









目录
前言
快期末了,浅浅复习一下数据结构。
第一章 绪论
-
1.1 什么是数据结构
-
1.2 基本概念和术语
数据 :是能输入到计算机中并被计算机程序处理的符号的总称。
数据元素: 是数据的基本单位。
数据项: 数据的最小单位。
四种基本结构:集合、线性结构、树形结构、图状结构(网状结构)。
两种存储结构:顺序存储结构、链式存储结构。
-
1.4 算法和算法分析
算法的5个特性:有穷性、确定性、可行性、输入、输出。
算法设计的要求:正确性可读性、健壮性、效率高、低存储量。
时间复杂度T(n)的计算:就是看基本操作重复执行的次数。
第二章 线性表
线性表有链表和顺序表。
链表在插入、删除时比较好。
顺序表在查找时比较好。
1.顺序表的优缺点
优点:元素可以随机存取。
元素位置可用一个简单的公式表达并求取
缺点:在做插入或删除时,需要移动大量元素。
2.单链表的优缺点。
优点:在做插入或删除时,无需移动大量元素。
缺点:元素不可随机存取
元素位置表达求取较为复杂。
长度为n的单链表插入、删除、查找第i个元素的时间复杂度是 O(n)
第三章 栈和队列
循环队列 rear永远指的是空的。为了区分是满还是空。浪费一个空间,当(rear+1)%q==f时,表示循环队列满了。
第六章 树和二叉树
结点的度:结点拥有的子树数。
树的度:树内各结点的度的最大值。
二叉树中:
1.叶子的数量=度为2的数量+1;
2.具有n个结点的完全二叉树,深度为+1;前面的对数向下取整
第七章 图
无向完全图 1/2*n*(n-1)条边
有向完全图 n*(n-1) 条边
最小生成树:Prim算法、克鲁斯卡尔算法。
最短路径:dijkstra算法
关键路径:做题!!!!
第九章 查找
9.1 静态查找
-
顺序查找 :
1.从表中最后一个记录开始
2.逐个进行记录的关键字和给定值的比较
3.若某个记录比较相等,则查找成功
4.若直到第1个记录都比较不等,则查找不成功
将待查找的数存在a[0]处,即为哨兵。然后把数列存入a[1]到a[n]。查找时从后往前查找,这样就不需要每次查找都比较一次是否越界了,查找到就return i;break;
- 折半查找(二分查找):
1.先确定待查记录所在的范围(前部分或后部分)
2.逐步缩小(一半)范围直到找(不)到该记录为止
折半查找首先需要按升序排好数列,用冒泡排序法就行了。折半查找就是将数组的最小的下标设为low,最大的下标设为high。mid=(low+high)/2。每一次比较待查找的值与a[mid]的值。若相等就找到了;若不相等:
1)待查找的数>a[mid],low=mid+1;
(2)待查找的的数<a[mid],high=mid-1;再次比较,循环。
当high<low时跳出循环。说明没有找到。
纸质考试可能让我们画判定树,就是一颗二叉树,结点里是下标。
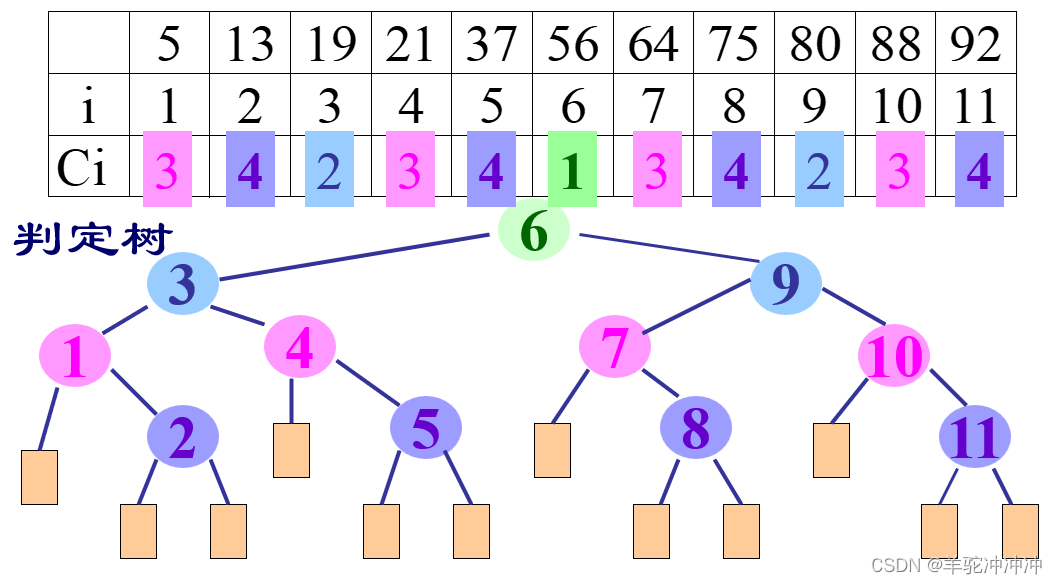
有了判定树之后可以算出ASL(成功)。上图这个例子ASL(成功)=(1*1+2*2+4*3+4*4)/11。
-
分块查找:
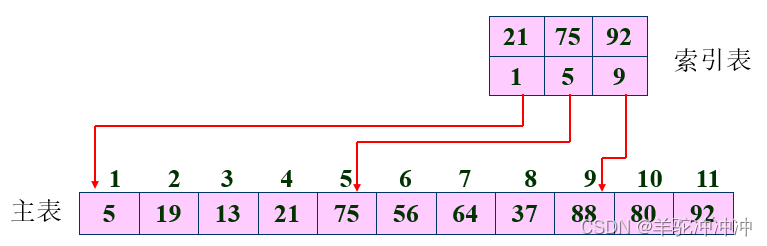
这个算法大致就是把所有数字分成很多块,把每一块的最大值记录下来。然后把待查找的数和这些最大值进行比较,就可以判断出这个数可能在哪一块中出现,然后再去这一个小块中查找。
9.2 动态查找
-
二叉排序查找
二叉排序树:或者是一颗空树,或者是具有下列性质的二叉树:
(1)若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;(2)若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;(3)它的左右子树也分别为二叉排序树。
题目:
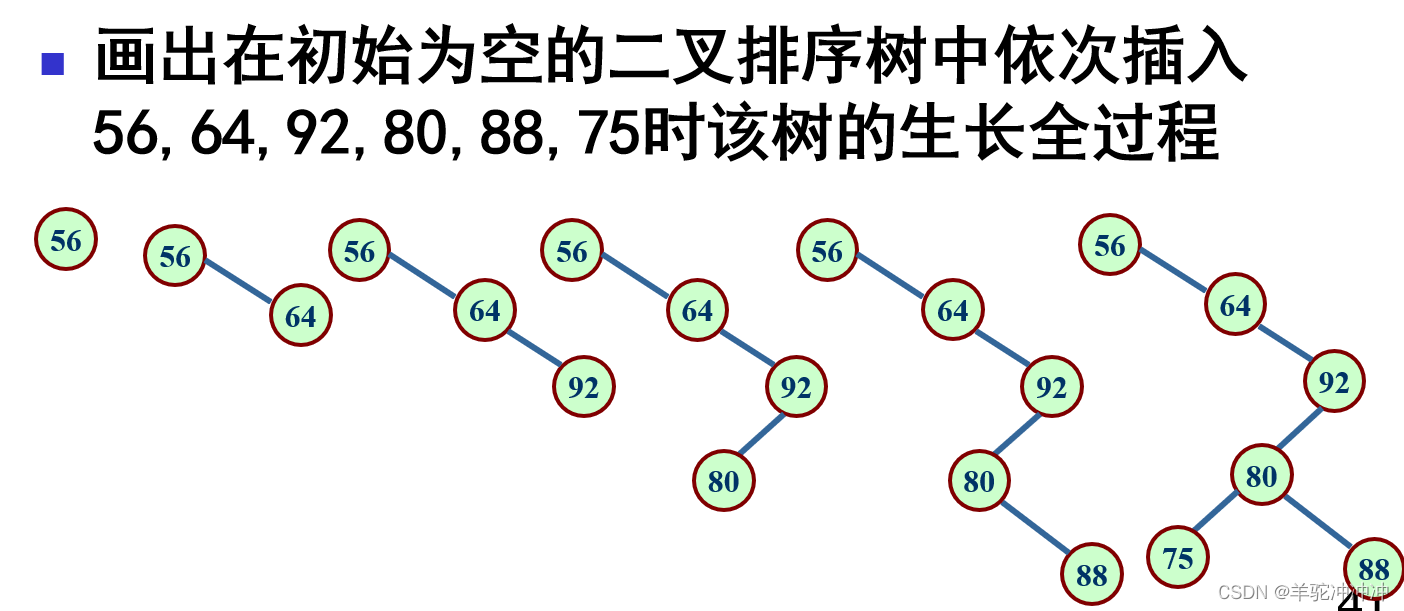
-
平衡二叉树AVL
平衡因子:左、右子树深度之差
平衡二叉树:是一个二叉查找树,并且每个结点的平衡因子只能取-1,0,1中的一个。
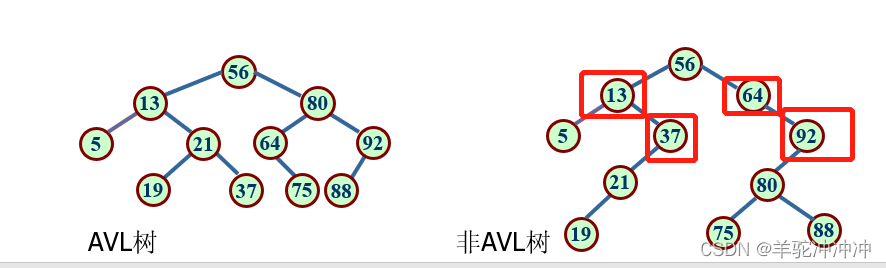
非AVL树中红框圈住的结点不满足平衡二叉树的要求。
非平衡树平衡化:
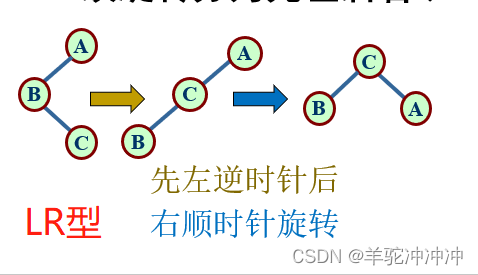
1.单向左旋 RR型

2.单向右旋 LL型
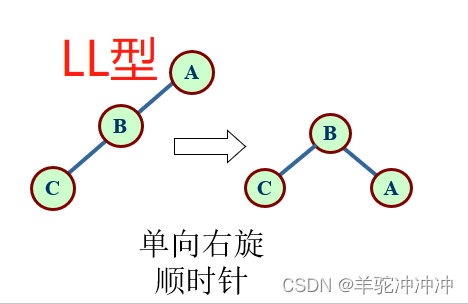
3.先单向右旋,再单向左旋 RL型
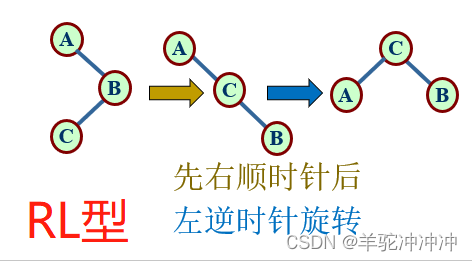
4.先单向左旋,再单向右旋 LR型
-
哈希查找
哈希函数构造方法:
1.直接定址法。
2.数字分析法。
3.平方取中法。
4.折叠法。
5.除留取余法。表长m,除数p。
H(key)=key%p。***p的选择注意:p<=m;p为质数 或 不包含小于20的质因数的合数。
处理冲突的方法:
1.开放定址法。线性探测,二次探测,随机探测。
给定关键字集合{19,01,23,14,55,68, 11,82,36},设定哈希函数H(key)=key MOD 11 (表长=11)
 2.再哈希法。
2.再哈希法。
3.链地址法(拉链法)。分为表头插入和表尾插入。
给定关键字集合{19,01,23,14,55,68, 11,82,36},设定哈希函数H(key)=key MOD 11 (表长=11)[表后插入]
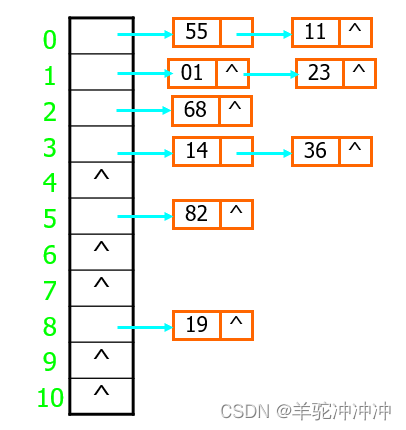
ASL = (1/9)(1x6 + 2x3) = 12/9
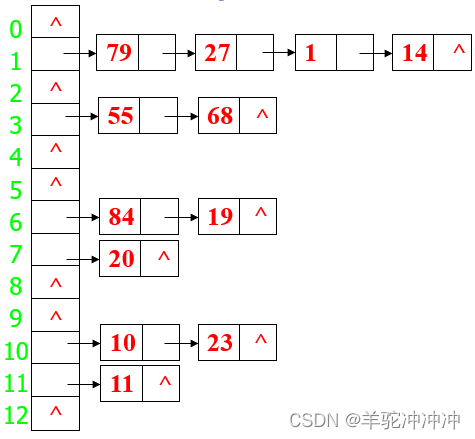
已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79)哈希函数为: H(key)=key MOD 13,用链地址法处理冲突[表头插入]
第十章 排序
10.1 插入排序---希尔排序
插入排序 O(). 稳定。
希尔排序O().不稳定。

10.2 冒泡排序---快速排序
冒泡排序O(). 稳定。
快速排序 O().不稳定。
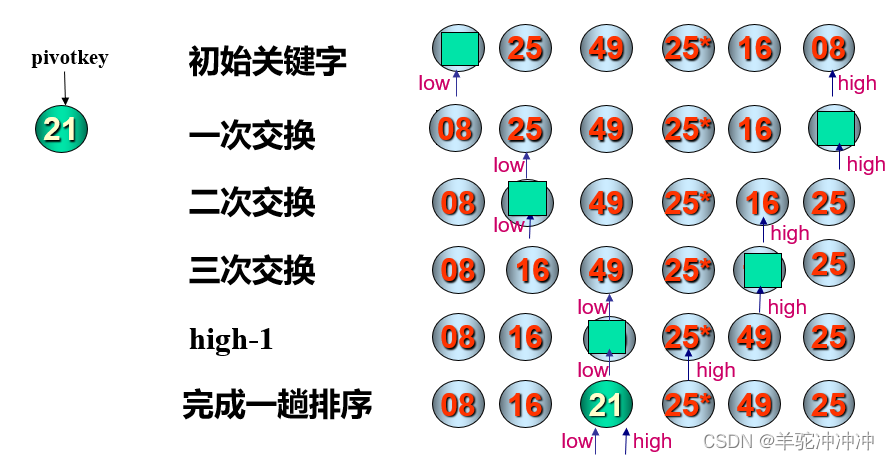
1.从high指向的记录开始,向前找到第一个关键字的值小于Pivotkey的记录,将其放到low指向的位置,low+1
2.从low指向的记录开始,向后找到第一个关键字的值大于Pivotkey的记录,将其放到high指向的位置,high-1
3.重复1,2,直到low=high,将枢轴记录放在low(high)指向的位置
10.3 选择排序---堆排序
选择排序O().不稳定。
选择排序:每一趟(例如第i趟,i=0,1,…,n-2)在后面n-i个待排序记录中选出关键字最小的记录,与第i个记录交换
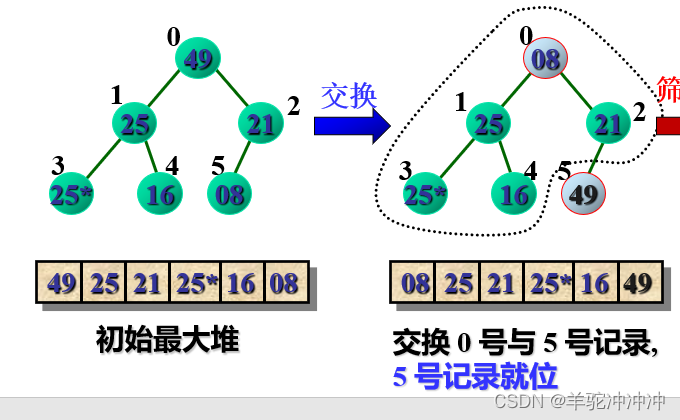
堆排序 O().不稳定。
最大堆:并且
.
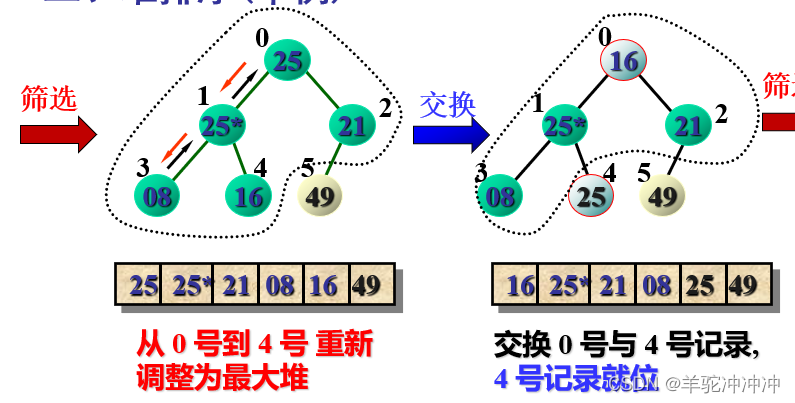
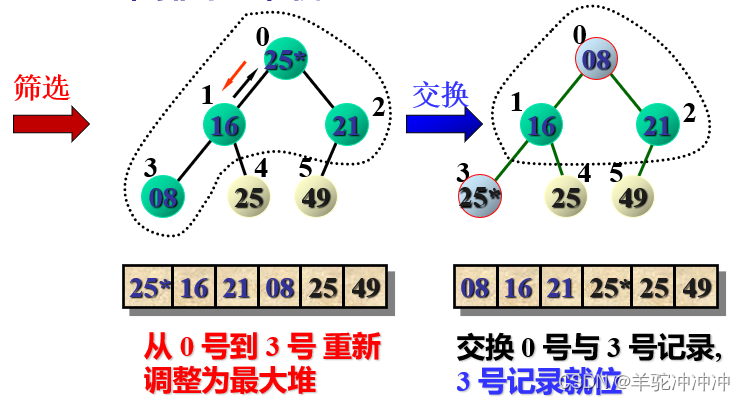
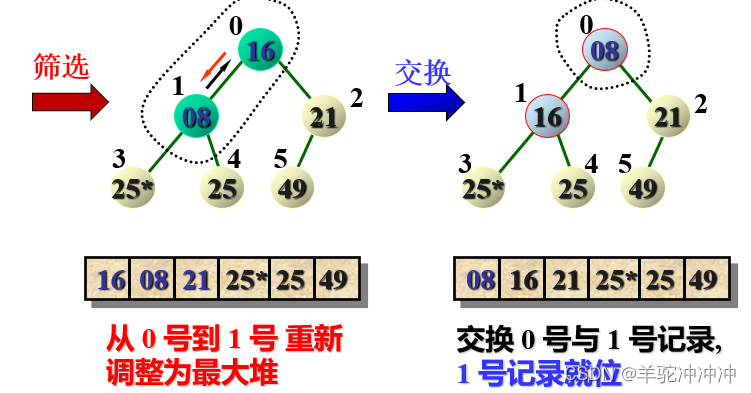
创建初始堆:由最后一个非终端结点(第n/2个结点)开始至第1个结点,逐步做筛选
交换
n个序列需要n-1次(筛选+交换)。

10.4 归并排序
归并排序O(m+n),稳定。
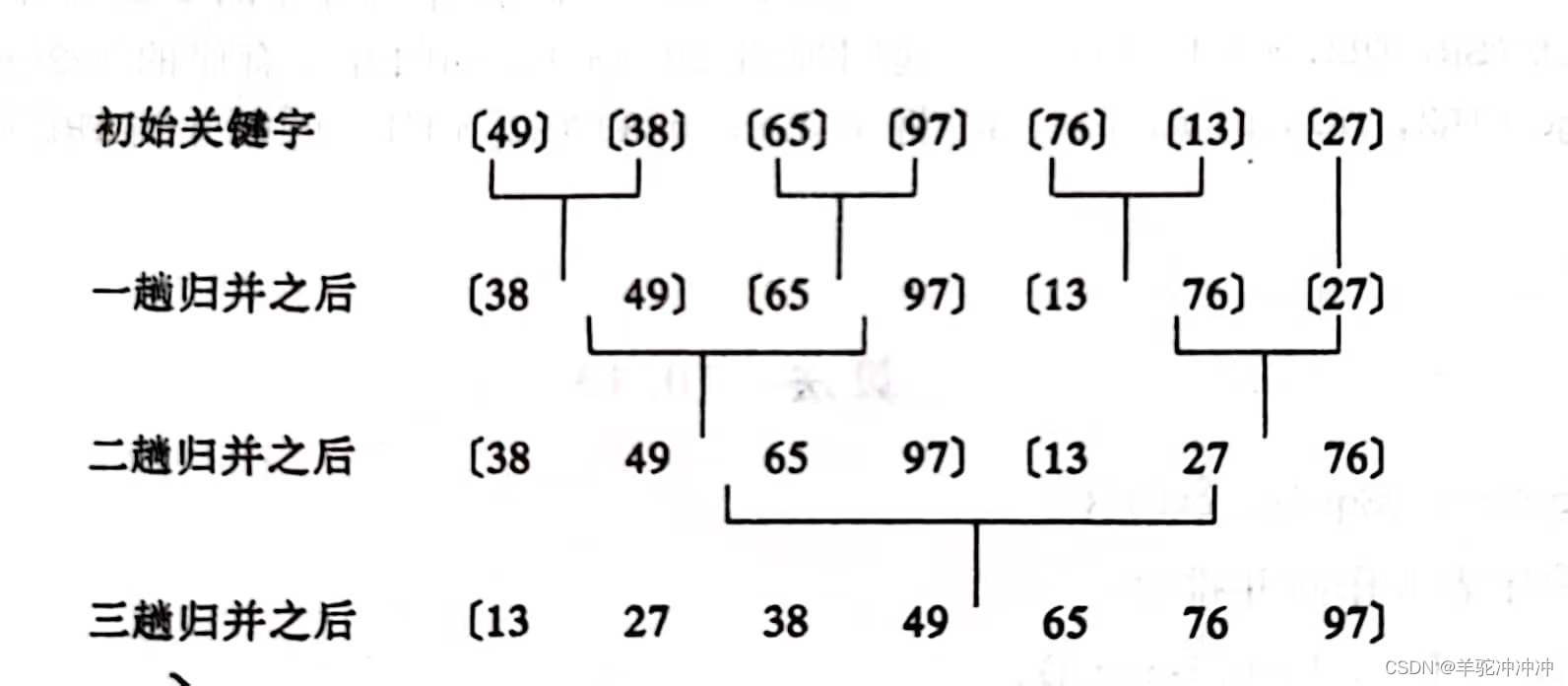
2-路归并排序O(),稳定。
10.5 基数排序
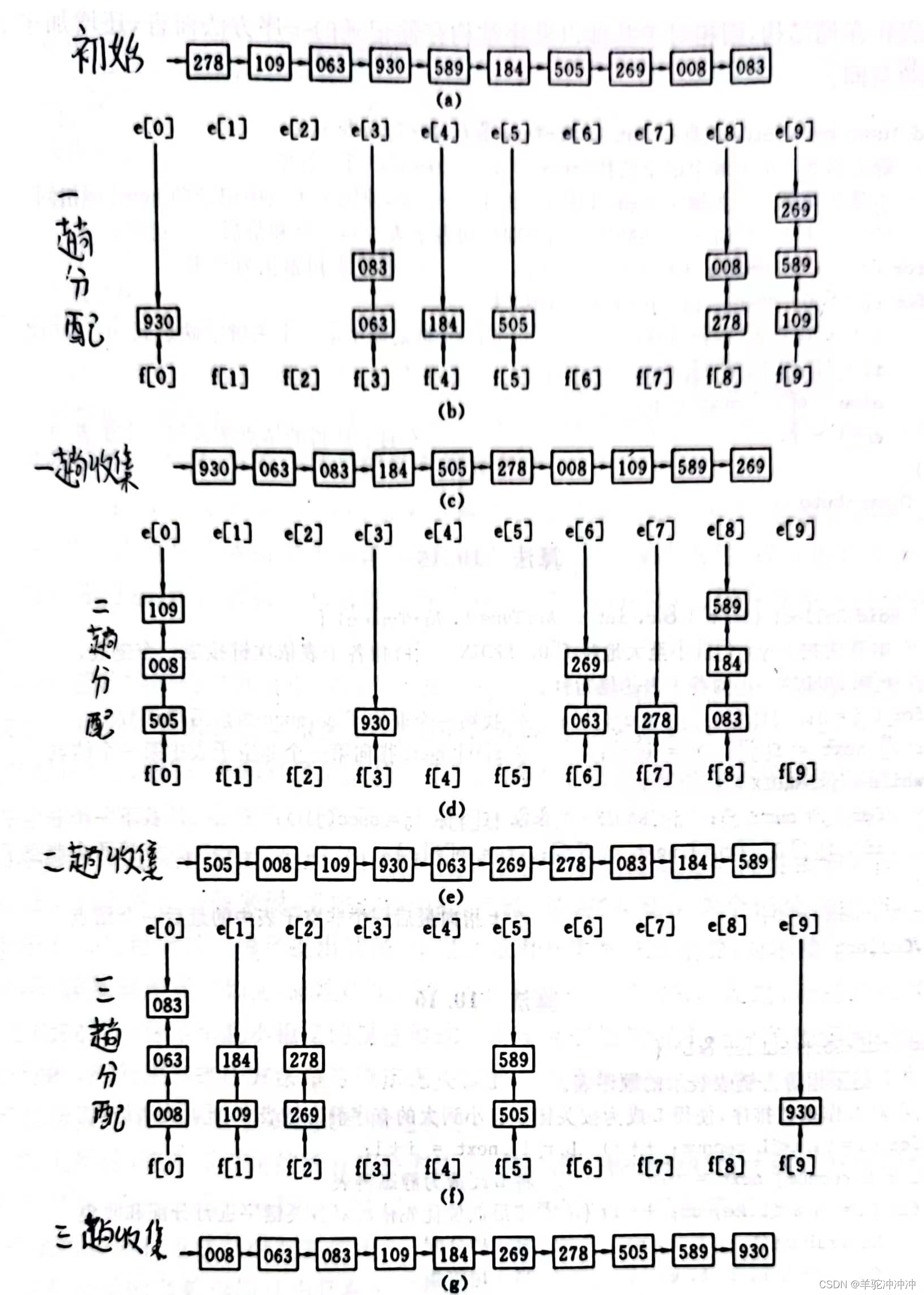
链式基数排序,先按最低位分配、收集。再往高位走。
总结
主要是针对笔试,一些概念上的东西。慢慢更,希望不要半途而废。















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









