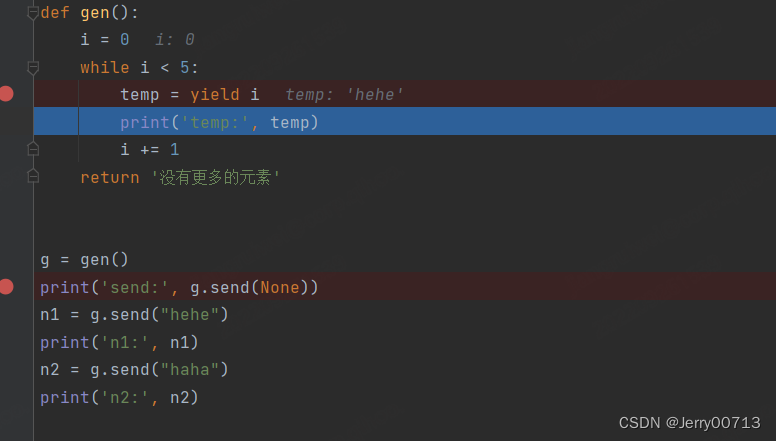
解释一下运行顺序:
第一次执行 print('send:', g.send(None)) ,进入生成器,执行 temp = yield i,但不往下执行,所以print('temp:', temp) 不打印,所以只输出了send: 0
第二次执行 print("send:", g.send("hehe")),进入生成器,执行 temp = yield i,往下执行,所以print('temp:', temp) 打印成 temp: hehe,直到遇到return,暂停返回输出yield i 中的 i ,然后执行 print("send:", g.send("hehe")) 打印 end: 1
3.6、生成器作用--协程
进程中可以包含多个线程,一个线程中包含多个协程
一个调用函数,开放一个协程处理,但是如果是生成器,没执行一次开发暂停一次,在卡方一次协程,几个任务交替运作,而不是先执行一个完成后,在执行另一个
def task1(n): for i in range(n): print("在搬第{}块砖".format(i)) yield def task2(n): for i in range(n): print("在听第{}首歌".format(i)) yield g1 = task1(6) g2 = task2(6) while True: try: g1.__next__() g2.__next__() except: break

四、迭代器和可迭代对象
4.1、可迭代对象
什么是可迭代的?每调用一下,生成一个新的元素,叫做可迭代的
可迭代的都有那些?1、生成器 2、列表、集合、字典、字符串、元组
判断列表是不是可迭代的:
isinstance 是判断的意思
Iterable 是可迭代的
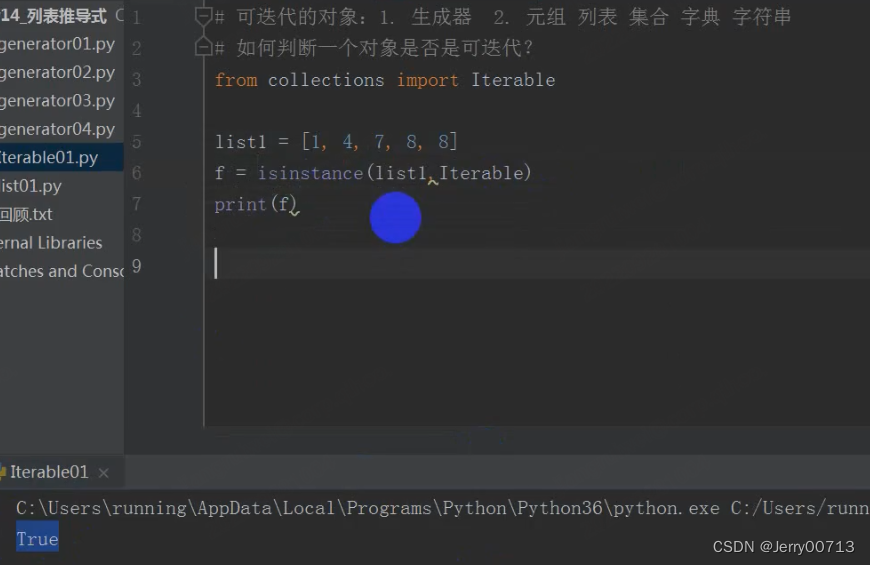
判断字符串是不是可迭代的:
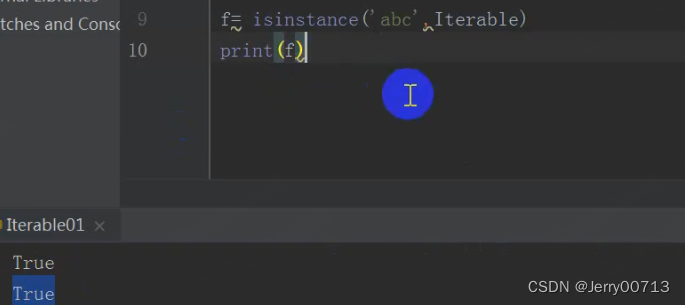
判断整型是不是可迭代的:
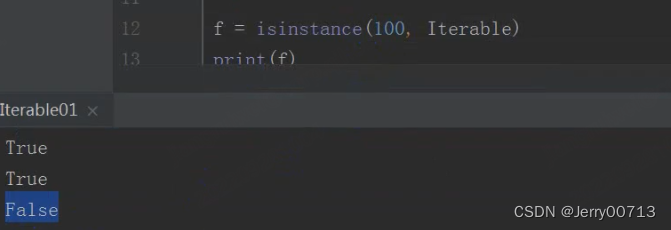
判断生成器是不是可迭代的:
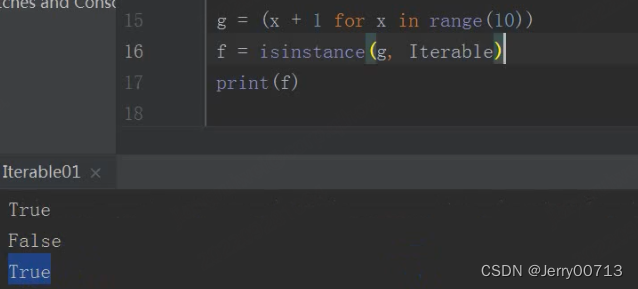
4.2 、迭代器
迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
迭代器只能往前不会后退。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator 。
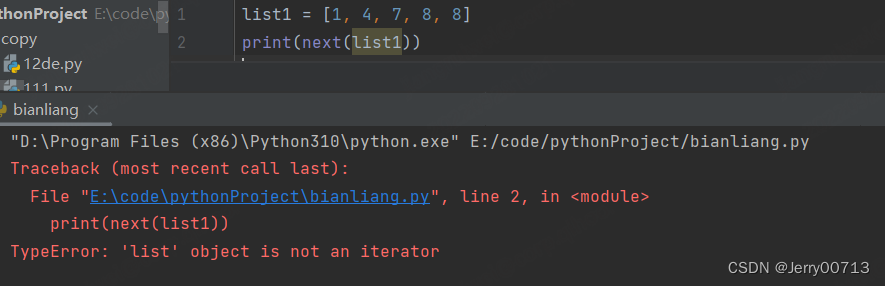
可迭代的 ≠ 迭代器对象,比如列表并不能被next() 调用
而生成器可以,所以生成器一定是迭代器
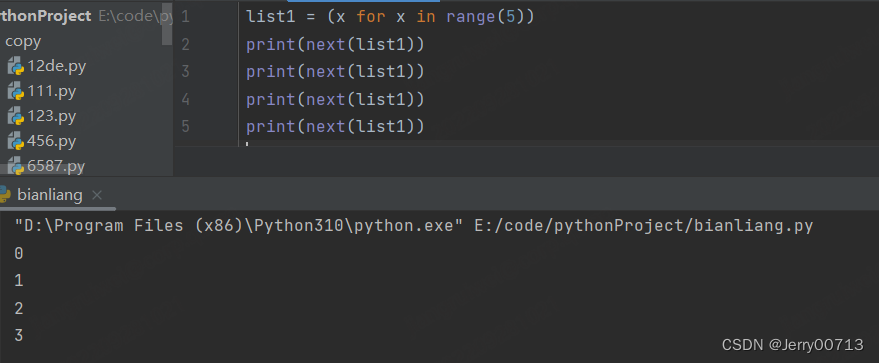
iter() 函数让列表、集合、字典、字符串、元组变成迭代器
# 列表 list1 = [1, 2, 3, 4, 8, 8] list1 = iter(list1) print(next(list1)) print(next(list1)) # 集合 set1 = {1, 2, 3, 4, 8, 8} set1 = iter(set1) print(next(set1)) print(next(set1)) # 字典 dict1 = {'key': 'value', 'key2': 'value2'} dict1 = iter(dict1) print(next(dict1)) print(next(dict1)) # 字符串 str = "123asd" str = iter(str) print(next(str)) print(next(str)) # 元组 tuple1 = (1, 2, 3, 4, 8, 8) tuple1 = iter(tuple1) print(next(tuple1)) print(next(tuple1))
















 2274
2274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









