







JAVA基础面试题
- 一、Java基础
- 1.Java的特点
- 2.Java 与 C++ 的区别
- 3.面向对象和面向过程的区别?
- 4.JKD和JRE的区别?
- 5.面向对象有哪些特性
- 6.Java的基本数据类型有哪些?
- 7.什么是值传递和引用传递?
- 8.了解Java的包装类型吗?为什么需要包装类?
- 9.String 为什么不可变?
- 10.String, StringBuffer 和 StringBuilder区别
- 11.String 类的常用方法有哪些?
- 12.new String("hello")会创建几个对象?
- 13.什么是字符串常量池?
- 14.Object常用方法有哪些?
- 15.两个对象的hashCode()相同,则 equals()是否也一定为 true?
- 16.Java创建对象有几种方式?
- 17.说说类实例化的顺序
- 18.equals和==有什么区别?
- 19.常见的关键字有哪些?
- 20.final, finally, finalize 的区别
- 21.Java不支持多继承的原因:
- 22.如何实现对象克隆?
- 23.深拷贝和浅拷贝的概念(需个人挖深)
- 23.重载和重写的区别
- 24.接口和抽象类的区别
- 25.什么时候使用抽象类,什么时候使用接口
- 26.java中为什么不允许静态方法里访问非静态变量
- 27.静态代理和动态代理的区别,什么场景使用(京东面)
- 二、内部类
- 三、异常
- 四、IO流
- 1、I/O 流的分类
- 2、字节流如何转为字符流
- 3、System.out.println 是什么
- 4、什么是 Filter 流
- 5、有哪些可用的 Filter 流
- 6、有哪些 Filter 流的子类
- 7、NIO 和 I/O 的主要区别
- 8、BIO、NIO、AIO 有什么区别?
- 9、NIO 有哪些核心组件?
- 10、IO 密集=Ncpu*2 是怎么计算出来(美团面)
- 11、select、poll、epoll 区别有哪些(百度面)?
- 12、如何实现对象克隆?
- 13、什么是缓冲区?有什么作用?
- 14、什么是阻塞 IO?什么是非阻塞 IO?
- 15、请说一下 PrintStream BufferedWriter PrintWriter 有什么不同?
- 五、反射
- 六、1.8新特性
一、Java基础
1.Java的特点
Java是一门面向对象的编程语言。
Java具有平台独立性和移植性。
Java有一句口号:Write once, run anywhere,一次编写、到处运行。这也是Java的魅力所在。而实现这种特性的正是Java虚拟机JVM。已编译的Java程序可以在任何带有JVM的平台上运行。你可以在windows平台编写代码,然后拿到linux上运行。只要你在编写完代码后,将代码编译成.class文件,再把class文件打成Java包,这个jar包就可以在不同的平台上运行了。
Java具有稳健性。
Java是一个强类型语言,它允许扩展编译时检查潜在类型不匹配问题的功能。Java要求显式的方法声明,它不支持C风格的隐式声明。这些严格的要求保证编译程序能捕捉调用错误,这就导致更可靠的程序。
异常处理是Java中使得程序更稳健的另一个特征。异常是某种类似于错误的异常条件出现的信号。使用try/catch/finally语句,程序员可以找到出错的处理代码,这就简化了出错处理和恢复的任务。
2.Java 与 C++ 的区别
Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 兼容 C ,不但支持面向对象也支持面向过程。
Java 通过虚拟机从而实现跨平台特性, C++ 依赖于特定的平台。
Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
Java 支持自动垃圾回收,而 C++ 需要手动回收。
Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
3.面向对象和面向过程的区别?
面向对象和面向过程是一种软件开发思想。
面向过程就是分析出解决问题所需要的步骤,然后用函数按这些步骤实现,使用的时候依次调用就可以了。
面向对象是把构成问题事务分解成各个对象,分别设计这些对象,然后将他们组装成有完整功能的系统。面向过程只用函数实现,面向对象是用类实现各个功能模块。
4.JKD和JRE的区别?
JDK和JRE是Java开发和运行工具,其中JDK包含了JRE,而JRE是可以独立安装的。
JDK:Java Development Kit,JAVA语言的软件工具开发包,是整个JAVA开发的核心,它包含了JAVA的运行(JVM+JAVA类库)环境和JAVA工具。
JRE:Java Runtime Environment,Java运行环境,包含JVM标准实现及Java核心类库。JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器)。
JRE是运行基于Java语言编写的程序所不可缺少的运行环境。也是通过它,Java的开发者才得以将自己开发的程序发布到用户手中,让用户使用。
5.面向对象有哪些特性
面向对象的特征:封装、继承、多态、抽象。
封装:就是把对象的属性和行为(数据)结合为一个独立的整体,并尽可能隐藏对象的内部实现细节,就是把不想告诉或者不该告诉别人的东西隐藏起来,把可以告诉别人的公开,别人只能用我提供的功能实现需求,而不知道是如何实现的。增加安全性。
继承:子类继承父类的数据属性和行为,并能根据自己的需求扩展出新的行为,提高了代码的复用性。
多态:指允许不同的对象对同一消息做出相应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式(发送消息就是函数调用)。封装和继承几乎都是为多态而准备的,在执行期间判断引用对象的实际类型,根据其实际的类型调用其相应的方法。
实现多态的三要素:继承、重写、父类引用指向子类对象。
静态多态性:通过重载实现,相同的方法有不同的參数列表,可以根据参数的不同,做出不同的处理。
动态多态性:在子类中重写父类的方法。运行期间判断所引用对象的实际类型,根据其实际类型调用相应的方法。
抽象表示对问题领域进行分析、设计中得出的抽象的概念,是对一系列看上去不同,但是本质上相同的具体概念的抽象。在Java中抽象用 abstract 关键字来修饰,用 abstract 修饰类时,此类就不能被实例化,从这里可以看出,抽象类(接口)就是为了继承而存在的。
6.Java的基本数据类型有哪些?
byte,8bit
char,16bit
short,16bit
int,32bit
float,32bit
long,64bit
double,64bit
boolean,只有两个值:true、false,可以使⽤用 1 bit 来存储
简单类型 boolean byte char short Int long float double
二进制位数 1 8 16 16 32 64 32 64
包装类 Boolean Byte Character Short Integer Long Float Double
为什么不能用浮点型表示金额?
由于计算机中保存的小数其实是十进制的小数的近似值,并不是准确值,所以,千万不要在代码中使用浮点数来表示金额等重要的指标。
建议使用BigDecimal或者Long来表示金额。
7.什么是值传递和引用传递?
值传递是对基本型变量而言的,传递的是该变量的一个副本,改变副本不影响原变量。
引用传递一般是对于对象型变量而言的,传递的是该对象地址的一个副本, 并不是原对象本身 。所以对引用对象进行操作会同时改变原对象。
8.了解Java的包装类型吗?为什么需要包装类?
Java 是一种面向对象语言,很多地方都需要使用对象而不是基本数据类型。比如,在集合类中,我们是无法将 int 、double 等类型放进去的。因为集合的容器要求元素是 Object 类型。
为了让基本类型也具有对象的特征,就出现了包装类型。相当于将基本类型包装起来,使得它具有了对象的性质,并且为其添加了属性和方法,丰富了基本类型的操作。
自动装箱和拆箱
Java中基础数据类型与它们对应的包装类如下:
原始类型 包装类型
boolean--------Boolean
byte-------------Byte
char------------Character
float-------------Float
int---------------Integer
long-------------Long
short------------Short
double----------Double
装箱:将基础类型转化为包装类型。
拆箱:将包装类型转化为基础类型。
当基础类型与它们的包装类有如下几种情况时,编译器会自动帮我们进行装箱或拆箱:
赋值操作(装箱或拆箱)
进行加减乘除混合运算 (拆箱)
进行>,<,==比较运算(拆箱)
调用equals进行比较(装箱)
ArrayList、HashMap等集合类添加基础类型数据时(装箱)
示例代码:
Integer x = 1; // 装箱 调⽤ Integer.valueOf(1)
int y = x; // 拆箱 调⽤了 X.intValue()
下面看一道常见的面试题:
Integer a = 100;
Integer b = 100;
System.out.println(a == b);
Integer c = 200;
Integer d = 200;
System.out.println(c == d);
输出:
true
false
为什么第三个输出是false?看看 Integer 类的源码就知道啦。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
Integer c = 200; 会调用 调⽤Integer.valueOf(200)。而从Integer的valueOf()源码可以看到,这里的实现并不是简单的new Integer,而是用IntegerCache做一个cache。
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
}
}
这是IntegerCache静态代码块中的一段,默认Integer cache的下限是-128,上限默认127。当赋值100给Integer时,刚好在这个范围内,所以从cache中取对应的Integer并返回,所以a和b返回的是同一个对象,所以比较是相等的,当赋值200给Integer时,不在cache 的范围内,所以会new Integer并返回,当然比较的结果是不相等的。
9.String 为什么不可变?
先看下Java8 String类的源码:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
}
String类是final的,它的所有成员变量也都是final的。
为什么是final的?
线程安全:同一个字符串实例可以被多个线程共享,因为字符串不可变,本身就是线程安全的。
支持hash映射和缓存:因为String的hash值经常会使用到,比如作为 Map 的键,不可变的特性使得 hash 值也不会变,不需要重新计算。
字符串常量池优化。String对象创建之后,会缓存到字符串常量池中,下次需要创建同样的对象时,可以直接返回缓存的引用。
10.String, StringBuffer 和 StringBuilder区别
String的值不可变,StringBuffer 和StringBuildr的值可变
运行速度 StringBuilder>StringBuffer>String (StringBuffer有锁,所以性能会降低)
StringBuffer线程是安全的,适合多线程;StringBuilder线程是不安全的,适合单线程
如果不需要频繁的修改值,用String即可
如果要操作少量的数据用 String,多线程操作字符串缓冲区下操作大量数据用 StringBuffer,单线程操作字符串缓冲区下操作大量数据用 StringBuilder。
11.String 类的常用方法有哪些?
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母。
toUpperCase():将字符串转成大写字符。
substring():截取字符串。
equals():字符串比较。
12.new String(“hello”)会创建几个对象?
使用这种方式会创建两个字符串对象(前提是字符串常量池中没有 “hello” 这个字符串对象)。
“hello” 属于字符串字面量,因此编译时期会在字符串常量池中创建一个字符串对象,指向这个 “hello” 字符串字面量;
使用 new 的方式会在堆中创建一个字符串对象。
13.什么是字符串常量池?
字符串常量池(String Pool)保存着所有字符串字面量,这些字面量在编译时期就确定。字符串常量池位于堆内存中,专门用来存储字符串常量。在创建字符串时,JVM首先会检查字符串常量池,如果该字符串已经存在池中,则返回其引用,如果不存在,则创建此字符串并放入池中,并返回其引用。
14.Object常用方法有哪些?
Java面试经常会出现的一道题目,Object的常用方法
Object常用方法有:toString()、equals()、hashCode()、clone()等。
toString:默认输出对象地址,也可以重写toString方法,按照重写逻辑输出对象值。
equals:默认比较两个引用变量是否指向同一个对象(内存地址),可以重写equals方法,按照制定规则来判断:
hashCode:将与对象相关的信息映射成一个哈希值,默认的实现hashCode值是根据内存地址换算出来。
clone: Java赋值是复制对象引用,如果我们想要得到一个对象的副本,使用赋值操作是无法达到目的的。Object对象有个clone()方法,实现了对象中各个属性的复制,但它的可见范围是protected的。
getClass: 返回此 Object 的运行时类,常用于java反射机制。
wait: 当前线程调用对象的wait()方法之后,当前线程会释放对象锁,进入等待状态。等待其他线程调用此对象的notify()/notifyAll()唤醒或者等待超时时间wait(long timeout)自动唤醒。线程需要获取obj对象锁之后才能调用 obj.wait()。
notify: obj.notify()唤醒在此对象上等待的单个线程,选择是任意性的。notifyAll()唤醒在此对象上等待的所有线程。
15.两个对象的hashCode()相同,则 equals()是否也一定为 true?
equals与hashcode的关系:
如果两个对象调用equals比较返回true,那么它们的hashCode值一定要相同;如果两个对象的hashCode相同,它们并不一定相同。
hashcode方法主要是用来提升对象比较的效率,先进行hashcode()的比较,如果不相同,那就不必在进行equals的比较,这样就大大减少了equals比较的次数,当比较对象的数量很大的时候能提升效率。
之所以重写equals()要重写hashcode(),是为了保证equals()方法返回true的情况下hashcode值也要一致,如果重写了equals()没有重写hashcode(),就会出现两个对象相等但hashcode()不相等的情况。这样,当用其中的一个对象作为键保存到hashMap、hashTable或hashSet中,再以另一个对象作为键值去查找他们的时候,则会查找不到。
16.Java创建对象有几种方式?
用new语句创建对象。
使用反射,使用Class.newInstance()创建对象。
调用对象的clone()方法。
运用反序列化手段,调用java.io.ObjectInputStream对象的readObject()方法。
17.说说类实例化的顺序
Java中类实例化顺序:
父先子后。
静态属性初始化
静态代码块初始化
普通属性初始化
普通代码块初始化
构造方法初始化
18.equals和==有什么区别?
对于基本数据类型,==比较的是他们的值。基本数据类型没有equal方法;
对于复合数据类型,==比较的是它们的存放地址(是否是同一个对象)。equals()默认比较地址值,重写的话按照重写逻辑去比较。
19.常见的关键字有哪些?
1.static
static可以用来修饰类的成员方法、类的成员变量。
static变量也称作静态变量,静态变量和非静态变量的区别是:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。而非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。
static方法一般称作静态方法。静态方法不依赖于任何对象就可以进行访问,通过类名即可调用静态方法。
静态代码块只会在类加载的时候执行一次。
静态内部类
在静态方法里,使用⾮静态内部类依赖于外部类的实例,也就是说需要先创建外部类实例,才能用这个实例去创建非静态内部类。⽽静态内部类不需要。
2.final
final 修饰的类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
3.this
this.属性名称指访问类中的成员变量,可以用来区分成员变量和局部变量。
this.方法名称用来访问本类的方法
4.super
super 关键字用于在子类中访问父类的变量和方法。
在子类B中,我们重写了父类的getName()方法,如果在重写的getName()方法中我们要调用父类的相同方法,必须要通过super关键字显式指出。
20.final, finally, finalize 的区别
final 用于修饰属性、方法和类, 分别表示属性不能被重新赋值,方法不可被覆盖,类不可被继承。
finally 是异常处理语句结构的一部分,一般以try-catch-finally出现,finally代码块表示总是被执行。
finalize 是Object类的一个方法,该方法一般由垃圾回收器来调用,当我们调用System.gc()方法的时候,由垃圾回收器调用finalize()方法,回收垃圾,JVM并不保证此方法总被调用。
21.Java不支持多继承的原因:
出于安全性的考虑,如果子类继承的多个父类里面有相同的方法或者属性,子类将不知道具体要继承哪个。
Java提供了接口和内部类以达到实现多继承功能,弥补单继承的缺陷。
22.如何实现对象克隆?
实现Cloneable接口,重写 clone() 方法。这种方式是浅拷贝,即如果类中属性有自定义引用类型,只拷贝引用,不拷贝引用指向的对象。如果对象的属性的Class也实现 Cloneable 接口,那么在克隆对象时也会克隆属性,即深拷贝。
通过org.apache.commons中的工具类BeanUtils和PropertyUtils进行对象复制。
23.深拷贝和浅拷贝的概念(需个人挖深)
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象。
23.重载和重写的区别
重载: 发生在同一个类中,方法名必须相同,参数类型不同.个数不同.顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
重写: 发生在父子类中,方法名.参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 则子类就不能重写该方法。
24.接口和抽象类的区别
1.实现:抽象类的子类使用 extends 来继承;接口必须使用 implements 来实现接口。
2.构造函数:抽象类可以有构造函数;接口不能有。
3.main 方法:抽象类可以有 main 方法,并且我们能运行它;接口不能有 main 方法。
4.实现数量:类可以实现很多个接口;但是只能继承一个抽象类。
5.访问修饰符:接口中的方法默认使用 public 修饰;抽象类中的方法可以是任意访问修饰符
25.什么时候使用抽象类,什么时候使用接口
抽象类更适合定义某个领域固有属性,也就是本质,接口更适合用于定义某个领域的扩展功能。
当需要为一些类提供公共的实现代码时,应优先考虑抽象类。因为抽象类中的非抽象方法可以被子类继承下来,使实现功能的代码更简单。
当注重代码的扩展性跟可维护性时,应当优先采用接口。
26.java中为什么不允许静态方法里访问非静态变量
静态变量属于类本身,在类加载的时候就会分配内存,可以通过类名直接访问;
非静态变量属于类的对象,只有在类的对象产生时,才会分配内存,通过类的实例去访问;
静态方法也属于类本身,但是此时没有类的实例,内存中没有非静态变量,所以无法调用。
27.静态代理和动态代理的区别,什么场景使用(京东面)
代理是一种常用的设计模式,目的是:为其他对象提供一个代理以控制对某个对象的访问,将两个类的关系解耦。代理类和委托类都要实现相同的接口,因为代理真正调用的是委托类的方法。
区别:
静态代理:由程序员创建或是由特定工具生成,在代码编译时就确定了被代理的类是哪一个是静态代理。静态代理通常只代理一个类;
动态代理:在代码运行期间,运用反射机制动态创建生成。动态代理代理的是一个接口 下的多个实现类;
实现步骤:
a.实现 InvocationHandler 接口创建自己的调用处理器;
b.给 Proxy 类提供 ClassLoader 和代理接口类型数组创建动态代理类;
c.利用反射机制得到动态代理类的构造函数;
d.利用动态代理类的构造函数创建动态代理类对象;
使用场景:Retrofit 中直接调用接口的方法;Spring 的 AOP 机制;
二、内部类
Java 类中不仅可以定义变量和方法,还可以定义类,这样定义在类内部的类就被称为内部类。根据定义的方式不同,内部类分为静态内部类,成员内部类,局部内部类,匿名内部类四种。
1.静态内部类
public class Out {
private static int a;
private int b;
public static class Inner {
public void print() {
System.out.println(a);
}
}
}
1.静态内部类可以访问外部类所有的静态变量和方法,即使是 private 的也一样。
2. 静态内部类和一般类一致,可以定义静态变量、方法,构造方法等。
3. 其它类使用静态内部类需要使用“外部类.静态内部类”方式,如下所示:Out.Inner inner = new Out.Inner();inner.print();
4. Java集合类HashMap内部就有一个静态内部类Entry。Entry是HashMap存放元素的抽象,HashMap 内部维护 Entry 数组用了存放元素,但是 Entry 对使用者是透明的。像这种和外部类关系密切的,且不依赖外部类实例的,都可以使用静态内部类。
2.成员内部类
public class Out {
private static int a;
private int b;
public class Inner {
public void print() {
System.out.println(a);
System.out.println(b);
}
}
}
定义在类内部的非静态类,就是成员内部类。成员内部类不能定义静态方法和变量(final 修饰的除外)。这是因为成员内部类是非静态的,类初始化的时候先初始化静态成员,如果允许成员内部类定义静态变量,那么成员内部类的静态变量初始化顺序是有歧义的。
3.局部内部类
public class Out {
private static int a;
private int b;
public void test(final int c) {
final int d = 1;
class Inner {
public void print() {
System.out.println(c);
}
}
}
}
定义在方法中的类,就是局部类。如果一个类只在某个方法中使用,则可以考虑使用局部类。
4.匿名内部类
abstract class Person {
public abstract void eat();
}
public class Demo {
public static void main(String[] args) {
Person p = new Person() {
public void eat() {
System.out.println("eat something");
}
};
p.eat();
}
}
匿名内部类我们必须要继承一个父类或者实现一个接口,当然也仅能只继承一个父类或者实现一个接口。同时它也是没有 class 关键字,这是因为匿名内部类是直接使用 new 来生成一个对象的引用。
三、异常
如果某个方法不能按照正常的途径完成任务,就可以通过另一种路径退出方法。在这种情况下会抛出一个封装了错误信息的对象。此时,这个方法会立刻退出同时不返回任何值。另外,调用这个方法的其他代码也无法继续执行,异常处理机制会将代码执行交给异常处理器。
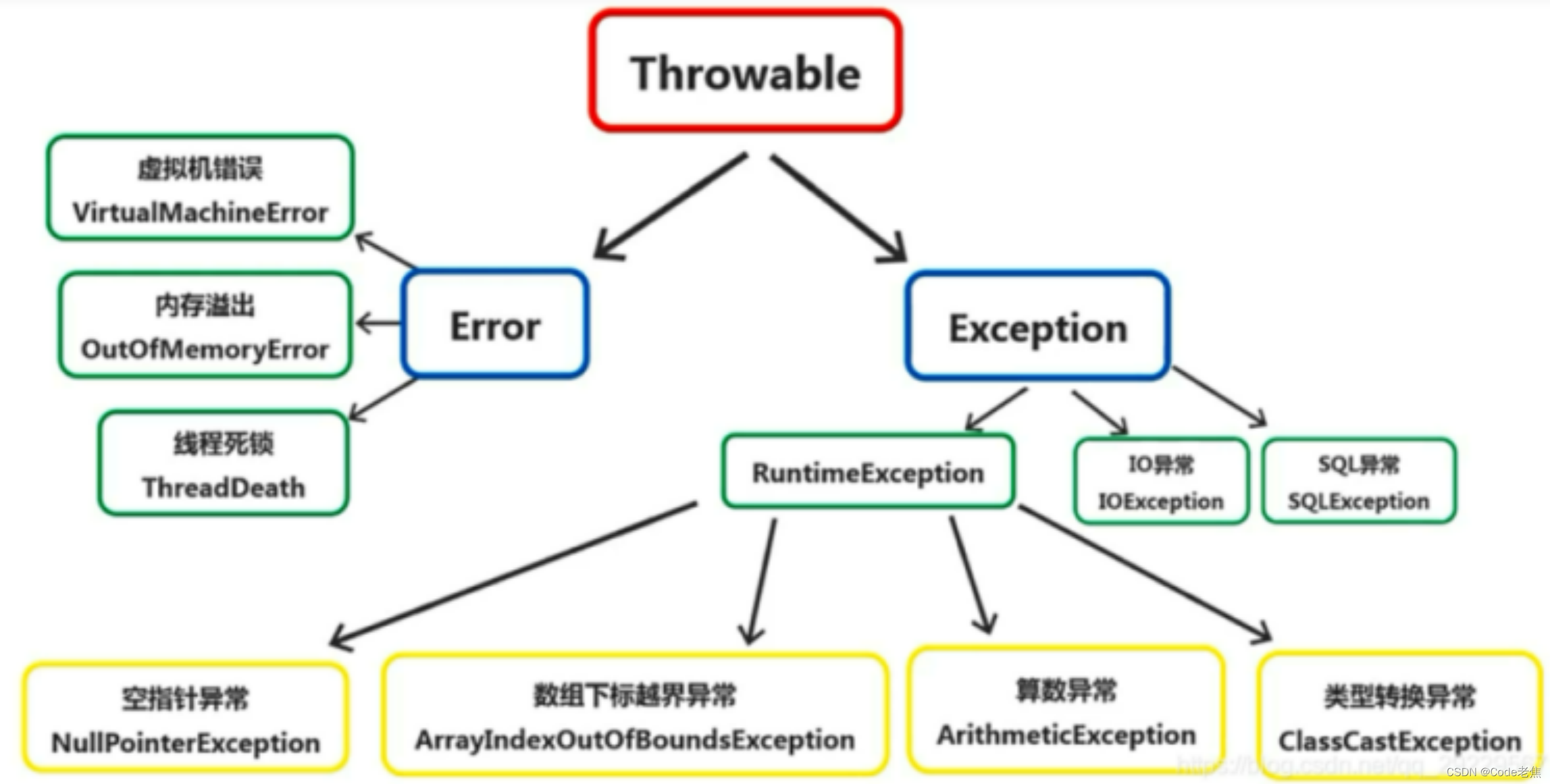
1.Error和Exception的区别:
Throwable是所有Java程序中错误处理的父类,有两种资类:Error和Exception。
Error 表示系统级的错误,是 java 运行环境内部错误或者硬件问题,不能指望程序来处理这样的问题,除了退出运行外别无选择,它是 java 虚拟机抛出的。Exception 表示程序需要捕捉、需要处理的异常,是由与程序设计的不完善而出现的问题,程序可以处理的问题。
2.运行时异常和编译异常区别
1.运行时异常:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
2.非运行时异常 (编译异常):是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
3.简述下 Java 的异常体系(京东面)。
Java 中 Throwable 是所有异常和错误的超类,两个直接子类是 Error(错误)和 Exception(异常):
Error 是程序无法处理的错误,由 JVM 产生和抛出,如 OOM、ThreadDeath 等。这些异常 发生时,JVM 一般会选择终止程序。
Exception 是程序本身可以处理的异常,又分为运行时异常(RuntimeException)(也叫Checked Eception)和 非 运 行 时 异 常(不 检 查 异 常 Unchecked Exception)。 运 行 时 异 常 有 NullPointerException\IndexOutOfBoundsException 等,这些异常一般是
由程序逻辑错误引起 的,应尽可能避免。非运行时异常有
IOException\SQLException\FileNotFoundException 以及 由用户自定义的 Exception异常等。
4.常见的运行时异常
NullPointerException - 空指针引用异常
ClassCastException - 类型强制转换异常。
IllegalArgumentException - 传递非法参数异常。
ArithmeticException - 算术运算异常
ArrayStoreException - 向数组中存放与声明类型不兼容对象异常
IndexOutOfBoundsException - 下标越界异常
NegativeArraySizeException - 创建一个大小为负数的数组错误异常
NumberFormatException - 数字格式异常
SecurityException - 安全异常
UnsupportedOperationException - 不支持的操作异常
5.Throw和Throws区别
位置不同
1.throws 用在函数上,后面跟的是异常类,可以跟多个;而 throw 用在函数内,后面跟的是异常对象。
功能不同:
2.throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式;throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语句,因为执行不到。
3. throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象。
4. 两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
public static void method() throws ArithmeticException {// 跟在方法声明后面,后面跟的是异常类名
int a=10;
int b=0;
if(b==0) {
throw new ArithmeticException();用在方法体内,后面跟的是异常类对象名
}else {
System.out.println(a/b);
}
}
}
6.finally一定会执行吗?
不一定,分情况。因为首先想要执行 finally 块的前提是必须执行到了 try 块,当在 try 块或者 catch 块中有 System.exit(0); 这样的语句存在时 finally 块就不会被执行到了,因为程序被结束了。此外当在 try 块或者 catch 块里 return 时 finally 会被执行;而且 finally 块里 return 语句会把 try 块或者 catch 块里的 return 语句效果给覆盖掉且吞掉了异常。
7.对异常处理有什么心得?(自己补充些)
1.方法返回值尽量不要使用 null(特殊场景除外),这样可以避免很多 NullPointerException 异常。
2.catch 住了如果真的没必要处理则至少加行打印,这样可在将来方便排查问题。
3.接口方法抛出的异常尽量保证是运行时异常类型,除非迫不得已才抛出检查类型异常。
4.避免在 finally 中使用 return 语句或者抛出异常,如果调用的其他代码可能抛出异常则应该捕获异常并进行处理,因为 finally 中 return 不仅会覆盖 try 和 catch 内的返回值且还会掩盖 try 和 catch 内的异常,就像异常没有发生一样(特别注意,当 try-finally 中没有 return 时该方法运行会继续抛出异常)。
5.尽量不要在 catch 块中压制异常(即什么也不处理直接 return),因为这样以后无论抛出什么异常都会被忽略,以至没有留下任何问题线索,如果在这一层不知道如何处理异常最好将异常重新抛出由上层决定如何处理异常。
6.方法定义中 throws 后面尽量定义具体的异常列表,不要直接 throws Exception。
7.捕获异常时尽量捕获具体的异常类型而不要直接捕获其父类,这样容易造成混乱。
8.避免在 finally 块中抛出异常,不然第一个异常的调用栈会丢失。
9.不要使用异常控制程序的流程,譬如本应该使用 if 语句进行条件判断的情况下却使用异常处理是非常不好的习惯,会严重影响性能。
10.不要直接捕获 Throwable 类,因为 Error 是 Throwable 类的子类,当应用抛出 Errors 的时候一般都是不可恢复的情况。
四、IO流
1、I/O 流的分类
①按照读写的单位大小来分:
字符流:以字符为单位,每次次读入或读出是 16 位数据。其只能读取字符类型数据。(Java 代码接收数据为一般为 char 数组,也可以是别的)
字节流:以字节为单位,每次次读入或读出是 8 位数据。可以读任何类型数据,图片、文件、音乐视频等。 (Java 代码接收数据只能为 byte 数组)
②按照实际 IO 操作来分:
输出流:从内存读出到文件。只能进行写操作。
输入流:从文件读入到内存。只能进行读操作。
注意:输出流可以帮助我们创建文件,而输入流不会。
③按照读写时是否直接与硬盘,内存等节点连接分:
节点流:直接与数据源相连,读入或读出。
处理流:也叫包装流,是对一个对于已存在的流的连接进行封装,通过所封装的流的功能调用实现数据读写。如添加个 Buffering 缓冲区。(意思就是有个缓存区,等于软件和mysql 中的 redis)
注意:为什么要有处理流?主要作用是在读入或写出时,对数据进行缓存,以减少 I/O 的次数,以便下次更好更快的读写文件,才有了处理流。
2、字节流如何转为字符流
字节输入流转字符输入流通过 InputStreamReader 实现,该类的构造函数可以传入InputStream 对象。
字节输出流转字符输出流通过 OutputStreamWriter 实现,该类的构造函数可以传入OutputStream 对象。
3、System.out.println 是什么
println 是 PrintStream 的一个方法。out 是一个静态 PrintStream 类型的成员变量,System 是一个 java.lang 包中的类,用于和底层的操作系统进行交互。
4、什么是 Filter 流
Filter Stream 是一种 IO 流主要作用是用来对存在的流增加一些额外的功能,像给目标文件增加源文件中不存在的行数,或者增加拷贝的性能。
5、有哪些可用的 Filter 流
在 java.io 包中主要由 4 个可用的 filter Stream。两个字节 filter stream,两个字符 filter stream. 分别是 FilterInputStream, FilterOutputStream, FilterReader and FilterWriter这些类是抽象类,不能被实例化的。
6、有哪些 Filter 流的子类
LineNumberInputStream 给目标文件增加行号
DataInputStream 有些特殊的方法如 readInt(), readDouble()和 readLine() 等可以读取一个 int, double 和一个 string 一次性的,
BufferedInputStream 增加性能
PushbackInputStream 推送要求的字节到系统中
7、NIO 和 I/O 的主要区别
面向流与面向缓冲
Java IO 和 NIO 之间第一个最大的区别是,IO 是面向流的,NIO 是面向缓冲区的。 Java IO 面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。 Java NIO 的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
阻塞与非阻塞 IO
Java IO 的各种流是阻塞的。这意味着,当一个线程调用 read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。Java NIO 的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞 IO 的空闲时间用于在其它通道上执行 IO 操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
选择器(Selectors)
Java NIO 的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
NIO 提供了与标准 IO 不同的 IO 工作方式:
Channels and Buffers(通道和缓冲区):标准的 IO 基于字节流和字符流进行操作的,而 NIO 是基于通道(Channel)和缓冲区(Buffer)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
8、BIO、NIO、AIO 有什么区别?
BIO (Blocking I/O):同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机 1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO (New I/O): NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。NIO 提供了与传统 BIO 模型中的 Socket 和 ServerSocket 相对应的 SocketChannel 和ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
AIO (Asynchronous I/O): AIO 也就是 NIO2。在 Java 7 中引入了NIO 的改进版NIO 2,它是异步非阻塞的 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步 IO 的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO 操作本身是同步的。
9、NIO 有哪些核心组件?
Channel 、Buffer 、Selector
Channel 和流有点类似。通过 Channel,我们即可以从 Channel 把数据写到 Buffer 中,也可以把数据冲 Buffer 写入到 Channel,每个 Channel 对应一个 Buffer 缓冲区,Channel会注册到 Selector。Selector 根据 Channel 上发生的读写事件,将请求交由某个空闲的线程处理,Selector 对应一个或多个线程,Channnel 和 Buffer 是可读可写的。
10、IO 密集=Ncpu*2 是怎么计算出来(美团面)
I/O 密集型任务任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在I/O 密集型任务的应用中,我们可以多配置一些线程。例如:数据库交互,文件上传下载,网络传输等。IO 密集型,即该任务需要大量的 IO,即大量的阻塞,故需要多配置线程数。
11、select、poll、epoll 区别有哪些(百度面)?
select:它仅仅知道了,有 I/O 事件发生了,却并不知道是哪那几个流(可能有一个,多个,甚至全部),我们只能无差别轮询所有流,找出能读出数据,或者写入数据的流,对他们进行操作。所以 select 具有 O(n)的无差别轮询复杂度,同时处理的流越多,无差别轮询时间就越长。
poll:poll 本质上和 select 没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd 对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的epoll:
epoll 可以理解为 event poll,不同于忙轮询和无差别轮询,epoll 会把哪个流发生了怎样的 I/O 事件通知我们。所以我们说 epoll 实际上是事件驱动(每个事件关联上 fd)的,此时我们对这些流的操作都是有意义的。(复杂度降低到了 O(1)),通过红黑树和双链表数据结构,并结合回调机制,造就了 epoll 的高效,epoll_create(),epoll_ctl()和 epoll_wait()系统调用。
12、如何实现对象克隆?
有两种方式:
① 实现 Cloneable 接口并重写 Object 类中的 clone()方法;
② 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
13、什么是缓冲区?有什么作用?
缓冲区就是一段特殊的内存区域,很多情况下当程序需要频繁地操作一个资源(如文件或数据库)则性能会很低,所以为了提升性能就可以将一部分数据暂时读写到缓存区,以后直接从此区域中读写数据即可,这样就可以显著的提升性能。
对于 Java 字符流的操作都是在缓冲区操作的,所以如果我们想在字符流操作中主动将缓冲区刷新到文件则可以使用 flush() 方法操作。
14、什么是阻塞 IO?什么是非阻塞 IO?
IO 操作包括:对硬盘的读写、对 socket 的读写以及外设的读写。
当用户线程发起一个 IO 请求操作(本文以读请求操作为例),内核会去查看要读取的数据是否就绪,对于阻塞 IO 来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;对于非阻塞 IO 来说,如果数据没有就绪,则会返回一个标志信息告知用户线程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的 IO 读请求操作,也就是说一个完整的 IO 读请求操作包括两个阶段:
查看数据是否就绪;
进行数据拷贝(内核将数据拷贝到用户线程)。
那么阻塞(blocking IO)和非阻塞(non-blocking IO)的区别就在于第一个阶段,如果数据没有就绪,在查看数据是否就绪的过程中是一直等待,还是直接返回一个标志信息。
Java 中传统的 IO 都是阻塞 IO,比如通过 socket 来读数据,调用 read()方法之后,如果数据没有就绪,当前线程就会一直阻塞在 read 方法调用那里,直到有数据才返回;而如果是非阻塞 IO 的话,当数据没有就绪,read()方法应该返回一个标志信息,告知当前线程数据没
有就绪,而不是一直在那里等待。
15、请说一下 PrintStream BufferedWriter PrintWriter 有什么不同?
PrintStream 类的输出功能非常强大,通常如果需要输出文本内容,都应该将输出流包装成 PrintStream 后进行输出。它还提供其他两项功能。与其他输出流不同,PrintStream 永远不会抛出 IOException;而是,异常情况仅设置可通过 checkError 方法测试的内部标志。另外,为了自动刷新,可以创建一个 PrintStreamBufferedWriter:将文本写入字符输出流,缓冲各个字符从而提供单个字符,数组和字符串的高效写入。通过 write()方法可以将获取到的字符输出,然后通过newLine()进行换行操作。BufferedWriter 中的字符流必须通过调用 flush 方法才能将其刷出去。并且BufferedWriter 只能对字符流进行操作。如果要对字节流操作,则使用BufferedInputStream。PrintWriter 的 println 方法自动添加换行,不会抛异常,若关心异常,需要调用checkError 方法看是否有异常发生,PrintWriter 构造方法可指定参数,实现自动刷新缓存(autoflush)。
五、反射
1、反射的基本原理
反射机制就是使 Java 程序在运行时具有自省(introsp ect) 的能力,通过反射我们可以直接操作类 和对象,比如获取某个类的定义,获取类的属性和方法 构造方法等。
2、反射的实现方式
①通过一个全限类名创建一个对象
Class.forName(“全限类名”);
类名.class;
对象.getClass();
②通过class对象获得一个属性对象
Field c=cls.getFields():获得某个类的所有的公共(public)的字段,包括父类中的字段。
Field c=cls.getDeclaredFields():获得某个类的所有声明的字段,即包括public、private和proteced,但是 不包括父类的声明字段
③通过class对象获得一个方法对象
Cls.getMethod(“方法名”,class……parameaType);(只能获取公共的)
Cls.getDeclareMethod(“方法名”);(获取任意修饰的方法,不能执行私有)
M.setAccessible(true);(让私有的方法可以执行)
④执行方法: Method.invoke(obj实例对象,obj可变参数);
3、反射Api有哪些
Field类:提供有关类的属性信息,以及对它的动态访问权限。它是一个封装反射类的属性的类。
Constructor类:提供有关类的构造方法的信息,以及对它的动态访问权限。它是一个封装反射类的构造方法的类。
Method类:提供关于类的方法的信息,包括抽象方法。它是用来封装反射类方法的一个类。
Class类:表示正在运行的Java应用程序中的类的实例。
Object类:Object是所有Java类的父类。所有对象都默认实现了Object类的方法。
4、反射能够做什么
我们知道反射机制允许程序在运行时取得任何一个已知名称的class的内部信息,包括包括其modifiers(修饰符),fields(属性),methods(方法)等,并可于运行时改变fields内容或调用methods。那么我们便可以更灵活的编写代码,代码可以在运行时装配,无需在组件之间进行源代码链接,降低代码的耦合度;还有动态代理的实现等等;但是需要注意的是反射使用不当会造成很高的资源消耗。
六、1.8新特性
1、Lambda 表达式
Lambda 允许把函数作为一个方法的参数。
使用Lambda 表达式可以使代码变的更加简洁紧凑。
1.lambda语法
语法格式一 : 无参数,无返回值
() -> System.out.println(“Hello Lambda!”);
语法格式二 : 有一个参数,并且无返回值
(x) -> System.out.println(x)
语法格式三 : 若只有一个参数,小括号可以省略不写
x -> System.out.println(x)
语法格式四 : 有两个以上的参数,有返回值,并且 Lambda 体中有多条语句
Comparator com = (x, y) -> {
System.out.println(“函数式接口”);
return Integer.compare(x, y);
};
语法格式五 : 若 Lambda 体中只有一条语句, return 和 大括号都可以省略不写
Comparator com = (x, y) -> Integer.compare(x, y);
语法格式六 : Lambda 表达式的参数列表的数据类型可以省略不写,因为JVM编译器通过上下文推断出,数据类型,即“类型推断”
(Integer x, Integer y) -> Integer.compare(x, y);
2、常见例子:
2、方法引用
方法引用允许直接引用已有 Java 类或对象的方法或构造方法。
方法引用通过方法的名字来指向一个方法。
方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
方法引用使用一对冒号 :: 。
class Car {
@FunctionalInterface
public interface Supplier<T> {
T get();
}
//Supplier是jdk1.8的接口,这里和lamda一起使用了
public static Car create(final Supplier<Car> supplier) {
return supplier.get();
}
public static void collide(final Car car) {
System.out.println("Collided " + car.toString());
}
public void follow(final Car another) {
System.out.println("Following the " + another.toString());
}
public void repair() {
System.out.println("Repaired " + this.toString());
}
public static void main(String[] args) {
//构造器引用:它的语法是Class::new,或者更一般的Class< T >::new实例如下:
Car car = Car.create(Car::new);
Car car1 = Car.create(Car::new);
Car car2 = Car.create(Car::new);
Car car3 = new Car();
List<Car> cars = Arrays.asList(car,car1,car2,car3);
System.out.println("===================构造器引用========================");
//静态方法引用:它的语法是Class::static_method,实例如下:
cars.forEach(Car::collide);
System.out.println("===================静态方法引用========================");
//特定类的任意对象的方法引用:它的语法是Class::method实例如下:
cars.forEach(Car::repair);
System.out.println("==============特定类的任意对象的方法引用================");
//特定对象的方法引用:它的语法是instance::method实例如下:
final Car police = Car.create(Car::new);
cars.forEach(police::follow);
System.out.println("===================特定对象的方法引用===================");
}
}
3、函数式接口
1.什么是函数是接口:
有且仅有一个抽象方法的接口叫做函数式接口,函数式接口可以被隐式转换为 Lambda 表达式。通常函数式接口
上会添加@FunctionalInterface 注解。
2.jdk1.8前后:
JDK 1.8之前已有的函数式接口:
· java.lang.Runnable
· java.util.concurrent.Callable
· java.security.PrivilegedAction
· java.util.Comparator
· java.io.FileFilter
· java.nio.file.PathMatcher
· java.lang.reflect.InvocationHandler
· java.beans.PropertyChangeListener
· java.awt.event.ActionListener
· javax.swing.event.ChangeListener
JDK 1.8 新增加的函数接口:
· java.util.function
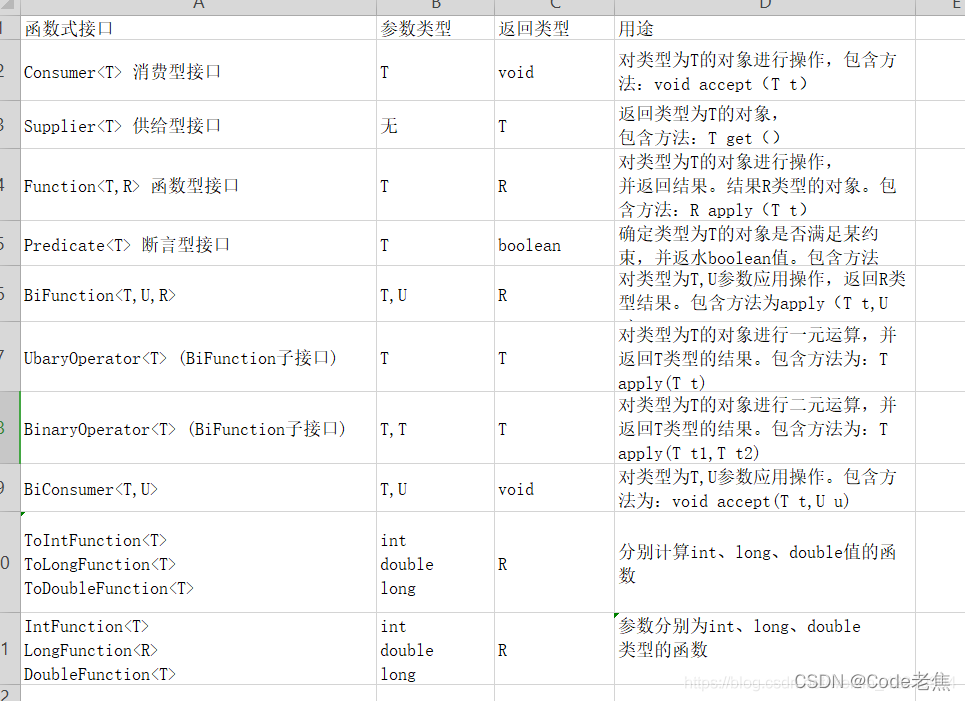
3、Java内置的四大核心函数式接口:
4、接口允许定义默认方法和静态方法
Java 8 新增了接口的默认方法。
简单说,默认方法就是接口可以有实现方法,而且不需要实现类去实现其方法。
我们只需在方法名前面加个default关键字即可实现默认方法。
为什么要有这个特性?
首先,之前的接口是个双刃剑,好处是面向抽象而不是面向具体编程,缺陷是,当需要修改接口时候,需要修改全部实现该接口的类,目前的java 8之前的集合框架没有foreach方法,通常能想到的解决办法是在JDK里给相关的接口添加新的方法及实现。然而,对于已经发布的版本,是没法在给接口添加新方法的同时不影响已有的实现。所以引进的默认方法。他们的目的是为了解决接口的修改与现有的实现不兼容的问题。
Java 8 的另一个特性是接口可以声明(并且可以提供实现)静态方法。
5、Stream流
1、什么是Stream:
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流,流在管道中传输,并且可以在管道的节点上进行处理,比如筛选,排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
2、Stream常见用法:
①forEach
Stream 提供了新的方法 ‘forEach’ 来迭代流中的每个数据。
list.stream.forEach(System.out::println);
②map
map 方法用于映射每个元素到对应的结果,以下代码片段使用 map 获取了用户的uid集合
Set<String> membersSet = userTblList.stream().filter(confUserTbl -> null != confUserTbl.getJoinTime())
.filter(confUserTbl -> null != confUserTbl.getQuitTime())
.map(confUserTbl -> confUserTbl.getUid())
.collect(Collectors.toSet());
③filter
filter 方法用于通过设置条件过滤出元素。以下代码片段使用filter 方法过滤出开始时间和结束时间不为null的用户:
List<ConfUserTbl> allUserTblListUpdate = allUserTblList.stream()
.filter(confUserTbl -> null != confUserTbl.getJoinTime())
.filter(confUserTbl -> null != confUserTbl.getQuitTime())
.collect(Collectors.toList());
⑤ limit
limit 方法用于获取指定数量的流。以下代码片段使用 limit 方法打印出 10 条数据:
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);
⑥sorted
sorted 方法用于对流进行排序。以下代码片段使用 sorted 方法对输出的 10 个随机数进行排序:
Random random = new Random();
random.ints().limit(10).sorted().forEach(System.out::println);
⑦并行(parallel)程序
parallelStream 是流并行处理程序的代替方法。以下实例我们使用parallelStream 来输出空字符串的数量:
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd", "", "jkl");
// 获取空字符串的数量
int count = (int) strings.parallelStream().filter(string -> string.isEmpty()).count();
我们可以很容易的在顺序运行和并行直接切换。
⑧Collectors
Collectors 类实现了很多归约操作,例如将流转换成集合和聚合元素。Collectors可用于返回列表或字符串:
allUserTblListUpdate = allUserTblListUpdate.stream()
.filter(confUserTbl -> StringUtils.isEmpty(confUserTbl.getConfSid()))
.collect(Collectors.toSet());
或者.collect(Collectors.toList());
⑨统计
获取常见统计结果
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
IntSummaryStatistics stats = numbers.stream().mapToInt((x) -> x).summaryStatistics();
System.out.println("列表中最大的数 : " + stats.getMax());
System.out.println("列表中最小的数 : " + stats.getMin());
System.out.println("所有数之和 : " + stats.getSum());
System.out.println("平均数 : " + stats.getAverage());
6、日期/时间类改进
之前的 JDK 自带的日期处理类非常不方便,我们处理的时候经常是使用的第三方工具包,比如 commons-lang 包等。不过 JDK8 出现之后这个改观了很多,比如日期时间的创建、比较、调整、格式化、时间间隔等。
这些类都在 java.time 包下,LocalDate/LocalTime/LocalDateTime。
LocalDateTime currentTime = LocalDateTime.now();
System.out.println("当前时间: " + currentTime);
LocalDate date1 = currentTime.toLocalDate();
System.out.println("date1: " + date1);
Month month = currentTime.getMonth();
int day = currentTime.getDayOfMonth();
int seconds = currentTime.getSecond();
System.out.println("月: " + month + ", 日: " + day + ", 秒: " + seconds);
LocalDateTime date2 = currentTime.withDayOfMonth(10).withYear(2012);
System.out.println("date2: " + date2);
// 12 december 2014
LocalDate date3 = LocalDate.of(2014, Month.DECEMBER, 12);
System.out.println("date3: " + date3);
// 22 小时 15 分钟
LocalTime date4 = LocalTime.of(22, 15);
System.out.println("date4: " + date4);
// 解析字符串
LocalTime date5 = LocalTime.parse("20:15:30");
System.out.println("date5: " + date5);
7、Optional 类
Optional 类是一个可以为 null 的容器对象。如果值存在则 isPresent()方法会返回 true,调用 get()方法会返回该对象。
类方法:
1、返回空的 Optional 实例。
static <T> Optional<T> empty()
2、判断其他对象是否等于 Optional。
boolean equals(Object obj)
3、如果值存在,并且这个值匹配给定的 predicate,返回一个Optional用以描述这个值,否则返回一个空的Option Optional。
Optional<T> filter(Predicate<? super <T> predicate)
4 如果值存在,返回基于Optional包含的映射方法的值,否则返回一个空的Optional
<U> Optional<U> flatMap(Function<? super T,Optional<U>> mapper)
5、如果在这个Optional中包含这个值,返回值,否则抛出异常:NoSuchElementException
T get()
6、返回存在值的哈希码,如果值不存在返回 0。
int hashCode()
7、如果值存在则使用该值调用 consumer , 否则不做任何事情。
void ifPresent(Consumer<? super T> consumer)
8、如果值存在则方法会返回true,否则返回 false。
boolean isPresent()
9、如果存在该值,提供的映射方法,如果返回非null,返回一个Optional描述结果。
<U>Optional<U> map(Function<? super T,? extends U> mapper)
10、返回一个指定非null值的Optional。
static <T> Optional<T> of(T value)
11、如果为非空,返回 Optional 描述的指定值,否则返回空的 Optional。
static <T> Optional<T> ofNullable(T value)
12、如果存在该值,返回值,否则返回 other。
T orElse(T other)
13、如果存在该值,返回值,否则触发 other,并返回 other 调用的结果。
T orElseGet(Supplier<? extends T> other)
14、如果存在该值,返回包含的值,否则抛出由 Supplier 继承的异常
<X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier)
15、返回一个Optional的非空字符串,用来调试
String toString()
8、Java8 Base64 实现
Java 8 内置了 Base64 编码的编码器和解码器。
Base64工具类提供了一套静态方法获取下面三种BASE64编解码器:
· 基本:输出被映射到一组字符A-Za-z0-9+/,编码不添加任何行标,输出的解码仅支持A-Za-z0-9+/。
· URL:输出映射到一组字符A-Za-z0-9+_,输出是URL和文件。
· MIME:输出隐射到MIME友好格式。输出每行不超过76字符,并且使用’\r’并跟随’\n’作为分割。编码输出最后没有行分割。
1、返回一个 Base64.Decoder ,解码使用基本型 base64 编码方案。
static Base64.Decoder getDecoder()
2、返回一个 Base64.Encoder ,编码使用基本型 base64 编码方案。
static Base64.Encoder getEncoder()
3、返回一个 Base64.Decoder ,解码使用 MIME 型 base64 编码方案。
static Base64.Decoder getMimeDecoder()
4、返回一个 Base64.Encoder ,编码使用 MIME 型 base64 编码方案。
static Base64.Encoder getMimeEncoder()
5、返回一个 Base64.Encoder ,编码使用 MIME 型 base64 编码方案,可以通过参数指定每行的长度及行的分隔符。
static Base64.Encoder getMimeEncoder(int lineLength, byte[] lineSeparator)
6、返回一个 Base64.Decoder ,解码使用 URL 和文件名安全型 base64 编码方案。
static Base64.Decoder getUrlDecoder()
7、返回一个 Base64.Encoder ,编码使用 URL 和文件名安全型 base64 编码方案。
static Base64.Encoder getUrlEncoder()
Java相关面试题持续更新中,敬请期待!















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









