







1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 背景
本文基于 linux-4.14.132 内核代码进行分析,x86 + Ubuntu 20.04.1 LTS Desktop + linux 5.11.0-37-generic 进行测试。
3. 什么 是 eBPF?
eBPF(Extended Berkeley Packet Filter) 起源于早期的网络包过滤机制 BPF(Berkeley Packet Filter),BPF 仅用作网络包的过滤,如 tcpdump 就是使用该机制来抓取网络包,而 eBPF 被扩展用来对内核进行观察,通过观察到的数据,进而进行内核优化、内核问题定位等工作。相对于 perf 等工具,eBPF 具有更好的性能。
4. eBPF 框架
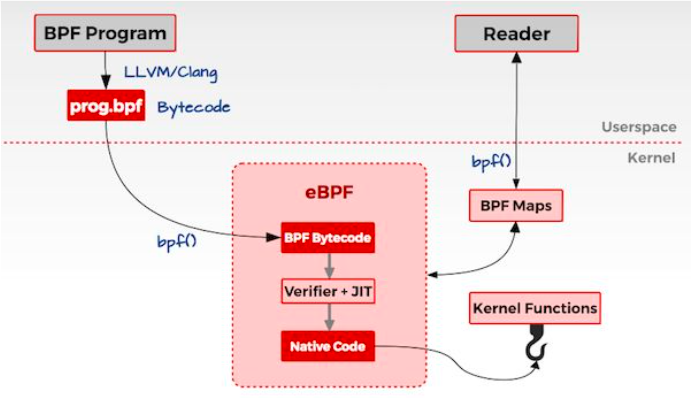
上面是 eBPF 机制的基本框架图,我找不到此图的原始出处,此处的引用如对原作者的权益造成损害,敬请告知。
这里先对上图框架的工作流程做下概述,后面再在此基础上展开具体细节。
1. 程序分为两部分: eBPF程序(图中BPF Program) + 用户态程序(图中Reader)。
2. 经 CLANG/LLVM 编译套件,将eBPF程序编译为符合eBPF指令规范的字节码程序;
经目标架构编译器(如 GCC),将用户态程序编译为目标架构可执行程序。
3. 用户态程序将eBPF字节码程序注入到内核空间;
内核空间eBPF虚拟机首先对字节码程序进行合法性检查、函数访问地址修正、bpf_map访问地址修正等工作,
接着通过目标架构 JIT 编译器,将字节码程序翻译为目标机器指令。
4. 用户态程序将eBPF程序关联到目标观察对象。
5. eBPF程序在一定条件下触发执行,将目标观察对象的观测数据写入bpf_map;
用户态程序从bpf_map读取观测数据。5. eBPF 范例
先通过一个范例来看看 eBPF 是怎么工作的。在下一章节,将对本节范例的工作流程做细节分析,借此梳理 eBPF 的工作原理。
范例来源于 linux 4.14 的 samples/bpf 目录的 sockex1_kern.c 和 sockex1_user.c 。其中:
. sockex1_kern.c 是 eBPF 程序,在网络接口 lo 往外发送数据路径中被触发,报告各协议类型往外发送网络包数据总量;
. sockex1_user.c 是用户空间程序,它首先将 sockex1_kern.o 注入到内核处理,然后将 sockex1_kern.o 挂接到 socket,
之后读取 sockex1_kern.o 写入到 bpf_map 的网络包统计数据。要编译 sockex1_kern.c 和 sockex1_user.c ,先要构建好其依赖的 linux 内核头文件、libbpf 、libelf 等。为方便操作,我将 sockex1_kern.c ,sockex1_user.c 以及它们依赖的部分源码文件从内核代码分离出来,放到了 此处。其中 kern 目录下为内核空间程序,user 目录下为用户空间程序。
5.1 编译
编译前,先切换到特权用户,测试需要特权用户才能完成。
5.1.1 编译环境搭建
5.1.1.1 安装 eBPF 程序依赖的内核头文件
测试 eBPF 程序 的编译依赖 linux 内核头文件,这个一般 Ubuntu 系统都自带了。如果没有,也可以通过如下命令进行安装:
$ sudo apt-get install linux-headers-$(uname -r) # 安装 linux 内核头文件
$ ls /usr/src/linux-headers-$(uname -r) # 查看安装的 linux 内核头文件5.1.1.2 安装 eBPF 程序编译套件
GCC 目前对 eBPF 虚拟机语言字节码支持的不好,所以需要另外安装 CLANG/LLVM 编译套件,来编译 eBPF 程序 。
$ sudo apt-get install clang-12 # 安装 CLANG/LLVM 编译套件5.1.1.3 安装用户程序依赖库
用户程序依赖 libbpf 和 libelf ,libbpf 已经从内核源码提取出来,所以现在只需要安装 libelf 了:
$ sudo apt-get install libelf-dev # 安装 libelf 开发库5.1.2 编译 eBPF 程序
# cd kern
# make clean; make上面的命令将在 kern 目录下生成 sockex1_kern.o 程序。
5.1.3 编译 用户空间程序
# cd user
# make clean; make上面的命令将在 user 目录下生成 sockex1_user 程序。
5.2 测试运行
# cd user
# ./sockex1_user ../kern/sockex1
[1] TCP 0 UDP 0 ICMP 0 bytes
[2] TCP 0 UDP 0 ICMP 196 bytes
[3] TCP 0 UDP 0 ICMP 392 bytes
[4] TCP 0 UDP 0 ICMP 588 bytes
[5] TCP 0 UDP 0 ICMP 784 bytes看到了吗?程序观测到了 ping 命令的 ICMP 包数据总量。
6. eBPF 实现
有了上面 eBPF 测试程序的初体验,本小节我们以上节的测试程序为入口,来梳理 eBPF 程序的工作流程。
6.1 eBPF 程序
eBPF 程序 sockex1_kern.o 到底是个什么样子?首先,它是一个符合 ELF 规范的二进制文件;其次,它的指令架构为 eBPF 。我们用 ELF 工具来观察下:
# readelf -h sockex1_kern.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Linux BPF
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 568 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 10
Section header string table index: 1看到了吗?程序的 Machine 字段为 Linux BPF ,这意思是说,程序是运行于 Linux BPF 的虚拟指令集虚拟机器架构,类似于 X86,ARM 等。再看下程序的 section 结构:
# readelf -s sockex1_kern.o
Symbol table '.symtab' contains 7 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS sockex1_kern.c
2: 0000000000000068 0 NOTYPE LOCAL DEFAULT 3 LBB0_3
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 4 OBJECT GLOBAL DEFAULT 6 _license
5: 0000000000000000 120 FUNC GLOBAL DEFAULT 3 bpf_prog1
6: 0000000000000000 28 OBJECT GLOBAL DEFAULT 5 my_map最后来看 sockex1_kern.o 程序的代码 sockex1_kern.c :
#include <uapi/linux/bpf.h>
#include <uapi/linux/if_ether.h>
#include <uapi/linux/if_packet.h>
#include <uapi/linux/ip.h>
#include "bpf_helpers.h"
/*
* 定义 用户程序 和 eBPF 程序 用来交互的 bpf_map 信息:
* 内核空间会根据 bpf_map_def 定义, 创建内核 bpf_map 对象,用户空间
* 程序通过 bpf_map_lookup_elem() 系列接口,读取该 bpf_map 对象存储空
* 间,从而得到 eBPF 程序写入到 bpf_map 的观测数据。
*/
struct bpf_map_def SEC("maps") my_map = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(u32),
.value_size = sizeof(long),
.max_entries = 256,
};
/*
* eBPF 程序段。
* 内核 eBPF 虚拟机运行程序段中的指令,这些指令会将观察到的数据,
* 经过加工处理后,填充到 bpf_map 对象的存储空间,之后 用户空间程序
* 可以读取 bpf_map 存储空间的数据。
*/
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
{
/*
* 读取 skb 的协议类型:
* index = *((char *)skb + ETH_HLEN + offsetof(struct iphdr, protocol));
* 也即:
* index = iphdr::protocol (IPPROTO_TCP, IPPROTO_UDP, IPPROTO_ICMP)
*
* load_byte() 为 CLANG 内置函数,作用是读取一个字节。
*/
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
long *value;
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
/*
* 别把 此处的 bpf_map_lookup_elem() 和 用户空间 libbpf 的同名函数 bpf_map_lookup_elem()
* 认为是同一回事:这里的 bpf_map_lookup_elem() 定义在 tools/testing/selftest/bpf/bpf_helpers.h
* 中,它是一个 枚举值,所以此处的 bpf_map_lookup_elem 并没有指向一个真正的函数,而是
* 一个指代内核函数的 枚举值。
* 当通过系统调用 sys_bpf(BPF_PROG_LOAD, ...) 将 eBPF 程序字节码 注入到内核时,
* 内核将会把 eBPF 程序字节码中调用指令(如此处的 bpf_map_lookup_elem(...))的目标
* 函数地址,修正为正确的地址 。如此处的 bpf_map_lookup_elem() 被修正为定义在
* kernel/bpf/helpers.c 中的 bpf_map_lookup_elem() 函数。
*
* 另外,此处对 &my_map 的访问也会让人觉得怪异,因为明明内核根据 SEC("maps") 中
* 的 bpf_map_def 信息创建 bpf_map 对象,并返回了该对象的 fd 到用户空间,但这里
* 的 eBPF 程序段,却用 &my_map 来访问,那不是风马牛不相及?那么这里是到底是怎么
* 访问到正确的 bpf_map 的呢?又是怎么和用户空间的访问对应起来的呢?
* 答案是数据访问重定位,CLANG/LLVM 编译套件会为 eBPF 代码中,所有对 bpf_map 的
* 访问,在编译输出的 eBPF 字节码程序中的重定位段中,插入数据重定位项。
* 具体细节见:
* 1. 用户空间代码修正 bpf_map 访问 fd
* do_load_bpf_file()
* parse_relo_and_apply()
* for (i = 0; i < nrels; i++) {
* ...
* insn[insn_idx].src_reg = BPF_PSEUDO_MAP_FD;
* if (match) {
* insn[insn_idx].imm = maps[map_idx].fd;
* } else {
* ...
* }
* }
* 2. 内核空间代码修正 bpf_map 访问指针
* sys_bpf(BPF_PROG_LOAD, ...)
* bpf_prog_load()
* bpf_check()
* replace_map_fd_with_map_ptr()
*/
/* 返回 bpf_map 中, 协议类型 index 指向的 map 数据指针 */
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
/*
* 累加包长度: *value += skb->len;
* 然后更新到 协议类型 index 指向的 bpf_map 数据地址。
*
* __sync_fetch_and_add() 为 CLANG 内置函数。
*/
__sync_fetch_and_add(value, skb->len);
return 0;
}
char _license[] SEC("license") = "GPL";这程序看起来有点奇怪,它既没有内核模块的 init 入口(如 module_init(xxx); 之类),也没有用户程序的 main() 函数,那它到底是怎么工作的呢?先别着急,要了解这一切,得先从用户空间程序入手。
在进入到用户空间程序分析之前,我们再来反汇编看一下程序 sockex1_kern.o 经 CLANG/LLVM 编译后生成的虚拟机指令序列,这对于后面的分析,将起到参照作用。
# llvm-objdump-12 -d sockex1_kern.o
sockex1_kern.o: file format elf64-bpf
Disassembly of section socket1:
0000000000000000 <bpf_prog1>:
0: bf 16 00 00 00 00 00 00 r6 = r1
1: 30 00 00 00 17 00 00 00 r0 = *(u8 *)skb[23]
2: 63 0a fc ff 00 00 00 00 *(u32 *)(r10 - 4) = r0
3: 61 61 04 00 00 00 00 00 r1 = *(u32 *)(r6 + 4)
4: 55 01 08 00 04 00 00 00 if r1 != 4 goto +8 <LBB0_3>
5: bf a2 00 00 00 00 00 00 r2 = r10
6: 07 02 00 00 fc ff ff ff r2 += -4
7: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
9: 85 00 00 00 01 00 00 00 call 1
10: 15 00 02 00 00 00 00 00 if r0 == 0 goto +2 <LBB0_3>
11: 61 61 00 00 00 00 00 00 r1 = *(u32 *)(r6 + 0)
12: db 10 00 00 00 00 00 00 lock *(u64 *)(r0 + 0) += r1
0000000000000068 <LBB0_3>:
13: b7 00 00 00 00 00 00 00 r0 = 0
14: 95 00 00 00 00 00 00 00 exit6.2 eBPF 用户程序
eBPF 用户程序 sockex1_user ,它是一切的起点。
int main(int ac, char **argv)
{
char filename[256];
/* sockex1_kern.o */
snprintf(filename, sizeof(filename), "%s_kern.o", argv[1]);
/*
* 加载 eBPF 程序 @filename:
* 1. 为所有的 map 段 (SEC("maps")) 中的 bpf_map_def 对象,创建内核对象 bpf_map ,
* 并返回所有指代所有这些 bpf_map 的匿名文件对象的 fd 到 map_fd[] ,总数记录到 map_data_count ;
* 2. 为 eBPF 程序中 的 所有程序段(如 sockex1_kern.c 中的 SEC("socket1") 段):
* . 创建内核程序段对象 (bpf_prog),并将程序段中字节码指令 @insns 存储到该对象 ;
* . 设置 eBPF 程序段的验证接口到 bpf_prog 对象,并通过验证接口验证字节码程序合法性;
* . 修正 bpf_map 访问指令中的 bpf_map 地址 和 bpf_map 访问函数的地址;
* . 设置程序段的解释执行接口;
* . 通过硬件架构的 JIT 编译器,将eBPF程序字节码编译为本地指令代码。
* 返回指代内核程序段对象 (bpf_prog) 的匿名文件对象的句柄 fd 到 prog_fd[], 总数据记录到 prog_cnt 。
* 加载一个程序段的出错日志,记录在缓冲 bpf_log_buf[] ,调用方可以打印该缓冲内容,查看出错的信息。
*/
if (load_bpf_file(filename)) {
printf("%s", bpf_log_buf); /* eBPF 程序加载出错日志信息 */
return 1;
}
sock = open_raw_sock("lo"); /* 创建本地回环网络接口 lo 监听套接字 */
/* 将 eBPF 程序 sockex1_kern.o 挂接到 套接字 @sock */
assert(setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, prog_fd,
sizeof(prog_fd[0])) == 0);
f = popen("ping -c5 localhost", "r"); /* 给 本地回环网络接口 lo 发 5 个 ping 包 */
(void) f;
/*
* 从 eBPF 内核程序 sockex1_kern.o 的 bpf_map ,
* 读取套接字 @sock 回应给 ping 的 TCP/UDP/ICMP 包数据累计总长度。
*/
for (i = 0; i < 5; i++) {
long long tcp_cnt, udp_cnt, icmp_cnt;
int key;
key = IPPROTO_TCP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &tcp_cnt) == 0);
key = IPPROTO_UDP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &udp_cnt) == 0);
key = IPPROTO_ICMP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &icmp_cnt) == 0);
printf("TCP %lld UDP %lld ICMP %lld bytes\n",
tcp_cnt, udp_cnt, icmp_cnt);
sleep(1);
}
return 0;
}6.2.1 加载 eBPF 程序
/* samples/bpf/bpf_load.c */
int load_bpf_file(char *path)
{
return do_load_bpf_file(path, NULL);
}
static int do_load_bpf_file(const char *path, fixup_map_cb fixup_map)
{
int fd, i, ret, maps_shndx = -1, strtabidx = -1;
Elf *elf;
...
Elf_Data *data, *data_prog, *data_maps = NULL, *symbols = NULL;
...
int nr_maps = 0;
fd = open(path, O_RDONLY, 0); /* 打开 sockex1_kern.o */
elf = elf_begin(fd, ELF_C_READ, NULL); /* 创建 sockex1_kern.o 的 ELF 对象 */
/* clear all kprobes */
i = system("echo \"\" > /sys/kernel/debug/tracing/kprobe_events");
/* scan over all elf sections to get license and map info */
/* 读取 sockex1_kern.o license, map section, symtab, kernel version 信息 */
for (i = 1; i < ehdr.e_shnum; i++) {
/*
* 读取第 @i 个 ELF section 的信息数据:
* @shname: section 名字
* @shdr: section 头
* @data: section 内容数据
*/
if (get_sec(elf, i, &ehdr, &shname, &shdr, &data))
continue;
if (strcmp(shname, "license") == 0) { /* sockex1_kern.c 通过 SEC("license") 指定 license 信息 */
processed_sec[i] = true;
memcpy(license, data->d_buf, data->d_size); /* 提取 license 信息 */
} else if (strcmp(shname, "version") == 0) { /* 通过 SEC("version") 指定目标内核版本 */
processed_sec[i] = true;
...
memcpy(&kern_version, data->d_buf, sizeof(int)); /* 提取 指定的内核版本信息 */
} else if (strcmp(shname, "maps") == 0) { /* 提取 SEC("maps") 段信息: section index, data */
int j;
maps_shndx = i;
data_maps = data;
for (j = 0; j < MAX_MAPS; j++)
map_data[j].fd = -1;
} else if (shdr.sh_type == SHT_SYMTAB) { /* 提取符号表以及其关联的字符串表信息 */
strtabidx = shdr.sh_link; /* 符号表关联的字符串表段索引: 该表给出了符号的名字 */
symbols = data; /* 符号表数据 */
}
}
...
/*
* 如果有 SEC("maps") 段, 将 BPF ELF 程序的所有 SEC("maps") 段注入到内核。
* 用户空间程序,从 内核空间 eBPF 程序的这些 map (bpf_map_def) 读取数据。
*/
if (data_maps) {
/*
* 解析所有 SEC("maps") 中包含的 bpf_map_def 对象到 map_data[],
* 返回 SEC("maps") 包含的 bpf_map_def 对象总数目到 nr_maps .
*/
nr_maps = load_elf_maps_section(map_data, maps_shndx,
elf, symbols, strtabidx);
...
/*
* 为解析到的 所有 bpf_map_def 对象(map_data[]) 创建内核 bpf_map 内核对象,
* 并返回内核用来指代所有这些内核 bpf_map 对象的 匿名文件对象的 fd 到 map_fd[] 。
* 创建的 bpf_map 对象总计数保存到 map_data_count 。
*/
if (load_maps(map_data, nr_maps, fixup_map))
goto done;
map_data_count = nr_maps;
processed_sec[maps_shndx] = true;
}
...
/* load programs */
/*
* 为 eBPF 程序中包含的所有程序段(如 sockex1_kern.c 中的 SEC("socket1") 段):
* . 创建内核程序段对象 (bpf_prog),并将程序段加载到该对象 ;
* . 设置程序段的验证接口,并通过验证接口验证程序合法性;
* . 设置程序段的解释执行接口。
*/
for (i = 1; i < ehdr.e_shnum; i++) {
...
if (get_sec(elf, i, &ehdr, &shname, &shdr, &data))
continue;
if (memcmp(shname, "kprobe/", 7) == 0 ||
memcmp(shname, "kretprobe/", 10) == 0 ||
memcmp(shname, "tracepoint/", 11) == 0 ||
memcmp(shname, "xdp", 3) == 0 ||
memcmp(shname, "perf_event", 10) == 0 ||
memcmp(shname, "socket", 6) == 0 || /* 如 sockex1_kern.c 中的 SEC("socket1") 段 */
memcmp(shname, "cgroup/", 7) == 0 ||
memcmp(shname, "sockops", 7) == 0 ||
memcmp(shname, "sk_skb", 6) == 0) {
ret = load_and_attach(shname, data->d_buf,
data->d_size);
if (ret != 0)
goto done;
}
}
ret = 0;
done:
close(fd); /* 解析 sockex1_kern.o 完毕 */
return ret;
}6.2.1.1 创建 eBPF 程序存储采集数据的 bpf_map
main()
load_bpf_file()
do_load_bpf_file()
load_elf_maps_section() /* 解析所有 SEC("maps") 中包含的 bpf_map_def 对象 */
load_maps() /* 创建内核 bpf_map */static int load_maps(struct bpf_map_data *maps, int nr_maps,
fixup_map_cb fixup_map)
{
for (i = 0; i < nr_maps; i++) {
...
/* 创建内核 bpf_map , 每个新建的 bpf_map 对应 1 个匿名文件句柄 */
if (maps[i].def.type == BPF_MAP_TYPE_ARRAY_OF_MAPS ||
maps[i].def.type == BPF_MAP_TYPE_HASH_OF_MAPS) {
} else {
map_fd[i] = bpf_create_map_node(maps[i].def.type,
maps[i].def.key_size,
maps[i].def.value_size,
maps[i].def.max_entries,
maps[i].def.map_flags,
numa_node);
}
maps[i].fd = map_fd[i];
...
}
return 0;
}
int bpf_create_map_node(enum bpf_map_type map_type, int key_size,
int value_size, int max_entries, __u32 map_flags,
int node)
{
union bpf_attr attr;
memset(&attr, '\0', sizeof(attr));
attr.map_type = map_type;
attr.key_size = key_size;
attr.value_size = value_size;
attr.max_entries = max_entries;
attr.map_flags = map_flags;
...
return sys_bpf(BPF_MAP_CREATE, &attr, sizeof(attr));
}
static inline int sys_bpf(enum bpf_cmd cmd, union bpf_attr *attr,
unsigned int size)
{
/* 进入内核空间创建 map 对象 (bpf_map) */
return syscall(__NR_bpf, cmd, attr, size);
}看内核空间 bpf_map 创建过程:
/* kernel/bpf/syscall.c */
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
union bpf_attr attr = {};
int err;
...
/* copy attributes from user space, may be less than sizeof(bpf_attr) */
if (copy_from_user(&attr, uattr, size) != 0)
return -EFAULT;
switch (cmd) {
case BPF_MAP_CREATE:
err = map_create(&attr);
break;
...
}
return err;
}
static int map_create(union bpf_attr *attr)
{
int numa_node = bpf_map_attr_numa_node(attr);
struct bpf_map *map;
int err;
...
/* find map type and init map: hashtable vs rbtree vs bloom vs ... */
/* 创建 @attr->map_type 类型的 bpf_map, 并绑定 类型操作接口 和 bpf_map_type */
map = find_and_alloc_map(attr);
...
/* 为 bpf map 分配设定独立的 id */
err = bpf_map_alloc_id(map);
...
/* 创建 bpf_map 匿名文件对象: 为 bpf map 分配 {fd,file,inode} */
err = bpf_map_new_fd(map);
...
return err; /* 返回 bpf map 的 fd */
}
/* 创建 @attr->map_type 类型的 bpf_map, 并绑定 类型操作接口 和 bpf_map_type */
static struct bpf_map *find_and_alloc_map(union bpf_attr *attr)
{
struct bpf_map *map;
/* 创建 @attr->map_type 类型的 bpf_map */
map = bpf_map_types[attr->map_type]->map_alloc(attr); /* array_map_alloc() */
/* 根据 @attr->map_type 类型, 设定 bpf_map 操作接口 */
map->ops = bpf_map_types[attr->map_type];
/* 设定 bpf_map 的类型 */
map->map_type = attr->map_type; /* BPF_MAP_TYPE_ARRAY */
return map;
}6.2.1.2 修正 eBPF 程序中 bpf_map 访问指令的句柄
main()
load_bpf_file()
do_load_bpf_file()
load_elf_maps_section() /* 解析所有 SEC("maps") 中包含的 bpf_map_def 对象 */
load_maps() /* 创建内核 bpf_map */
/* process all relo sections, and rewrite bpf insns for maps */
for (i = 1; i < ehdr.e_shnum; i++) {
...
if (get_sec(elf, i, &ehdr, &shname, &shdr, &data))
continue;
if (shdr.sh_type == SHT_REL) {
...
if (parse_relo_and_apply(data, symbols, &shdr, insns,
map_data, nr_maps))
continue;
}
}
static int parse_relo_and_apply(Elf_Data *data, Elf_Data *symbols,
GElf_Shdr *shdr, struct bpf_insn *insn,
struct bpf_map_data *maps, int nr_maps)
{
...
for (i = 0; i < nrels; i++) {
...
if (insn[insn_idx].code != (BPF_LD | BPF_IMM | BPF_DW)) {
printf("invalid relo for insn[%d].code 0x%x\n",
insn_idx, insn[insn_idx].code);
return 1;
}
insn[insn_idx].src_reg = BPF_PSEUDO_MAP_FD;
/* Match FD relocation against recorded map_data[] offset */
for (map_idx = 0; map_idx < nr_maps; map_idx++) {
if (maps[map_idx].elf_offset == sym.st_value) { /* 找到对应的 bpf_map 的 fd */
match = true;
break;
}
if (match) {
/*
* 修正 eBPF bpf_map 访问指令的 bpf_map 句柄。
* 如 sockex1_kern.c 中 对 mymap 的访问语句:
* value = bpf_map_lookup_elem(&my_map, &index);
* 必须将 &my_map 修正为对应内核 bfp_map 对象的指针。
* 这分为2步:
* 1. 用户空间程序 sockex1_user.c 在此处初步修正 mymap 访问指令:
* . bpf_insn::src_reg = BPF_PSEUDO_MAP_FD
* . bpf_insn::imm = fd (修正对 mymap 的访问为其对应 bpf_map 的 fd)
* 2. 在加载 eBPF 程序的系统调用 sys_bpf(BPF_PROG_LOAD, ...) 过程中
* sys_bpf(BPF_PROG_LOAD, ...)
* bpf_prog_load()
* bpf_check()
* replace_map_fd_with_map_ptr()
* 再将此处修正的 fd 修正为 bpf_map 对象的地址。
*/
insn[insn_idx].imm = maps[map_idx].fd;
} else {
printf("invalid relo for insn[%d] no map_data match\n",
insn_idx);
return 1;
}
}
}
}注意到,用户空间程序仅仅将对 bpf_map 的访问,修正为了对应 bpf_map 对象的句柄。直到后续将 eBPF 程序注入内核过程中,才最终将 bpf_map 的句柄修正为 bpf 对象地址,后面章节的会有细述。
6.2.1.3 eBPF 程序注入
main()
load_bpf_file()
do_load_bpf_file()
/* 解析创建 bpf_map */
load_elf_maps_section()
load_maps()
/* 修正 bpf_map 访问句柄 */
parse_relo_and_apply()
/* 注入、验证、修正、编译 所有的 eBPF 程序段 */
for (i = 1; i < ehdr.e_shnum; i++) {
...
if (get_sec(elf, i, &ehdr, &shname, &shdr, &data))
continue;
if (memcmp(shname, "kprobe/", 7) == 0 ||
memcmp(shname, "kretprobe/", 10) == 0 ||
memcmp(shname, "tracepoint/", 11) == 0 ||
memcmp(shname, "xdp", 3) == 0 ||
memcmp(shname, "perf_event", 10) == 0 ||
memcmp(shname, "socket", 6) == 0 || /* 如 sockex1_kern.c 中的 SEC("socket1") 段 */
memcmp(shname, "cgroup/", 7) == 0 ||
memcmp(shname, "sockops", 7) == 0 ||
memcmp(shname, "sk_skb", 6) == 0) {
ret = load_and_attach(shname, data->d_buf,
data->d_size);
if (ret != 0)
goto done;
}
}static int load_and_attach(const char *event,
struct bpf_insn *prog, int size)
{
bool is_socket = strncmp(event, "socket", 6) == 0;
...
if (is_socket) {
prog_type = BPF_PROG_TYPE_SOCKET_FILTER;
} else if (is_kprobe || is_kretprobe) {
...
} ...
else {
...
}
/*
* 为 eBPF 程序中的 @type 类型程序段(如 sockex1_kern.c 中的 SEC("socket1") 段):
* . 创建内核程序段对象 (bpf_prog),并将程序段指令 @insns 加载到该对象 ;
* . 设置程序段的验证接口,并通过验证接口验证程序合法性;
* . 设置程序段的解释执行接口。
* 返回指代内核 eBPF 程序段对象 (bpf_prog) 的匿名文件对象的句柄 fd 。
*/
fd = bpf_load_program(prog_type, prog, insns_cnt, license, kern_version,
bpf_log_buf, BPF_LOG_BUF_SIZE);
prog_fd[prog_cnt++] = fd;
...
if (is_socket || is_sockops || is_sk_skb) {
if (is_socket)
event += 6;
else
event += 7;
if (*event != '/')
return 0;
...
}
...
}
int bpf_load_program(enum bpf_prog_type type, const struct bpf_insn *insns,
size_t insns_cnt, const char *license,
__u32 kern_version, char *log_buf, size_t log_buf_sz)
{
int fd;
union bpf_attr attr;
bzero(&attr, sizeof(attr));
attr.prog_type = type; /* BPF_PROG_TYPE_SOCKET_FILTER */
...
fd = sys_bpf(BPF_PROG_LOAD, &attr, sizeof(attr));
if (fd >= 0 || !log_buf || !log_buf_sz)
return fd;
...
}进入内核空间:
/* kernel/bpf/syscall.c */
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
union bpf_attr attr = {};
int err;
...
if (copy_from_user(&attr, uattr, size) != 0)
return -EFAULT;
switch (cmd) {
...
case BPF_PROG_LOAD:
err = bpf_prog_load(&attr);
break;
...
}
return err;
}
static int bpf_prog_load(union bpf_attr *attr)
{
enum bpf_prog_type type = attr->prog_type;
struct bpf_prog *prog;
int err;
...
/* 为 eBPF 程序段分配空间(包括 bpf_prog_aux) */
prog = bpf_prog_alloc(bpf_prog_size(attr->insn_cnt), GFP_USER);
...
prog->len = attr->insn_cnt; /* 设置 eBPF 程序段指令数目 */
/* 将 eBPF 程序段中字节码指令 拷贝到 内核 eBPF 程序对象 bpf_prog 指令存储空间 */
err = -EFAULT;
if (copy_from_user(prog->insns, u64_to_user_ptr(attr->insns),
bpf_prog_insn_size(prog)) != 0)
goto free_prog;
/*
* 根据 eBPF 程序类型(@type):
* 设定 verifier ops, 设定 eBPF 程序 (@prog) 的类型
*/
err = find_prog_type(type, prog);
if (err < 0)
goto free_prog;
/*
* . 验证 eBPF 程序合法性
* . 修正 eBPF 程序中 bpf_map 访问指令中的 fd 为目标 bpf_map 的地址: (bpf_insn::imm)
* . 修正 eBPF 调用指令的目标函数地址
* ......
*/
err = bpf_check(&prog, attr);
...
/*
* 设定 eBPF 程序的解释器接口(bpf_prog::bpf_func):
* __bpf_prog_run##stack_size() -> ___bpf_prog_run()
* 调用硬件架构特定的 JIT 编译器接口 bpf_int_jit_compile()
* 编译 eBPF 字节码指令 编译为 本地硬件架构指令。
*/
prog = bpf_prog_select_runtime(prog, &err);
...
/* 为 eBPF 程序分配唯一 id */
err = bpf_prog_alloc_id(prog);
...
/* 创建 eBPF 程序的匿名文件对象: 为 eBPF 程序创建 {fd,file,inode} */
err = bpf_prog_new_fd(prog);
...
return err;
}eBPF 程序验证、bpf_map 访问地址修正、bpf_map 访问函数地址修正:
/* kernel/bpf/verifier.c */
/* 验证 eBPF 程序、bpf_map 访问地址修正、bpf_map 访问函数地址修正 */
int bpf_check(struct bpf_prog **prog, union bpf_attr *attr)
{
struct bpf_verifier_env *env;
int ret = -EINVAL;
env = kzalloc(sizeof(struct bpf_verifier_env), GFP_KERNEL);
env->insn_aux_data = vzalloc(sizeof(struct bpf_insn_aux_data) *
(*prog)->len);
...
env->prog = *prog;
...
/* bpf_map 访问地址修正: fd ==> bpf_map* */
ret = replace_map_fd_with_map_ptr(env);
...
ret = do_check(env); /* 程序验证 */
...
if (ret == 0)
ret = fixup_bpf_calls(env); /* bpf_map 访问函数地址修正 */
...
return ret;
}先看 bpf_map 访问地址的修正 工作,前面的章节 6.2.1.2 修正 eBPF 程序中 bpf_map 访问指令的句柄 中,已经修正了 bpf_map 访问的句柄,这里就是要 bpf_map 句柄最终修正为 bpf_map 对象地址。
/* kernel/bpf/verifier.c */
static int replace_map_fd_with_map_ptr(struct bpf_verifier_env *env)
{
...
for (i = 0; i < insn_cnt; i++, insn++) {
...
/*
* 此处摘自章节 6.1 中对 sockex1_kern.o 的反汇编代码片段:
* $ llvm-objdump-12 -d sockex1_kern.o
* 7: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
* 对应的代码语句为 sockex1_kern.c 中的:
* value = bpf_map_lookup_elem(&my_map, &index);
*
* 这里要将 &my_map 修正为其对应 bpf_map 对象的地址。
*/
if (insn[0].code == (BPF_LD | BPF_IMM | BPF_DW)) {
struct bpf_map *map;
struct fd f;
f = fdget(insn->imm); /* 找到 fd 对象 */
map = __bpf_map_get(f); /* 找到 bpf_map 对象 */
...
/* store map pointer inside BPF_LD_IMM64 instruction */
/* 将指令的数据访问地址修正为 bpf_map 对象地址 */
insn[0].imm = (u32) (unsigned long) map;
insn[1].imm = ((u64) (unsigned long) map) >> 32;
...
}
}
}再来看 bpf_map 访问接口(如 bpf_map_lookup_elem() 等)地址的修正 工作:
/*
* bpf_map 访问接口地址修正。
* 如 samples/bpf/sockex1_kern.c 中的 bpf_map_lookup_elem():
* value = bpf_map_lookup_elem(&my_map, &index);
*/
static int fixup_bpf_calls(struct bpf_verifier_env *env)
{
/* 重点关注对 sockex1_kern.c 中 bpf_map_lookup_elem() 调用的修正情形 */
for (i = 0; i < insn_cnt; i++, insn++) {
...
if (insn->code != (BPF_JMP | BPF_CALL))
continue;
...
patch_call_imm:
fn = prog->aux->ops->get_func_proto(insn->imm); /* 如 sk_filter_func_proto() */
/* 包括但不仅限于 对 bpf_map_lookup_elem() 调用指令目标函数地址的修正 */
insn->imm = fn->func - __bpf_call_base; /* insn->imm = bpf_map_lookup_elem - __bpf_call_base */
}
}/* net/core/filter.c */
static const struct bpf_func_proto *
sk_filter_func_proto(enum bpf_func_id func_id)
{
switch (func_id) {
case BPF_FUNC_skb_load_bytes:
return &bpf_skb_load_bytes_proto;
case BPF_FUNC_get_socket_cookie:
return &bpf_get_socket_cookie_proto;
case BPF_FUNC_get_socket_uid:
return &bpf_get_socket_uid_proto;
default:
return bpf_base_func_proto(func_id);
}
}
static const struct bpf_func_proto *
bpf_base_func_proto(enum bpf_func_id func_id)
{
switch (func_id) {
case BPF_FUNC_map_lookup_elem:
return &bpf_map_lookup_elem_proto;
...
}
}/* kernel/bpf/helpers.c */
const struct bpf_func_proto bpf_map_lookup_elem_proto = {
.func = bpf_map_lookup_elem,
.gpl_only = false,
.pkt_access = true,
.ret_type = RET_PTR_TO_MAP_VALUE_OR_NULL,
.arg1_type = ARG_CONST_MAP_PTR,
.arg2_type = ARG_PTR_TO_MAP_KEY,
};6.2.2 创建 eBPF 程序目标观察对象
尽管已经加载了 eBPF 内核程序,但是它该从哪里的采集观测数据呢?所以还需要为其创建一个被观察对象,并把它和被观察对象关联起来,然后从该对象采集观测数据。
在我们的例子中,被观察的对象是一个 socket ,来看它的创建流程:
int main(int ac, char **argv)
{
...
sock = open_raw_sock("lo");
...
}
static inline int open_raw_sock(const char *name)
{
struct sockaddr_ll sll;
int sock;
sock = socket(PF_PACKET, SOCK_RAW | SOCK_NONBLOCK | SOCK_CLOEXEC, htons(ETH_P_ALL));
...
memset(&sll, 0, sizeof(sll));
sll.sll_family = AF_PACKET;
sll.sll_ifindex = if_nametoindex(name);
sll.sll_protocol = htons(ETH_P_ALL);
if (bind(sock, (struct sockaddr *)&sll, sizeof(sll)) < 0) {
printf("bind to %s: %s\n", name, strerror(errno));
close(sock);
return -1;
}
return sock;
}sys_socket()
sock_create()
__sock_create()
pf->create() = packet_create()
struct sock *sk;
struct packet_sock *po;
__be16 proto = (__force __be16)protocol; /* weird, but documented */
sk = sk_alloc(net, PF_PACKET, GFP_KERNEL, &packet_proto, kern);
...
sock->ops = &packet_ops;
...
po = pkt_sk(sk);
sk->sk_family = PF_PACKET;
po->num = proto;
po->xmit = dev_queue_xmit; /* PF_PACKET 协议类型包发送接口 */
...
po->prot_hook.func = packet_rcv; /* PF_PACKET 协议类型包接收接口 */
...
if (proto) {
po->prot_hook.type = proto;
__register_prot_hook(sk);
dev_add_pack(&po->prot_hook)
}当然,被观察的对象不限于 socket 对象,还可以是 tracepoint, kretprobe, kprobe, perfevent 等等其它类型对象。
6.2.3 关联 eBPF 程序和其目标观察对象
被 eBPF 程序观察的 socket 对象已经创建了,但在能够读取被观察的 socket 对象的数据之前,我们还要将它们关联到一起。
/* net/socket.c */
SYSCALL_DEFINE5(setsockopt, int, fd, int, level, int, optname,
char __user *, optval, int, optlen)
{
struct socket *sock;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock != NULL) {
if (level == SOL_SOCKET)
err =
sock_setsockopt(sock, level, optname, optval,
optlen);
else
...
}
}/* net/core/sock.c */
int sock_setsockopt(struct socket *sock, int level, int optname,
char __user *optval, unsigned int optlen)
{
...
switch (optname) {
...
case SO_ATTACH_BPF:
ret = -EINVAL;
if (optlen == sizeof(u32)) {
u32 ufd;
ret = -EFAULT;
if (copy_from_user(&ufd, optval, sizeof(ufd)))
break;
ret = sk_attach_bpf(ufd, sk); /* 挂接 eBPF 内核程序到 sock */
}
break;
...
}
}/* net/core/filter.c */
int sk_attach_bpf(u32 ufd, struct sock *sk)
{
struct bpf_prog *prog = __get_bpf(ufd, sk); /* 获取 @ufd 对应的 bpf_prog */
int err;
...
err = __sk_attach_prog(prog, sk);
if (err < 0) {
bpf_prog_put(prog);
return err;
}
return 0;
}
static int __sk_attach_prog(struct bpf_prog *prog, struct sock *sk)
{
struct sk_filter *fp, *old_fp;
fp = kmalloc(sizeof(*fp), GFP_KERNEL);
...
fp->prog = prog; /* 设定 sock 过滤用的 bpf_prog */
...
rcu_assign_pointer(sk->sk_filter, fp);
...
return 0;
}6.2.4 eBPF 程序写观测数据到 bpf_map
在网络接口收到 ping 请求包时,将会从 socket 回送数据包给 ping 。在会送数据包的路径中,将会触发 sockex1_kern.c 中的 eBPF 代码片段 SEC("socket1"),并最终进入注入 eBPF 程序段时设置的解释执行接口 ___bpf_prog_run() ,执行 eBPF 程序段 SEC("socket1"):
/* 发送 */
sys_sendmsg()
__sys_sendmsg()
___sys_sendmsg()
sock_sendmsg()
sock_sendmsg_nosec(sock, msg)
sock->ops->sendmsg() = inet_sendmsg()
sk->sk_prot->sendmsg() = raw_sendmsg()
ip_push_pending_frames()
ip_send_skb()
ip_local_out()
__ip_local_out()
dst_output()
ip_output()
ip_finish_output()
ip_finish_output2()
neigh_output()
dev_queue_xmit()/* 接收: softirq */
net_rx_action()
napi_poll()
n->poll() = process_backlog()
__netif_receive_skb()
__netif_receive_skb_core()
...
packet_rcv()
run_filter()
bpf_prog_run_clear_cb()
BPF_PROG_RUN(prog, skb) = ___bpf_prog_run32()
___bpf_prog_run() /* 运行 eBPF 钩子程序 *//* kernel/bpf/core.c */
static unsigned int ___bpf_prog_run(u64 *regs, const struct bpf_insn *insn,
u64 *stack)
{
/* 细节详见章节 6.1 eBPF 程序 中 bpf_prog1() 的注释 */
...
/* CALL */
JMP_CALL:
/*
* samples/bpf/sockex1_kern.c:
* val = bpf_map_lookup_elem(&my_map, &index);
*/
BPF_R0 = (__bpf_call_base + insn->imm)(BPF_R1, BPF_R2, BPF_R3,
BPF_R4, BPF_R5);
CONT;
...
}6.2.5 读取 eBPF 程序写到 bpf_map 的数据
/* samples/bpf/sockex1_user.c */
main()
key = IPPROTO_TCP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &tcp_cnt) == 0);
key = IPPROTO_UDP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &udp_cnt) == 0);
key = IPPROTO_ICMP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &icmp_cnt) == 0);/* tools/lib/bpf/bpf.c */
int bpf_map_lookup_elem(int fd, const void *key, void *value)
{
union bpf_attr attr;
bzero(&attr, sizeof(attr));
attr.map_fd = fd;
attr.key = ptr_to_u64(key);
attr.value = ptr_to_u64(value);
return sys_bpf(BPF_MAP_LOOKUP_ELEM, &attr, sizeof(attr));
}接下来进入到内核空间:
/* kernel/bpf/syscall.c */
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
...
switch (cmd) {
...
case BPF_MAP_LOOKUP_ELEM:
err = map_lookup_elem(&attr);
break;
...
}
return err;
}
static int map_lookup_elem(union bpf_attr *attr)
{
void __user *ukey = u64_to_user_ptr(attr->key);
void __user *uvalue = u64_to_user_ptr(attr->value);
int ufd = attr->map_fd;
struct bpf_map *map;
void *key, *value, *ptr;
u32 value_size;
struct fd f;
int err;
f = fdget(ufd);
map = __bpf_map_get(f);
...
key = memdup_user(ukey, map->key_size);
...
value = kmalloc(value_size, GFP_USER | __GFP_NOWARN);
...
if (map->map_type == BPF_MAP_TYPE_PERCPU_HASH ||
...
} else if (map->map_type == BPF_MAP_TYPE_PERCPU_ARRAY) {
...
} else if (map->map_type == BPF_MAP_TYPE_STACK_TRACE) {
...
} else if (IS_FD_ARRAY(map)) {
...
} else if (IS_FD_HASH(map)) {
...
} else { /* BPF_MAP_TYPE_ARRAY, ... */
ptr = map->ops->map_lookup_elem(map, key); /* array_map_lookup_elem(), ... */
if (ptr)
memcpy(value, ptr, value_size); /* 读取 @key 指向的数据到 @value */
...
}
...
err = -EFAULT;
if (copy_to_user(uvalue, value, value_size) != 0) /* 将 attr->key 指向的数据,写到用户空间 attr->value */
goto free_value;
err = 0;
free_value:
kfree(value);
free_key:
kfree(key);
err_put:
fdput(f);
return err;
}7. eBPF 小结
上面程序代码和分析过程看起来很复杂,其实关键的操作也就只有下列3点:
map_fd = sys_bpf(BPF_MAP_CREATE, &attr, sizeof(attr)); /* 创建数据交互的 bpf_map */
prog_fd = sys_bpf(BPF_PROG_LOAD, &attr, sizeof(attr)); /* 注入 eBPF 字节码程序片段 */
bpf_map_lookup_elem(map_fd , &key, &value); /* 读取 bpf_map 数据 */上面很大一部分的复杂性来自对 ELF 二进制格式的解析过程。如果将 sockex1_kern.c 中的 eBPF 程序段 SEC("socket1") 直接硬编码为 eBPF 指令,那么整个程序可以简化为 这样 。
8. eBPF 实际应用方案
使用 CLANG/LLVM 方式,如果仅仅是作为学习研究,那是无所谓的。但如果作为注重效率和安全的生产环境,这种低效的方式显然是不合适的。为此,引入了 bcc 和 bpftrace 等方案。
来看一下 bcc 和 bpftrace 工具的框架图:
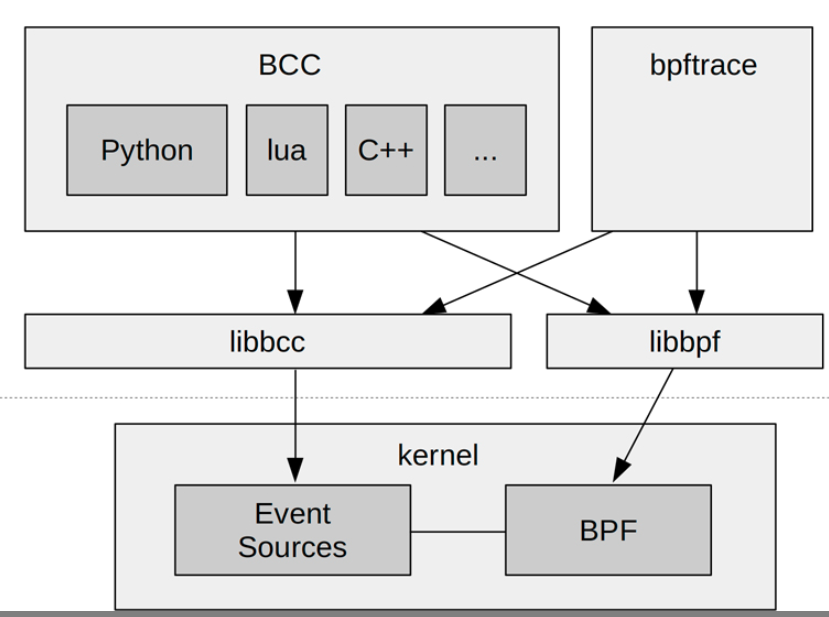
从上面的框架图我们了解到,不管使用什么样的 eBPF 前端,这些工具的工作原理都是相近的:向内核注入 eBPF 程序,挂接到目标观测对象,观测数据写入 bpf_map ,最终从 bpf_map 读取数据。
8.1 bcc
bcc 工具开源仓库: https://github.com/iovisor/bcc。
更多 bcc 工具的使用方法可参考仓库文档。
8.2 bpftrace
bpftrace 工具开源仓库: https://github.com/iovisor/bpftrace。
更多 bpftrace 工具的使用方法请参考仓库文档。
9. 参考资料
《ELF V1.2.pdf》
《BPF PerformanceTools》,Brendan Gregg
https://github.com/iovisor














 1107
1107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









