







机器学习笔记(吴恩达老师)
第一章 引言
引言
一、监督学习
例如,前阵子,一个学生从波特兰俄勒冈州的研究所收集了一些房价的数据。你把这些数据画出来,看起来是这个样子:横轴表示房子的面积,单位是平方英尺,纵轴表示房价,单位是千美元。那基于这组数据,假如你有一个朋友,他有一套750平方英尺房子,现在他希望把房子卖掉,他想知道这房子能卖多少钱。
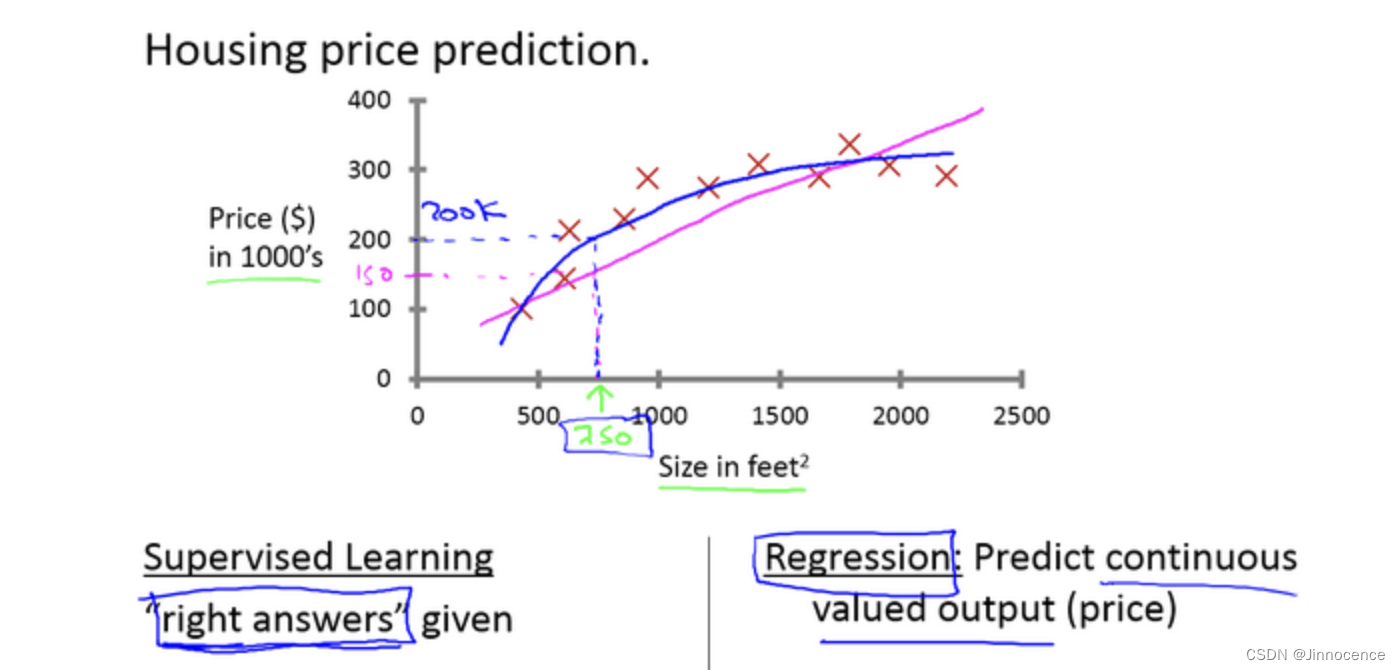
监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格,即它们实际的售价然后运用学习算法,算出更多的正确答案。比如你朋友那个新房子的价格。用术语来讲,这叫做回归问题。我们试着推测出一个连续值的结果,即房子的价格。
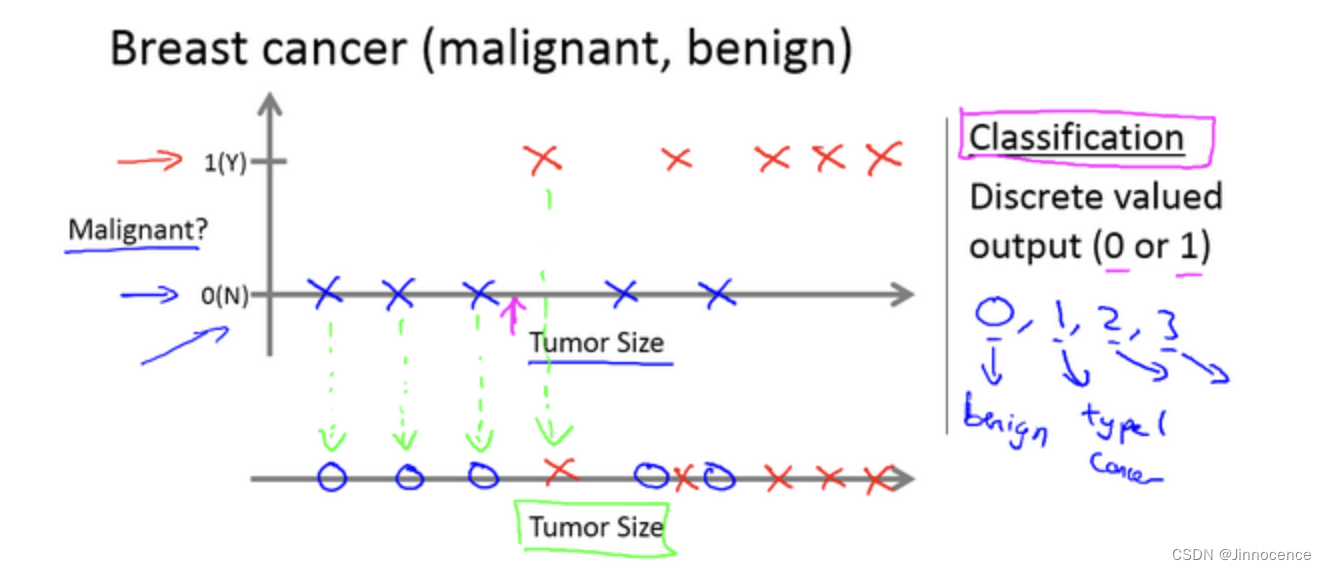
再举另外一个监督学习的例子。假设说你想通过查看病历来推测乳腺癌良性与否,假如有人检测出乳腺肿瘤,恶性肿瘤有害并且十分危险,而良性的肿瘤危害就没那么大,所以人们显然会很在意这个问题。
这个数据集中,横轴表示肿瘤的大小,纵轴上,我标出1和0表示是或者不是恶性肿瘤。我们之前见过的肿瘤,如果是恶性则记为1,不是恶性,或者说良性记为0。
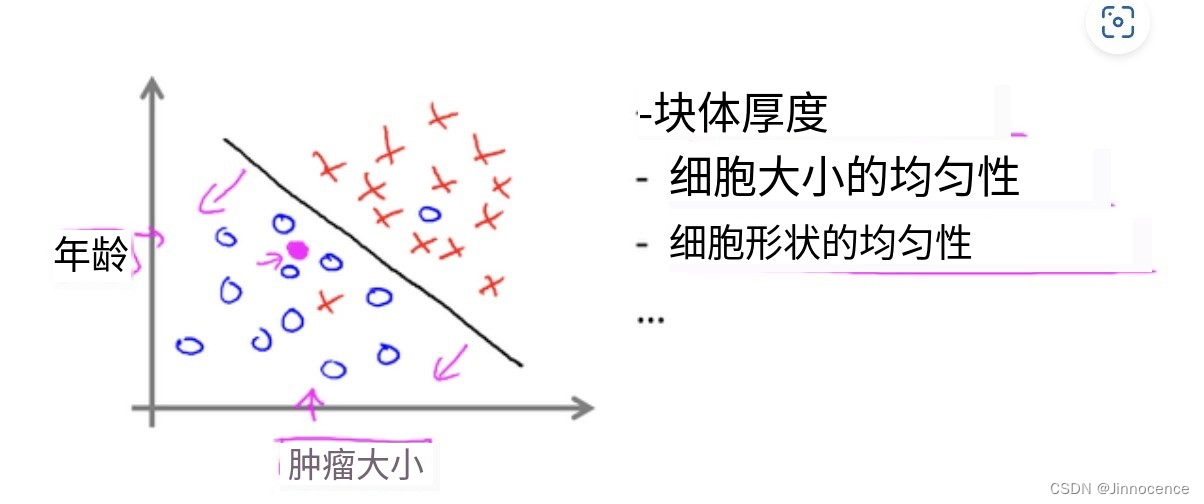
下图中,列举了总共五种不同的特征,坐标轴上的两种和右边的三种,但是在一些学习问题中,你希望不只用3种或5种特征。怎么处理无限多个特征,甚至怎么存储这些特征都存在问题,电脑的内存肯定不够用。
需要用到一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机无限处理多个特征。
二、无监督学习
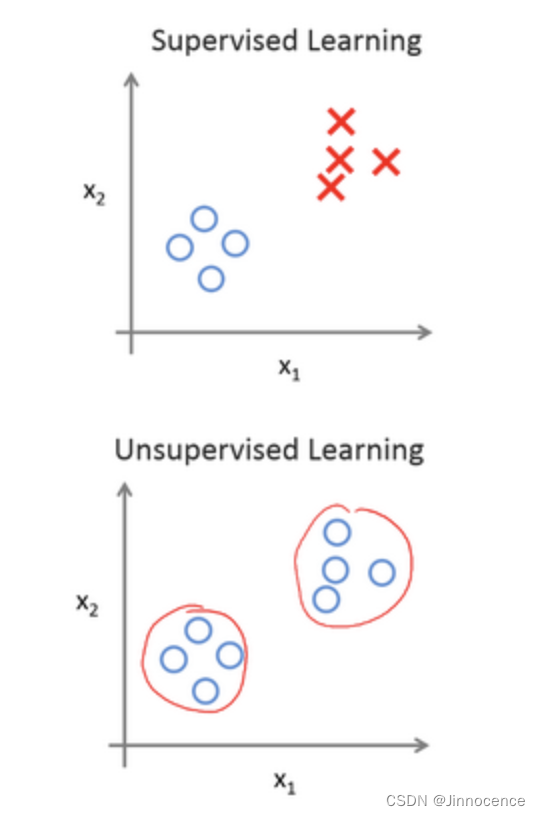
对于监督学习里的每条数据,我们已经清楚地知道,训练集对应的正确答案,是良性或恶性了。
在无监督学习中,我们已知的数据。看上去有点不一样,不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。
针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。
例如,给小孩子一堆水果,比如有苹果、橘子、梨三种,小孩子一开始不知道这些水果是什么,让小孩子对这堆水果进行分类。等小孩子分类完后,给他一个苹果,他应该把他这个苹果放到刚刚分好的苹果堆中去。
建议学习Octave的知识,事实上,许多人在大硅谷的公司里做的其实就是,
使用一种工具像Octave来做第一步的学习算法的原型搭建,只有在你已经让它工作后,你才移植它到C++或Java或别的语言。
事实证明,这样做通常可以让你的算法运行得比直接用C++实现更快。
三、总结
我们介绍了无监督学习,它是学习策略,交给算法大量的数据,并让算法为我们从数据中找出某种结构。
复习题:
1.垃圾邮件问题
如果你有标记好的数据,区别好是垃圾还是非垃圾邮件,我们把这个当作监督学习问题。
2.新闻事件分类的例子
可以用一个聚类算法来聚类这些文章到一起,所以是无监督学习。
3.细分市场的例子
你可以当作无监督学习问题,因为我只是拿到算法数据,再让算法去自动地发现细分市场。
4.糖尿病的例子
这个其实就像是我们的乳腺癌,上个视频里的。只是替换了好、坏肿瘤,良性、恶性肿瘤,我们改用糖尿病或没病。所以我们把这个当作监督学习,我们能够解决它,作为一个监督学习问题,就像我们在乳腺癌数据中做的一样。
以上就是监督学习和无监督学习的内容,接下来,我们将深入探究特定的学习算法,开始介绍这些算法是如何工作的,和我们还有你如何来实现它们。















 326
326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









