







1.拉链表
概念:记录一条数据每天的变化信息。
案例:
创建一个主表
---拉链表
---创建一个主表,模拟3个字段 按照时间进行分区
--- uuid 用户唯一表示
--- version 版本
--- visit_time 访问时间 以天为记录单位
create table if not exists ods_zipper_test(
uuid string comment "用户id",
version string comment "版本号",
visit_time string comment "时间"
)comment "主表"
partitioned by(day string)
row format delimited fields terminated by ",";按照分区导入数据
load data local inpath '/home/hadoop/test_data/拉链11.txt' overwrite into table ods_zipper_test partition(day="2018-10-11");
load data local inpath '/home/hadoop/test_data/拉链12.txt' overwrite into table ods_zipper_test partition(day="2018-10-12");
load data local inpath '/home/hadoop/test_data/拉链13.txt' overwrite into table ods_zipper_test partition(day="2018-10-13");数据样式:

创建一个拉链表 按照时间进行分区
---创建一个拉链表,
--- uuid version first_date(第一次访问时间) last_date(最后一次访问时间)
create table if not exists dw_zipper(
uuid string comment "用户id",
version string comment "版本号",
first_date string comment "第一次访问时间",
last_date string comment "最后一次访问时间"
)comment "拉链表"
partitioned by(day string);往拉链表中写入数据 写入的时候需要更改时间
--- 每天往拉链表中存入数据
insert overwrite table dw_zipper partition(day="2018-10-13")
select
coalesce(b1.uuid,b2.uuid) as uuid,
coalesce(b1.version,b2.version) as version,
coalesce(b2.first_date,b1.visit_time) as first_date,
coalesce(b1.visit_time,b2.last_date) as last_date
from
(
select
uuid,
version,
visit_time
from ods_zipper_test
where day="2018-10-13"
)b1
full outer join
(
select
uuid,
version,
first_date,
last_date
from dw_zipper
where day="2018-10-12"
)b2
on(b1.uuid=b2.uuid)
order by uuid;
拉链表中的数据为:
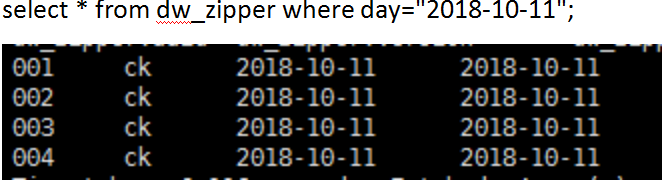
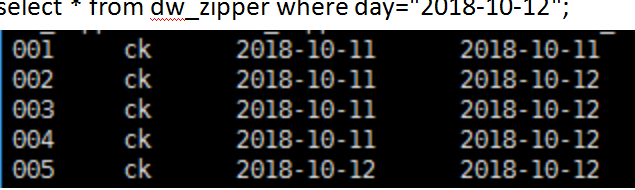

完整数据为

2.留存率
留存率=新增用户中登录用户数/新增用户数*100%(一般统计周期为天)
新增用户数:在某个时间段(一般为第一整天)新登录应用的用户数;
登录用户数:登录应用后至当前时间,至少登录过一次的用户数;
次日留存率:(当天新增的用户中,在注册的第2天还登录的用户数)/第一天新增总用户数;
第3日留存率:(第一天新增用户中,在注册的第3天还有登录的用户数)/第一天新增总用户数;
第7日留存率:(第一天新增的用户中,在注册的第7天还有登录的用户数)/第一天新增总用户数;
第30日留存率:(第一天新增的用户中,在注册的第30天还有登录的用户数)/第一天新增总用户数。案例:需求 根据上面的数据求以下:
时间 当天活跃用户数 新增用户数 累计活跃用户数 次日留存率 3日留存率创建业务表
create table if not exists da_user_action_d(
dt string comment '日期',
active_user_num bigint comment '活跃用户数',
new_user_num bigint comment '新增用户数',
total_active_user_num bigint comment '累计活跃用户数',
next_retention double comment '次日新增用户留存率',
three_retention double comment '3日新增用户留存率'
)
partitioned by(day string)根据拉链表来实现需求:按照时间来进行分区

insert overwrite table da_user_action_d partition (day="2018-10-13")
select
b1.dt as dt,--- 时间
b1.active_user_num as active_user_num,---当天活跃的用户数
b1.new_user_num as new_user_num,---当天新增的用户数
b1.total_active_user_num as total_active_user_num,--- 累计活跃用户数
round(b2.next_retention/b1.new_user_num,2) as next_retention,-- 次日新增用户留存率
round(b2.three_retention/b1.new_user_num,2) as three_retention-- 3日新增用户留存率
from
(
select
day as dt,--- 时间
sum(if(last_date=day,1,0)) as active_user_num, ---当天活跃的用户数
sum(if(first_date=day,1,0)) as new_user_num,---当天新增的用户数
count(1) as total_active_user_num--- 累计活跃用户数
from dw_zipper
group by day
)b1
left join
(
select
first_date as dt,
sum(if(date_add(first_date,1)=last_date,1,0)) as next_retention,-- 次日新增用户留存率
sum(if(date_add(first_date,2)=last_date,1,0)) as three_retention -- 3日新增用户留存率
from dw_zipper
where day="2018-10-13"
group by first_date
)b2 on b1.dt=b2.dt1).次日新增用户留存率 即2018-10-12 的数据

2).三日新增用户留存率 即2018-10-13的数据
![]()
3.同比和环比
同比:与历史同一时期进行比较,例如:今年6月与去年6月比较
环比:与上一统计段比较就是与前一个相邻的时期作比较,例如:今年3月与4月对比
同比率:(本期发展水平-去年同期水平)/去年同期水平×100%
环比率:(本期数-上期数)/上期数×100%
















 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









