






- 实验目的:
- 掌握定量数据的描述性统计分析中常用的指标
- 集中趋势:众数、中位数median()、四分位数、百分位数quantile()、(加权)平均数(weigthted.)mean()
- 分散程度:极差range()、半极差、方差var()、标准差sd()、变异系数、标准误
- 分布形态:偏度系数、峰度系数
- 掌握R语言绘直方图、茎叶图和箱线图的方法。
实验内容:
以前在做实验2的练习时,我们画过直方图。当时的题目是这样的:
利用hist()函数画直方图。
X<-c(35,40,40,42,37,45,43,37,44,42,41,39)
hist(X)这次实验先重新运行以上命令后,接着运行以下命令绘出第二幅直方图:
hist(X, freq=F)如果在RStudio中运行,第二幅图不会覆盖前一幅图,可以通过界面中的箭头按钮图标找到之前绘制的图;但如果在R中绘制第二幅图,会覆盖前一幅图,这时可以在绘制第二幅图时在R中先运行windows(),此命令是新开一个画图窗口,然后再绘制第二幅图。
把两个图分别截下复制到下面,进行比较,你发现有什么不同?
第一幅图纵坐标表示的是频数
第二幅图纵坐标表示的是密度
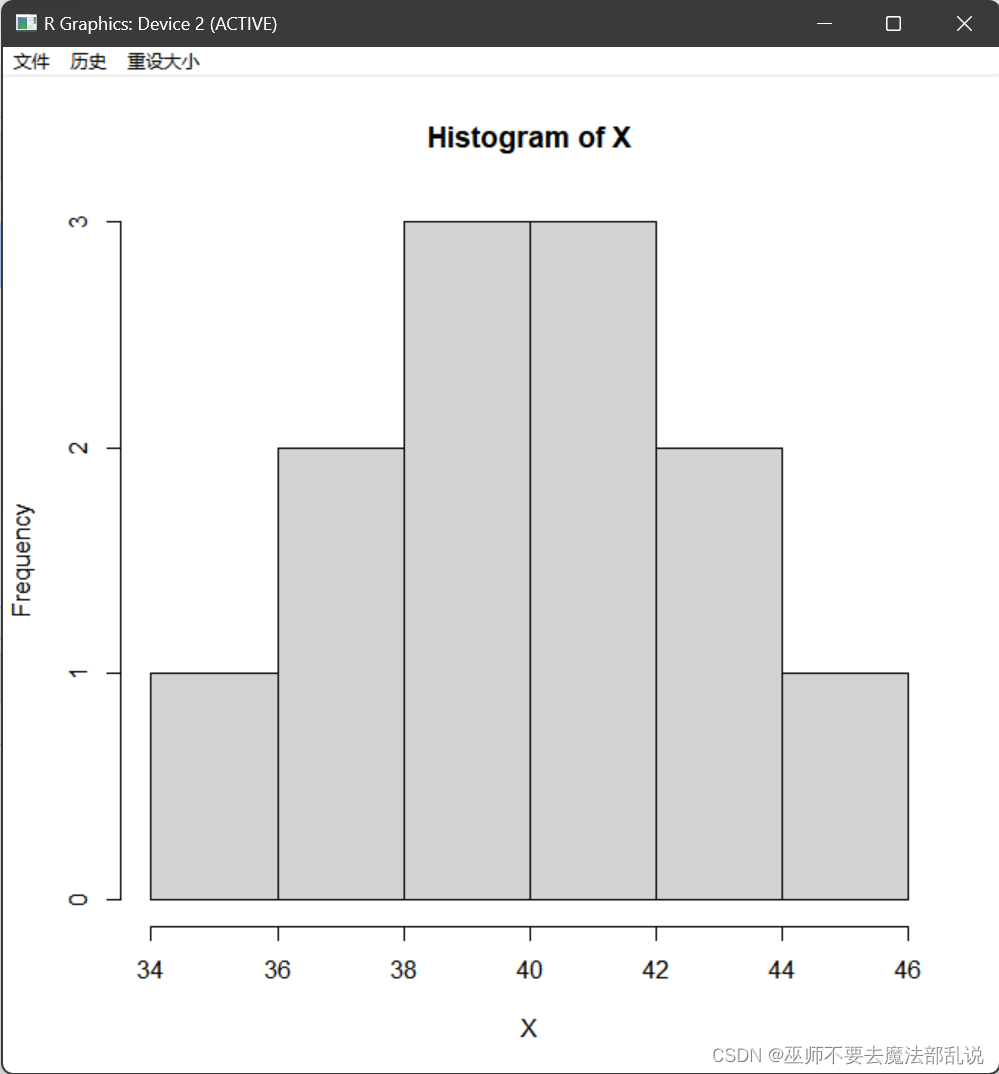

如果想把这两幅图画在同一个画图窗口中,可以输入以下命令:
par(mfrow=c(1,2)) #在一个窗口里放多张图,这里是1行2列共2个图
hist(X)
hist(X,freq=F)运行结果或截图:
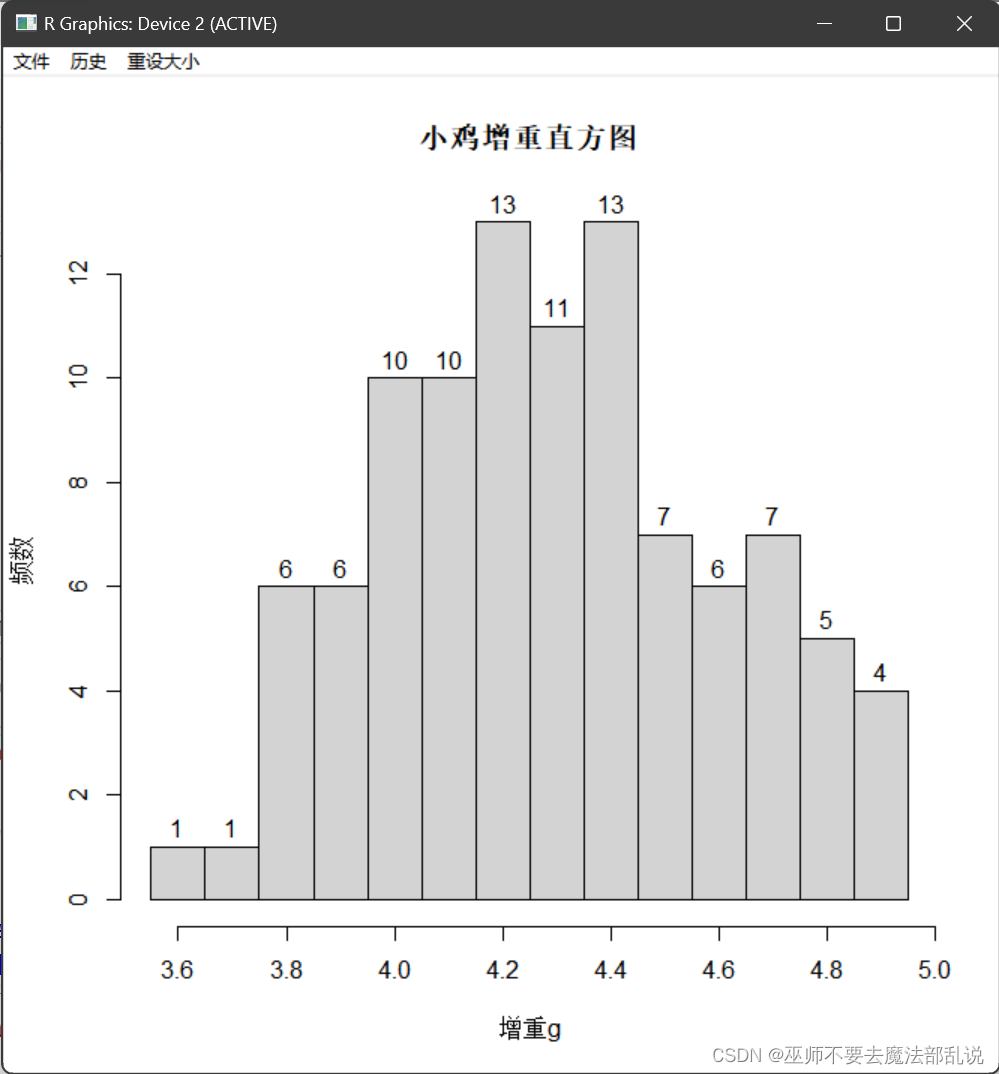
(习题3.7)画出习题3.3中小鸡增重的直方图 (1) 小区间的宽度为 0.lg,起点为 3.55g,终点为4.95g。纵坐标是频数,并将频数标在直方图的上方(类似图 3.6(a)); (2) 将(1)中直方图的纵坐标改为频率,并将数据的概率密度曲线和正态分布密度曲线同时画在直方图上(类似图 3.6(b))。(数据文件是cock.data)
(1)源代码:
# 读取数据
data <- scan("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/cock.data")
# 输出结果
hist(data,labels = TRUE,
breaks = seq(3.55,4.95,by = 0.1),
main = "小鸡增重直方图",
xlab = "增重g",
ylab = "频数")运行结果或截图:
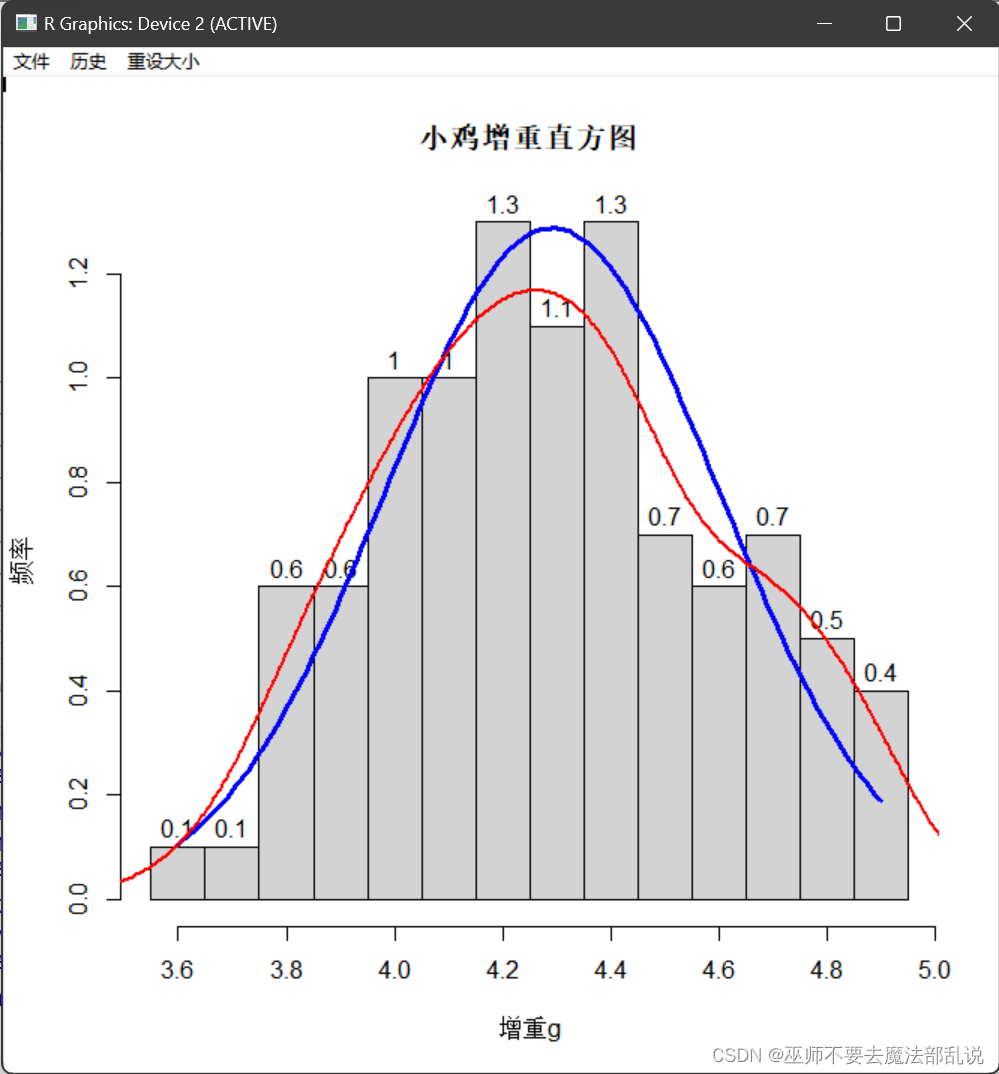
(2)源代码:
# 读取数据
data <- scan("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/cock.data")
# 计算各个区间的频数和频率
freq <- table(cut(data, breaks = seq(3.55, 4.95, by = 0.1)))
prop.freq <- prop.table(freq)
# 计算均值和标准差
mean_data <- mean(data)
sd_data <- sd(data)
# 计算数据的最小值和最大值
min_data <- min(data)
max_data <- max(data)
# 计算正态分布密度曲线的x轴和y轴
x <- seq(min_data, max_data, length = 100)
y <- dnorm(x, mean = mean_data, sd = sd_data)
# 输出结果
hist(data,freq = FALSE,
labels = TRUE,
breaks = seq(3.55,4.95,by = 0.1),
main = "小鸡增重直方图",
xlab = "增重g",
ylab = "频率")
lines(x, y, col = "blue", lwd = 3)
lines(density(data), col = "red", lwd = 2)运行结果或截图:
(习题3.11)计算习题3.3中小鸡增重数据的中位数、算术平均数,以及上四分位数和下四分数。
源代码:
# 读取数据
data <- scan("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/cock.data")
# 计算中位数、算术平均数、上四分位、下四分位数
median(data,na.rm = FALSE)
mean(data,trim = 0,na.rm = FALSE)
quantile(data,probs = 0.25,
na.rm = FALSE)
quantile(data,probs = 0.75,
na.rm = FALSE)运行结果或截图:

(习题3.16)计算习题3.3中小鸡增重数据的极差、四分位差、方差和标准差。
源代码:
# 读取数据
data <- scan("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/cock.data")
# 计算极差、四分位差、方差、标准差
R<-range(data)
R[2] - R[1]
Q<-quantile(data,p = c(0.25,0.75))
IQR <-Q[2] - Q[1]
IQR
var(data);sd(data)运行结果或截图:

(习题3.18)计算习题3.3中小鸡增重数据的偏度系数和峰度系数。结合习题3.7中的直方图,理解偏度系数和峰度系数的意义。
源代码:
# 读取数据
data <- scan("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/cock.data")
# 计算偏度系数、峰度系数
source("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/skew.R")
skew(data)
source("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/kurt.R")
kurt(data)
运行结果或截图:
(习题3.9)计算习题 3.1中饮料数据的众数。
源代码:
# 读取数据
data <- scan("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/drink.data",
what = list(顾客性别 = "",饮料类型 = ""))
# 计算众数
which.max(table(data$饮料类型))
max(table(data$饮料类型))运行结果或截图:

(习题3.13)2015 年某大学经济管理学院共有学生 500 名,其中 18 岁的学生 110 名,19 岁的学生110 名,20 岁的学生 100 名,21 岁的学生 90 名,22 岁的学生 90 名。计算该学院学生的平均年龄。
源代码:
# 建立数据
num<-c(110,110,100,90,90)
age<-c(18,19,20,21,22)
# 计算平均年龄
平均年龄<-sum(num*age)/sum(num)
print(平均年龄)运行结果或截图:

(习题3.14)有一项为期 10 年的抵押贷款(按复利计算),其中第1年的利率为 5% ,第2年为 7% ,第3 年为 9%,第4年为 11%,第5年为 13% ,第6 ~ 第10 年为 15%,试计算此贷款的年均利率。
源代码:
source("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/exa_0314.R")
X<-c(5,7,9,11,13,15,15,15,15,15)/100
m<-mean(log(1+X))
X_bar<-exp(m)
X_bar运行结果或截图:

(习题3.15)假设在过去的 3个月,猪肉价格在 16.8元/500g ~ 20.4元/500g 之间变化。某学校食堂在这 3个月中共购买了 5次猪肉,其价格与购买金额如下表所示。计算该食堂购买猪肉的平均价格。
三个月内的猪肉价格和购买金额
| 购买 批次 | 价格 (元/500g) | 购买金 额(元) | 购买 批次 | 价格 (元/500g) | 购买金 额(元) |
| 1 | 18.0 | 21600 | 4 | 17.4 | 17400 |
| 2 | 20.4 | 10200 | 5 | 19.5 | 15600 |
| 3 | 16.8 | 46200 |
源代码:
source("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/exa_0315.R")
x<-c(18.0,20.4,16.8,17.4,19.5)
f<-c(216,102,462,174,156)*100
(x_bar<-1/weighted.mean(1/x,w=f))运行结果或截图:

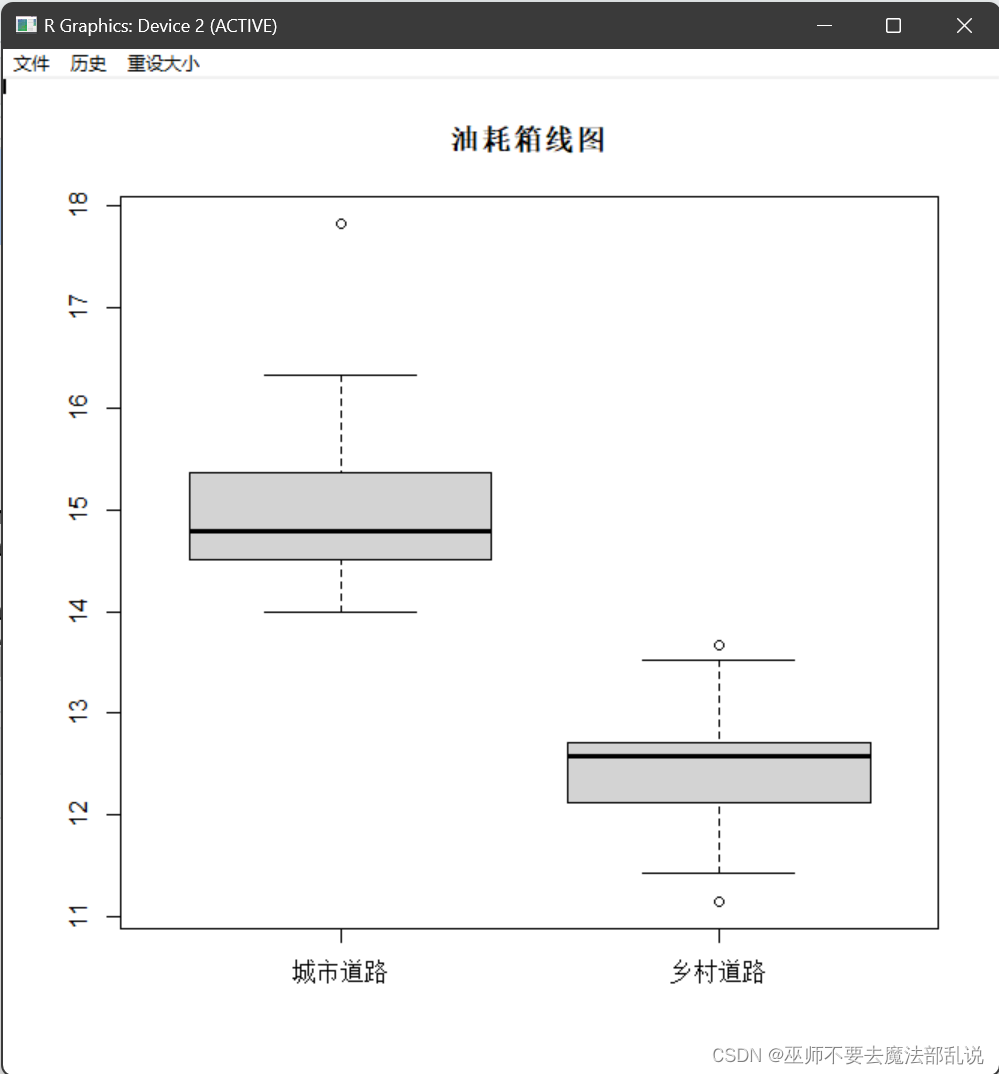
(习题3.22)在汽车的汽油时数和汽车油耗的测试中, 13 辆汽车分别在城市和乡村行驶 500km的路况下接受了检测,下表中的数据(存放在 car.data 文件中)记录了它们每百千米的耗油量。(1) 运用均值、中位数和百分位数来评价在城市和乡村路况下汽车性能的差别;(2) 画出两组数据的箱线图,比较不同路况下汽车性能是否有差别。
两种道路状况百公里耗油量(单位:L)
| 城市道路 | 乡村道路 | 城市道路 | 乡村道路 | ||
| 1 | 14.52 | 12.12 | 8 | 14.70 | 12.65 |
| 2 | 14.08 | 11.42 | 9 | 14.61 | 12.38 |
| 3 | 14.79 | 12.85 | 10 | 15.37 | 11.15 |
| 4 | 16.33 | 12.65 | 11 | 15.47 | 12.12 |
| 5 | 17.82 | 12.25 | 12 | 15.37 | 12.71 |
| 6 | 15.37 | 13.52 | 13 | 14.52 | 12.58 |
| 7 | 14.00 | 13.67 |
(1)源代码:
#读取数据
data<-read.table("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/car.data")
#计算均值、中位数和百分位数
city_mean<-mean(data$城市道路)
village_mean<-mean(data$乡村道路)
city_median<-median(data$城市道路)
village_median<-median(data$乡村道路)
city_quantile<-quantile(data$城市道路,probs = 1,na.rm = FALSE)
village_quantile<-quantile(data$乡村道路,probs = 1,na.rm = FALSE)
result<-c(城市均值 = city_mean,乡道均值 = village_mean,
城市中位数 = city_median,乡村中位数 = village_median,
城市百分数 = city_quantile,乡村百分位数 = village_quantile)
print(result)运行结果或截图:
城市油耗高于乡道油耗

(2)源代码:
#读取数据
data<-read.table("C:/Users/黄培滇/Desktop/R语言生物统计学/chap03/car.data")
#绘制箱线图
boxplot(data,main = "油耗箱线图")运行结果或截图:
思考:
描述定量数据集中趋势的指标主要有?
均值、中位数、众数
描述定量数据分散程度的指标主要有?
极差、方差、标准差
描述定量数据分布形态的指标主要有?
偏度、峰度
直方图和条图有什么区别?各适用于哪种数据?
直方图用于展示连续型变量的频数分布,横轴表示变量取值的范围,纵轴表示频数或频率。条图则适用于展示离散型变量的频数或频率,横轴表示不同的类别,纵轴表示频数或频率。
stem()函数画出的茎叶图,其本质是图吗?
本质是一种(统计)图形
上、下四分位数之间(即半极差)的数,占所有数据的百分之几?
25%
偏度系数大于0,说明其密度函数图形的尾部相对于正态分布偏左还是偏右?峰度系数大于0,说明其密度函数图形相对于正态分布更尖峭还是更平缓?
偏度系数大于0说明密度函数图形的尾部相对于正态分布偏左;峰度系数大于0说明密度函数图形相对于正态分布更尖峭
箱线图中,盒子的上、下连线分别代表什么?盒子中间的线代表什么?由“触须”延长的下、下边缘线的值分别为多少?
盒子的上、下连线代表数据集的上四分位数(Q3)和下四分位数(Q1);盒子中间的线代表数据集的中位数(Q2);由“触须”延长的下、下边缘线的值分别为最小非异常值和最大非异常值
在R中,如果想在一个输出窗口里放2行3列共6张图,需要运行什么命令?
Par(mfrow = c(2,3))















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









