







标题:
Identifying adolescents at risk for depression: Assessment of a global prediction model in the Great Smoky Mountains Study
识别有抑郁风险的青少年:对大烟山研究中全球预测模型的评估
Highlights:
-
Previously, a risk score for adolescent depression (IDEA-RS) was validated in five countries.此前,青少年抑郁症的风险评分(IDEA-RS)在五个国家进行了验证。
-
The IDEA-RS performed above chance in predicting depression in an external sample from the USA. 在来自美国的外部样本中,IDEA-RS预测抑郁症的几率高于chance。
-
Differences on predictive measures and on prevalence rates did not compromise performance. 预测指标和患病率的差异并没有影响表现。
-
Cross-informant prediction had similar performance to common-informant. 交叉信息预测与普通信息预测具有相似的性能。
-
This indicates that IDEA-RS is informative in distinct settings across the globe. 这表明IDEA-RS在全球不同的环境中提供了信息。
Abstract:
青少年早期抑郁风险识别评分(IDEA-RS)已经在四大洲的样本中进行了外部评估,但北美缺乏。我们这里的目的是评估在大烟山研究(GSMS)中,IDEA-RS对美国青少年群体样本中未来严重抑郁症(MDD)发作的预测性能。我们应用巴西开发的原始IDEA-RS模型的截距和权重,为GSMS的每个参与者生成一个15岁时的个人概率(N=1029)。然后,我们使用简单的、病例混合校正和改装的模型,评估了这些预测对19岁时MDD诊断的效果。此外,我们比较了优先考虑父母或青少年提供的信息对性能的影响。当使用未校正的权重时,IDEA-RS预测的C统计量为0.63 (95% CI 0.53-0.74)。病例混合修正模型和改装模型将性能分别提高到0.69和0.67。通过优先考虑青少年或其父母的报告,在性能上没有发现显著差异。IDEA-RS能以超过chance discrimination的性能在GSMS样本中分析出有晚发抑郁症风险的青少年。IDEARS目前在五个大洲都有above-chance的性能。
1. Introduction
青少年抑郁症患病率明显增加(Avenevoli等人,2015),这既是生命早期疾病负担的增加,也是预防的主要机会。因此,区分青少年未来发展为抑郁症的风险高低,可能是为公共卫生和临床决策提供信息的关键一步(Kieling等人,2019)。然而,尽管抑郁症和精神健康障碍的风险因素已经确定,但将多个变量聚合为一个个体水平风险估计的预测模型才刚刚开始出现在文献中(Salazar de Pablo等人,2021)。
为了实现这一目标,我们的小组开发了青少年早期抑郁风险识别评分(IDEA-RS),这是一个预测青少年重度抑郁障碍(MDD)发作的预后模型。该模型最初是使用巴西1993年Pelotas出生群体的数据设计的(Rocha等人,2021),这是一项在中上收入国家进行的具有代表性的前瞻性研究。该算法在临床或流行病学背景下易于收集,只需在简短的评估中收集青少年的信息,即可得出11个社会和人口预测变量。在C统计量上,IDEA-RS实现了0.76-0.79的判别性能,该结果可与医学中广泛使用的预测模型相媲美(china, 2011;Marques等人)。随后,该模型在英国、尼日利亚、新西兰和尼泊尔等一系列具有不同社会文化和经济背景的国家进行了评估,C统计量分别达到0.59、0.62、0.63和0.73 (Brathwaite等人,2020,2021;Rocha等人,2021)。因此,IDEA-RS在四个不同的大洲都取得了超出偶然的成绩,但仍需要对其在北美的表现进行评估。
从这个意义上说,大烟山研究(GSMS)为外部复制提供了一个独特的机会。这是一项具有社区代表性的纵向研究,从9岁起对参与者进行随访,旨在评估儿童时期精神疾病的患病率及其随时间的发展。因此,IDEA-RS中使用的大部分预测因子都是本研究收集的变量,如“童年虐待”、“打架斗殴”、“吸毒”、“社会孤立”、“性别”、“学业失败”、“离家出走”和“肤色”。此外,GSMS的一个明显特点是,敏感话题的信息来源是双重的——从父母和年轻人自己那里获取数据。先前的研究表明,青少年的自我评价信息和父母评价信息之间在估计的一致性方面存在差异(Lewis等人,2012;Piehler等人,2020),目前尚不清楚它们是否可以互换使用,以确定预测工具中是否存在风险因素。
为了弥补这些研究空白,目前的研究试图使用最初在巴西Pelotas 1993出生队列中建立的模型,确定美国大烟山研究(GSMS)中哪些15岁青少年在19岁时患抑郁症的风险较高。作为第二个目标,我们评估了来自青少年及其监护人的风险因素信息的一致性,以及使用一方或另一方报告的信息对模型性能的影响。
2. Method
2.1 Description of study setting and recruitment of study cohort 研究设置和研究群体的选择
我们使用的数据来自GSMS群体,这是一个基于人口的样本,从美国南部阿巴拉契亚山区的11个县招募了1420名儿童。该研究采用加速队列设计,包括3组9岁、11岁和13岁的儿童,在以前的工作中有更详细的描述(Costello等人,1996;Copeland et al, 2014)。杜克大学医学中心机构审查委员会批准了GSMS数据收集协议。家长和成年人签署知情同意书,未成年儿童签署知情同意书。调查是根据2013年版的《赫尔辛基宣言》进行的。
在纳入研究的1420名儿童中,我们选择了1072名同时具有15岁和19岁可用数据的参与者进行当前分析(保留率= 75.5%)。失去随访的参与者更有可能是男性(67.1%对52.5%,卡方独立性检验 p < 0.001),更多在学校失败(32.0%对24.9%,p = 0.014),不太可能吸毒(34.8%对41.5%,p = 0.035),但在其他人口统计学和风险因素变量方面与保留的参与者有相似的情况(见补充表S2)。然后,我们应用了先前在抑郁症风险模型开发中采用的排除标准,目的是捕捉抑郁症的首次发作,并克服潜在的混杂因素(智力残疾、青春期延迟)。因此,29名参与者因在15岁或之前出现抑郁发作而被排除在外,另有12名参与者因被诊断为青春期延迟而被排除(15岁时Tanner分期<2)。没有参与者因智力残疾而被排除在外(智商低于70),因为这已经是GSMS的排除标准。另外两名参与者缺少相关变量的数据,因此被排除在外。当前分析的最终样本量为1029。图1中的流程图概括了选择过程。

2.2 Predictor variables and data harmonization 预测变量和数据协调
最初基于Pelotas群体开发的IDEA-RS包括11个在15岁时评估的变量,用于预测18岁时的抑郁症。我们在GSMS样本中先验定义了15岁时的匹配变量,以构建数据协调矩阵(见表S1)。大多数变量完全或部分对应。“与母亲的关系”、“与父亲的关系”和“父母之间的关系”这三个变量没有发现对应关系,因此没有出现在这里的模型中。正因为如此,我们还通过在Pelotas中生成一个预测模型来更新变量的系数,该模型不包含在GSMS中缺失的三个变量,正如之前的复制工作中所做的那样(Brathwaite等人,2020,2021)。
补充表S1:Pelotas群体中预测因素和抑郁结果测量的描述,以及大烟山研究(GSMS)数据集中的相应的匹配变量
| Pelotas cohort predictors and description | Categories for questions asked in Pelotas | Matching variable available in GSMS dataset? | GSMS cohort matching predictor variable and description | Categories for questions asked in the GSMS cohort |
| 1. Sex | Male | Yes | Sex | Male |
| Female | Female | |||
| 2. Skin colour | White | Yes | Skin colour | White |
| Non-white (including Black, Asian, and Indigenous) | Non-white (including African American and American Indian) | |||
| 3. Childhood maltreatmenta Responses to 7 dichotomous questions on lifetime exposure to emotional, physical, or sexual abuse and child neglect at age 15 years old: 1. Have you ever been separated from your parents to be cared for by someone else?
| None (no positive responses) | Partially | Childhood maltreatment Four domains ascertained from the Child and Adolescent Psychiatric Assessment (CAPA) lifetime exposure to domestic violence, physical abuse and or neglect: 1. Physical violence between P1 and P2. May include pushing, hitting, and throwing things at the partner. 0=absent 1=present 2. Subject has experienced neglect, meaning that a) the caregiver is unable to meet the child's need for food, clothing, housing, transportation, medical attention, or safety, or b) that the sociofamilial setting is potentially dangerous to the child due to a lack of family resources required to meet the child's needs. 0=absent 1=present 3. Victim of physical violence (including threatened with a weapon). Victim of physical violence OR abuse (including threatened with a weapon) 0=absent 1=present 4. Subject has experienced sexual violence (including rape) or sexual abuse in the last 3 months. 0=absent 1=present | None (no positive responses) |
| Probable (1 positive response) | Probable (1 positive response) | |||
| Severe (2 or more positive responses) | Severe (2 or more positive responses) | |||
| 4. School failure Child progressed to next level if achieved predetermined score at end of school year Child was retained in school to repeat the same school year if failed to achieve a predetermined score at end of school year) | No school failure | Yes | School failure Participant was retained in a given year of school / repeated a grade | No school failure (Never repeated a class) |
| Failing at school (Yes, child retained) | Failing at school (Yes, repeated a class) | |||
| 5. Social isolation Normally meets up with friends to chat, play or do other things OR Does not normally meet up with friends to chat, play or do other things | No social isolation | Yes | Social isolation
| No social isolation |
| Social isolation | Social isolation | |||
| 6. Fights Never got into a physical fight that someone got hurt in the last year OR Got into a physical fight that someone got hurt in the last year | No fight involvement | Yes | Fights No fights or fights do not sustain physical injury OR Fights sustained physical injury | No fight involvement |
| Fight involvement | Fight involvement | |||
| 7. Ran away from home Never ran away from home OR Ran away from home | Did not run away | Yes | Ran away from home Absent OR Intending to stay away at time of leaving, but returning or returned before away overnight. Some preparations to allow the subject to have stayed away should have occurred such as packing a bag, taking some treasured possessions, or buying a one-way tick; or intending to stay away and leaving at least overnight. | Did not run away (0) |
| Ran away | Ran away (Any positive answer) | |||
| 8. Drug use Responses to dichotomous questions about lifetime use of alcohol, tobacco, cannabis, cocaine and inhalants. | No drug use | Yes | Drug use Responses to dichotomous questions about lifetime use of alcohol, tobacco, or cannabis. | No drug use |
| Drug use (Any positive answer) | Drug use (Any positive answer) | |||
| 9. Relationship with mother Responses to question on ‘How do you rate your relationship with your mother’. | Great | No | n/a | n/a |
| Very good, Good, Regular, or Bad | n/a | |||
| 10. Relationship with father Responses to question on ‘How do you rate your relationship with your father’. | Great | No | n/a | n/a |
| Very good, Good, Regular, or Bad | n/a | |||
| 11. Relationship between parents Responses to question on ‘How do you rate the relationship between your mother and father’. | Great | No | n/a | n/a |
| Very good, Good, Regular, or Bad | n/a |
2.3 Variables informed by parents and by adolescents 由父母和青少年告知的变量
在Pelotas中生成的原始IDEA-RS模型使用青少年直接提供的信息确定了所有预测因素。为了保持相似性,当可用时,我们在GSMS中优先考虑青少年评分变量。然而,GSMS的预测因素依赖于从父母和青少年那里收集的信息。因此,我们使用卡方统计量比较频率,并使用Cohen 's kappa统计量检验信息提供者之间的一致性。此外,我们通过将模型应用于主要从青少年或其照顾者收集的信息,并比较每种方法的性能,分别计算了个体概率。
2.4 Assessment and definition of the outcome variable 结果变量的评估和定义
我们分析的结果是明确诊断为19岁时的重度抑郁发作。在GSMS参与者中,青年精神病评估(YAPA)(Angold等人,1999)是一种结构化诊断访谈,用于获取19岁时的症状信息。它是儿童和青少年精神病学评估(CAPA)的改编版,用于评估前3个月出现的症状。其诊断MDD的重测可靠性k值为0.9,其有效性被十种不同的标准确定为良好(Angold和Costello,2000)。通过计算机算法评估,如果这些症状符合《精神障碍诊断和统计手册》(DSM-IV)第四版MDD标准(美国精神病协会,1994),则诊断为抑郁症。
2.5 Statistical analysis 统计分析
我们使用R版本3.6.2的软件包rms进行统计分析。在Pelotas队列中,使用惩罚最大似然估计来开发涉及11个预测因子的逻辑回归预测模型(见Rocha等人,2021)。对于当前的分析,我们使用相同的程序在Pelotas数据集中重建了IDEA-RS模型,以删除GSMS中不可用的三个变量。然后,我们将更新后的模型应用于三种外部验证类型的GSMS数据,以评估性能指标。在一个简单的外部验证程序中,我们使用在Pelotas中获得的系数,将其应用于GSMS(即外部独立数据集)的基线数据,计算了每个参与者患抑郁症的预测概率。然而,在评估独立样本中预测模型的性能时,我们还采用了另外两种推荐的方法(Steyerberg, 2009;Debray et al, 2015)。这些方法旨在考虑参与者特征分布的差异(病例组合),以及模型中包含的预测因子效果的真实差异(修正模型)。
我们使用涵盖不同方面的统计技术来衡量模型在独立数据集上预测抑郁症发作的性能。其中包括受试者工作曲线下的面积(或C统计量)、校准曲线、大范围校准、校准斜率、R平方、Brier分数和EMax。C统计量提供了一种区分的衡量标准,即患抑郁症的人比没有患抑郁症的人在IDEA-RS中得分更高的概率。C统计量为0.5表示与chance相似的区分,C统计量为1表示完全区分(Steyerberg, 2009)。校准是指预测结果与观测结果之间的一致性(Fenlon等人,2018)。校准曲线提供了该参数的可视化估计。大范围校准将所有预测概率的平均值与样本中抑郁症的平均观察诊断进行比较,用以表明平均观察差异(0表示完美的大范围校准)。校准斜率衡量的是在预测值范围内,预测值与观测值之间的一致性,1表示完全一致。R平方提供了模型总体拟合优度的度量,即由其解释的方差的比例(Steyerberg,2009)。值的范围从0到1,值越高表示性能越好。Brier Score通过计算预测的抑郁概率和实际抑郁概率之间的均方差来估计模型的总体性能,0表示完美性能(Brier,1950)。EMax量化了预测概率的最大绝对误差,通过校准曲线与代表完美校准的对角线之间的最大绝对垂直距离来估计(Harrell Jr., 2015)。数值越低,表示模型中的误差越小。
我们计算了具有表观性能的原始数据的性能统计数据,并在使用1000个重采样的自举进行内部验证后进行了计算。我们还计算了三种验证类型(简单外部验证、案例混合校正样本和改装模型)的GSMS数据中外部验证的性能指标。我们还使用简单外部验证框架对比了青少年信息优先和父母信息优先的预测因子的表现。
为了了解风险因素之间的关联,我们通过网络分析来比较样本,以评估它们在每个队列中的相互关系。网络是通过bootnet(Epskamp等人,2018)和“IsingFit”函数(Ising,1925;van Borkulo,2018)估计的,能够识别二元变量之间的相关关联。具体来说,我们将变量“儿童虐待”分为存在(可能或严重)或不存在(无),就像IDEA-RS中的所有其他变量一样。我们还将调优参数设置为0.25,并将逻辑规则设置为“OR”,这表明只需要一个回归系数非零就可以在两个节点(变量)之间生成一条边。使用qgraph包(Epskamp等人,2012)以“spring”布局对网络进行可视化。使用1000次迭代(排列),将网络的连通性和结构与网络比较测试(NCT)包(Van Borkulo等人,2015)进行统计比较。使用网络中所有边的加权绝对和来计算网络的全局强度,进而衡量网络的连通性;网络结构是通过距离M来计算的,即网络边权的最大差异(van Borkulo, 2018)。与其他出版物中先前对GSMS样本进行的分析不同,我们决定在分析中不包括权重,因为我们使用的是受限子样本,并且我们也不专注于生成具有代表性的精神障碍患病率估计。
3. Results
3.1. GSMS样本分析及其与pelotas队列比较
最终分析共包括1029名青少年。19岁时,其中32人(3.1%)被诊断为MDD。图2详细说明了Pelotas和GSMS队列中参与者的特征和预测因子的频率。网络分析比较了每个样本中变量之间的关系(网络结构见图3;网络中心性测量见补充图S1)。尽管Pelotas网络似乎在互联度上表现更好,但没有证据表明整体连通性(S=3.78,p=0.41)或结构(M=0.64,p=0.86)存在显著差异。此外,我们观察到,两个网络中的边缘具有相同的正关联和负关联模式。
3.2 IDEA-RS模型在GSMS队列中的外部验证
使用青少年提供的预测因子的外部验证显示,C统计量为0.63 (95% CI 0.53至0.74),截距为0.89,斜率为0.71(见表1)。其余的性能估计显示,拟合优度(R平方)为0.02,Brier评分为0.03,Emax为0.02。正如预期的那样,病例组合校正(C统计量为0.69)和修正模型(C统计量为0.67,95% CI为0.56至0.77)在所有测量中都优于简单的外部验证程序,除了校准较差,这可能是由于少数病例在一系列阈值(即样本量有限)内产生了不稳定的预测。作为另一种分析方法,我们还使用父母和青少年提供的预测因子(将信息与OR规则相结合)测试了IDEA-RS的性能。简单验证(C统计量为0.62,95%CI 0.52至0.71)和改装验证(C统计量为0.67,95%CI 0.57至0.76)的性能略有下降。
3.3 使用主要从家长处收集的信息对IDEA-RS进行评估
除“性别”和“肤色”外,所有其他预测因素的信息均可从两个不同的被调查者(青少年和主要监护人)处获得。图2描述了不同信息源的频率差异。我们还使用Cohen 's kappa系数测试了这些变量的可比性。“儿童虐待”的一致性最高(Kappa为0.81,95% CI 0.78至0.85,p < 0.001),其次是“学业失败”(Kappa为0.76,95% CI 0.72至0.81,p < 0.001)。其余变量的一致性较低,如“吸毒”(Kappa为0.40,95% CI 0.34至0.46,p < 0.001)、“参与打架”(Kappa为0.35,95% CI 0.29至0.41,p < 0.001)、“社会孤立”(Kappa为0.32,95% CI 0.25至0.38,p < 0.001)和“离家出走”(Kappa为0.29,95% CI 0.09至0.50,p < 0.001)。
尽管使用青少年报告变量和父母报告变量的预测因素之间的一致程度各不相同,但无论优先考虑哪种信息来源,模型的总体表现相似。两个模型的个体水平概率估计值之间的相关性为0.76(95%CI,0.73至0.78,p<0.001)。有关三个模型的性能度量的完整信息,请参见表1。
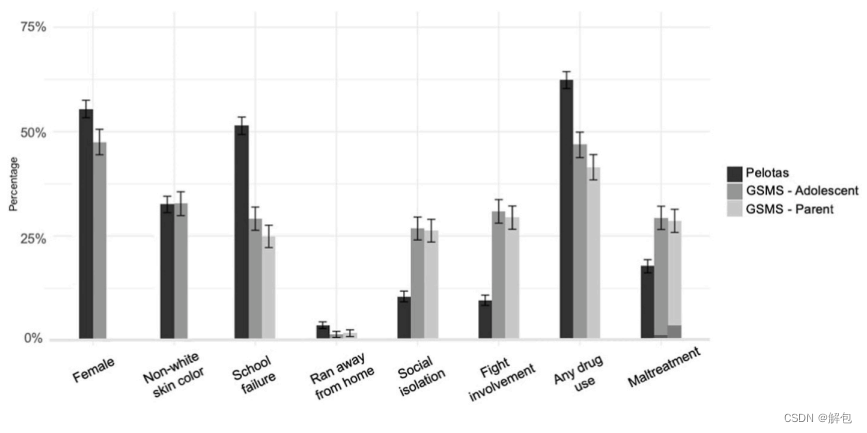
“儿童虐待”变量分为“严重”和“可能”,深色(底部)表示更严重。频率比较采用两比例Ztest。
比较Pelotas和GSMS青少年,发现变量“女性”、“学业失败”、“离家出走”、“社会孤立”、“打架斗殴”、“任何药物使用”、“可能的儿童虐待”和“严重的儿童虐待“存在显著差异(p<0.001)。将Pelotas与GSMS Parent进行比较,发现“学业失败”、“离家出走”、“社会孤立”、“打架斗殴”、“任何药物使用”、“可能的儿童虐待”和“严重的儿童虐待“方面存在显著差异(p<0.001)。比较GSMS青少年和GSMS父母,在变量“学业失败”和“任何药物使用”以及“严重儿童虐待”方面存在显著差异(p<0.05)。

Pelotas和GSMS的网络结构有8个节点,每个节点代表一个风险评分的变量。较暗的边表示正关联,较亮的边表示负关联。线条越粗表示关联关系越强。

4. Discussion
为了从外部评估青少年抑郁症风险预测模型的性能,我们在来自美国的独立样本中测试了巴西开发的模型。根据C统计量,IDEA-RS的判别性能为0.63,这表面在随访中,与非重度抑郁症的个体相比,重度抑郁症的参与者具有更高IDEA-RS的概率为63%。当采用修正模型和病例混合修正模型时,性能提高到0.67至0.69。IDEA-RS之前已经在四大洲的国家进行了测试,在英国达到0.59 (Rocha等人,2021),在尼日利亚达到0.62 (Brathwaite等人,2020),在新西兰达到0.63 (Rocha等人,2021),在尼泊尔达到0.73 (Brathwaite等人,2021)。因此,本研究将北美列为IDEA-RS一贯表现出高于chance discrimination的第五大洲(图4),这是心理健康预测科学的一项不同寻常的成就(Salazar de Pablo et al, 2021)。虽然在将当前验证与0.76–0.79(内部验证后为0.71)的原始模型性能进行比较时,出现了辨别能力的丧失,该模型仍然能为青少年抑郁症风险分级提供信息。在独立样本中复制预测工具时,预计会出现一定程度的性能下降。在这项研究中,即使网络分析发现两个样本中的变量以相似的方式连接。我们还是遇到了原始模型中11个预测因子中有3个不可用,以及变量和结果的不同分布。值得注意的是,我们获得的0.63(外部验证)至0.69(病例混合校正模型)的分数与其他经验证的、广泛使用的医学预后工具相当(Friberg等人,2012;Marques等人,2015)。
虽然最初设计IDEA-RS是为了方便地从青少年中收集信息,但我们在这里也讨论了父母和青少年评级信息之间的一致性。我们进一步测试了优先考虑不同信息来源的变量对IDEA-RS性能的影响。在外部验证中,优先考虑青少年或父母报告的信息会产生类似的预测区分,C统计量分别为0.63和0.64。当使用病例混合校正模型时,性能提高到0.69(青少年)和0.70(父母)。使用修正GSMS样本的最佳预测因子模型时,性能达到曲线下面积为0.67(青少年)和0.68(父母)。因此,我们观察到使用一个或另一个信息源的模型的性能没有显著变化。我们将这些结果归因于这样一个事实,即“性别”和“童年虐待”是模型中的重要预测因素,并且这些因素不受信息来源的影响。虽然这一发现可以允许更广泛的信息提供者,并促进风险计算者的数据收集,但应谨慎使用一致性较低的预测变量。据我们所知,这是心理健康预测模型首次评估使用这些不同信息来源的影响,展示了通过使用父母评定的数据来预测青少年评定的重度抑郁症诊断结果的交叉预测。这在方法论方面增加了研究结果的相关性,因为它避免了单一信息者偏见的问题,并为IDEA-RS模型的概念有效性提供了额外的证据。
4.1 Limitations
我们的研究并非没有局限性。首先,Pelotas队列中使用的三个IDEA-RS变量在GSMS数据集中不可用,因此无法用于数据协调:“与母亲的关系”、“与父亲的关系”和“父母之间的关系”。另外两个变量只是部分匹配:“儿童虐待”在每个队列中的评估不同,尽管被归为相同的三个类别;“社会孤立”在Pelotas队列中是一个二分变量,在GSMS中是一个有三个类别的有序变量。在我们的样本中,只有6个变量完全对应:“性别”、“肤色”、“学业失败”、“打架”、“离家出走”和“吸毒”。这样,从最初的11个预测因子中,模型只剩下8个变量。同时,我们认识到这是一个局限性,因为变量协调性更强的预测模型可以提高性能。IDEA-RS能够超越chance进行解析这一事实表明,尽管存在所有这些差异,但该模型仍具有鲁棒性。此外,在本研究和之前的模型验证中,我们缺乏必要的数据来研究风险变量的重要心理测量特性,如重新测试的可靠性和结构有效性,这在未来的研究中应该优先考虑。
研究设计也存在差异。Pelotas的研究是一项着眼于广泛健康问题的出生队列研究,而GSMS是一项基于社区的样本研究,招募了9岁、11岁和13岁的儿童,旨在对有精神健康问题风险的儿童进行抽样调查。预测因子的频率在不同的样本中是不同的,目前的研究没有探讨不同环境中预测因子相对重要性的潜在差异。尽管与Pelotas样本相比,了解GSMS中每个个体预测因子的样本特异性影响会很有趣,但通过多次比较可能会发现偶然而非实际样本差异产生的虚假结果。因此,我们的重点是从整体上分析模型的预测性能。此外,两个队列都使用了DSM诊断抑郁症的标准,但他们使用不同的结构化访谈得出了症状。GSMS队列使用青年精神病评估(YAPA),因此评估了前3个月发生的症状。而Pelotas队列使用了迷你国际神经精神病学访谈(Mini),该访谈考虑了前两周出现的症状。这可能解释了这些样本中MDD患病率的不同,并可能影响了GSMS中IDEA-RS的性能。最后,还值得注意的是,虽然IDEA-RS可以更好地预测抑郁症,但其特异性可能有限,因为它在较小程度上也可以预测其他心理健康问题,并提供跨诊断风险评分(Rocha等人,2021)。
5. Conclusion
IDEA-RS是在巴西开发的,旨在识别有抑郁风险的青少年,在四大洲的国家,特别是尼泊尔、新西兰、尼日利亚和英国,取得了超过chance的成绩。由于北美的外部验证尚未完成,我们使用了这个多变量模型来预测美国GSMS队列中哪些15岁青少年在19岁时诊断为重度抑郁症的风险较高。我们取得了0.63的性能,超过chance,改装模型和案例混合校正模型分别将其提高到0.67和0.69。在一系列异构环境中进行一致的验证是开发预测工具的关键一步,因为即使在成熟的计算工具中,它仍然具有挑战性和争议性(Chia, 2011;Wong et al, 2021)。例如,在心理健康领域提出的预测模型中,只有不到5%得到了外部验证(Salazar de Pablo等人,2021年)。同样,目前缺乏能够为跨文化情景提供早期发现和青年抑郁症预防策略信息的有效工具。虽然与开发IDEA-RS的原始样本相比,本文提供的GSMS样本在方法上存在一些差异,但该模型足够稳健,可以保持令人满意的性能,这可能类似于临床和研究使用的实际情况。此外,交叉信息者模型的表现与普通信息者模型一样好,这可以被解释为IDEA-RS有效性的进一步证据。















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









