







 本文介绍了如何使用Python爬虫获取Airbnb的房屋信息,包括通过浏览器抓包识别API请求参数,处理中文编码问题,编写爬虫代码以及将获取的数据保存到MySQL数据库中。
本文介绍了如何使用Python爬虫获取Airbnb的房屋信息,包括通过浏览器抓包识别API请求参数,处理中文编码问题,编写爬虫代码以及将获取的数据保存到MySQL数据库中。
1. 必要的库
import requests
import re
import json
import urllib
import pymysql # 为了连接mysql
from time import sleep
2. 前期准备
2.1 通过浏览器抓包
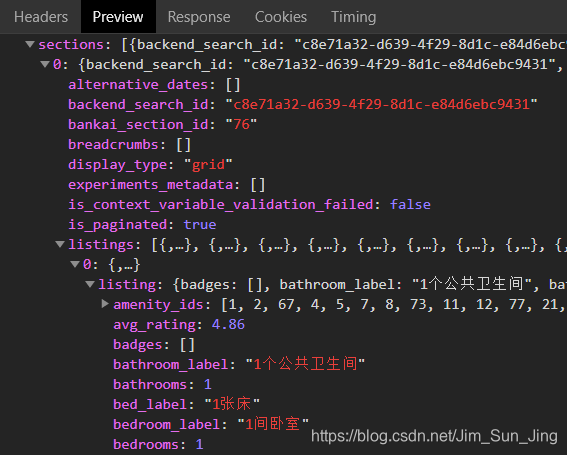
房屋信息是使用airbnb的api获取的json传输,网址的截取部分如下:
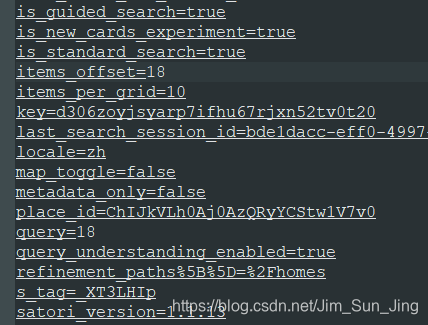
翻页后对比前后两页的网址可分辨出items_offset和query为主要的产生数据请求的数据。
于是可以用下面的代码向这个api网址发出请求获得json数据:
base_url = '''https://www.airbnb.cn/api/v2/...(省略)
&items_offset={}&items_per_grid=10&...(省略)&
query={}&...(省略)'''
2.1 中文编码
其中,城市的字段不能直接传入中文,需要使用urllib库进行转换。
def quote_word(word):
# 转换为URL所需编码
return urllib.parse.quote(word)
>>> quote_word('深圳')
'%E6%B7%B1%E5%9C%B3'
3. 编写爬虫
传入一个搜索关键字,返回一个装满了房屋信息dict的列表。
def get_json(key_word, pages = 5, base = base_url, header = header0):
'''
key_work:查询的数据
pages: 需要查询的页数
base: api网址
'''
houses = []
for i in range(pages):
sleep(1.5)
print(f'page {i}')
offset = i*10
url = base.format(offset, quote_word(key_word))
req = requests.get(url, headers = header)
dic = json.loads(req.content.decode('utf-8'))
house = dic 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









