







纸上得来终觉浅
1.这样一个问题,作为一个开发人员需要掌握数据库的哪些东西? 在开发中涉及到数据库,基本上只用到了sql语句,如何写sql以及对其进行优化就比较重要,那些mysql的厚本书籍针对的是DBA,我们只需要学习其中的sql就可以了。
2.既然会写sql是目标,那么怎么才能写好sql.学习下面几点:
1)Mysql的执行顺序,这个是写sql的核心,之前遇到的一些错误就是因为对其不了解;
2)如何进行多表查询,优化,这个是很重要的部分;
3)sql语句的函数,sql提供的函数方便了很多操作;
3.这篇对Mysql语句执行顺序的学习做了总结:
1)Mysql语法顺序,即当sql中存在下面的关键字时,它们要保持这样的顺序:
select[distinct]
from
join(如left join)
on
where
group by
having
union
order by
limit2)Mysql执行顺序,即在执行时sql按照下面的顺序进行执行:
from
on
join
where
group by
having
select
distinct
union
order by建立如下表格orders:
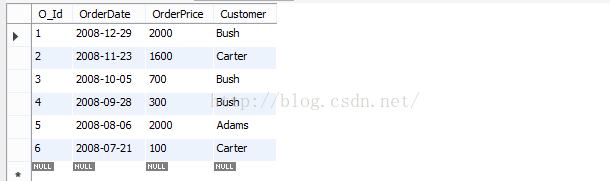
注:下面所有语句符合语法顺序(也不可能不符合,因为会报错^_^),只分析其执行顺序:(join和on属于多表查询,放在最后展示)
语句一:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









