







开发环境:Anaconda
项目地址:Titanic : A Complete Tutorial For Beginners | Kaggle
项目概述:主要还是进行泰坦尼克的数据处理分析,但是相比之前的两个项目还是要更容易掌握,更适合小白入手学习。
在项目开始之前,先搞清楚两个问题。
1、什么是分类?
当目标是分类的(有两个或更多类别)时,我们使用分类技术。在泰坦尼克号数据集里,目标是 “存活” 变量,有类别 0 和类别 1。类别 0 表示 “未存活”,类别 1 表示 “存活”。
2、什么是逻辑回归?
逻辑回归用于分类问题。逻辑回归因其方法核心所使用的函数而得名,即逻辑函数。逻辑函数也被称为 Sigmoid 函数。它是一个 S 形曲线。
第一部分 数据准备
# 数据分析
import numpy as np
import pandas as pd
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
# 忽略告警
import warnings
warnings.filterwarnings('ignore')
# 设置绘图风格为ggplot
plt.style.use('ggplot')
# 导入数据
train_df = pd.read_csv(r'E:/train.csv')
test_df = pd.read_csv(r'E:/test.csv')
# 注释:
# PassengerId:乘客编号
# Survived:生存状态(0代表未存活,1代表存活)
# Pclass:舱位等级
# Name:乘客姓名
# Sex:性别
# Age:年龄
# SibSp:同舱兄弟姐妹或配偶的数量
# Parch:同行父母或子女的数量
# Ticket:票号
# Fare:票价
# Cabin:舱位
# Embarked:登船港口# 复制一下这两个数据
train = train_df.copy()
test= test_df.copy()# 打印基本信息
print(train.info())
print("-"*40)
train.describe()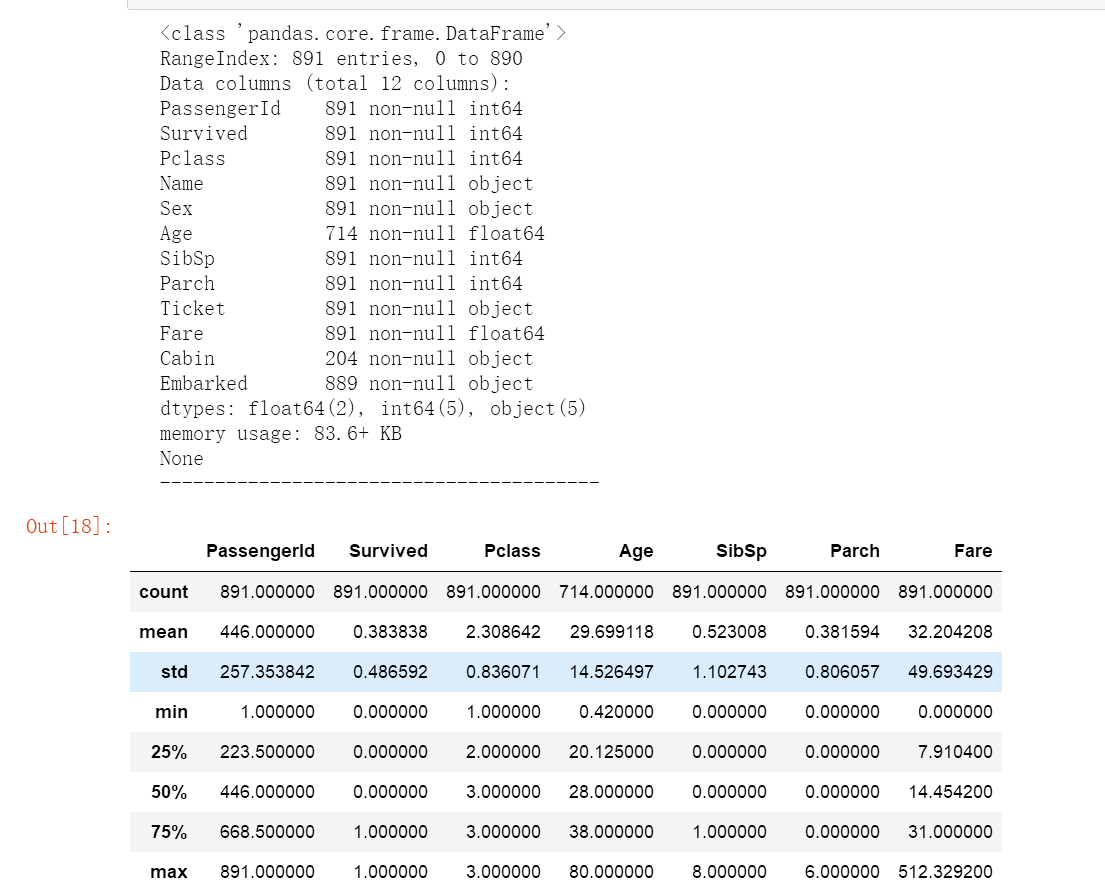
print(test.info())
print("-"*40)
test.describe()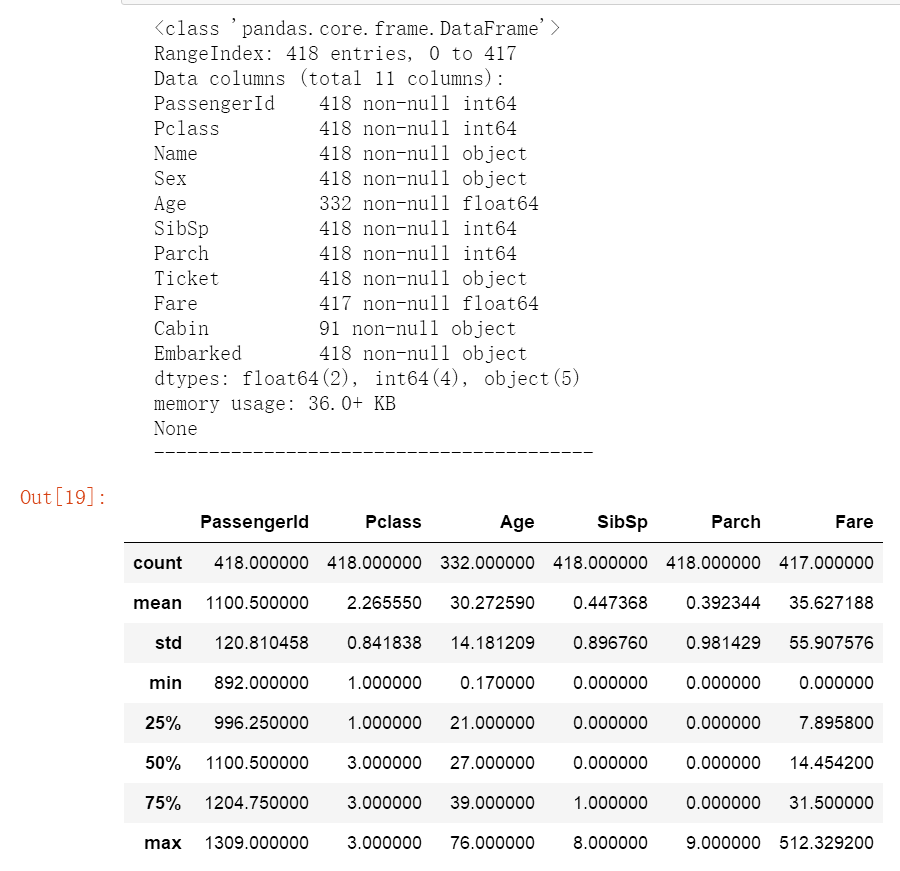
# 检查空值,可以看到训练数据中Age和Cabin缺失值较多,登船口缺失较少
print(train.isnull().sum()) 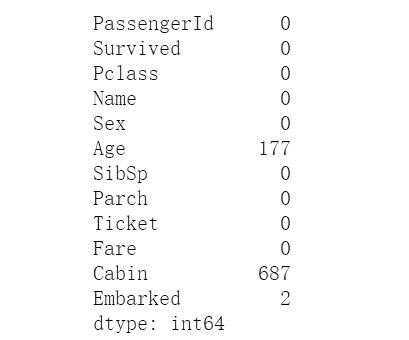
# 可以看到测试数据中年龄、票价和舱位缺失值较多
print(test.isnull().sum()) 
# 打印一下列名索引
print(train.columns) 
print(test.columns) 
# 移除一些不显著的变量
train.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
test.drop(columns= ['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace= True)
# 空值采用均值、众数和中位数来填充
# 查看年龄中位数
train['Age'].median()![]()
# 找出 train 数据框中 Embarked 列里出现频率最高的值(也就是众数),并取出该众数。
train['Embarked'].mode()[0]
# 处理训练数据,分别用中位数和众数填充
train["Age"].fillna(train["Age"].median(),inplace= True)
train["Embarked"].fillna(test["Embarked"].mode()[0],inplace = True)# 查看训练数据的空值情况
train.isnull().sum()
test["Age"].median() ![]()
test["Fare"].median() ![]()
# 处理测试数据用中位数填充
test['Age'].fillna(test['Age'].median(), inplace=True)
test['Fare'].fillna(test['Fare'].median(), inplace=True)
test.isnull().sum()
# 将空值处理完之后,统计一下Survived值
train['Survived'].value_counts() 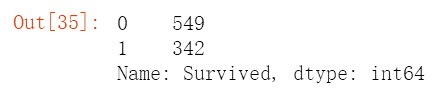
train['Pclass'].value_counts() 
train['Sex'].value_counts() 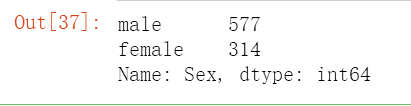
train['SibSp'].value_counts() 
train['Parch'].value_counts() 
train['Embarked'].value_counts() 
# 统计一下测试数据值的情况
test['Pclass'].value_counts() 
test['Sex'].value_counts() 
test['SibSp'].value_counts()
test['Parch'].value_counts() 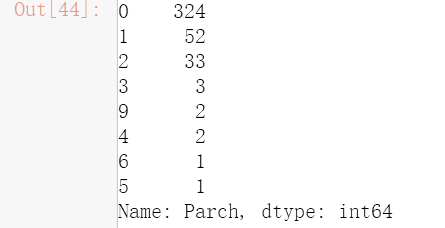
test['Embarked'].value_counts() 
第二部分 可视化分析
# 观察训练存活数据
plt.figure(figsize=(8,6))
sns.countplot(x='Survived', data= train)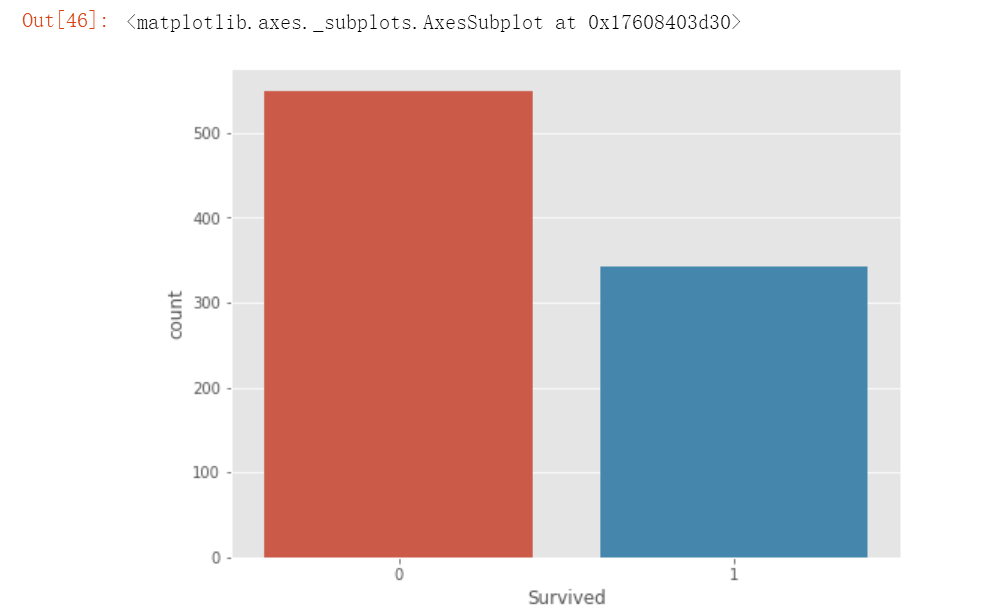
plt.figure(figsize=(8,6))
sns.countplot(x='Sex', data= train) 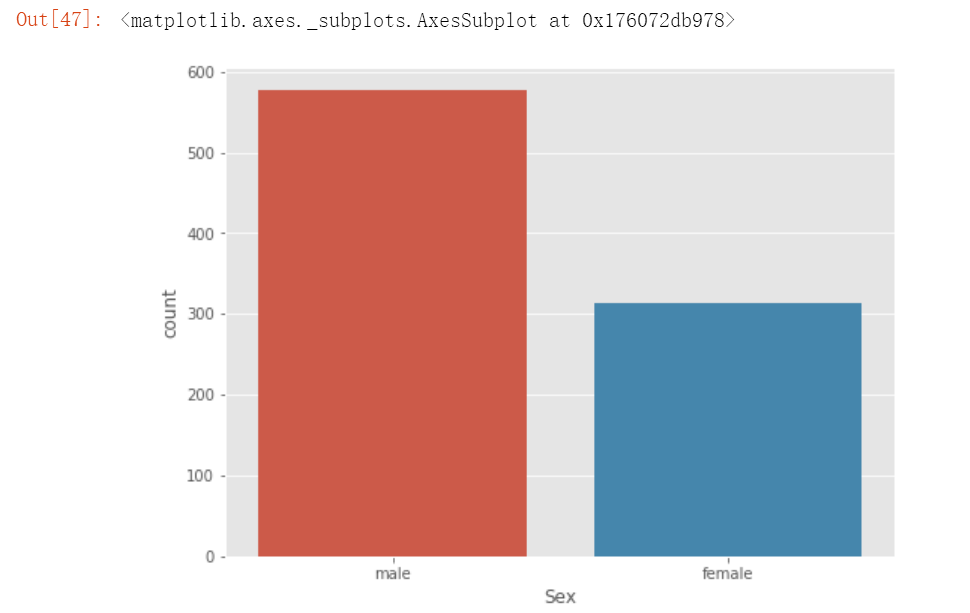
# 观察性别对存活的影响
plt.figure(figsize=(8,6))
sns.countplot(x='Survived', hue='Sex', data= train) 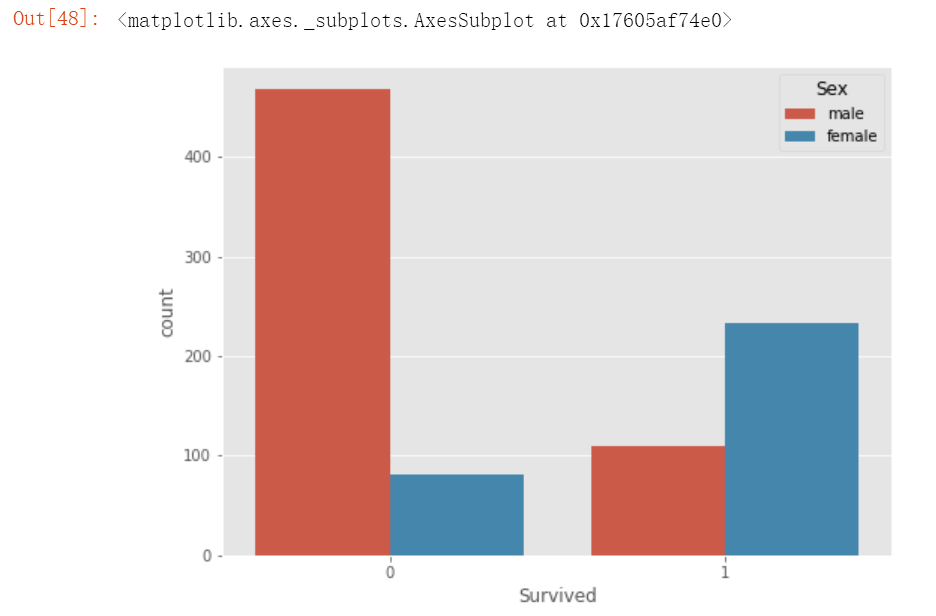
# 观察船舱级别对存活的影响
plt.figure(figsize=(8,6))
sns.countplot(x='Survived', hue='Pclass', data= train) 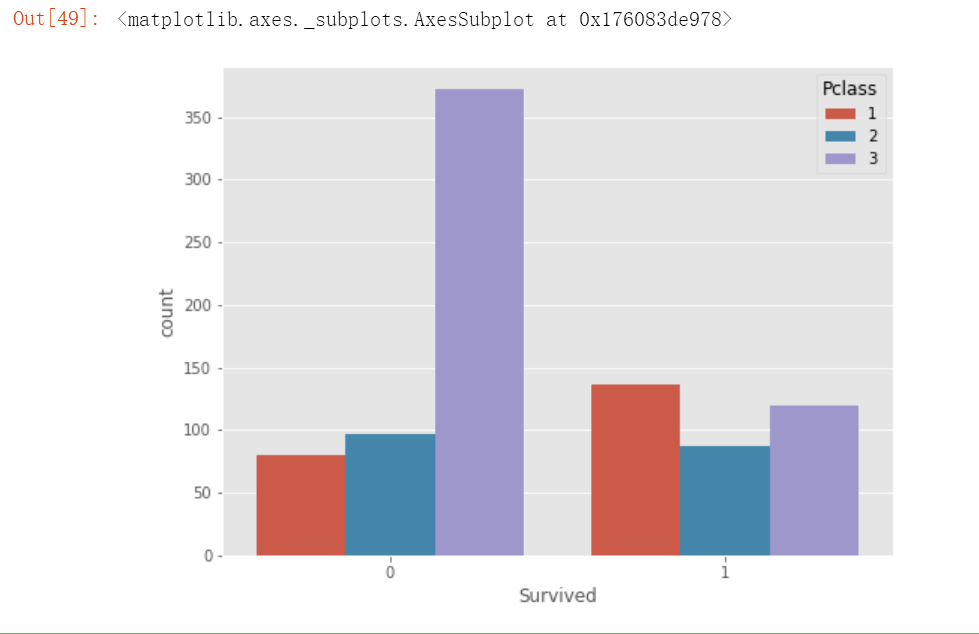
# 用箱线图观察男性和女性存活情况
plt.figure(figsize=(8,6))
sns.boxplot(x='Survived', y= 'Age', hue='Sex', data= train) 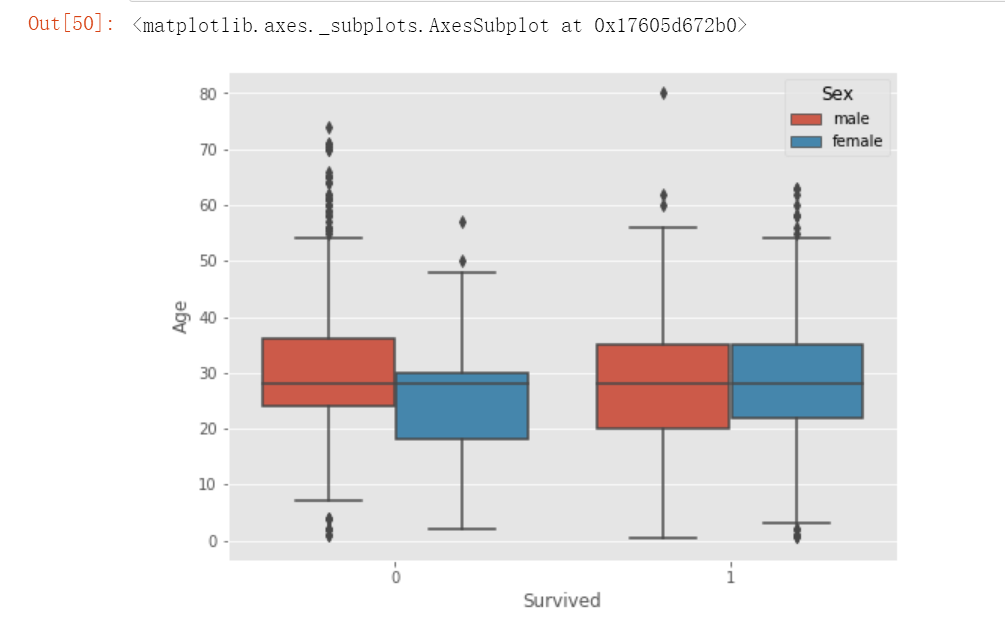
# 观察舱位级别和票价的关系
plt.figure(figsize=(8,6))
sns.boxplot(x='Pclass', y= 'Fare', data= train) 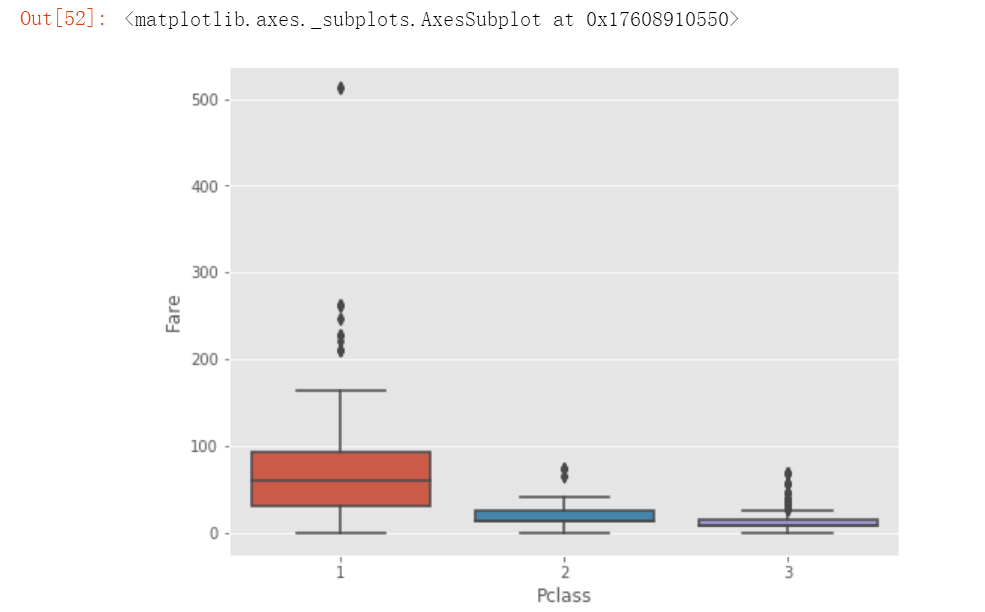
plt.figure(figsize=(8,6))
sns.countplot(x='Sex', data= test) 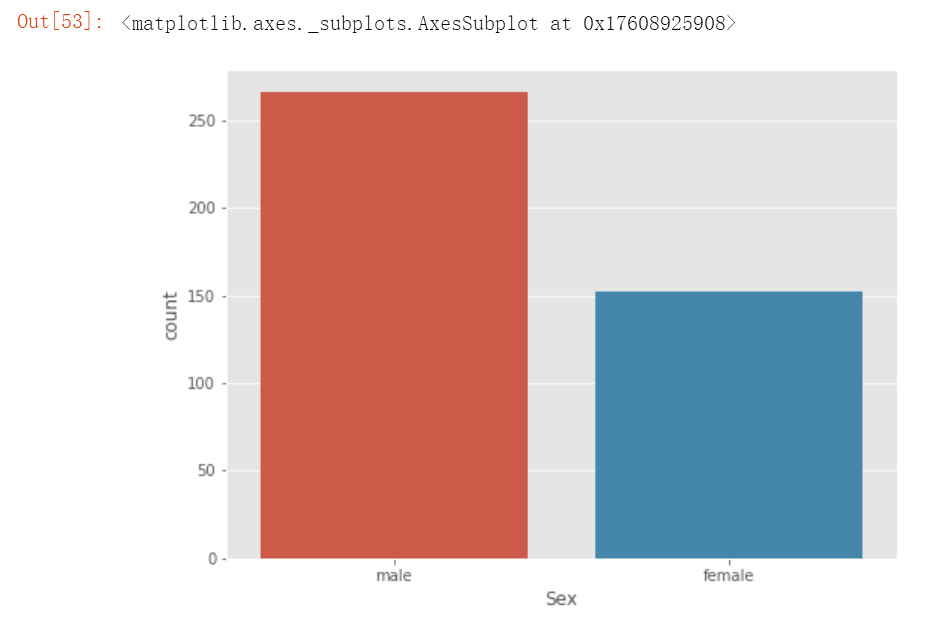
plt.figure(figsize=(8,6))
sns.boxplot(x='Pclass', y= 'Fare', data= test) 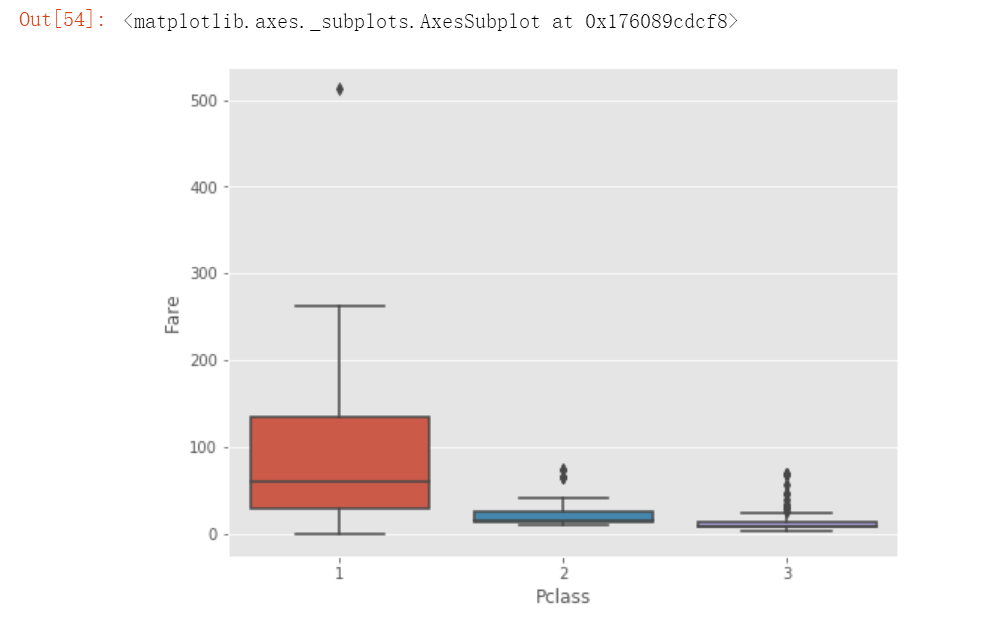
train.plot(kind='box', figsize= (10,8)) 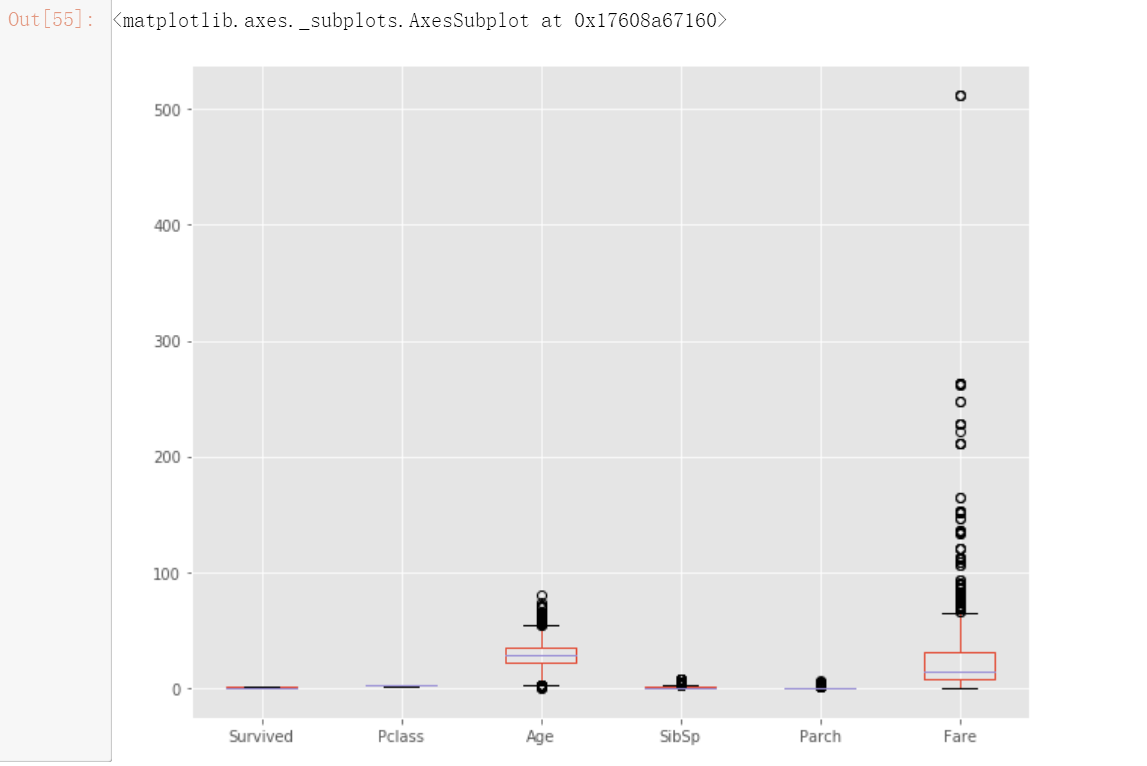
"""
年龄、兄弟姐妹配偶数、父母子女数和票价变量中存在离群值。我正在使用 clip () 函数来去除离群值。
父母子女数变量被移除,因为超过 75% 的值为 0。
代码注释:
clip方法说明:
clip() 是 pandas 的一个方法,用于对数据进行裁剪。
lower=train[cols].quantile(0.15):设置裁剪的下限为每列数据的 15% 分位数,即小于该分位数的值会被替换为该分位数的值。
upper=train[cols].quantile(0.85):设置裁剪的上限为每列数据的 85% 分位数,即大于该分位数的值会被替换为该分位数的值。
axis=1:表示按行进行操作,确保对每一行的数据进行裁剪。
"""
cols= ['Age', 'SibSp', 'Parch', 'Fare']
train[cols]= train[cols].clip(lower= train[cols].quantile(0.15), upper= train[cols].quantile(0.85), axis=1)
train.drop(columns=['Parch'], axis=1, inplace=True)
# 处理完异常值,再此用箱型图来观察训练数据
train.plot(kind='box', figsize= (10,8))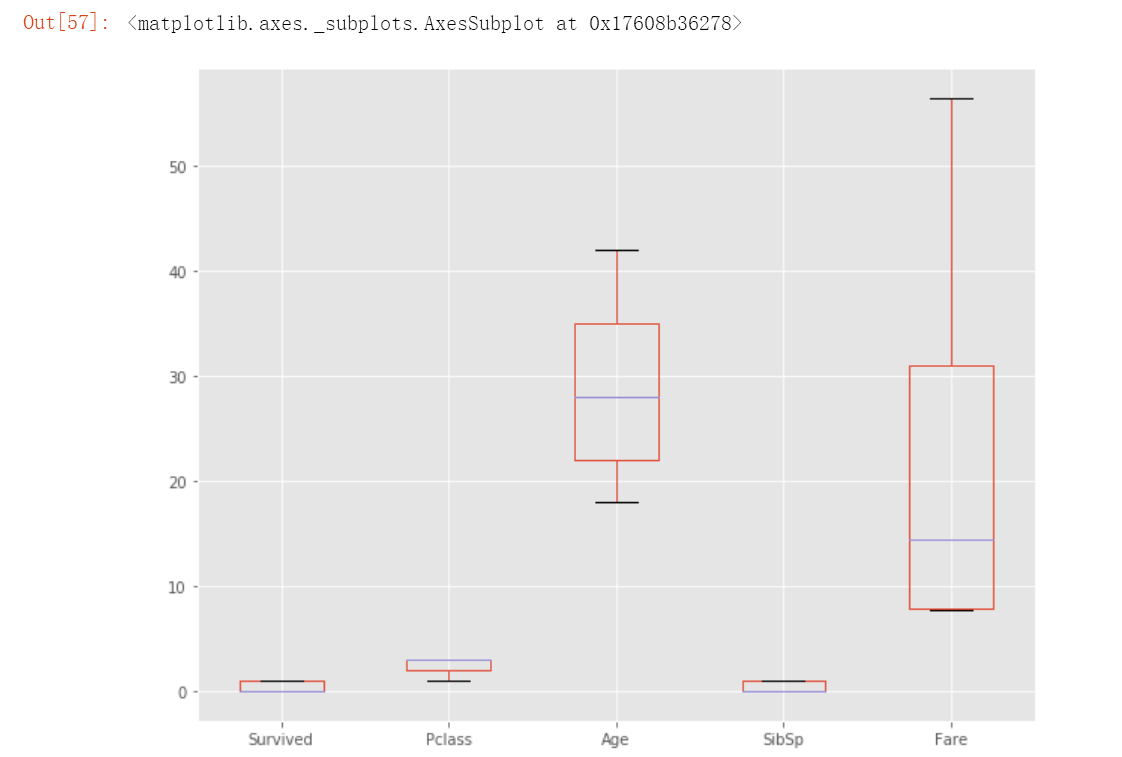
test.plot(kind='box', figsize= (10,8)) 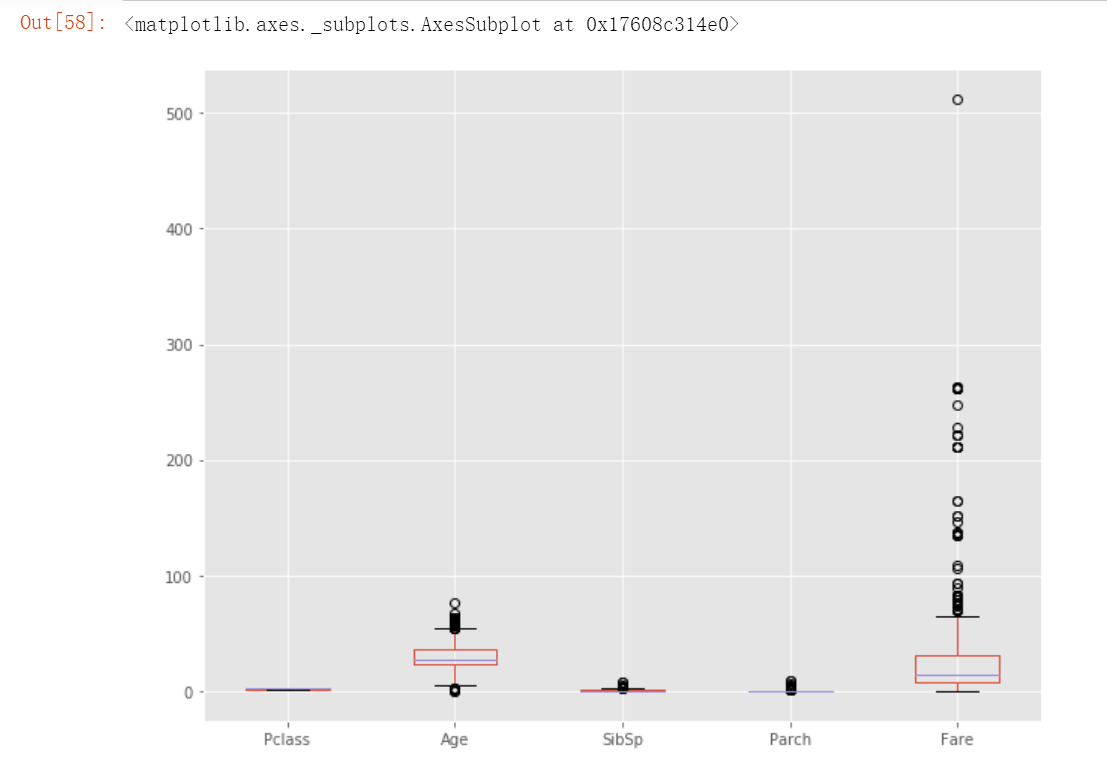
test[cols]= test[cols].clip(lower= test[cols].quantile(0.15), upper= test[cols].quantile(0.85), axis=1)
test.drop(columns=['Parch'], axis=1, inplace=True)
# 用同样的方法处理完测试数据后观察箱型图数据
test.plot(kind='box', figsize= (10,8))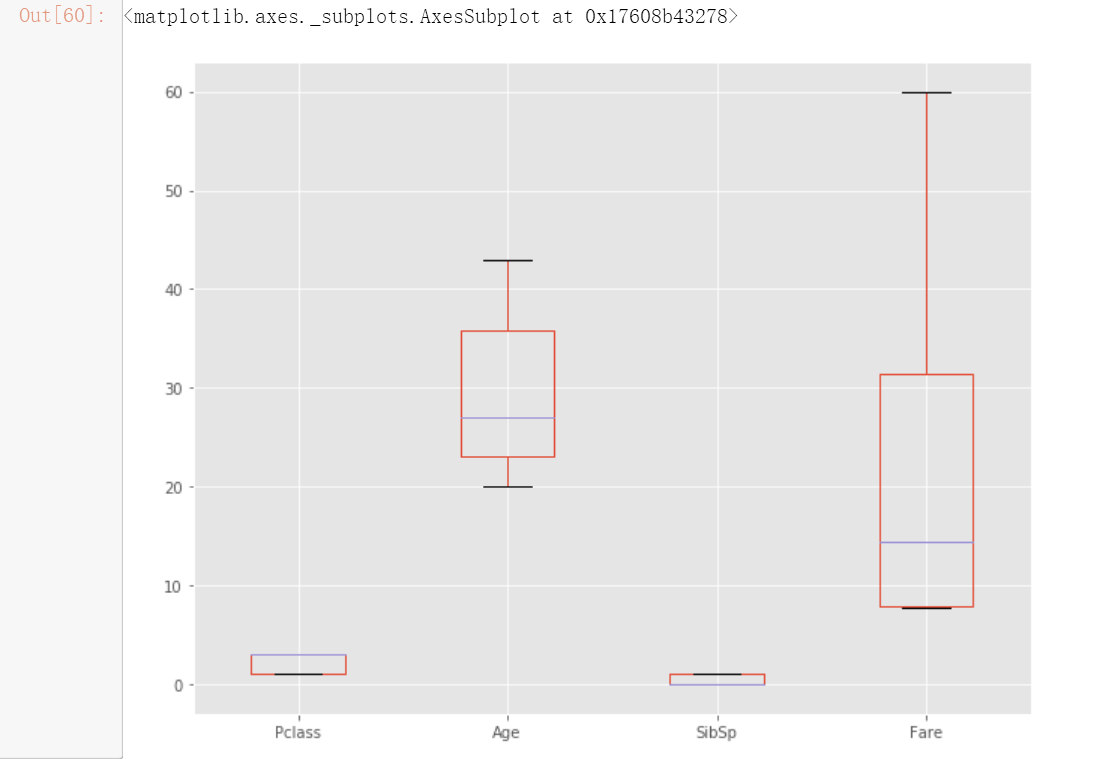
# get_dummies将分类变量转换为数值变量的常用方法,
# 它可以把每个分类变量的不同取值转化为一个二进制向量,使得机器学习算法能够更好地处理这些分类数据
# drop_first=True:该参数用于控制是否删除每个分类变量的第一个编码列。
train= pd.get_dummies(train, columns=['Pclass', 'Sex', 'Embarked' ], drop_first= True)
test= pd.get_dummies(test, columns=['Pclass', 'Sex', 'Embarked' ], drop_first= True)
train.head()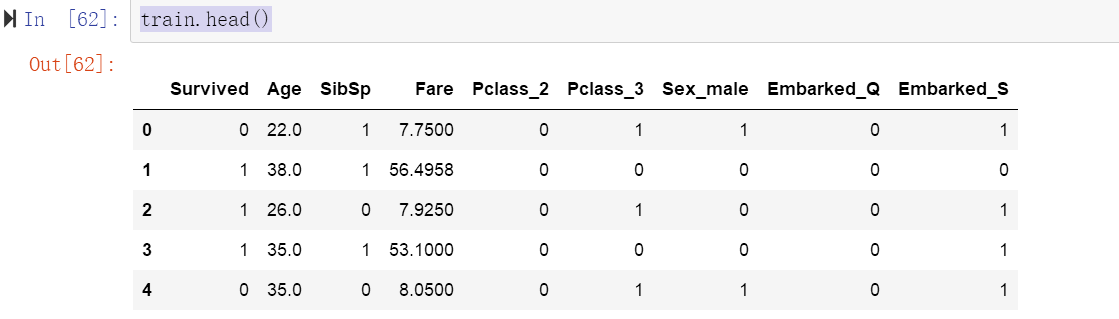
test.head() 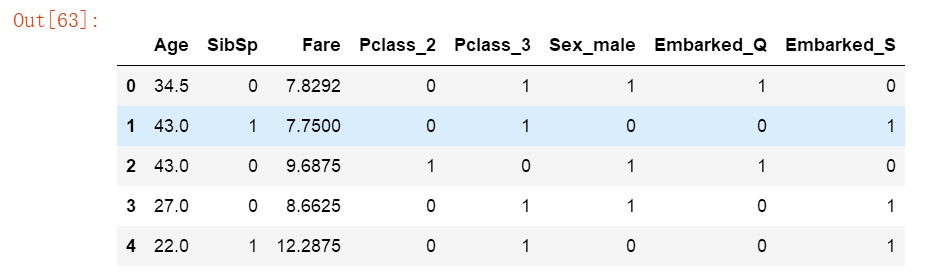
# 拆分数据
X_train= train.iloc[:, 1:]
y_train= train['Survived'].values.reshape(-1,1)
X_test= test
# 特征缩放用于将数据中存在的自变量标准化到一个固定的范围。
from sklearn.preprocessing import StandardScaler
ss= StandardScaler()
features= ['Age', 'SibSp', 'Fare']
X_train[features]= ss.fit_transform(X_train[features])
X_test[features]= ss.fit_transform(X_test[features])X_train.head()
X_test.head()
第三部分 数据探索
# 采用逻辑回归模型来进行数据预测
from sklearn.linear_model import LogisticRegression
clf= LogisticRegression()
clf.fit(X_train, y_train.ravel())
predictions= clf.predict(X_test)
print(clf.score(X_train, y_train))![]()
submission= pd.DataFrame({'PassengerId' : test_df['PassengerId'], 'Survived': predictions })
print(submission.head())
# 保存预测数据
filename= 'titanic predictions.csv'
submission.to_csv(filename, index=False)以上就是本次跟随kaggle项目进行泰坦尼克数据的探索,主要还是复习和巩固之前的一些知识。同时它的难度较低,更适合我们初学者探索的一个项目。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









