






1. 横向取最值
GREATEST( value1,value2,value3,...) --取一条记录中的最大值 横向取值
LEAST( value1,value2,value3,...) --取一条记录中的最小值 横向取值
2. 整理表碎片
OPTIMIZE TABLE table_name --通过制作原来的表的一个临时副本来工作
使用场景:当您的库中删除了大量的数据后,您可能会发现数据文件尺寸并没有减小。这是因为删 除操作后在数据文件中留下碎片所致。optimize table 可以去除删除操作后留下的数据文件碎片,减小文件尺寸,加快未来的读写操作。您只要在做完批量删除,或定期(如 每一两个月)进行一次数据表优化操作即可。
3. 统计数据库中表的数量
SELECT
COUNT(*) TABLES,
table_schema
FROM
information_schema.TABLES
WHERE
table_schema = 'db_name'
GROUP BY
table_schema
4. 查询当前数据库所有表名
SELECT
table_name
FROM
information_schema.TABLES
WHERE
table_schema = 'db_name'
5. 查询当前表所有列信息
SELECT
*
FROM
information_schema.COLUMNS
WHERE
TABLE_NAME = 'table_name'
6. mysl各种函数
--6-1.字符串函数
CONCAT(str1,str2...) --连接字符串str1,str2为一个完整字符串
INSERT(str,x,y,instr) --将字符串从第x位置开始,y个字符长度的子串替换为字符串instr
LOWER(str) --小写
UPPER(str) --大写
LEFT(str,x) --返回字符串最左边的x个字符
RIGHT(str,x) --返回字符串最右边的x个字符
LPAD(str,n,pad) --使用字符串pad对字符串str最左边进行填充,直到长度为n个字符长度
RPAD(str,n,pad) --使用字符串pad对字符串str最右边进行填充,直到长度为n个字符长度
LTRIM(str) --去掉字符串str左边的空格
RTRIM(str) --去掉字符串str右边的空格
REPEAT(str,x) --返回字符串str重复x次的结果
REPLACE(str,a,b) --使用字符串b替换字符串中所有出现的a
STRCMP(str1,str2) --比较字符串str1,str2
TRIM(str) --去掉字符串str头和尾的空格
SUBSTRING(str,x,y) --返回字符串str中从x位置起y个长度的字符串
--6-2.常用数值函数
ABS(x) --返回数组x的绝对值
CEIL(x) --返回大于或等于x的最小整数值
FLOOR(x) --返回小于或等于x的最大整数值
MOD(x,y) --返回x除以y的余数
RAND() --返回0-1内的随机数
ROUND(x,y) --返回数值x的四舍五入后有y位小数的数值
TRUNCATE(x,y) --返回数值x且截断为y位小数的数值
--6-3.常用日期和时间的函数
CURDATE() --获取当前日期
CURTIME() --获取当前时间
NOW() --获取当前的日期和时间
UNIX_TIMESTAMP(date) --获取日期date的UNIX时间戳
FROM_UNIXTIME() --获取UNIX时间戳的日期值
WEEK(date) --返回日期date为一年中的第几周
YEAR(date) --返回日期date的年份
HOUR(time) --返回时间time的小时值
MINUTE(time) --返回时间time的分钟值
MONTHNAME(date) --返回时间time的月份值
--6-4常用系统信息函数
VERSION() --返回数据库的版本号
DATABASE() --返回当前数据库名
USER() --返回当前用户
LAST_INSERT_ID() --返回最近生成的AUTO_INCREMENT值
7. Mysql自增主键清零从1开始
--7-1:如果曾经的数据都不需要的话,可以直接清空所有数据,并将自增字段恢复从1开始计数
truncate table table_name
--7-2:直接设置数据表的 AUTO_INCREMENT 值为想要的初始值,比如200:
--*注意:需要大于当前最大id
ALTER TABLE byk_card AUTO_INCREMENT=200
8. IN 和 EXISTS 的区别及应用
--8-1:IN语句流程:
--01.首先会执行 from 语句找出 student 表;
--02.然后执行 in 里面的子查询,再然后将查询到的结果和原有的 student 表做一个笛卡尔积;
--03.再根据我们的s.stuid IN ss.stuid的条件,将结果进行筛选(既比较stuid列的值是否相等,将不相等的删除);
--04.最后,得到符合条件的数据。
SELECT
*
FROM
student s
WHERE
s.stuid IN ( SELECT ss.stuid FROM score ss WHERE ss.stuid < 999 )
--8-2:EXISTS语句流程:
--01.先执行主查询SQL:select * from student s
--02.然后根据表的每一条记录,执行以下语句,依次去判断where后面的条件是否成立:
--EXISTS(select stuid from score ss where ss.stuid = s.stuid);
--上面语句如果成立则返回true不成立则返回false;
--如果返回的是true的话,则该行结果保留,如果返回的是false的话,则删除该行,最后将得到的结果返回。
SELECT
*
FROM
student s
WHERE
EXISTS (
SELECT
ss.stuid
FROM
score ss
WHERE
ss.stuid = s.stuid)
--8-3:NOT IN 和 NOT EXISTS:
--01.如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;
--02.而not extsts 的子查询依然能用到表上的索引;
--03.所以无论那个表大,用not exists都比not in要快。
--*总结*:
in 和 exists的区别:
01.如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in,
02.反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。
03.区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键);
04.如果是exists,那么以外层表为驱动表,先被访问,
05.如果是IN,那么先执行子查询,所以会以驱动表的快速返回为目标,那么就会考虑到索引及结果集的关系了 ,
06.另外IN 时不对NULL进行处理。
07.in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
08.一直以来认为exists比in效率高的说法是不准确的。
**所以**:IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
9. MYSQL建表-自动创建时间和更新时间
CREATE TABLE `user` (
`id` int(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`last_modify_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
);
--DEFAULT CURRENT_TIMESTAMP :插入数据时当前字段自动插入当前时间
--ON UPDATE CURRENT_TIMESTAMP :更新数据时自动更新当前字段为当前时间
--这两个操作是mysql数据库本身在维护,所以根据这个特性来生成(创建时间)和(更新时间)两个字段,且不需要代码来维护
10. MYSQL-UUID()的用法
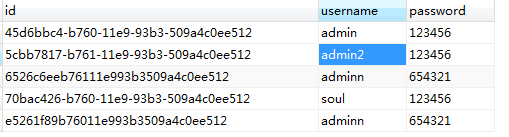
#去除uuid()自动生成的"-"
INSERT INTO USERVALUES(REPLACE ( UUID(), "-", "" ),'adminn','654321')
INSERT INTO USER VALUES (uuid(),'admin2','123456')
11. 在sql里面设置(空值赋空)
SELECT
IFNULL( username, '' ) AS uaerName
FROM
userinfo
WHERE
userid =1
IFNULL(test, ‘’) AS test
12. mysql添加天数函数
#给指定字段添加指定天数
date_add( recharge_time, INTERVAL 15 DAY )
13. mysql区间分组
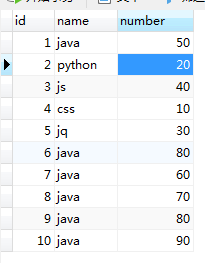
13-1.INTERVAL ( number,20,50,80 ):如果number小于后面的某个参数,就返回这个参数索引;
SELECT INTERVAL ( number,20,50,80 ) my_number,number FROM my_table
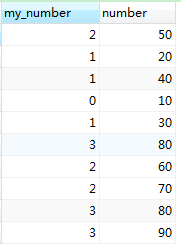
13-2. elt(n,str1,str2,…):如果n=1,则返回str1,…;注意n=0的话str会返回null值,例:
SELECT
elt( INTERVAL ( number, 20, 50, 80 ), 'one', 'two', 'three' ) AS my_number,
number
FROM
my_table
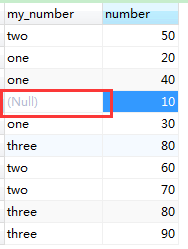
所以 最好这么写:
-- one = [0,20)
-- tow = [20,50)
-- three = [50,80)
-- four = [80)
SELECT
elt( INTERVAL ( number,0, 20, 50, 80 ), 'one', 'two', 'three','four' ) AS my_number,
number
FROM
my_table

13-3. 按照区间分组
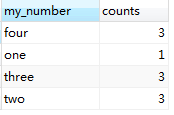
-- 方法一:
SELECT
elt( INTERVAL ( number, 0, 20, 50, 80 ), 'one', 'two', 'three', 'four' ) AS my_number,
count( * ) AS counts
FROM
my_table
GROUP BY
my_number
-- 方法二:
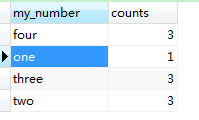
SELECT
CASE
WHEN number >= 0 AND number < 20 THEN 'one'
WHEN number >= 20 AND number < 50 THEN 'two'
WHEN number >= 50 AND number < 80 THEN 'three'
WHEN number >= 80 THEN 'four'
END my_number,
count(*) counts
FROM
my_table
GROUP BY
my_number
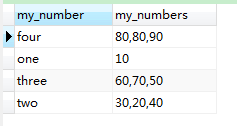
13-4. 列转行:按照区间显示区间内所有数据
SELECT
result.my_number,
GROUP_CONCAT( result.number ) my_numbers
FROM
(
SELECT
elt( INTERVAL ( number, 0, 20, 50, 80 ), 'one', 'two', 'three', 'four' ) AS my_number,
number
FROM
my_table
) result
GROUP BY
result.my_number
14. 行转列
-- 可以用case when 实现行转列
数据库事务的四大特性:
一、原子性(Atomicity):事务的所有操作视为一个原子单元,只能是完全提交或者完全回滚。
二、一致性(Consistency):事务在完成时,必须使所有的数据从一种状态到另一种状态,
所有变更都必须应用于事务的修改,以确保数据完整性。
三、隔离性(Isolation):一个事务中的操作语句所做的修改必须与其他事务所做相隔离。
四、持久性(Durability):事务完成后,所做的修改对数据的影响是永久的,即使系统故障重启之后也可以恢复。















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









