




 本文详细介绍了Elasticsearch中文档如何通过映射算法均匀分布到各个分片,以及文档创建、读取、批量操作的流程,强调了路由算法在分片选择中的作用,确保高效利用资源。
本文详细介绍了Elasticsearch中文档如何通过映射算法均匀分布到各个分片,以及文档创建、读取、批量操作的流程,强调了路由算法在分片选择中的作用,确保高效利用资源。
1.简介
(1).问题
文档最终会存储在分片上,假如一个文档最终存储在分片P1上,那么该文档是如何存储到分片P1上的?选择P1的依据是什么?
(2).解决方案
需要文档到分片的映射算法,目的是使得文档均匀分布在所有分片上,以充分利用资源。算法既不是随机选择算法,也不是轮询(round-robin)算法,原因是这两者算法需要维护文档到分片的映射关系,成本巨大。实际上elasticsearch选择的是根据文档值实时计算对应的分片来完成文档存储的,具体的映射算法如下。
shard = hash(routing)%number_of_primary_shards
- shard:文档需要进入的分片
- hash:hash算法保证文档数据可以均匀地分散在分片中
- routing:一个关键参数,默认是文档的id,可以自行制定
- number_of_primary_shards:主分片数
文档到分片的映射算法可以看出分片数在索引结构确定后就不可以更改的原因
2.文档创建流程
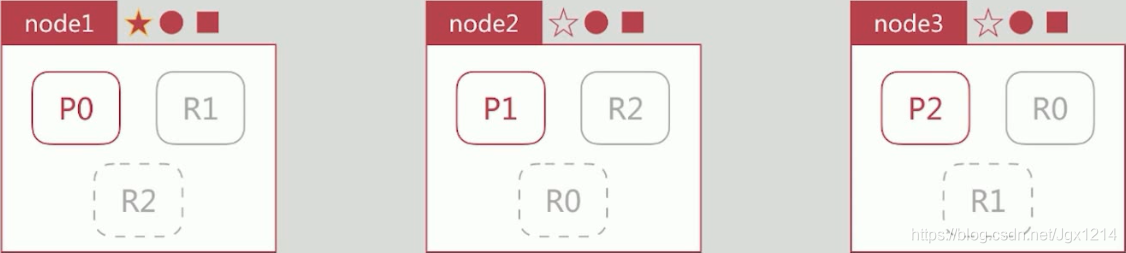
- client向node3发起创建文档的请求
- node3通过routing计算该文档应该存储在P1上,查询cluster state后确认主分片P1在node2上,然后转发创建文档的请求到node2
- P1接收并执行创建文档请求后,将同样的请求发送到副本分片R1
- R1接收并执行创建文档请求后,通知P1成功创建的结果
- P1接收副本分片创建成功的结果后,通知node3创建成功
- node3返回结果到client
3.文档读取流程
- client向node3发起获取文档1的请求
- node3通过routing计算该文档应该存储在P1上,查询cluster state后获取P1的主副分片列表,然后以轮询的机制获取一个分片,比如这里是R1,然后转发读取文档的请求到node1
- R1接收并执行读取文档请求后,将结果返回给node3
- node3返回结果到client
4.文档批量创建流程
- client向node3发起批量创建文档的请求
- node3通过routing计算所有文档对应的分片,然后按照主分片分配对应执行的操作,同时发送请求到涉及的主分片,比如这里的3个主分片都需要参与
- 主分片接收并执行请求后,将同样的请求同步到副本分片
- 副本分片执行结果后返回结果到主分片,主分片再返回到node3
- node3整合结果返回到client
5.文档批量读取流程
- client向node3发起批量获取文档的请求(mget)
- node3通过routing计算所有文档对应的分片,然后以轮询的机制获取需要参与的分片,按照分片构建mget请求,同时发送请求到涉及的分片
- 涉及的分片执行查询请求并返回结果
- node3返回结果到client

















 408
408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









