






朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。朴素贝叶斯原理简单,也很容易实现,多用于文本分类,比如垃圾邮件过滤。
预备知识
先验概率与后验概率
先验概率:
通俗来说,对于某一个概率事件,我们都会有基于自己已有的知识,对于这个概率事件会分别以什么概率出现各种结果会有一个预先的估计,而这个估计并未考虑到任何相关因素。
举例来说,假如你考试没及格,老师要求大家拿卷子回家给爸妈签字,按照你已有的对爸妈脾气的了解,以及他们对自己成绩的要求,你在不考虑其它任何因素的情况下,自己已经有了一个对把卷子拿回家给他们签字的后果预估(先验):
被胖揍一顿:70%
被简单地数落一下:20%
被温情地鼓励:10%
后验概率:
后验概率就是在先验概率的基础上加了一层“考虑”:结合我们已有的知识,将与待检验事件(即我们正在估计概率的随机事件)相关的因素也考虑进去后,我们对随机事件的概率的预估。
先验概率和后验概率的区别:先验概率基于已有知识对随机事件进行概率预估,但不考虑任何相关因素(P©)。后验概率基于已有知识对随机事件进行概率预估,并考虑相关因素(P(c|x))。
朴素贝叶斯分类器
基于贝叶斯公式来估计后验概率P(c|x)主要困难在于类条件概率P(x|c)是所有属性上的联合概率,难以从有限的训练样本直接估计而得。
基于有限训练样本直接计算联合概率,在计算上将会遭遇组合爆炸问题;在数据上将会遭遇样本稀疏问题;属性越多,问题越严重。
为了避开这个障碍,朴素贝叶斯分类器采用了“属性条件独立性假设”“属性条件独立性假设”:对已知类别,假设所有属性相互独立。换言之,假设每个属性独立的对分类结果发生影响相互独立。
回答西瓜的例子就可以认为{色泽 根蒂 敲声 纹理 脐部 触感}这些属性对西瓜是好还是坏的结果所产生的影响相互独立。
基于条件独立性假设,对于多个属性的后验概率可以写成:
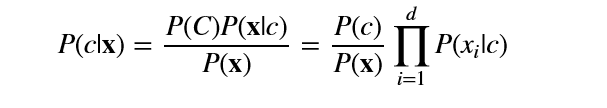
d为属性数目,xixi是x在第i个属性上取值。
对于所有的类别来说P(x)相同,基于极大似然的贝叶斯判定准则有朴素贝叶斯的表达式:
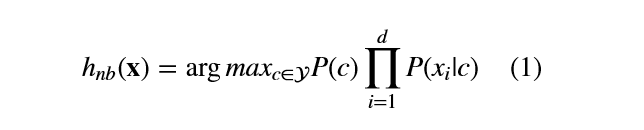
代码实现
import math
class NaiveBayes:
def __init__(self):
self.model = None
# 数学期望
@staticmethod
def mean(X):
"""计算均值
Param: X : list or np.ndarray
Return:
avg : float
"""
avg = 0.0
# ========= show me your code ==================
avg = np.mean(X)
# ========= show me your code ==================
return avg
def stdev(self, X):
"""计算标准差
Param: X : list or np.ndarray
Return:
res : float
"""
res = 0.0
res = math.sqrt(np.mean(np.square(X-self.mean(X))))
return res
def gaussian_probability(self, x, mean, stdev):
"""
根据均值和标注差计算x符号该高斯分布的概率
Parameters:
----------
x : 输入
mean : 均值
stdev : 标准差
Return:
res : float, x符合的概率值
"""
res = 0.0
exp = math.exp(-math.pow(x - mean, 2) / 2 * math.pow(stdev, 2))
res = (1 / (math.sqrt(2 * math.pi) * stdev)) * exp
return res
def summarize(self, train_data):
"""计算每个类目下对应数据的均值和标准差
Param: train_data : list
Return : [mean, stdev]
"""
summaries = [0.0, 0.0]
summaries = [(self.mean(i), self.stdev(i)) for i in zip(*train_data)]
return summaries
def fit(self, X, y):
labels = list(set(y))
data = {label: [] for label in labels}
for f, label in zip(X, y):
data[label].append(f)
self.model = {
label: self.summarize(value) for label, value in data.items()
}
return 'gaussianNB train done!'
# 计算概率
def calculate_probabilities(self, input_data):
"""计算数据在各个高斯分布下的概率
Paramter:
input_data : 输入数据
Return:
probabilities : {label : p}
"""
# summaries:{0.0: [(5.0, 0.37),(3.42, 0.40)], 1.0: [(5.8, 0.449),(2.7, 0.27)]}
# input_data:[1.1, 2.2]
probabilities = {}
# ========= show me your code ==================
for label, value in self.model.items():
probabilities[label] = 1
for i in range(len(value)):
mean, stdev = value[i]
probabilities[label] *= self.gaussian_probability(input_data[i], mean, stdev)
return probabilities
def predict(self, X_test):
# {0.0: 2.9680340789325763e-27, 1.0: 3.5749783019849535e-26}
label = sorted(self.calculate_probabilities(X_test).items(), key=lambda x: x[-1])[-1][0]
return label
# 计算得分
def score(self, X_test, y_test):
right = 0
for X, y in zip(X_test, y_test):
label = self.predict(X)
if label == y:
right += 1
return right / float(len(X_test))
参考文献:
https://www.cnblogs.com/cvlas/p/9372142.html
https://www.cnblogs.com/bluemapleman/p/9277180.html
https://github.com/datawhalechina/team-learning















 1321
1321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









