






Location Beijing
过拟合
对于一个模型
A
A
A,解向量空间为
θ
\theta
θ,误差函数用式1表示
J
(
θ
)
=
J
a
c
c
=
[
y
θ
(
x
)
−
y
]
2
(1)
J(\theta)=J_{acc}=[y_\theta(x)-y]^2\tag{1}
J(θ)=Jacc=[yθ(x)−y]2(1)
首先我们考虑用模型
A
A
A拟合下图Fig. 1这些点(数据集)

首先用一个模型去拟合这个曲线
y
=
a
+
b
x
+
c
x
2
+
d
x
3
y=a+bx+cx^2+dx^3
y=a+bx+cx2+dx3,可得如下图Fig. 2
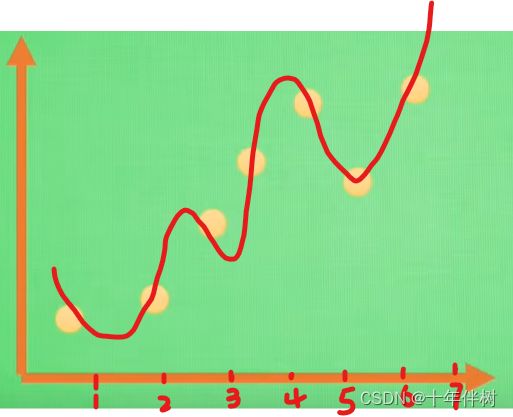
简直完美,因为误差
J
(
θ
)
J(\theta)
J(θ)=0。然而当我预测
x
=
4
x=4
x=4的函数值时,发现预测值比真实值稍微大一丢丢,虽然感觉不对劲但是还可以接受;但当我预测
x
=
20
x=20
x=20的函数值时,发现预测值大的离谱。
具体原因可以从上图Fig. 2看出,模型认为数据集中的点所有
x
x
x及其对应的
y
y
y都是百分百对应的,过分相信了数据集的准确性,忽略了数据集的误差。实际上可以看出,比如上图Fig. 2数据集中的
x
=
2
x=2
x=2的点对应的函数值大概是
y
=
2
y=2
y=2,然而数据集却把这一项标注成了
y
=
1
y=1
y=1。模型A太厉害直接把带误差的数据集学透了。
这里也可以看出为什么说过拟合的表现是
J
(
θ
)
J(\theta)
J(θ)很小,但是预测新数据的能力很差,因为过拟合的模型太复杂,另外数据集标注太烂。
正则化
接下来看用正则化解决这个问题。
具体方法式在
J
(
θ
)
J(\theta)
J(θ)后面加一个正则化项,对于加入L1正则化的误差函数如公式2,加入L2正则化项的误差函数如公式3
J
L
1
(
θ
)
=
J
a
c
c
+
L
1
=
[
y
θ
(
x
)
−
y
]
2
+
[
∣
θ
1
∣
+
∣
θ
2
∣
.
.
]
(2)
J_{L1}(\theta)=J_{acc}+L_1=[y_\theta(x)-y]^2+[|\theta_1|+|\theta_2|..]\tag{2}
JL1(θ)=Jacc+L1=[yθ(x)−y]2+[∣θ1∣+∣θ2∣..](2)
J
L
2
(
θ
)
=
J
a
c
c
+
L
2
=
[
y
θ
(
x
)
−
y
]
2
+
[
θ
1
2
+
θ
2
2
+
.
.
]
(3)
J_{L2}(\theta)=J_{acc}+L_2=[y_\theta(x)-y]^2+[\theta_1^2+\theta_2^2+..]\tag{3}
JL2(θ)=Jacc+L2=[yθ(x)−y]2+[θ12+θ22+..](3)
从公式2、3可以看出所谓正则化就是想以“牺牲”一些准确率的代价,来避免模型的复杂度。这里“牺牲”加引号的原因可以从第一章看出,这点损失的“准确率”事实上是象征着数据集的不准确性。让模型更有泛化能力。
至于为什么说L1正则化更容易得到稀疏的向量解空间,可以通过图Fig. 3看出,假设
θ
\theta
θ是一个二维向量,包含两个元素{
θ
1
\theta_1
θ1,
θ
2
\theta_2
θ2}。(一个模型肯定不止两个参数,这里举两个参数的例子是比较好画)
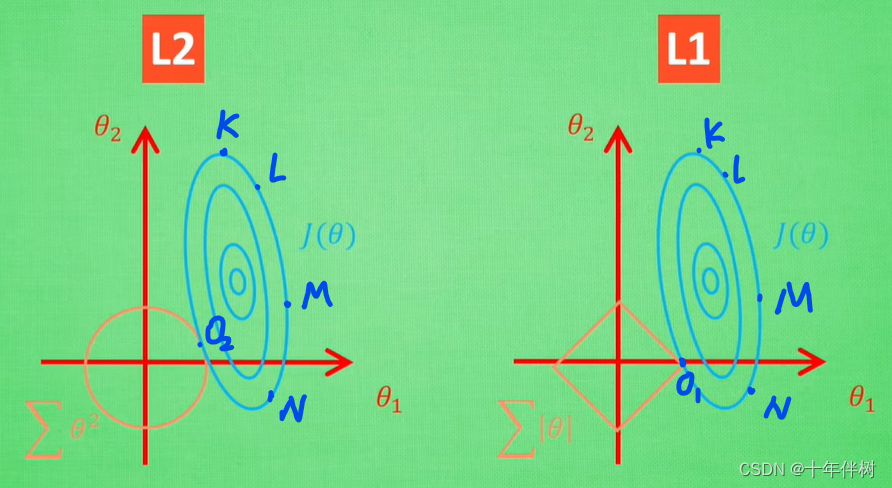
图Fig. 3中每个蓝色椭圆上的点表示不同的
θ
\theta
θ使
J
(
θ
)
J(\theta)
J(θ)(注意不是
J
a
c
c
(
θ
)
J_{acc}(\theta)
Jacc(θ))相同的点。如点
K
K
K,
L
L
L,
M
M
M,
N
N
N,
O
2
O_2
O2是解空间
θ
\theta
θ使含L2正则化项的误差函数
J
L
2
(
θ
)
J_{L2}(\theta)
JL2(θ)相同的点,这一批点中显然点
O
2
O_2
O2的L2正则化项最小;再比如点
K
K
K,
L
L
L,
M
M
M,
N
N
N,
O
1
O_1
O1是解空间
θ
\theta
θ使含L1正则化项的误差函数
J
L
1
(
θ
)
J_{L1}(\theta)
JL1(θ)相同的点,这一批点中显然点
O
1
O_1
O1的L1正则化项最小。(从公式2、3可以看出,相同的
J
(
θ
)
J(\theta)
J(θ),正则化项越小,
J
a
c
c
(
θ
)
J_{acc}(\theta)
Jacc(θ)越大,所以尽量保留正则化较小的
θ
\theta
θ解)
从这里可以看出L1正则化更容易使正则化项最小的同时,
J
a
c
c
(
θ
)
J_{acc}(\theta)
Jacc(θ)最大,而且还带来了一个效果,由于L1正则化尖尖的探出的部分,更容易使
θ
\theta
θ中的某一项为0,这就造成了L1正则化解空间的稀疏性。如果还想更稳妥,把这个正则化项改成非凸函数,特定情况下在成稀疏性的概率更大。
reference
[1] 莫烦Python 2017 什么是 L1 L2 正规化 正则化 Regularization (深度学习 deep learning)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









