









前言:领导又下发了个任务,要把项目中所有开发的表中的表名,字段名,字段注释导到excel中,本来想直接基于达梦迁移工具的导出为excel来实现,不过导出的结果会带上数据且没有字段注释等信息。在查阅相关说明后形成以下脚本,原理为识别达梦迁移工具导出的sql中的comment语句来进行excel识别输出操作。
1.导出包含表名,字段名,字段注释等信息的sql文件
1.1 打开DM数据迁移工具

1.2 新建迁移,选择导出为sql
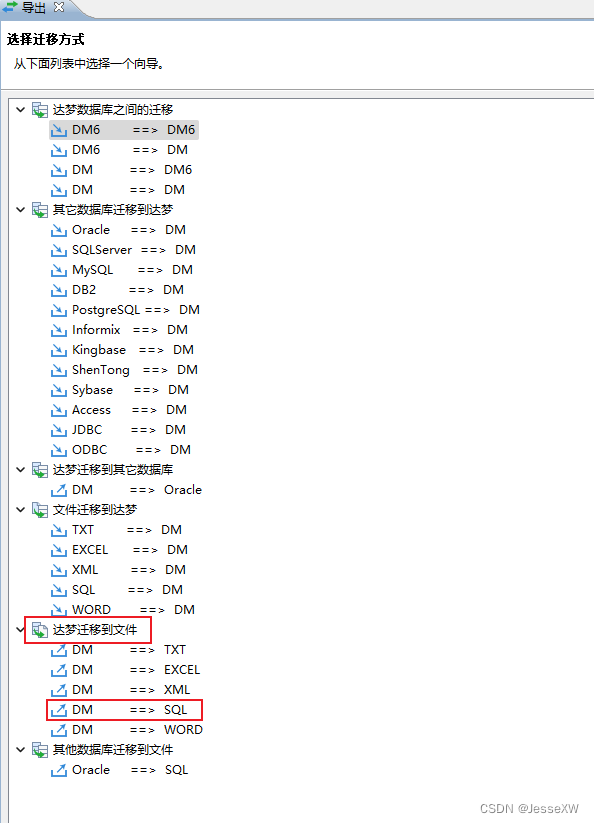
1.3 进行数据验证等操作
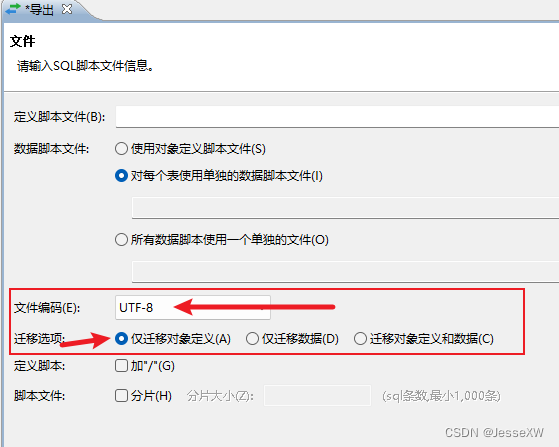
选择文件编码为UTF-8,迁移选项选为仅迁移对象定义:
(定义脚本文件就是选择导出地址,然后保存的文件名为你输入的名字,这个交互操作我觉得dm设计的很垃圾。。。。。。)
1.4 选择你要导出的表,进行导出操作
=====================================================================================
2.脚本操作
2.1 引入依赖
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.3</version>
</dependency>2.2 引入脚本
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class SqlTest {
public static void main(String[] args) throws IOException {
// 读取SQL文件
String sqlFilePath = "C:\\Users\\导出.sql"; // 替换为你自己的SQL文件路径
String sqlContent = new String(Files.readAllBytes(Paths.get(sqlFilePath)));
// 正则表达式匹配COMMENT ON COLUMN语句
Pattern pattern = Pattern.compile("COMMENT ON COLUMN \"(.*?)\".\"(.*?)\".\"(.*?)\" IS '(.*?)';");
Matcher matcher = pattern.matcher(sqlContent);
// 创建Excel工作簿
Workbook workbook = new XSSFWorkbook();
Sheet sheet = workbook.createSheet("sql-out");
// 创建标题行
Row titleRow = sheet.createRow(0);
titleRow.createCell(0).setCellValue("命名空间");
titleRow.createCell(1).setCellValue("表名");
titleRow.createCell(2).setCellValue("字段");
titleRow.createCell(3).setCellValue("字段注释");
// 逐行解析SQL文件内容
int rowNum = 1;
while (matcher.find()) {
String schema = matcher.group(1);
String table = matcher.group(2);
String column = matcher.group(3);
String comment = matcher.group(4);
// 写入Excel
Row dataRow = sheet.createRow(rowNum++);
dataRow.createCell(0).setCellValue(schema);
dataRow.createCell(1).setCellValue(table);
dataRow.createCell(2).setCellValue(column);
dataRow.createCell(3).setCellValue(comment);
}
// 将工作簿写入文件
String excelFilePath = "C:\\Users\\export.xlsx"; // 替换为你想要保存的Excel文件路径
try (FileOutputStream outputStream = new FileOutputStream(excelFilePath)) {
workbook.write(outputStream);
}
// 关闭工作簿
workbook.close();
}
}ps:如果运行报错提示
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.commons.io.IOUtils.byteArray(I)
可以尝试引入这个依赖:
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>=====================================================================================
最终效果:

脚本比较简单,可根据你的需求再定义操作。
=====================================================================================
目前已知bug:因为是基于comment语句来生成的,如果当初建表时没有输入字段注释,那么该字段及其注释是不会在excel中生成!
=====================================================================================
上周又让导出所有字段,包含没注释的,正好当时在用PD,最后发现可以通过脚本直接导出到excel,效果还挺不错的。参考链接:















 8323
8323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









