







 超级会员免费看
超级会员免费看
in-context 作为随着大模型涌现的范式,被大规模的应用到各种知识库问答、资料汇总等领域中,开源社区对 in-context 也非常活跃地响应,推出了 langchain [3]、向量数据库 [4] 等系列优秀框架与技术基座。但是,基于 langchain + 开源大模型在实践过程中也会遇到系列不尽人意的问题,本文将深入剖析 langchain + 开源大模型用于搭建基于公司语料库(iwiki、oncall、码客)上的缺陷,剖析利用开源方案进行实践过程中性能下降的根本原因。
常规方案
架构
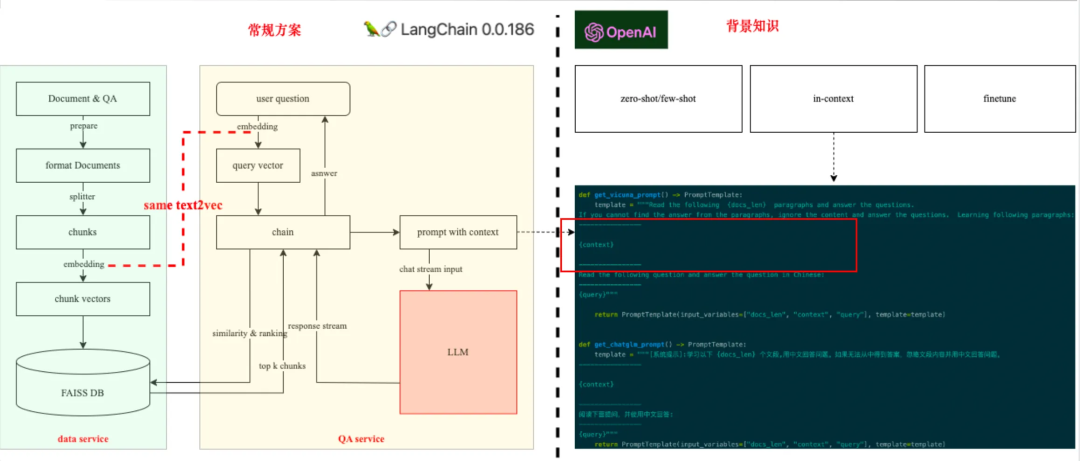
基于 langchain + 大模型 in-context 能力来搭建智能问答系统的常规方案如上图所示,包含 3 个核心模块:数据服务,在线 QA 服务,以及大模型。下面分别详细说明一下各个模块具体做些什么?他们是如何串联在一起完成整个问答任务的?再反过来看看为什么业界基于 openAI 实践很棒,而如果换成基于开源自研后性能下滑很多?
数据服务
数据对方案的性能影响极其重要,高质量的数据对模型的提升非常显著;但数据处

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 1259
1259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











