






在做文本分类的项目时,有可能出现用户可以提供大量的无标注数据,但无法自行归类标签,因此就需要用到无监督文本聚类的方法,对文本做一个初步的分类,再提供给用户校验和定义标签。本文章将讲解基于K-Means算法实现文本聚类:
加载所需的库:
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import numpy as np
from sklearn import metrics然后是读取数据集:
## 调用已保存过的cut words, 以免每次测试模型都要重新分词 ##
Cut_df = pd.read_excel(r"C:\Users\xxx\Desktop\data\classify\train-clear.xlsx")
Cut_df = Cut_df.dropna()
sentences = Cut_df.CutWords.values.tolist()
## TF-IDF 特征提取
vec1 = TfidfVectorizer(analyzer='word',max_features=30000) ## 字典的最大词量 ##
feature = vec1.fit_transform(sentences)
tfidf_weight = feature.toarray()先通过轮廓系数评估K-Means聚类的n_clusters以及得分,这里取2-10个簇来计算:
## 通过轮廓系数评估聚类的n_clusters以及得分
def get_parameter_k_means(data):
test_score = []
n_clusters_end = 10
n_clusters_start = 2
while n_clusters_start <= n_clusters_end:
km = KMeans(n_clusters=n_clusters_start)
km.fit(data)
clusters = km.labels_.tolist()
## 轮廓系数计算聚类分数
score = metrics.silhouette_score(X=feature,labels=clusters)
num = sorted([(np.sum([1 for a in clusters if a==i]),i) for i in set(clusters)])[-1]
test_score.append([n_clusters_start,score,num[0],num[1]])
n_clusters_start += 1
return pd.DataFrame(test_score,columns=['聚类数目','分数','最大特征个数','聚类名称']).sort_values(by ='分数',ascending =False)
Result = get_parameter_k_means(tfidf_weight) #得到最佳参数
Result.to_excel("C:/Users/xxx/Desktop/Cluster.xlsx",index=False)输出结果:
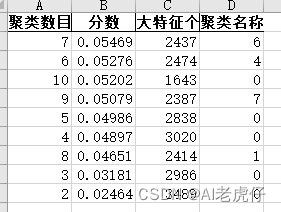
因此确定簇的数量=7,则开始K-Means聚类,输出聚类结果:
## K-Means聚类,指定分成n个类
kmeans = KMeans(n_clusters=7)
kmeans.fit(tfidf_weight)
## 打印出各个族的中心点
# print(kmeans.cluster_centers_)
# for index, label in enumerate(kmeans.labels_, 1):
# print("idx: {}, label: {}".format(index, label))
# inertia:样本距其最近的聚类中心的平方距离之和,用来评判分类的准确度
# k-means的超参数n_clusters可以通过该值来评估
print("inertia: {}".format(kmeans.inertia_))
clusters = kmeans.labels_.tolist()
Cut_df['ClusterLabel'] = clusters
Cut_df.to_excel("C:/Users/xxx/Desktop/ClusterResult.xlsx",index=False)
# 通过轮廓系数计算聚类分数,越接近1越好(分离边界越清晰),0表示在边界之间,-1表示聚类效果最差
score = metrics.silhouette_score(X=feature,labels=clusters)
print('聚类分数:',score)若需要可视化查看聚类特征情况,可以使用T-SNE算法,对权重进行降维,准确率比PCA算法高,但耗时更长:
tsne = TSNE(n_components=2) # n_components:嵌入式空间的维度
decomposition_data = tsne.fit_transform(tfidf_weight)
x = []
y = []
for i in decomposition_data:
x.append(i[0])
y.append(i[1])
fig = plt.figure(figsize=(10, 10))
ax = plt.axes()
replace_dict = {0:'black',1:'red',2:'peru',3:'orange',4:'yellow',5:'lime',6:'cyan',7:'pink',8:'navy',9:'fuchsia',10:'olive',11:'lightsalmon',12:'powderblue',13:'yellowgreen',14:'deeppink',15:'thistle',16:'silver',17:'darkcyan'}
colors =[replace_dict[i] if i in replace_dict else i for i in clusters]
plt.scatter(x, y, c=colors, marker="*")
plt.xticks(())
plt.yticks(())
# plt.show()
plt.savefig('C:/Users/xxx/desktop/Cluster.png')















 3291
3291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









