






目录
10.4.3 Azkaban多Executor模式下注意事项
十:全流程调度
10.1 Azkaban部署
这里就不部署了,可以参考我的其他文章,里面有专门的讲azkaban的部署。
10.2 创建MySQL数据库和表
1)创建gmall_report数据库
2)创建表(就是ADS层的12张表,这里建表时,要和ADS层表的字段要一一对应)
建表语句由于篇幅原因,这里就不展示了。
10.3 Sqoop导出脚本
1)编写Sqoop导出脚本
在/home/atguigu/bin目录下创建脚本hdfs_to_mysql.sh
[axing@hadoop102 bin]$ vim hdfs_to_mysql.sh在脚本中填写如下内容
#!/bin/bash
hive_db_name=gmall
mysql_db_name=gmall_report
export_data() {
/opt/module/sqoop/bin/sqoop export \
--connect "jdbc:mysql://hadoop102:3306/${mysql_db_name}?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 000000 \
--table $1 \
--num-mappers 1 \
--export-dir /warehouse/$hive_db_name/ads/$1 \
--input-fields-terminated-by "\t" \
--update-mode allowinsert \
--update-key $2 \
--input-null-string '\\N' \
--input-null-non-string '\\N'
}
case $1 in
"ads_activity_stats" )
export_data "ads_activity_stats" "dt,activity_id"
;;
"ads_coupon_stats" )
export_data "ads_coupon_stats" "dt,coupon_id"
;;
"ads_order_by_province" )
export_data "ads_order_by_province" "dt,recent_days,province_id"
;;
"ads_order_spu_stats" )
export_data "ads_order_spu_stats" "dt,recent_days,spu_id"
;;
"ads_order_total" )
export_data "ads_order_total" "dt,recent_days"
;;
"ads_page_path" )
export_data "ads_page_path" "dt,recent_days,source,target"
;;
"ads_repeat_purchase" )
export_data "ads_repeat_purchase" "dt,recent_days,tm_id"
;;
"ads_user_action" )
export_data "ads_user_action" "dt,recent_days"
;;
"ads_user_change" )
export_data "ads_user_change" "dt"
;;
"ads_user_retention" )
export_data "ads_user_retention" "create_date,retention_day"
;;
"ads_user_total" )
export_data "ads_user_total" "dt,recent_days"
;;
"ads_visit_stats" )
export_data "ads_visit_stats" "dt,recent_days,is_new,channel"
;;
"all" )
export_data "ads_activity_stats" "dt,activity_id"
export_data "ads_coupon_stats" "dt,coupon_id"
export_data "ads_order_by_province" "dt,recent_days,province_id"
export_data "ads_order_spu_stats" "dt,recent_days,spu_id"
export_data "ads_order_total" "dt,recent_days"
export_data "ads_page_path" "dt,recent_days,source,target"
export_data "ads_repeat_purchase" "dt,recent_days,tm_id"
export_data "ads_user_action" "dt,recent_days"
export_data "ads_user_change" "dt"
export_data "ads_user_retention" "create_date,retention_day"
export_data "ads_user_total" "dt,recent_days"
export_data "ads_visit_stats" "dt,recent_days,is_new,channel"
;;
esac关于导出update还是insert的问题?
- --update-mode:
updateonly 只更新,无法插入新数据
allowinsert 允许新增
- --update-key:允许更新的情况下,指定哪些字段匹配视为同一条数据,进行更新而不增加。多个字段用逗号分隔。
- --input-null-string和--input-null-non-string:
分别表示,将字符串列和非字符串列的空串和“null”转义
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
2)执行Sqoop导出脚本
[axing@hadoop102 bin]$ chmod 777 hdfs_to_mysql.sh
[axing@hadoop102 bin]$ hdfs_to_mysql.sh all10.4 全调度流程
10.4.1 数据准备
1)用户行为数据准备
(1)修改/opt/module/applog下的application.properties
#业务日期
mock.date=2020-06-15注意:hadoop102和hadoop103都有采集flume,所以也要在hadoop103中执行相同命令。
(2)生成数据
[axing@hadoop102 bin]$ lg.sh注意:生成数据之后,记得查看HDFS数据是否存在!
(3)观察HDFS的/origin_data/gmall/log/topic_log/2020-06-15路径是否有数据
2)业务数据准备
(1)修改/opt/module/db_log下的application.properties
[axing@hadoop102 db_log]$ vim application.properties
#业务日期
mock.date=2020-06-15(2)生成数据
[axing@hadoop102 db_log]$ java -jar gmall2020-mock-db-2020-04-01.jar(3)观察Navicat中order_infor表中operate_time中有2020-06-15日期的数据
10.4.2 编写Azkaban工作流程配置文件
1)编写azkaban.project文件,内容如下
azkaban-flow-version: 2.02)编写gmall.flow文件,内容如下
nodes:
- name: mysql_to_hdfs
type: command
config:
command: /home/atguigu/bin/mysql_to_hdfs.sh all ${dt}
- name: hdfs_to_ods_log
type: command
config:
command: /home/atguigu/bin/hdfs_to_ods_log.sh ${dt}
- name: hdfs_to_ods_db
type: command
dependsOn:
- mysql_to_hdfs
config:
command: /home/atguigu/bin/hdfs_to_ods_db.sh all ${dt}
- name: ods_to_dim_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dim_db.sh all ${dt}
- name: ods_to_dwd_log
type: command
dependsOn:
- hdfs_to_ods_log
config:
command: /home/atguigu/bin/ods_to_dwd_log.sh all ${dt}
- name: ods_to_dwd_db
type: command
dependsOn:
- hdfs_to_ods_db
config:
command: /home/atguigu/bin/ods_to_dwd_db.sh all ${dt}
- name: dwd_to_dws
type: command
dependsOn:
- ods_to_dim_db
- ods_to_dwd_log
- ods_to_dwd_db
config:
command: /home/atguigu/bin/dwd_to_dws.sh all ${dt}
- name: dws_to_dwt
type: command
dependsOn:
- dwd_to_dws
config:
command: /home/atguigu/bin/dws_to_dwt.sh all ${dt}
- name: dwt_to_ads
type: command
dependsOn:
- dws_to_dwt
config:
command: /home/atguigu/bin/dwt_to_ads.sh all ${dt}
- name: hdfs_to_mysql
type: command
dependsOn:
- dwt_to_ads
config:
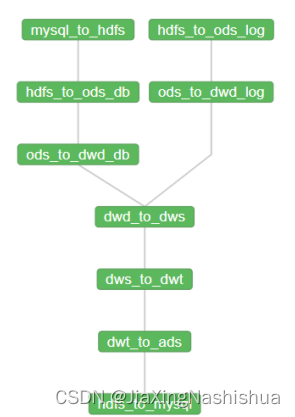
command: /home/atguigu/bin/hdfs_to_mysql.sh all注意:要检查一下每个任务点之间的依赖关系,不能出错。
3)将azkaban.project、gmall.flow文件压缩到一个zip文件,文件名称必须是英文。
4)在WebServer新建项目:http://hadoop102:8081/index
5)给项目名称命名和添加项目描述
6)gmall.zip文件上传
7)选择上传的文件
8)查看任务流
9)详细任务流展示
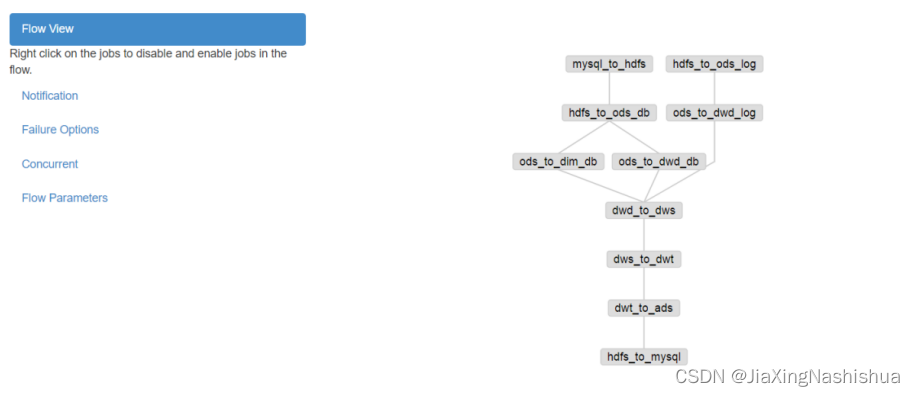
10)配置输入dt时间参数
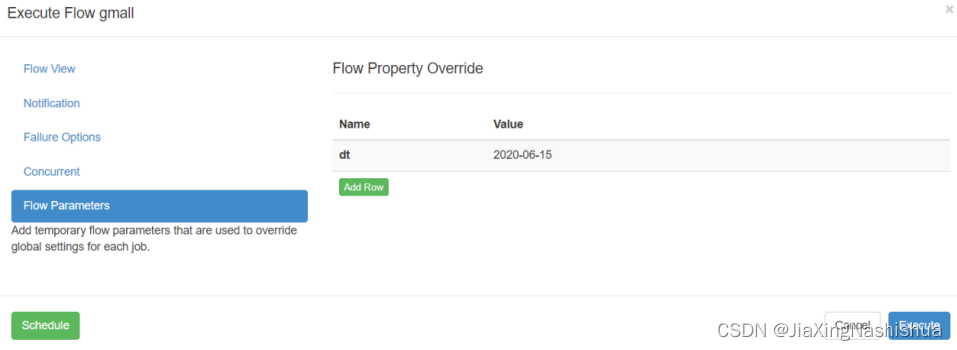
注意:
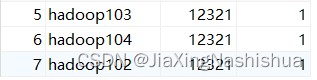
因为脚本都存放于hadoop102中,但是,hadoop102、hadoop103、hadoop104都有azkaban-exec,因此,我们要声明这些脚本在hadoop102中。这时候,除了增加dt,我们还要增加一个变量,变量名为useExecutor,值为hadoop102的主键id,我们可以打开azkaban数据库中,查看executors表,查看hadoop102的主键id ,这里,我的值为7。
10)执行成功
11)在Navicat上查看结果
10.4.3 Azkaban多Executor模式下注意事项
Azkaban多Executor模式是指,在集群中多个节点部署Executor。在这种模式下, Azkaban web Server会根据策略,选取其中一个Executor去执行任务。
由于我们需要交给Azkaban调度的脚本,以及脚本需要的Hive,Sqoop等应用只在hadoop102部署了,为保证任务顺利执行,我们须在以下两种方案任选其一,推荐使用方案二。
方案一:指定特定的Executor(hadoop102)去执行任务。
1)在MySQL中azkaban数据库executors表中,查询hadoop102上的Executor的id。
mysql> use azkaban;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from executors;
+----+-----------+-------+--------+
| id | host | port | active |
+----+-----------+-------+--------+
| 1 | hadoop103 | 35985 | 1 |
| 2 | hadoop104 | 36363 | 1 |
| 3 | hadoop102 | 12321 | 1 |
+----+-----------+-------+--------+
3 rows in set (0.00 sec)2)在执行工作流程时加入useExecutor属性,如下
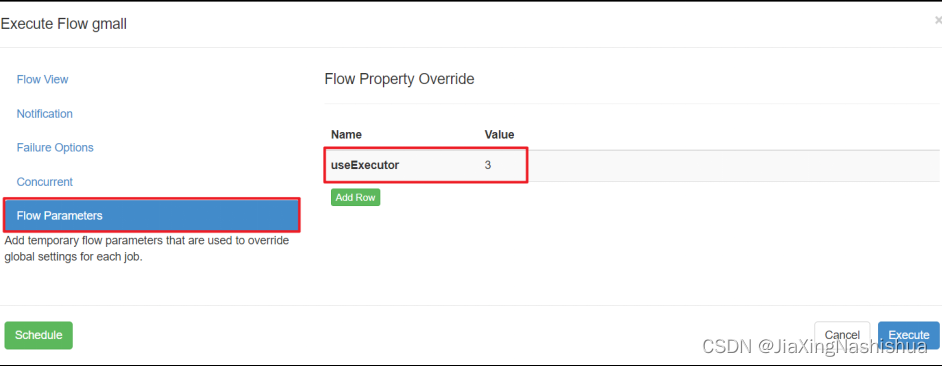
方案二:在Executor所在所有节点部署任务所需脚本和应用。
1)分发脚本、sqoop、spark、my_env.sh
[axing@hadoop102 ~]$ xsync /home/atguigu/bin/
[axing@hadoop102 ~]$ xsync /opt/module/hive
[axing@hadoop102 ~]$ xsync /opt/module/sqoop
[axing@hadoop102 ~]$ xsync /opt/module/spark
[axing@hadoop102 ~]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh2)分发之后,在hadoop103,hadoop104重新加载环境变量配置文件,并重启Azkaban。















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









