







9.机器学习-十大算法之一朴素贝叶斯(Naive Bayes)算法案例讲解
一·摘要
机器学习中的朴素贝叶斯(Naive Bayes)算法是一种基于贝叶斯定理和特征条件独立假设的分类算法。该算法通过计算给定特征下各个类别的概率,并选择概率最大的类别作为预测结果。朴素贝叶斯算法因其简单、高效且易于实现的特点,在文本分类、垃圾邮件过滤、情感分析等领域得到广泛应用。以下案例将详细讲解朴素贝叶斯算法的原理、应用及其实践过程中的注意事项。

二·个人简介
🏘️🏘️个人主页:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,CSDN内容合伙人,阿里云社区专家博主,新星计划导师,在职数据分析师。
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。

| 类型 | 专栏 |
|---|---|
| Python基础 | Python基础入门—详解版 |
| Python进阶 | Python基础入门—模块版 |
| Python高级 | Python网络爬虫从入门到精通🔥🔥🔥 |
| Web全栈开发 | Django基础入门 |
| Web全栈开发 | HTML与CSS基础入门 |
| Web全栈开发 | JavaScript基础入门 |
| Python数据分析 | Python数据分析项目🔥🔥 |
| 机器学习 | 机器学习算法🔥🔥 |
| 人工智能 | 人工智能 |
三·3种贝叶斯模型
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立(即朴素的假设)。根据特征的分布类型,朴素贝叶斯可以采用不同的分布模型来描述特征的概率分布。
高斯分布朴素贝叶斯(Gaussian Naive Bayes):
当特征值是连续的并且近似正态分布时,可以使用高斯分布(正态分布)来建模。在这种情况下,我们假设每个特征的值都服从一个高斯分布,其参数(均值和方差)由训练数据估计。高斯朴素贝叶斯适用于特征值近似正态分布的情况,例如身高、体重等。
多项式分布朴素贝叶斯(Multinomial Naive Bayes):
当特征值是离散的并且每个特征可以取多个值时,可以使用多项式分布来建模。例如,文本分类中,每个单词的出现与否可以看作一个特征,每个特征可以取0或1的值(出现或不出现)。多项式分布朴素贝叶斯适用于文本数据或计数数据,其中特征的分布可以用多项式概率质量函数来描述。
伯努利分布朴素贝叶斯(Bernoulli Naive Bayes):
当特征值是二元的(即每个特征只能取0或1的值)时,可以使用伯努利分布来建模。伯努利朴素贝叶斯适用于二元特征,例如垃圾邮件分类中,每个特征可能表示某个特定单词是否出现在邮件中。伯努利分布是二项分布的特例,其中试验次数为1。
导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# naive_bayes 朴素贝叶斯
# 一般数据 GaussianNB
# 文本数据 MultinomialNB,BernoulliNB
from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB
3.1 高斯分布朴素贝叶斯
高斯分布朴素贝叶斯(Gaussian Naive Bayes,GNB)是一种基于高斯分布(正态分布)的朴素贝叶斯分类器。它适用于特征值连续且近似正态分布的情况。
1. 高斯分布(正态分布):
高斯分布是一种连续概率分布,其概率密度函数呈对称的钟形曲线,也称为正态分布。它由两个参数定义:均值(μ)和标准差(σ)。数学上,一个随机变量X服从均值为μ、标准差为σ的正态分布可以表示为:
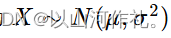
2. 朴素贝叶斯原理:
朴素贝叶斯分类器基于贝叶斯定理,它通过计算给定观测数据特征下,各个类别的概率来预测数据点的类别。贝叶斯定理可以表示为:
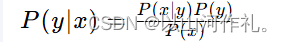
其中,( P(y|x) ) 是后验概率,即在给定特征x的条件下类别y的概率;( P(x|y) ) 是似然概率,即在类别y的条件下观测到特征x的概率;( P(y) ) 是类别y的先验概率;( P(x) ) 是特征x的边缘概率。
3. 朴素假设:
朴素贝叶斯的“朴素”之处在于它假设特征之间相互独立,即给定类别,一个特征的出现不影响其他特征的出现。这在现实世界中通常不成立,但在许多情况下,这种简化的假设仍然能够提供良好的分类性能。
4. 高斯分布朴素贝叶斯的应用:
在高斯分布朴素贝叶斯中,我们假设每个类别的数据特征都遵循高斯分布。因此,我们可以为每个类别学习一个高斯分布,即估计每个特征的均值和方差。在分类时,我们计算新数据点在每个类别的高斯分布下的概率,然后使用贝叶斯定理来确定数据点最可能属于的类别。
5. 计算过程:
- 训练阶段:对于每个类别,计算每个特征的均值和方差。
- 分类阶段:对于每个类别,使用高斯概率密度函数计算数据点的概率。然后,将这些概率与类别的先验概率相乘,并应用贝叶斯定理来计算后验概率。选择具有最高后验概率的类别作为预测类别。
6. 优点:
- 简单:模型简单,易于理解和实现。
- 快速:计算效率高,尤其是在特征维度很高时。
- 可扩展:可以很好地处理多分类问题。
7. 缺点:
- 特征独立性假设:特征独立性假设在现实世界中往往不成立,这可能会影响模型的性能。
- 数据分布假设:假设所有特征都服从高斯分布,这在某些情况下可能不适用。
导入自带的鸢尾花数据
from sklearn.datasets import load_iris
data,target = load_iris(return_X_y=True)
data.shape
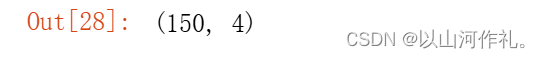
# 取两列数据方便画图
data2 = data[:,:2].copy()
使用高斯分布贝叶斯模型
gs_nb = GaussianNB()
gs_nb.fit(data2,target)
# 预测数据
x = np.linspace(data2[:,0].min(),data2[:,0].max(),1000)
y = np.linspace(data2[:,1].min(),data2[:,1].max(),1000)
X,Y = np.meshgrid(x,y)
XY = np.c_[X.ravel(),Y.ravel()]
y_pred = gs_nb.predict(XY)
画边界图
data2.shape
plt.pcolormesh(X,Y,y_pred.reshape(1000,1000))
plt.scatter(data2[:,0],data2[:,1],c =target,cmap='rainbow')
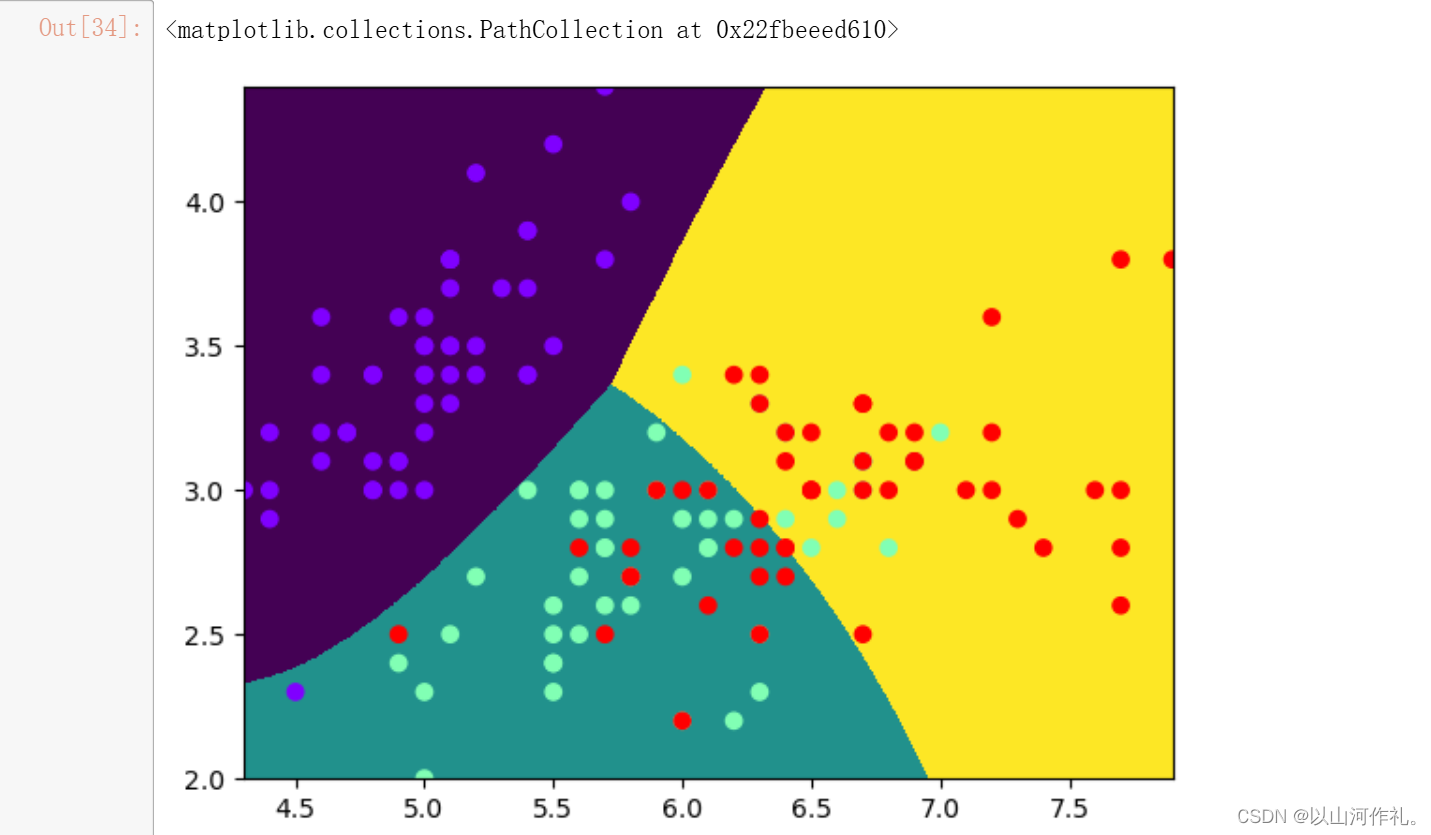
gs_nb.score(data2,target)

3.2 多项式分布朴素贝叶斯
多项式分布朴素贝叶斯(Multinomial Naive Bayes,MNB)是朴素贝叶斯分类器的一种变体,适用于处理离散数据,特别是多项式分布的数据。这种模型在文本分类任务中非常流行,因为文本数据可以自然地表示为单词或字符的出现次数(即词袋模型)。
1. 多项式分布:
多项式分布是一种离散概率分布,用于描述n个独立的伯努利试验中成功的次数,其中每次试验成功的概率是相同的。在文本处理中,每个单词的出现可以视为一个“成功”,而多项式分布可以用来描述文档中单词的分布。
2. 朴素贝叶斯原理:
与高斯朴素贝叶斯一样,多项式朴素贝叶斯也基于贝叶斯定理,通过计算后验概率来进行分类。不同之处在于,它假设数据的特征是多项式分布的。
3. 朴素假设:
MNB也采用朴素贝叶斯的朴素假设,即特征之间相互独立。在文本分类中,这意味着文档中一个单词的出现不影响另一个单词的出现。
4. 参数估计:
在多项式朴素贝叶斯中,每个类别的每个特征(如文本中的单词)都有一个参数,通常表示为该特征在该类别中出现的次数或频率。这些参数可以通过最大似然估计或添加拉普拉斯平滑来估计。
5. 分类决策:
在分类时,MNB计算新文档在每个类别下出现的概率,并选择具有最高后验概率的类别作为文档的分类。
6. 拉普拉斯平滑:
由于文本数据的稀疏性,很多单词可能在训练数据中从未出现过。这会导致概率估计为零,从而影响模型的性能。为了解决这个问题,MNB通常使用拉普拉斯平滑(也称为加一平滑),即在每个类别的每个特征的计数中加上一个小常数(通常是1),以避免零概率。
7. 优点:
- 适合文本数据:由于其对离散数据的处理能力,MNB非常适合文本分类任务。
- 计算效率:模型训练和分类速度快,适合处理大规模数据集。
- 易于实现:朴素贝叶斯模型相对简单,容易实现和理解。
8. 缺点:
- 特征独立性假设:与所有朴素贝叶斯模型一样,特征独立性假设可能导致性能受限。
- 忽略词序:MNB作为词袋模型,忽略了文本中单词的顺序信息,这可能影响分类的准确性。
延续上面,使用鸢尾花数据
mu_nb = MultinomialNB()
mu_nb.fit(data2,target)
y_pred = mu_nb.predict(XY)
plt.pcolormesh(X,Y,y_pred.reshape(1000,1000))
plt.scatter(data2[:,0],data2[:,1],c =target,cmap='rainbow')
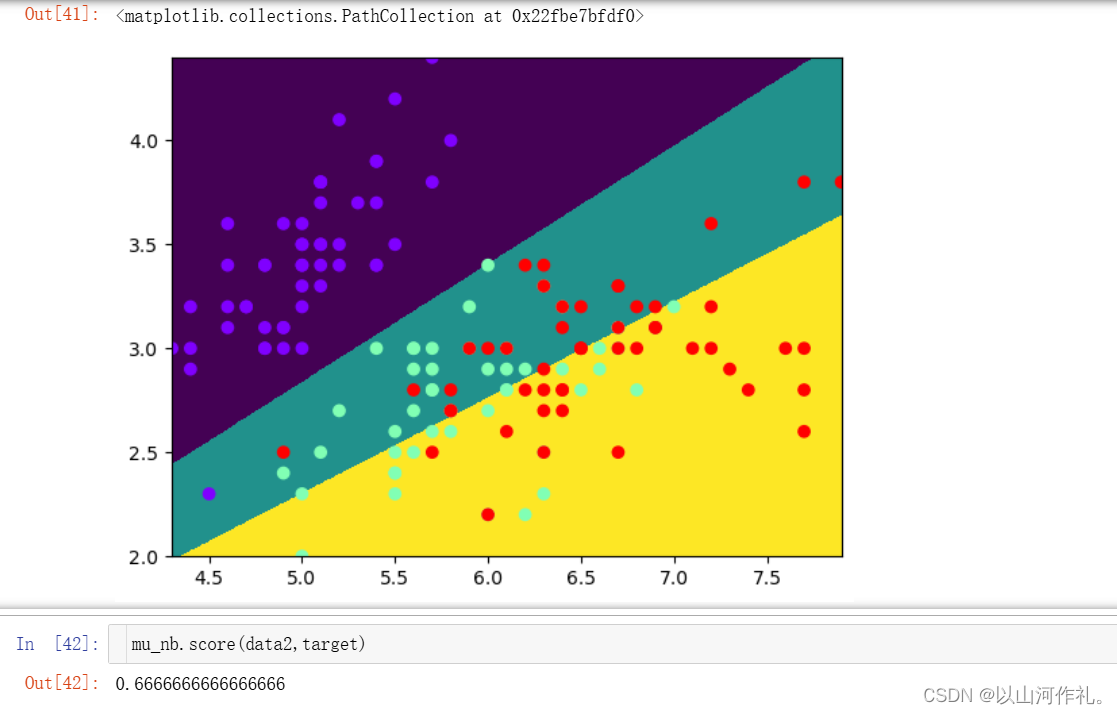
3.3 伯努利分布朴素贝叶斯
伯努利分布朴素贝叶斯(Bernoulli Naive Bayes,BNB)是朴素贝叶斯分类器的一个特殊版本,它适用于每个特征都是独立同分布的二元特征的情况。这种模型在特征表现为二元(即每个特征只能取0或1值,表示某个事件是否发生)的数据集上特别有用。
1. 伯努利分布:
伯努利分布是一种离散概率分布,用于描述单个独立的伯努利试验(即只有两种可能结果的随机试验,通常表示为成功或失败)的结果。在这种情况下,随机变量X可以取值为0或1,其概率由参数p控制,其中p是成功的概率。
2. 朴素贝叶斯原理:
和高斯朴素贝叶斯以及多项式朴素贝叶斯一样,伯努利朴素贝叶斯也是基于贝叶斯定理,通过计算后验概率来进行分类。
3. 朴素假设:
BNB同样采用朴素贝叶斯的朴素假设,即假设所有特征都是相互独立的。这意味着一个特征的值不影响其他特征的值。
4. 参数估计:
在BNB中,每个类别的每个特征都有一个参数,表示为该特征为1(即事件发生)的概率。这些参数可以从训练数据中通过最大似然估计来获得。
5. 分类决策:
在分类时,BNB计算新实例在每个类别下的条件概率,然后使用贝叶斯定理来确定实例最可能属于的类别。
6. 拉普拉斯平滑:
由于二元特征可能在某些类别的训练数据中从未出现,这会导致概率估计为零。为了避免这种情况,BNB同样可以使用拉普拉斯平滑来调整概率估计。
7. 优点:
- 简单高效:模型简单,易于实现,并且计算效率高。
- 适用于二元特征:特别适合处理二元特征,如文本数据中的词项出现与否。
8. 缺点:
- 特征独立性假设:由于朴素贝叶斯的朴素假设,模型可能无法捕捉特征之间的复杂关系。
- 忽略特征权重:所有特征被视为同等重要,而实际中某些特征可能比其他特征更重要。
be_nb = BernoulliNB()
be_nb.fit(data2,target)
y_pred = be_nb.predict(XY)
plt.pcolormesh(X,Y,y_pred.reshape(1000,1000))
plt.scatter(data2[:,0],data2[:,1],c =target,cmap='rainbow')
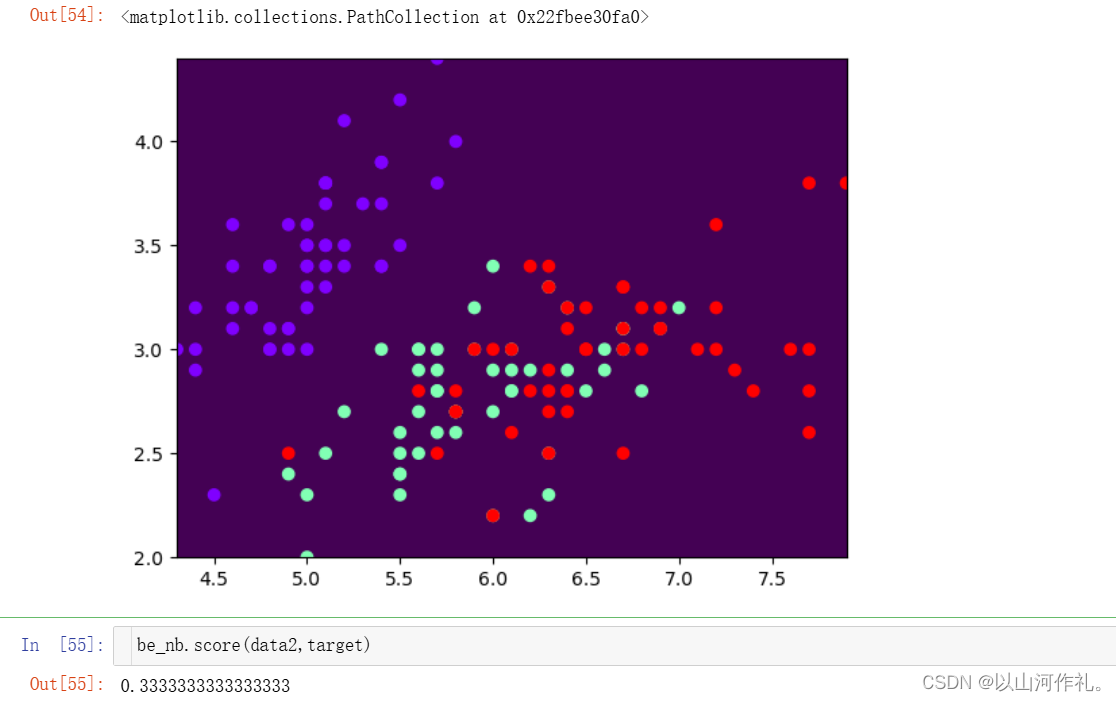
四·文本分类实战
对短信进行二分类,数据为SMSSpamCollection
sms = pd.read_table('../data/SMSSpamCollection',header=None)
sms

sms[0].value_counts()

target = sms[0]
data = sms[1]
target.shape,data.shape
导入 sklearn.feature_extraction.text.TfidfVectorizer 用于转换字符串
from sklearn.feature_extraction.text import TfidfVectorizer
TfidfVectorizer 特征词向量化
from sklearn.feature_extraction.text import TfidfVectorizer
# TfidfVectorizer 特征词向量化
# 快速对data数据进行处理
tf = TfidfVectorizer()
tf.fit(data)
tf.transform(data)
#<5572x8713 sparse matrix of type '<class 'numpy.float64'>'
# with 74169 stored elements in Compressed Sparse Row format>
# sparse matrix 稀疏矩阵
tf.fit(data) :训练
tf.transform(data)
参数必须是字符串的一维数组(比如列表或者Series)
返回的是一个稀疏矩阵类型的对象,行数为样本数,列数为所有出现的单词统计个数。
toarray()
得到数组
tf_data =tf.transform(data).toarray()
tf_data

# tf_data.sum()
tf_data.shape
高斯分布贝叶斯
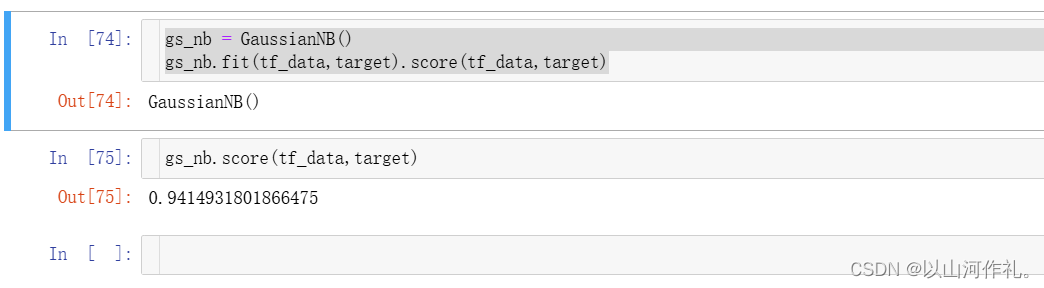
多项式分布贝叶斯

伯努利分布贝叶斯

预测数据,使用tf.transform([‘xx’])进行转换生成测试数据
> # 提供几条短信 msg = [
> "hello world how are you",
> "Free lunch, pleace call 08002986030 £5 9am-11pm as a £1000 or £5000 prize",
> "qianfeng encoding utf8",
> "Please call our on 0808 145 4742 9am-11pm as a £1000 or £5000 prize!" ]
tf_data2 = tf.transform(msg).toarray()
tf_data2.shape

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











