









使用教材:《算法与数据结构——c语言描述》(第2版) 张乃孝
第一章 绪论
数据结构概念
传统概念:计算机中表示(存储) 的、具有一定逻辑关系和行为特征的一组数据。
根据面向对象的观点:数据结构是抽象数据类型的物理实现。
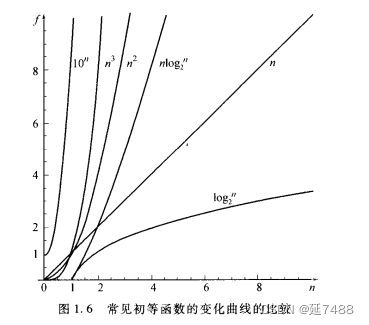
描述算法复杂度(大O表示法)
两个算法顺序连接,使用加法原则;
出现子程序嵌套情况,使用乘法原则。
第二章 线性表
L=<K,R>
表中所含元素的个数称为表的长度,长度为零的表称为空表;
k0称为第一个元素,kn-1为最后一个元素, ki(0≤i≤n-2)是ki+1的前驱, ki+1是ki的后继。
一、顺序表
struct SeqList{
int MAXNUM; /*顺序表中可以存放元素的个数*/
int n; /* 实际存放线性表中元素的个数,n≤MAXNUM */
DataType *element;
/* element[0], element[1],…,element[n- 1]存放线性表中的元素 */
};
typedef struct SeqList *PSeqList;
如果palist是一个PSeqList类型的指针变量,则:
• palist->MAXNUM:顺序表中可以存放元素的个数;
• palist->n:顺序表中实际元素的个数;
• palist->element[0] ,…,palist->element[palist->n - 1]:顺序表中的各个元素。
判断线性表是否为空
int isNullList_seq( PSeqList palist ) {
/*判别palist所指顺序表是否为空表。*/
return ( palist->n == 0 );
}
在顺序表中求某元素的下标
int locate_seq( PSeqList palist, DataType x ) {
/* 求x在palist所指顺序表中的下标 */
int q;
for ( q=0; q<palist->n ; q++)
if ( palist->element[q] == x) return q ;
return -1;
}
顺序表的插入
int insertPre_seq( PSeqList palist, int p, DataType x ) {
/* 在palist所指顺序表中下标为p的元素之前插入元素x */
int q;
if ( palist->n >= palist-> MAXNUM ) { /* 溢出 */
printf(“Overflow!\n”);
return 0 ;
}
if (p<0 || p>palist->n ) { /* 不存在下标为p的元素 */
printf(“Not exist! \n”); return 0 ;
}
for(q=palist->n - 1; q>=p; q--) /* 插入位置及之后的元素均后移一个位置 */
palist->element[q+1] = palist->element[q];
palist->element[p] = x; /* 插入元素x */
palist->n = palist->n + 1; /* 元素个数加1 */
return 1 ;
}
按下标删除元素
int deleteP_seq( PSeqList palist, int p ) {
/* 在palist所指顺序表中删除下标为p的元素 */
int q;
if ( p<0 || p>palist->n – 1 ) {/* 不存在下标为p的元素 */
printf(“Not exist!\n “);
return 0 ;
}
for(q=p; q<palist->n-1; q++) /* 被删除元素之后的元素均前移一个位置 */
palist->element[q] = palist->element[q+1];
palist->n = palist->n - 1; /* 元素个数减1 */
return 1 ;
}
按值删除元素
int deleteV_seq( PSeqList palist, DataType x )
• 在palist所指顺序表中,删除一个值为x的元素,返回
删除成功与否的标志。
• 实现的算法只要首先调用locate_seq (palist, x ),在
palist所指顺序表中寻找一个值为x的元素的下标,假
设为p,然后调用deleteP_seq(palist, p )即可。
• 顺序表插入和删除操作的平均时间代价和最坏时间代价都是 O(n) ;
– 两种特殊情况:表后端插入/删除的时间代价为O(1) ;
• 根据元素值的定位操作(locate_seq),需顺序与表中元素比较,当定位的概率平均分布在表的所有元素上时,一次定位平均需要和n/2个元素进行比较,时间代价为O(n) ;
– 特殊情况:如果顺序表中的元素按照值的升(降)序排列,则可使用二分法使得定位操作的时间代价减少到O(log2 n) 。
二、链表
不连续的存储单元,通过增加指针来指示元素之间的逻辑关系和后继元素的位置
单链表
• 最简单的链表表示:只为每个数据元素关联一个链接,表示后继关系。
• 每个结点包括两个域:
– 数据域: 存放元素本身信息。
– 指针域: 存放其后继结点的存储位置。
• 最后一个元素的指针不指向任何结点,称为空指针,在图示中用“∧”表示,在算法中用“NULL”表示。
• 指向链表中第一个结点的指针,称为这个链表的头指针。
struct Node; /*单链表结点类型*/
typedef struct Node * PNode; /*结点指针类型*/
struct Node { /*单链表结点结构*/
DataType info;
PNode link;
};
typedef struct Node * LinkList ; /*单链表类型*/
LinkList llist; /*llist是一个链表的头指针*/
创建空单链表
LinkList createNullList_link(void) {
LinkList llist;
/*申请表头结点空间*/
llist=(LinkList)malloc(sizeof(struct Node ));
if (llist!=NULL) llist->link=NULL;
else printf(“Out of space!\n”); /*创建失败*/
return llist;
}
判断单链表是否为空
int isNullList_link(LinkList llist) {
return (llist->link==NULL);
}
/*因为llist指向头结点,总是非空, 所以算法中只要检查llist->link是否为空即可*/
求某元素存储位置
PNode locate_link(LinkList llist, DataType x) {
PNode p;
if(llist==NULL) return NULL; /*找不到时返回空指针*/
p=llist->link;
while (p!=NULL&&p->info!=x)p=p->link;
return p;
}
在带头结点的单链表llist中下标为p的结点后插入值为x的新结点
int insertPost_link (LinkList llist, PNode p, DataType x) {
PNode q=(PNode)malloc(sizeof(Struct Node)); /*申请新结点*/
if (q==NULL) {
printf(″Out of Space!\n″) ;
return 0;
}
else {
q->info =x;
q->link=p->link;
p->link=q;//注意指针更新次序
return 1;
}
求p所指结点的前驱
PNode locatePre_link (LinkList llist, PNode p) {
PNode p1;
if(llist==NULL) return NULL;
p1=llist;
while(p1!=NULL && p1->link!=p) p1=p1->link;
return p1;
}
删除
在带头结点的单链表llist中,删除第一个元素值为x的结点(这里要求DataType 可以用!=比较)
int deleteV_link(LinkList llist, DataType x) {
PNode p, q; p = llist;
if(p==NULL) return 0 ;
while( p->link != NULL && p->link->info != x )
p = p->link; /*找值为x的结点的前驱结点的存储位置 */
if( p->link == NULL ) { /* 没找到值为x的结点 */
printf(”Not exist!\n ”); return 0 ;
}
else {
q = p->link;/* 找到值为x的结点 */
p->link = q->link; /* 删除该结点 */
free( q ); return 1 ;
}
}
循环链表
顺序链表
第三章 字符串
模式匹配就是在目标串 t 中查找与模式串 p 相同的子串的过程。
朴素模式匹配
int index( PSeqString t, PSeqString p) {
int i = 0, j = 0; /*初始化*/
while ( i < p->n && j < t->n ) /*反复比较*/
if (p->c[i] == t->c[j]) { /* 继续匹配下一个字符 */
++ i; ++ j;
}
else { /* i, j值回溯,再开始下一位置的匹配 */
j =j- i + 1; i = 0;
}
if (i >= p->n) return( j - p->n + 1); /* 匹配成功*/
else return 0;
}
其它知识点指路
字符串
第四章 栈与队列
栈
先入后出
顺序栈
struct SeqStack { /* 顺序栈类型定义 */
int MAXNUM; /* 栈中最大元素个数 */
int t; /* t<MAXNUM,指示栈顶位置,而不是元素个数 */
DataType *s;
};
typedef struct SeqStack *PSeqStack;
/* 顺序栈的指针类型 */
栈与递归
Eg.迷宫问题
void mazePath(int *maze[],int *direction[],int x1, int y1,int x2,int y2,int M,int N) {
int i,j,k,g,h;
PSeqStack st;
DataType element;
st = createEmptyStack_seq(M*N );
maze[x1][y1] = 2;
element.x = x1;
element.y = y1;
element.d = -1;
push_seq(st,element);
while (! isEmptyStack_seq(st)) {
element = top_seq(st);
pop_seq(st);
i = element.x;
j = element.y;
k = element.d + 1;
while (k<=3) {
g = i + direction[k][0];
h = j + direction[k][1];
if (g==x2 && h==y2 && maze[g][h]==0) {
printf("The revers path is:\n");
while(!isEmptyStack-seq(st)){
element=top_seq(st);
pop_seq(st);
printf("the node is: %d %d \n",
element.x,element.y);
}
return;
}
if (maze[g][h]==0) {
maze[g][h] = 2;
element.x = i;
element.y = j;
element.d = k;
push_seq(st,element);
i = g; j = h; k = -1;
}
k = k + 1;
}
}
printf("The path has not been found.\n");
}
队列
先入先出
顺序队列
struct SeqQueue{ struct SeqQueue{
int MAXNUM; /* 队列中最大元素个数 */
int f,r;
DataType *q;
};
/*为了算法设计上的方便:f 指出实际队头元素所在的位置,r 指出
实际队尾元素所在位置的下一个位置。*/
typedef struct SeqQueue *PSeqQueue;
/* 顺序队列类型的指针类型 */
环形队列
创建一个空队列
PSeqQueue createEmptyQueue_seq( int m )
具体实现与PSeqList createNullList_seq( int m )
(创建空表)类似,需要为队列申请空间,不同之处
是需要对变量f和r均赋值为0。请自己给出。
• 判断队列是否为空
int isEmptyQueue_seq( PSeqQueue paqu )
当paqu->f==paqu->r时,则返回1,否则返回0。
进队
void enQueue_seq( PSeqQueue paqu, DataType x ) {
/* 在队尾插入元素x */
if( (paqu->r + 1) % MAXNUM == paqu->f )
printf( "Full queue.\n" );
else { paqu->q[paqu->r] = x;
paqu->r = (paqu->r + 1) % MAXNUM;
}
}
出队
void deQueue_seq( PSeqQueue paqu ) {
/* 删除队列头部元素 */
if( paqu->f == paqu->r ) printf( "Empty Queue.\n" );
else paqu->f = (paqu->f + 1) % MAXNUM;
}
取队列头部元素
DataType frontQueue_seq( PSeqQueue paqu ) {
if( paqu->f == paqu->r )
printf( "Empty Queue.\n" );
else return (paqu->q[paqu->f]);
}
链队
第五章 二叉树与树
定义
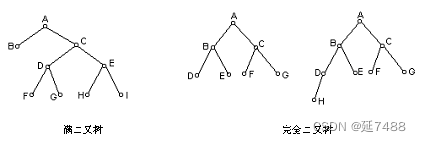
满二叉树和完全二叉树
满二叉树:如果一棵二叉树的任何结点或者是树叶,或有两棵非空子树,则此二叉树称作满二叉树。
完全二叉树:如果一棵二叉树至多只有最下面的两层结点度数可以小于2,其余各层结点度数都必须为2,并且最下面一层的结点都集中在该层最左边的若干位置上,则此二叉树称为完全二叉树。
完全二叉树不一定是满二叉树。
扩充二叉树和外部结点
扩充二叉树:把原二叉树的结点都变为度数为2的分支结点。如果原结点的度数为2,则不变,度数为1,则增加一
个分支,度数为0(树叶),则增加两个分支。
新增加的结点都用小方框表示,称为外部结点,树中原有的结点称为内部结点。
特别对空二叉树扩充得到只有一个外部结点的扩充二叉树。
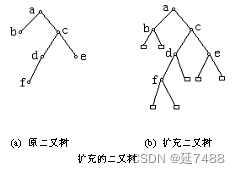
外部路径长度和内部路径长度
外部路径长度E:在扩充的二叉树中从根到每个外部结点的路径长度之和。
内部路径长度I:在扩充的二叉树中从根到每个内部结点的路径长度之和。
二叉树的性质
• 性质1 在二叉树的i层上至多有2i个结点(i≥0)。
• 性质2 高度为k的二叉树中最多有2k+1 - 1个结点(k≥0)。
• 性质3 对于任何一棵二叉树,如果叶结点数为n0,度为2的结点个数为n2,则有:n0= n2+ 1 。
完全二叉树的主要性质
• 性质4 具有n个结点的完全二叉树的深度k为 ceil(log2n) ,向下取整
• 性质5 对于具有n个结点的完全二叉树,如果按照从上(根结点) 到下(叶结点)和从左到右的顺序对二叉树中的所有结点从0开始到n-1进行编号,则对于任意的下标为i的结点,有:
(1) 如果i=0,则它是根结点,它没有父结点: 如果i>0,则它的父结点的下标为 (i-1)/2 ;
(2) 如果2i+1≤n-1,则下标为i的结点的左子结点的下标为2i+1; 否则,下标为i的结点没有左子结点;
(3) 如果2i+2≤n-1,则下标为i的结点的右子结点的下标为2i+2; 否则,下标为i的结点没有右子结点。
满/扩充二叉树的主要性质
• 性质6 在满二叉树中,叶结点的个数比分支结点个数多1。
• 性质7 在扩充二叉树中,外部结点的个数比内部结点的个数多1。
• 性质8 对任意扩充二叉树,外部路径长度E和内部路径长度I之间满足关系:E = I + 2n,其中n是内部结点个数。
二叉树的周游
按某种方式访问二叉树中的所有结点,使每个结点被访问一次且只被访问一次。
深度优先周游
先左后右的三种周游方式:
- DLR-----先根次序(简称先序或前序)周游
- LRD-----后根次序(简称后序)周游
- LDR-----中根次序(简称中序或对称序)周游
注意,周游之前要判断二叉树是否为空。
先根序列(先根次序周游得到的结点序列):若二叉树不空,则先访问根;然后按先根次序周游左子树;最后按先根次序周游右子树。
后根序列:若二叉树不空,则先按后根次序周游左子树;然后按后根次序周游右子树;最后访问根。
对称(中根)序列:若二叉树不空,则先按对称序周游左子树;然后访问根;最后按对称序周游右子树。
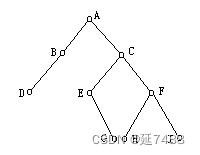
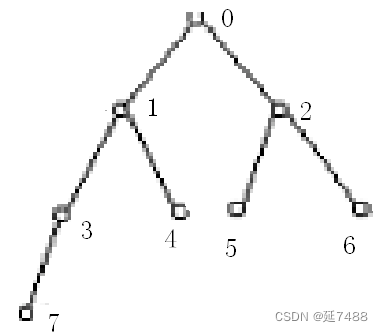
先根次序周游得到的结点序列(也称为先根序列)为:A,B,D,C,E,G,F,H,I 。
后根序列:D,B,G,E,H,I,F,C,A 。
中根序列:D,B,A,E,G,C,H,F,I。
周游结果为表达式的树,所得三个周游序列也分别被称为表达式的前缀表示、后缀表示和中缀表示。
周游的抽象算法
建立在抽象数据类型基本运算的基础上,不依赖二叉树的具体存储结构。
二叉树周游的递归算法
先根次序周游
void preOrder( BinTree t) {
if (t==NULL) return;
visit(root(t));
preOrder(leftChild(t));
preOrder(rightChild(t));
}
对称序周游
void inOrder(BinTree t){
if (t==NULL) return;
inOrder(leftChild(t));
visit(root(t));
inOrder(rightChild(t));
}
后根次序周游
void postOrder(BinTree t){
if (t==NULL) return;
postOrder(leftChild(t));
postOrder(rightChild(t));
visit(root(t));
}
一般而言,如果已知一个二叉树的对称序列,又知道另外一种周游序列(无论是先根序列还是后根序列),就可以唯一确定这个二叉树。
广度优先周游
逐层从左到右逐个访问存在的结点。
广度优先周游一棵二叉树所得到的结点序列称为其层次序列。
上图中层次序列: A,B,C,D,E,F,G,H,I。
void levelOrder(BinTree t) {
BinTree c, cc;
Queue q= createEmptyQueue();
/* 队列元素为BinTree类型*/
if (t==NULL) return; /*空二叉树返回*/
c = t; enQueue(q,c); /*将二叉树送入队列*/
while (!isEmptyQueue(q)) {
c = frontQueue(q); deQueue(q); visit(root( c ));
/*从队列首部取出二叉树并访问*/
cc = leftChild( c ); if(cc!=NULL) enQueue(q,cc);
/*将左子树送入队列*/
cc= rightChild( c ); if(cc!=NULL) enQueue(q,cc);
/*将右子树送入队列*/
}
}
二叉树的实现
• 顺序表示
完全二叉树:从上(根结点)到下(叶结点)、从左到右,所有结点从0到n-1编号,一维数组中。
通过数组元素的下标关系,---->结点间逻辑关系。
一般二叉树:进行扩充,增加空节点,称为完全二叉树。
定义
struct SeqBinTree{
int MAXNUM /* 完全二叉树中允许结点的最大个数 */
int n; /* 改造成完全二叉树后,结点的实际个数 */
DataType *nodelist; /*存放结点的数组*/
};
typedef struct SeqBinTree *PSeqBinTree;
/*顺序二叉树类型的指针类型*/
运算
/*返回下标为p的结点的父结点的下标*/
int parent_seq(PSeqBinTree t, int p){
if (p < 0 || p >= t->n) return -1;
return (p - 1) / 2;
}
/*返回下标为p的结点的左子结点的下标*/
int leftChild_seq(PSeqBinTree t, int p){
if (p < 0 || p >= t->n) return -1;
return 2*p + 1; /*可能不存在*/
}
/*返回下标为p的结点的右子结点的下标*/
int rightChild_seq (PSeqBinTree t, int p){
if (p < 0 || p >= t->n) return -1;
return 2 * (p + 1) ; /*可能不存在*/
}
• 链接表示(左-右指针表示法)
struct BinTreeNode; /* 二叉树中结点 */
typedef struct BinTreeNode * PBinTreeNode;
/* 结点的指针类型 */
struct BinTreeNode {
DataType info; /* 数据域 */
PBinTreeNode llink; /* 指向左子结点 */
PBinTreeNode rlink; /* 指向右子结点 */
};
/*返回结点p的左子结点的地址*/
PBinTreeNode leftChild_link(PBinTreeNode p){
if (p == NULL) return NULL;
return p->llink;
}
/*返回结点p的右子结点的地址*/
PBinTreeNode rightChild_link(PBinTreeNode p){
if (p == NULL) return NULL;
return p->rlink;
}
求父结点
从节点出发,使用周游算法,检查当前结点是否所求结点的父结点。
为了提高求父结点操作的速度,可以采用的另一种链接表示方式是三叉链表表示,即给二叉树中的每个结点增加一个指向父结点的指针域。
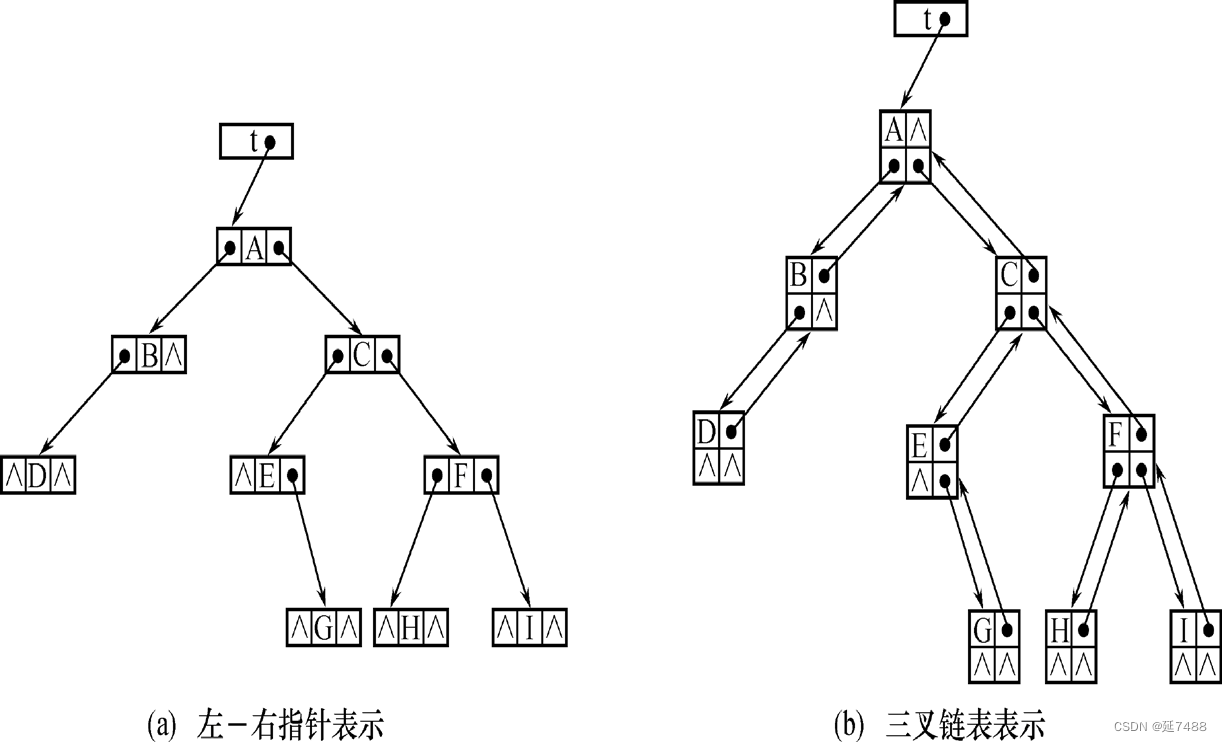
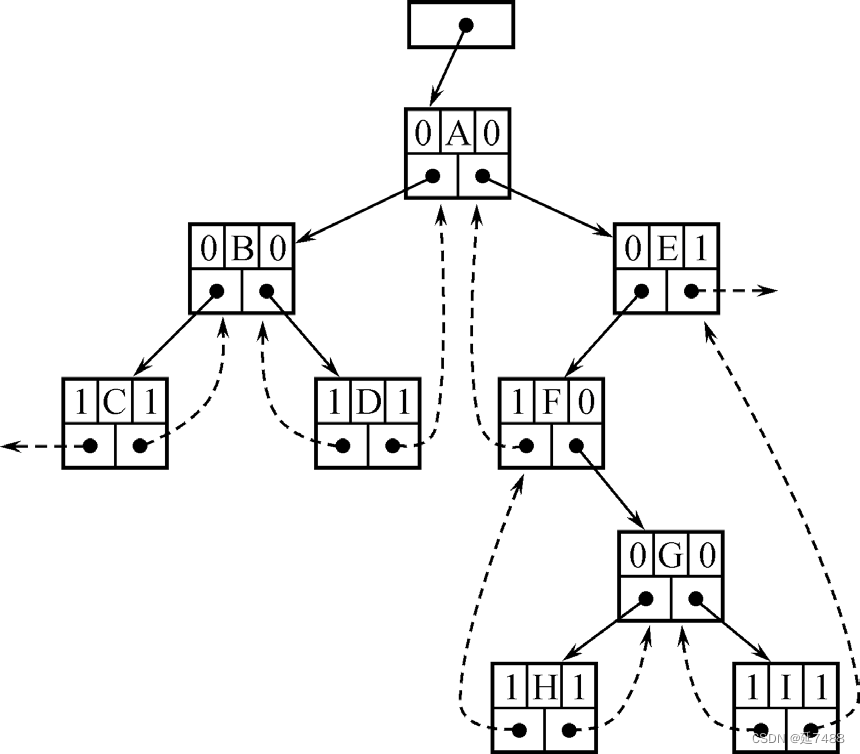
• 线索二叉树
对于左-右指针表示法的一种修改。
• 它利用结点的空的左指针(llink)存储该结点在某种周游序列中的前驱结点的位置;利用结点的空的右指针(rlink)存储该结点在同种周游序列中的后继结点的位置。
• 这种附加的指向前驱结点和后继结点的指针称作线索,加进了线索的二叉树左-右指针表示称作线索二叉树。
结点结构:
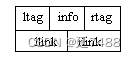
ltag=0,llink是指针,指向结点的左子结点;
ltag=1,llink是线索,指向结点的对称序的前驱结点;
rtag=0,rlink是指针,指向结点的右子结点;
rtag=1,rlink是线索,指向结点的对称序的后继结点。
 定义
定义
struct ThrTreeNode;/* 线索二叉树中的结点 */
typedef struct ThrTreeNode * PThrTreeNode;
/* 指向线索二叉树结点的指针类型 */
struct ThrTreeNode { /* 线索二叉树中结点的定义 */
DataType info;
PThrTreeNode llink, rlink;
int ltag, rtag;
};
typedef struct ThrTreeNode * ThrTree; /* 线索二叉树类型的定义 */
typedef ThrTree * PThrTree; /* 线索二叉树类型的指针类型 */
按对称序线索化二叉树:按对称序列周游,过程中用线索代替空指针。
void thread(ThrTree t) {
PSeqStack st = createEmptyStack (M);
/*栈元素的类型是ThrTree, M一般取t的高度 */
ThrTree p, pr;
if (t==NULL) return ;
p = t; pr = NULL;
do {
while (p!=NULL) {push_seq(st,p);p= p->llink;}
p = top_seq(st); pop_seq(st);
if (pr!=NULL) {
if (pr->rlink==NULL) { pr->rlink = p;pr->rtag = 1; }
/*修改前驱结点的右指针*/
if (p->llink==NULL) { p->llink = pr; p->ltag = 1;}
/*修改该结点的左指针*/
}
pr = p; p = p->rlink;
} while ( !isEmptyStack_seq(st) || p!=NULL );
}
按对称序周游对称序线索二叉树
void nInOrder(ThrTree t ) {
ThrTree p= t;
if (t==NULL) return ;
while ( p->llink!=NULL && p->ltag==0 ) p = p->llink;
while (p!=NULL) {
visit(*p);
if ( p->rlink!=NULL && p->rtag==0 ) {
/* 右子树不是线索时 */
p = p->rlink;
while (p->llink!=NULL&&p->ltag==0)
p = p->llink; /*顺右子树的左子树一直向下*/
}
else p = p->rlink;
}
}
小根堆
每个子二叉树的根均小于等于其左、右子结点。根结点是最小结点。
优先队列
最小元素先出。
最常用的实现方法是小根堆。
struct PriorityQueue {
int MAXNUM; /*元素个数的上限 */
int n; /*实际元素个数*/
DataType *pq; /*存放元素的数组的指针*/
}; /*优先队列类型*/
typedef struct PriorityQueue * PPriorityQueue;
/*指向优先队列的指针类型*/
向优先队列中插入x(保持堆序性)
void add_heap(PPriorityQueue papq, DataType x) {
int i;
if (papq->n >= MAXNUM)
{ printf("Full!\n"); return; }
for (i = paqu->n; i > 0 && papq->pq[(i - 1) / 2] > x; i = (i - 1) / 2)
}
papq->pq[i] = papq->pq[(i - 1) / 2];
/*空位向根移动,找插入的位置*/
papq->pq[i] = x; papq->n++; /*将x插入*/
最小结点的删除
void removeMin_heap(PPriorityQueue papq) {
int s, i, child; DataType temp ;
if (isEmpty_heap(papq)) {printf("Empty!\n"); return;}
s = --papq->n; /*先删除,*/
temp = papq->pq[s]; /*把最后元素移到temp*/
i =0; child = 1;
while (child < s) { /*找最后元素存放的位置*/
if (child < s - 1 && papq->pq[child] > papq->pq[child + 1])
child++; /*选择比较小的子结点*/
if (temp > papq->pq[child]) /*空位向叶结点移动*/
{ papq->pq[i] = papq->pq[child]; i = child; child = 2 * i + 1; }
else break; /*已经找到适当位置*/
}
papq->pq[i] = temp; /*把最后元素填入*/
}
哈夫曼树(最优二叉树)
扩充二叉树的带权的外部路径长度 WPL:每个外部结点都有权值,第i个的为wi,有
WPL=∑I=1m wili
构造
一组(无序)实数{w1, w2,…, wm},满足条件:
(1) 有m个外部结点, 且分别以wi为(i=1,…,m)其权值;
(2)满足条件(1)的基础上,WPL最小。
基本思想
(1) 由给定的m个权值{w1, w2,…, wm},构造包含m棵二叉树的集合F= {T1,T2,…,Tm}, 其中二叉树Ti 只含权为 wi 的根结点;
(2)从F中选取两棵根结点权最小和次最小的树作为左,右子树,构造一棵新二叉树,其根结点的权值为两棵子树的根结点权值之和;
(3)从F删除所选的两棵树,把新构造的二叉树加入F;
(4)重复(2)和(3),直到F中只含一棵树为止。
数据结构
| ww | parent | link | rlink |
struct HtNode { /* 哈夫曼树结点的结构 */
int ww;
int parent,llink,rlink;
};
struct HtTree{ /* 哈夫曼树结构 */
int m; /* 外部结点的个数 */
int root;/* 哈夫曼树根在数组中的下标 */
struct HtNode *ht; /*存放2*m-1个结点的数组 */
};
typedef struct HtTree *PHtTree;/ 哈夫曼树类型的指针类型 */
哈夫曼编码
(1)以需要编码的字符集合作外部结点标注,把w1, w2,…, wn分别作为这n个外部结点的权,构造一棵哈夫曼树。
(2)在得到的哈夫曼树中,将所有从一个结点引向其左子结点的边标上二进制数字 0;引向其右子结点的边标二进制数字 1。
(3)以从根结点到一个叶结点的路径上的二进制数字序列,作为这个叶结点的字符的编码,就是这个叶结点所代表字符的最优前缀编码,称为哈夫曼编码。
Eg.d = { d1 ,d2,…,d13 }w = { 2,3,5,7,11,13,17,19,23,29,31,37,41 }。
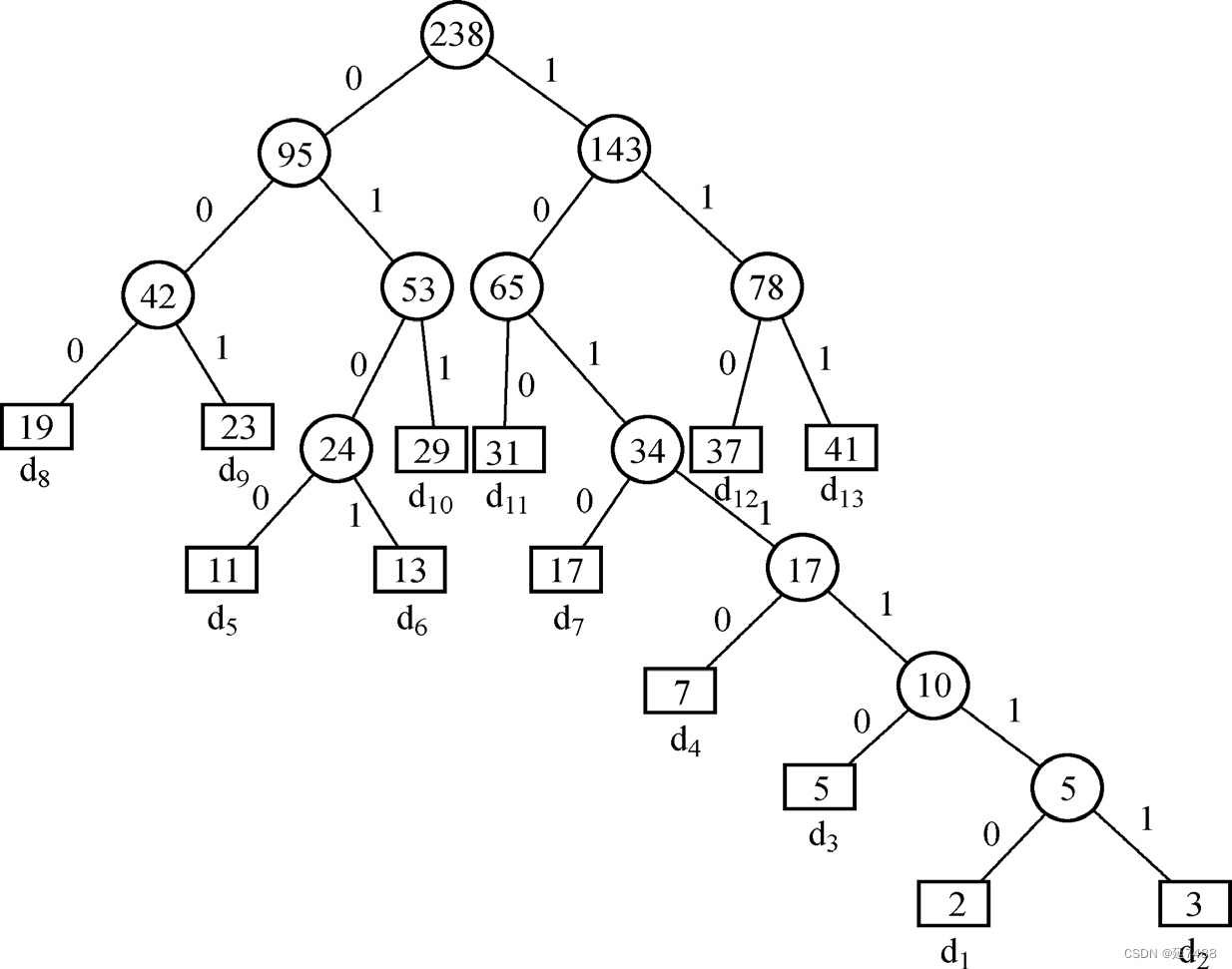
二叉树和森林或树的相互转换
树林–>二叉树:
所有相邻的兄弟结点之间加一条线;
然后对每个非终端结点,只保留它到其最左子结点的连线,删去它与其他子结点之伺原有的连线;
最后以根结点为轴心,将整棵树顺时针旋转一定角度 ,使其层次分明。
任何树林都唯一地对应到一棵二叉树; 任何二叉树也都唯一地对应到一个树林。
树–>二叉树:
根节点的右子树总为空。
二叉树–>森林:
1)若某结点是其父母的左子结点,则把该结点的右子结点,右子结点的右子结点……,都与该结点的父母用(虚)
线连起来;
2)去掉原二叉树中所有父母到右子结点的连线
3)整理由1)、2)两步所得到的树或树林,使之结构层次分明。
第六章 集合与字典
集合
定义
列举法和谓词描述法。
空集
子集
超集:若A是B的子集,那么B是A的超集。
主要运算
并集:A U B = {x | x ∈ A ∨ x ∈ B}
交集:A ∩ B = {x | x ∈ A ∧ x ∈ B}
差集:A − B = {x | x ∈ A ∧ x ∉ B}
子集:A ⊆ B ⇔ ∀x( x ∈ A ⇒ x ∈ B)
超集:A⊆B⇔B⊇A
相等:A=B⇔ A⊆B∧B⊆ A
单链表表示集合
struct Node;
typedef struct Node *PNode;
struct Node {
DataType info;
PNode link;
};
typedef struct Node *LinkSet;
交集
int intersectionLink (LinkSet s0,LinkSet s1,LinkSet s2) {
PNode x;
if(s0= =NULL||s1= =NULL||s2= =NULL){
printf("no head node error");return 0;}
s2->link=NULL; /*将s2置成空集合*/
s0=s0->link; s1=s1->link;
while(s0!=NULL&&s1!=NULL)
if(s0->info>s1->info) s1=s1->link;
elseif(s0->info<s1->info) s0=s0->link;
elseif(s0->info= =s1->info) { /*找到相同元素*/
x=(PNode)malloc(sizeof(struct Node)); /*分配结点空间*/
if(x= =NULL) {printf("out of space");return 0;}
x->info=s0->info; x->link=NULL; s2->link=x; /*在s2中插入*/
s0=s0->link; s1=s1->link; s2=s2->link; /*指针后推*/
}
return 1;
}
赋值
int assignLink (LinkSet s0,LinkSet s1) {
PNode x;
if(s0= =NULL||s1= =NULL){printf("no head node error");return 0;}
s0->link=NULL; /*将s0置成空集合*/
s1=s1->link;
while(s1!=NULL) {
x=(PNode)malloc(sizeof(struct Node)); /*分配结点空间*/
if(x= =NULL) {printf("out of space");return 0;}
x->info=s1->info; x->link=NULL; s0->link=x; /*在s0中插入*/
s1=s1->link; s0=s0->link; /*指针后推*/
}
return 1;
}
插入
int insertLink (LinkSet s0,DataType x) {
PNode temp;
if(s0= =NULL){printf("no head node error");return 0;}
temp=(PNode)malloc(sizeof(struct Node)); /*分配结点空间*/
if(temp= =NULL){printf("out of space");return 0;}
while(s0->link!=NULL) {
if(s0->link->info= =x) {printf("data already exist");return 1;}
else if(s0->link->info<x) s0=s0->link;
else if(s0->link->info>x) { /*找到插入位置*/
temp->info=x; temp->link=s0->link; s0->link=temp; /*插入*/
return 1;
}
}
if(s0->link= =NULL) { /*插到最后*/
temp->info=x; temp->link=s0->link; s0->link=temp;
return 1;
}
}
字典
每个元素都有两部分组成, 即关键码和属性(也称为值)。
平均检索长度ASL:其中n是字典中元素的个数, pi是查找第i个元素的概率, ci是找第i个元素的比较次数。
ASL(n)=∑i=1n pici
顺序表示
typedef int KeyType;
typedef int DataType;
typedef struct {
KeyType key; /* 字典元素的关键码字段 */
DataType value; /* 字典元素的属性字段 */
} DicElement;
typedef struct {
int MAXNUM ; /*字典中元素的个数上界*/
int n; /*实际元素个数*/
DicElement *element.; /*存放字典中的元素*/
} SeqDictionary;
二分法检索
前提:字典的元素在顺序表中按关键码排序。
int binarySearch(SeqDictionary * pdic, KeyType key, int *position){
int low, mid, high;
low=0; high=pdic->n-1;
while(low<=high) {
mid=(low+high)/2; /* 当前检索的中间位置 */
if(pdic->element[mid].key==key)
{*position=mid; return(1);} /* 检索成功 */
else if(pdic->element[mid].key>key) high=mid-1;/* 检索左半区 */
else low=mid+1;
}
*position=low; return 0 ; /* 检索失败 */
}
最大检索长度:log2(n+1)
ASL=( (n+1)/n )*log2(n+1) -1
检索速度 O(log2n)
散列函数
散列法(hashing,杂凑法、关键码一地址转换法)
关键码 key–散列函数h–>散列地址 h(key)
负载因子: α =字典中结点数目/基本区域能容纳的结点数目 。理想的α>0.5
碰撞: 如果 key1≠key2, 而h(key1)=h(key2). 发生碰撞的关键码称为同义词.
散列表: 采用散列法表示的字典.
常用设计方法
数字分析法
折叠法
中平方法
基数转换法
除余法(使用最广)
关键码除以某个不大于基本区域大小(m)的数p后的 余数为散列地址, 即**h(key)=(int)key%p;**,p一般为素数
解决碰撞
开地址法
在基本区域内形成一个同义词的探查序列,沿着探查序列逐个查找,直到找到查找的元素或碰到一个未被占用的地址为止。若插人元素,则碰到空的地址单元就存放要插入的同义词。若检索元素,则需要碰到空的地址单元后,才能说明表中没有待查的元素(检索失败)。
负载因子必须小于1。
线性探查
基本区域内的一个探查序列:Hi= (h(key)+di)%m,其中:m为表长, di为增量序列, i=1,2, …,k (k≤m-1)。
如果增量序列满足:di=i,则为线性探查序列。
如果增量序列满足:di=i× h2 (key)则为双散列探查序列。
Eg.已知关键码集合K = { 1 8 , 7 3 , 1 0 , 5 , 6 8 , 9 9 , 2 7 , 4 1 , 5 1 , 3 2 , 2 5} ,设散列表基本区域用数组emelent表示,大小为m ( m = 1 3 ) ,散列函数为h ( k e y ) = k e y % 1 3 ,用线性探查法解决碰撞。
为了构造散列表,首先按散列函数d = key%13计算每个元素的散列地址。
h(18) =5, h(73) =8, h(10)= 10, h(5) =5, h(68) =3, h(99) =8 ,h(27)=1,h(41) =2, h(51) = 12, h(32) =6, h(25) =12
插人18 , 73 , 10 时,地址都未被占用,可以直接存放;插入5 时,其地址与1 8 的地址发生碰撞,进行线性探查,由于element [ 6 ]为空单元,可以插人;68的地址为3 , e l e m e n t [ 3 ] 是空单元,直接插人;9 9 的地址为8 ,与73的地址相冲突,线性探查后放入element[9];27,41,51的地址都未被占用,可以直接存放;32的地址为6,e l e m e n t [6] 已经被5占用,线性探查后存人e l e m e n t :7 ] , 2 5 的地址为1 2 , 与5 1 发生冲突,线性探查后存入element[0],存放后的散列表为
| 散列地址 | 0 | | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | | 7 | | 8 | | 9 | | 10 | | 11 | | 12 |
| 关键码 |25| |27| |41| |68| | | |18| | 5 | |32| |73| |99| | 10 | | | | 51 |
线性探测容易出现堆积现象,即在处理同义词的过程中又添加了非同义词冲突。
双散列函数探查序列
对关键码集合K={18,10,73,7}, 取h(key)=key%5, h2 (key) =key%3+1,则h(18)=3, h(10)=0, h(73)=3, h(7)=2;
h2 (18)=1, h2 (10)=2, h2 (73)=2, h2 (7)=2。
|散列地址| 0 | 1 | 2 | 3 | 4 |
| 关键码 |10| |73|18| 7 |
|73| | 7 |13|
开地址法散列表上的检索
对给定key值:
(1)根据散列函数求出散列地址;
(2)若该位置无记录,则检索失败结束;
(3)否则比较元素关键码,若与 key 相等则检索成功结束;
(4)否则根据本散列表设计的冲突处理方法找出“下一地址”, 回到步骤(2) 用这个位置检查
typedef int KeyType;
typedef int DataType;
typedef struct {
KeyType key; /* 字典元素的关键码字段*/
DataType value; /* 字典元素的属性字段*/
} DicElement;
typedef struct {
int m; /* m为基本区域长度 */
DicElement *elements;
} HashDictionary;
typedef HashDictionary *PHashDictionary;
int linearSearch(HashDictionary *phash, KeyType key, int
*position) {
int d = h(key), inc; /* 设 h 为散列函数 */
for (inc = 0; inc < phash->m; inc++) {
if (phash->elements[d].key == key) {
*position = d; return 1; /* 检索成功 */
}
else if (phash->elements[d].key == 0) {
*position = d; return 0; /* 检索失败,找到空位置 */
}
d = (d+1) % phash->m;
}
*position = -1; /* 散列表溢出 */
return 0;
}
拉链法
基本思想:元素存在基本区域之外;为每个关键码建立一个链接表,所有关键字为同义词的记录存储在同一个链表中。
•所有元素可以统一处理(无论是否冲突)。
• 允许任意的负载因子。
• 最简单的方法是把新元素插在链接表头。如果要防止出现重复关键码,就需要检查整个链表。
对关键码集合K={18,10,73,7}, 取h(key)=key%5,则 h(18)=3, h(10)=0, h(73)=3, h(7)=2.
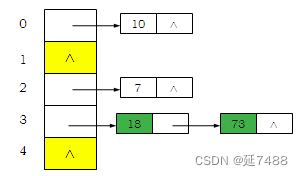
第七章 高级字典结构
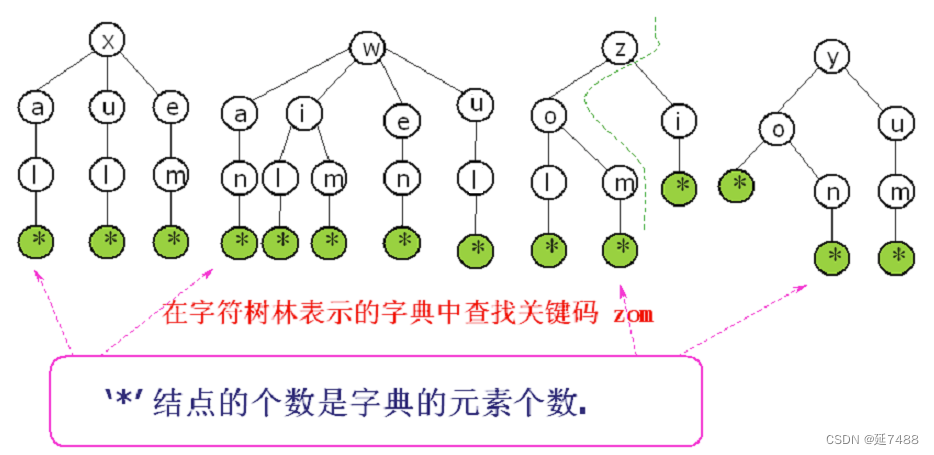
字符树(林)的构造
前提:字典所有关键码都是字符串
方法
字符树中的每个结点表示关键码中的一个字符;
从根出发的每条路径上,所对应的字符连接起来得到的字符串是一个关键码;
一个字典的所有关键码,可用一个字符树(林)中从根到其它结点路径对应字符串的集合表示;
在每个构成字典关键码的结点上增加一个指向对应元素的指针,就成为相应字典的一个字符树表示。
K={xal,wan,wil,zol,yo,xul,yum,wen,wim,zi,yon,xem, wul,zom}。
关键码由2至3个字符组成:第一个字符为w,x,y,z,第二个字符可为a,e,i,o,u,第三个字符可为l,m,n。
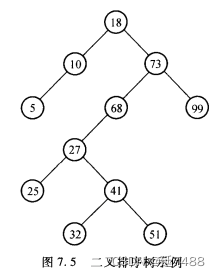
二叉排序树(二叉搜索树)
关键码为结点的二叉树
如果其左子树非空,则左子树中所有结点的关键码都小于根结点的关键码;
如果其右子树非空,则右子树中所有结点的关键码都大于根结点的关键码;
其左右子树(如果存在)也是二叉排序树。
对称序周游,可得到按关键码排序的递增序列。
Eg.K= {18,73, 10, 5,68, 99, 27, 41,51, 32, 25}对称序周游序列为: 5,10,18,25,27,32, 41,51,68,73,99.
则二叉排序树为
平衡二叉排序树
平衡二叉排序树又称AVL树,适合动态字典的表示。
平衡因子BF :结点的右子树与左子树的高度之差。可能取值只有 -1, 0, 1.
n个结点平衡二叉排序树的高度小于c *log 2n (c为常量).
第八章 排序
第九章 图
图的基本概念
有向图:有向图中的边有方向,边是顶点的有序对。 有序对用尖括号表示。<vi,vj> 表示从 vi 到 vj 的有向边, vi 是边的始点,vj是边的终点。称顶点vi 邻接到顶点vj 。 也称这条边与顶点 vi 、vj关联。
无向图:无向图中的边没有方向,是顶点的无序对。 用圆括号表示,(vi ,vj) 和 (vj ,vi) 表示同一条无向 边。称顶点vi 和顶点vj邻接。也称这条边与顶点 vi 、vj 关联。
完全图: 任意两个顶点之间都有边的有向图(或无向图).
n 个顶点的无向完全图有 n*(n-1)/2 条边;
n 个顶点的有向完全图有n*(n-1) 条边。
顶点的度、入度和出度
无论有向图无向图,顶点数n,边数e等于(所有点的度数之和)/2。
路径:可达;
路径长度
回路(环):起点终点相同
简单回路:其他顶点均不相同的回路
简单路径:不包含环的路径
子图
有根(有向)图
根:出发可到达图中所有顶点
有根图中根可能不唯一
树是有唯一根的有根图,且所有顶点的入度至多为1
连通(无向)图
连通
连通图:所有不同点之间连通
连通分量:无向图中的一个极大连通子图。若G不连通,它的连通分量将多于一个。
有向图的连通性
强连通图、强联通分量
带权图:每条边都有权值
网络:带权的无向图
给定权值找最优路径
图的周游(给定定点周游)
深度优先周游(通过深度优先搜索的方式周游)
广度优先周游(通过广度优先搜索的方式周游)
图的储存:邻接矩阵
一个顺序存储顶点信息的顶点表+一个存储顶点间相互关系的关系矩阵
typedef char VexType;
typedef float AdjType;
typedef struct {
VexType vexs[VN]; /* 顶点信息 */
AdjType arcs[VN][VN]; /*关系矩阵*/
}GraphMatrix;
/* VN为图中顶点个数*/
arcs[i, j] =1则(vi,vj)或<vi,vj>是图G的边,=0则不是。
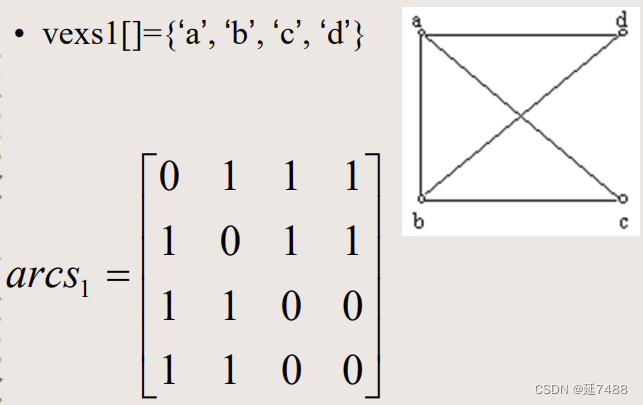
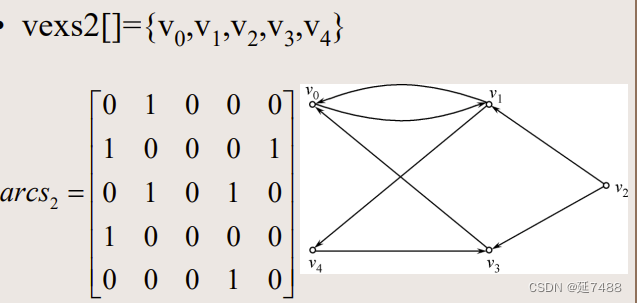
特点
(1) 无向图的关系矩阵一定是一对称矩阵。
(2) 无向图的关系矩阵的第i行(或第i列)非零元素个数为第i个顶点的度D(vi)。
(3) 有向图的关系矩阵的第i行非零元素个数为第i个顶点的出度OD(vi),第i列非零元素个数就是第i个顶点的入度ID(vi)。
(4) 从图的邻接矩阵表示,很容易确定图中任意两个顶点之间是否有边相连。
带权的邻接矩阵和邻接表
带权图
如果G是带权的图,wij是边(vi,vj)或< vi,vj> 的权,则其关系矩阵的所有对角线的值为0,其它元素定义为∶
arcs[i, j] ={wij,若 (vi,vj)或<vi,vj> 是图G的边(i ≠ j)
{∞,若不是
邻接矩阵
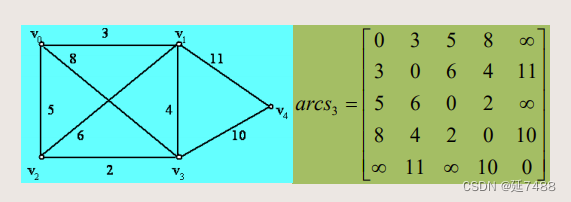
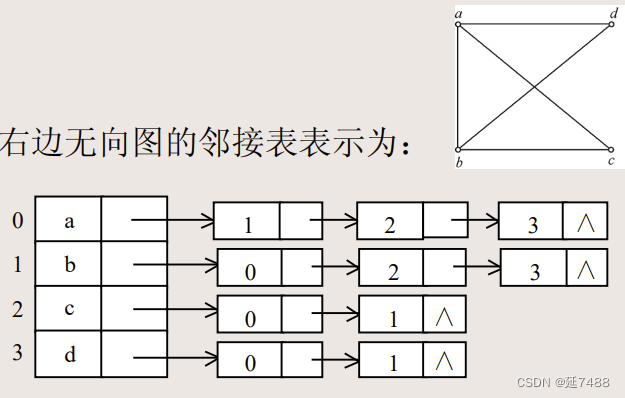
邻接表
顺序存储的顶点表+ 与每个顶点相关联的(n个)链式存储的边表
struct EdgeNode;
typedef struct EdgeNode * PEdgeNode;
typedef struct EdgeNode * EdgeList;
struct EdgeNode{
int endvex; /* 相邻顶点在顶点表中下标 */
AdjType weight; /* 边的权,非带权图应该省略 */
PEdgeNode nextedge; /* 链字段 */
/* 边表中的结点 */
typedef struct{
VexType vertex; /* 顶点信息 */
EdgeList edgelist; /* 边表头指针 */
} VexNode ;/* 顶点表中的结点 */
typedef struct {
VexNode vexs[VN]; /*顶点表 , VN为图中顶点个数*/
}GraphList; /* 图的邻接表表示 */
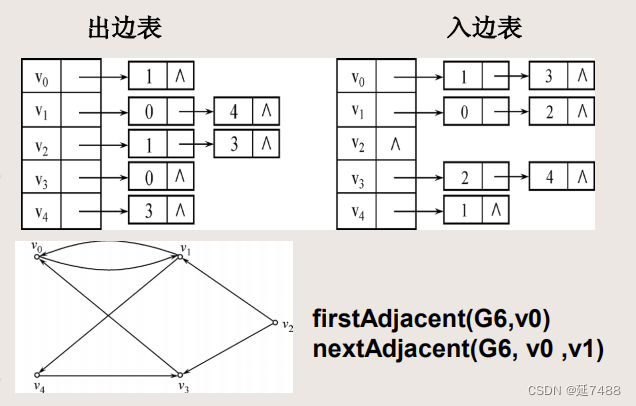
最小生成树MST
图的最小生成树不一定唯一。
prim
设G=(V,E)是具有n个顶点的网络。
• T=(U,TE)为(构造中)G的最小生成树,U是T的顶点集合,TE是T的边集合。T 初始状态是空树。
(1) 从集合V中任取一顶点(例如取顶点v0)放入集合U中,这时U={v0},TE=NULL,
(2)在所有一个顶点在集合U里,另一个顶点在集合V-U里的边中,找出权最小的边(u,v)(u∈U,v∈V-U),将该边放入TE,并将顶点v加入集合U。
重复上述操作(2)直到U=V为止。
结果TE中有n-1条边,T=(U,TE)就是G的一棵最小生成树
void prim(GraphMatrix * pgraph, Edge mst[]) {
int i, j, min, vx, vy;
double weight; Edge edge;
for (i = 0; i < VN-1; ++ i) { /* mst[]初始化为(v0, vi) */
mst[i].start_vex = 0;
mst[i].stop_vex = i+1; /* mst[i] 保存v0到vi+1的边信息 */
mst[i].weight = pgraph->arcs[0][i+1];
}
/* mst[i]..mst[n-2]记录从 U 到 V-U 顶点的最短边 */
for (i = 0; i < VN-1; ++ i) { /* 循环加入各边,共n-1条 */
weight = MAX; min = i;
for (j = i; j < VN-1; ++ j)
/* 从边mst[i] .. mst[n-2]中选最短的 (vx,vy) */
if(mst[j].weight < weight) {
weight = mst[j].weight;
min = j;
}
/* mst[min]是 U 到 V-U 的边 (vx,vy) 中最短的,
将mst[min]加入MST(换到 mst[i]) */
edge = mst[min]; mst[min] = mst[i]; mst[i] = edge;
vx = mst[i].stop_vex; /* vx为刚加入mst的顶点的下标 */
/* 考察mst[i+1] .. mst[n-2],是否该用来自vx的边取代 */
for(j = i+1; j < VN-1; ++ j) {
vy = mst[j].stop_vex;
weight = pgraph->arcs[vx][vy];
if (weight < mst[j].weight) {
mst[j].weight = weight;
mst[j].start_vex = vx;
}
}
}}
krudkal
设G=(V,E)是网络,最小生成树的初始状态为只有n个顶点而无边的非连通图T=(V,φ),T中每个顶点自成为一个连通分量。
将集合E中的边按权递增顺序排列,从小到大依次选择顶点分别在两个连通分量中的边加入图T,则原来的两个连通分量由于该边的连接而成为一个连通分量。
依次类推,直到T中所有顶点都在同一个连通分量上为止,该连通分量就是G的一棵最小生
成树。
int kruskal(GraphMatrix *graph, Edge mst[]) {
int i, j, num = 0, start, stop;
double minweight;
int status[VN];
for (i = 0; i < VN; ++ i)
status[i] = i; /* 每个顶点属于自己代表的连通分支 */
while (num < VN - 1){
minweight = MAX;
for (i = 0; i < VN-1; ++ i)
for (j = i+1; j < VN; ++ j)
if ( graph->arcs[i][j] < minweight ){
start = i; stop = j;
minweight = graph->arcs[i][j];
}
/* start和stop是找到的最短边的起点和终点 */
if (minweight == MAX) return 0; /* 无 MST */
/* 加入start和stop组成的边不产生回路*/
if (status[start] != status[stop]){ /* 不属于同一连通分支 */
mst[num].start_vex = start;
mst[num].stop_vex = stop;
mst[num].weight = graph->arcs[start][stop];
++ num;
/* 原 status[stop] 代表的连通分支 的结点,现都属于status[start] 代表的连通分支,该代表顶点 */
for ( j = status[stop], i = 0; i < VN; ++ i)
if (status[i] == j) status[i] = status[start];
}
/* 删除start和stop组成的边*/
graph->arcs[start][stop] = MAX;
}
return 1; /* 得到了最小生成树*/
}
最短路径
dijkstra
void dijkstra(GraphMatrix *graph, Path dist[]) {
int i, j, mv; AdjType min;
init(graph, dist); /* 初始化,集合U中只有顶点v0 */
for(i = 1; i < VN; ++ i) {
min = MAX; mv = 0;
for (j = 1; j < VN; ++ j) /*在V-U中选出距 v0 最近的顶点*/
if( graph->arcs[j][j] == 0 && dist[j].length < min )
{ mv = j; min = dist[j].length; }
if (mv == 0) break; /* v0 与 V-U 的顶点不连通,结束 */
graph->arcs[mv][mv] = 1;/* 顶点mv加入U */
for (j = 1; j < VN; ++ j) { /*调整V-U 顶点的已知最短路径*/
if (graph->arcs[j][j] == 0 && /*为V-U的顶点*/
dist[j].length>dist[mv].length + graph->arcs[mv][j]) {
dist[j].prevex = mv; /* 调整已知最短路径信息 */
dist[j].len = dist[mv].len + graph->arcs[mv][j];
} } }
}
floyd
void Floyd(GraphMatrix * pgraph, ShortPath * path) {
int i, j, k;
for (i = 0; i < VN; ++ i)
for (j = 0; j < VN; ++ j) {
if (pgraph->arcs[i][j] != MAX) path->nextvex[i][j] = j;
else path->nextvex[i][j] = -1;
path->a[i][j] = pgraph->arcs[i][j]; /* 复制邻接矩阵 */
}
for (k = 0; k < VN; ++ k)
for (i = 0; i < VN; ++ i)
for (j = 0; j < VN; ++ j) {
if ( path->a[i][k] == MAX || path->a[k][j] == MAX )
continue;
if ( path->a[i][j] > path->a[i][k]+ path->a[k][j] ) {
path->a[i][j] = path->a[i][k] + path->a[k][j];
path->nextvex[i][j] = path->nextvex[i][k];
} } }
拓扑排序(重点)
AOV网(顶点活动网):顶点表示活动,边表示活动间某种约束关系的有向图。
拓扑排序:
思想请戳隔壁文章 22/5/13 数据结构 排序
int topoSort(GraphList * paov, Topo * ptopo) { //算法精化
int i, nd = 0, top = -1;
int indegree[VN];
findInDegree(paov, indegree); /* 求图所有顶点的入度 */
for (i = 0; i < VN; ++ i) /* 入度0的顶点入栈 */
if (indegree[i] == 0) {
indegree[i] = top; top = i;
}
/* 拓扑排序,将顶点序列记入ptopo,返回记入的顶点数 */
nd = topoList (paov, ptopo, indegree, top);
if (nd < VN) { /* AOV网中存在回路 */
printf ("The AOV has no topo-sort sequence.\n");
return 0;
}
return 1;
}
void findInDegree(GraphList* g, int *inDegree){
int i;
EdgeList p;
for (i = 0; i < VN; ++ i) inDegree[i] = 0;
for (i = 0; i < VN; ++ i)
for (p = g->vexs[i].elist; p != NULL; p = p->next)
++inDegree[p->endvex]; /* 邻接终点的入度加一 */
}
拓扑排序算法
int topoSort(GraphList * paov, Topo * ptopo) {
int i, nd = 0, top = -1;
int indegree[VN];
findInDegree(paov, indegree); /* 求图所有顶点的入度 */
for (i = 0; i < VN; ++ i) /* 入度0的顶点入栈 */
if (indegree[i] == 0) {
indegree[i] = top; top = i;
}
/* 拓扑排序,将顶点序列记入ptopo,返回记入的顶点数 */
nd = topoList (paov, ptopo, indegree, top);
if (nd < VN) { /* AOV网中存在回路 */
printf ("The AOV has no topo-sort sequence.\n");
return 0;
}
return 1;
}
int topoList(GraphList *paov, Topo *ptopo, int indegree[], int top) {
EdgeList p;
int i, k, nd = 0;
while ( top != -1) { /* 有入度0的顶点 */
i = top;
top = indegree[top]; /* top 顶点退栈 */
ptopo[nd++] = i; /* 将 i 记入拓扑序列 */
for (p = paov->vexs[i].elist; p != NULL; p = p->next) {
k = p->endvex;
if (--indegree[k] == 0) {
indegree[k] = top; top = k; /* 入度0的顶点入栈 */
}
}
}
return nd;
}

















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











