







 超级会员免费看
超级会员免费看
 阿里云发布的CIPU(Cloud Infrastructure Processing Units)旨在成为云时代IDC的核心,它专注于优化数据流动过程中的计算效率。CIPU具备IO硬件设备虚拟化、VPC overlay network硬件加速、EBS分布式存储接入硬件加速等10大能力,尤其在弹性RDMA方面,提供了高性能、低时延的解决方案,兼容RDMA verbs生态,并支持大规模组网。此外,CIPU还强调安全硬件加速和云可运维能力,助力云计算服务的高效、安全运行。
阿里云发布的CIPU(Cloud Infrastructure Processing Units)旨在成为云时代IDC的核心,它专注于优化数据流动过程中的计算效率。CIPU具备IO硬件设备虚拟化、VPC overlay network硬件加速、EBS分布式存储接入硬件加速等10大能力,尤其在弹性RDMA方面,提供了高性能、低时延的解决方案,兼容RDMA verbs生态,并支持大规模组网。此外,CIPU还强调安全硬件加速和云可运维能力,助力云计算服务的高效、安全运行。
目录
文章目录
神龙 MoC 卡
2017 年,阿里云推出了自研第一代神龙服务器,搭载自研 MoC(Microserver on Chip)卡,MoC 卡能力伴随神龙架构的演进也在迭代更新:
- 神龙 1.0:解决上云后如何支持裸机服务的问题,将云化组件尤其是裸金属的管理模块卸载到 MoC 卡,提供裸金属的弹性交付和运维;
- 神龙 2.0:神龙芯片能力进一步增强,通过构建轻量级 Hypervisor 实现计算虚拟化的卸载,支持虚拟机服务;
- 神龙 3.0:存储、网络等数据面路径全面通过 DPU 芯片硬件优化,性能大幅提升,可以提供接近裸机的低延时网络;
- 神龙 4.0:融入弹性 RDMA 能力,让 RDMA 从 HPC 类应用,走向支持通用类计算场景。
以 MoC 卡作为雏形,2022 年 6 月阿里云发布云数据中心专用处理器 CIPU,宣称将成为云时代 IDC 的处理核心。
CIPU
与传统的 SmartNIC 厂家比,云计算巨头完全是为了满足自身云计算需求。在他们看来,SmartNIC 就是一个完整的计算、存储、网络一体化处理单元,只视乎于想把如何具体的业务卸载下来,而具体业务只有使用云厂商自己最清楚了。
因此,对云厂商来说,自研 SmartNIC 似乎是一条正确的道路,其 “智能网卡” 的概念已经很薄弱了,它不仅仅是个 NIC 这么简单,它已经深深的融入他们的血液里了。
2017 年,阿里云开始部署完全自研的 X-Dragon MOC 卡。
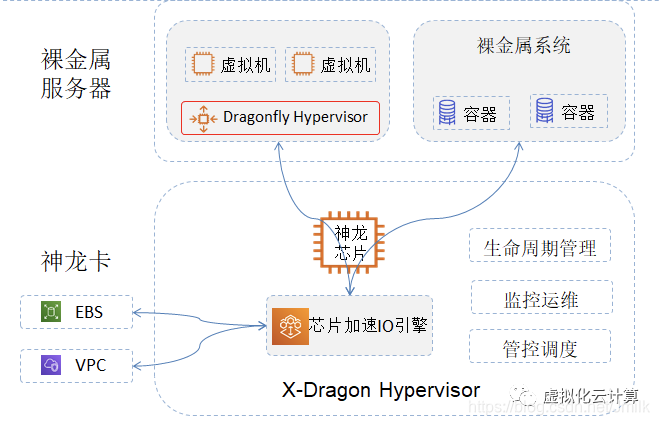
在 2022 年阿里云峰会上,发布了一款云数据中心专用处理器 CIPU(Cloud infrastructure Processing Units,云基础设施处理器)。把 IDC 计算、存储、网络基础设施云化并且硬件加速的专用业务处理器。

CIPU 的定位
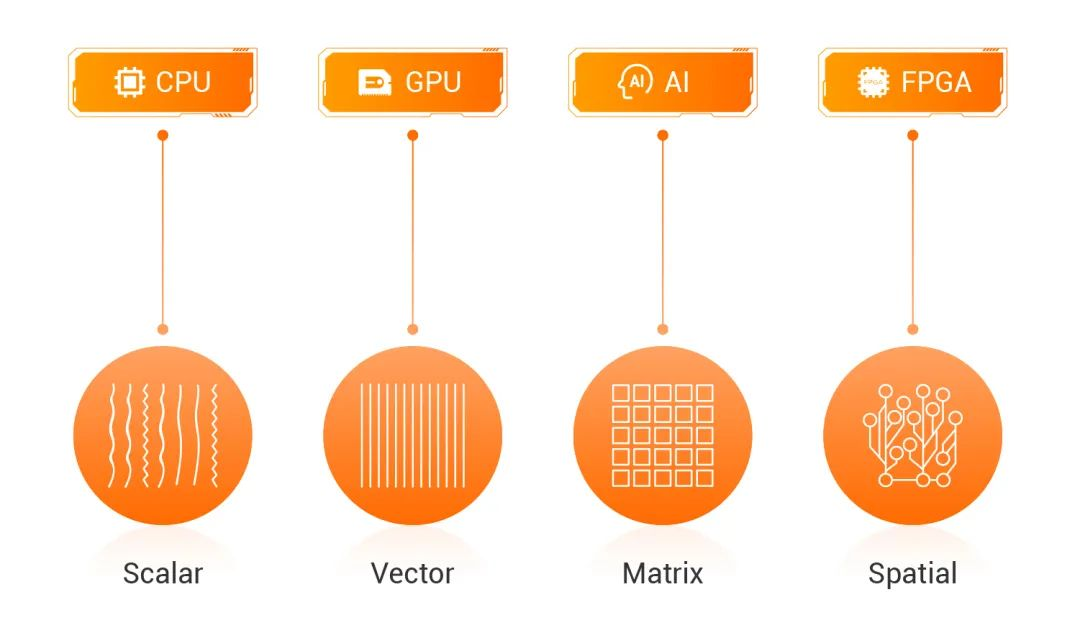
CIPU 要在通用标量计算和 AI 矢量计算等业务领域,去完成 XEON ALU 算力和 GPU stream processor 的 offloading 显然不现实。CIPU 适合的业务类型的共同业务特征:在数据流动(移动)过程中,通过深度垂直软硬件协同设计,尽最大可能减少数据移动,以此提升计算效率。
因此,CIPU 在计算机体系架构视角的主要工作是:优化云计算服务器之间和服务器内部的数据层级化 cache、内存和存储的访问效率。
CIPU 随路异构计算(位于网络和存储必经之路) = 近网络计算(in networking computing)+ 近存储计算(in storage computing)
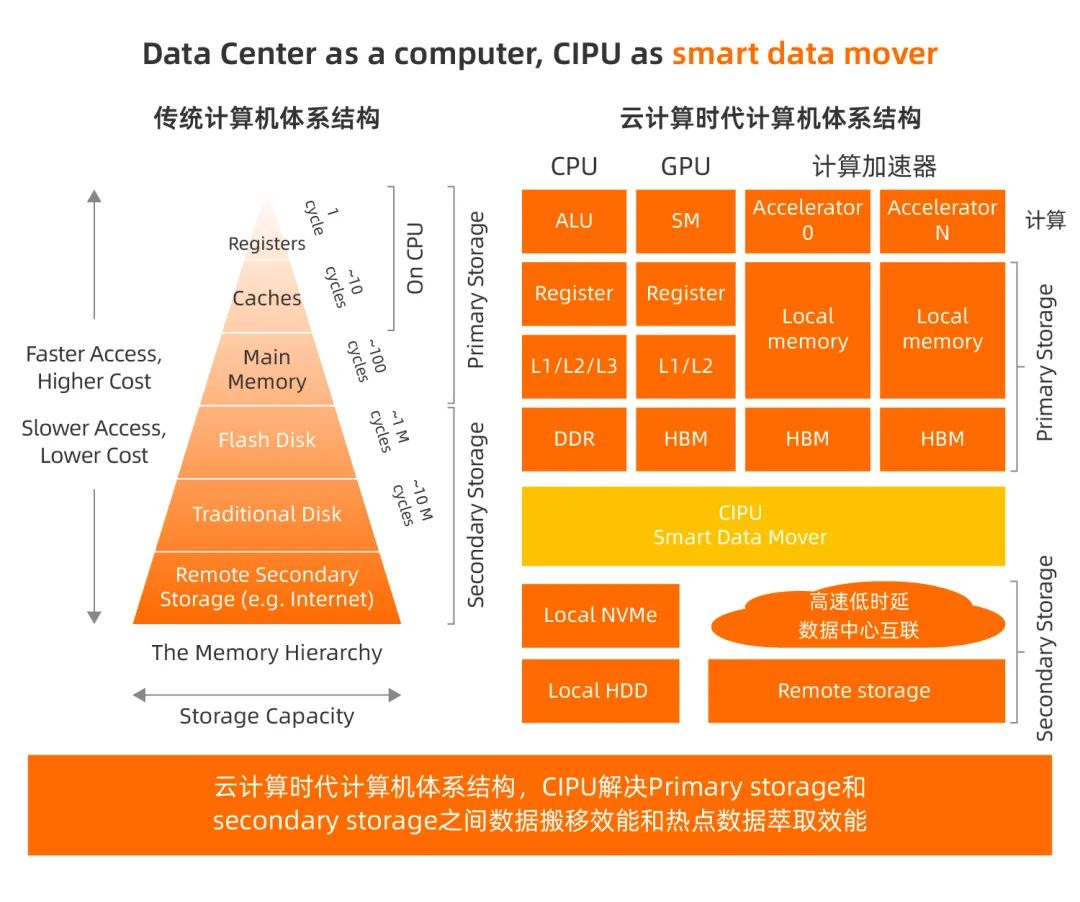
CIPU 的 10 大能力
IO 硬件设备虚拟化
通过 VT-d 的前置支撑技术,实现高性能的 IO 硬件设备虚拟化。
同时考虑公有云 OS 生态兼容,设备模型应该尽最大努力做到兼容。因此实现基于 virtio-net、virtio-blk、NVMe 等业界标准的 IO 设备模型,成为了必须。
同时注意到 IO 设备的高性能,那么在 PCIe 协议层面的优化则至关重要。如何减少 PCIe TLP 通信量、降低 Guest OS 中断数量(同时平衡时延需求),实现灵活的硬件队列资源池化,新 IO 业务的可编程和可配置的灵活性等方面,是决定 IO 硬件设备虚拟化实现优劣的关键。
VPC overlay network 硬件加速
网络虚拟化的业务需求有:
- 需求 1:带宽线速处理能力;
- 需求 2:极致 E2E 低时延和低时延抖动;
- 需求 3:不丢包条件下的高 pps 转发能力。
目前传统方案遇到的挑战:
- 100Gbps+ 大带宽数据移动,导致 “冯诺依曼内存墙” 问题突出;
- CPU 标量处理网络虚拟化业务,并行性瓶颈明显;
- 基于软件的数据路径处理,时延抖动难以克服。
此时,基于硬件转发加速的业务需求诞生,技术实现层面可以分为:
- 类似于 MNLX ASAP、Intel FXP、Broadcom trueflow 等基于可配置的 ASIC 转发技术:具备最高的性瓦比和最低的转发时延,但是业务灵活性就比较捉襟见肘;
- 基于 many core 的 NPU 技术:具备一定的转发业务灵活性,但是 PPA(power-performance-area)效率和转发时延无法和可配置 ASIC 竞争。
- FPGA 可重配置逻辑实现转发技术:time to market 能力有很大优势,但是对于 400Gbps/800Gbps 转发业务,挑战很大。
EBS 分布式存储接入硬件加速
公有云存储要实现 9 个 9 的数据持久性,且计算和存储要满足弹性业务需求,必然导致存算分离。EBS(阿里云块存储)必须在机头 Initiator 高性能、低时延地接入机尾的分布式存储 Target。
具体需求层面:
- EBS 作为实时存储,必须实现 E2E 极致低时延和极致 P9999 时延抖动;
- 实现线速存储 IO 转发,诸如 200Gbps 网络环境下实现 6M IOPS;
- 新一代 NVMe 硬件 IO 虚拟化,满足共享盘业务需求的同时,解决 PV NVMe 半虚拟化 IO 性能瓶颈。
本地存储虚拟化硬件加速
本地存储,虽然不具备诸如 EBS 9 个 9 的数据持久性和可靠性,但是在低成本、高性能、低时延等方面仍然具备优势,对计算 Cache、大数据等业务场景而言是刚需。
如果做到本地盘虚拟化之后,带宽、IOPS、时延的零衰减,同时兼具一虚多、QoS 隔离能力、可运维能力,是本地存储虚拟化硬件加速的核心竞争力。
弹性 RDMA
RDMA 网络在 HPC、AI、大数据、数据库、存储等 Data centric 业务中,扮演愈来愈重要的技术角色。可以说,RDMA 网络已经成为了 Data centric 业务差异化能力的关键。
eRDMA 能力可用于包括 HPC、AI、数据库、大数据等多个场景,将 RDMA 变成一种通用的网络基础设施。
普惠
eRDMA 依托于阿里云的神龙架构 MoC 卡,结合通用的服务器以及交换机,再加上私有的协议来实现 RDMA,由于替代了专用网络交换机和网卡设备,所以成本亲民,无需购买昂贵的设备和建设专用网络。
高性能
eRDMA 可提供最低 5 微秒的时延,延迟表现优于同类技术方案(AWS 的 EFA 为 15.5 微秒),虽然比基于 Infiniband 实现的 RDMA 方案高了几微秒,但与原来 25 微秒的 VPC 相比,大约降低了 80%,由此,数据库、AI 和大数据等应用获得 30%~130% 的性能提升(Redis 数据库性能提升 100%,AI 训练性能和大数据性能提升 30%)。
值得强调的是,eRDMA 最低 5 微秒的时延表现是在单个 AZ(可用区)组网中的表现。当然,如果跨地域组网,则时延表现会增长,但实际上,跨区域组网部署应用的情况很少见。因此,5 微秒的时延有比较实际的参考价值。
大规模组网
常见的 RDMA 实现方案有 Infiniband 和 RoCE 网络两种(iWARP 比较少见了),这两种方案虽然性能表现比 eRDMA 强,但都依赖于昂贵的专用网络设备,特别是要有优先级流量控制能力的交换机设备,运维成本也比较高,更重要的是,这两种方案都无法实现大规模组网。
eRDMA 具备很强的扩展性,eRDMA 突破了传统 RDMA 实现方案中无法大规模组网的问题,传统组网方案中,一台交换机只能支持三四百台设备,而 eRDMA 则能通过大规模组网构建更大的计算集群。
技术实现上,阿里云的 eRDMA 采用了自研的 HPCC 拥塞控制算法,可以容忍 VPC 网络中的传输质量变化(延迟、丢包等),在有损的网络环境中依然拥有良好的性能表现。
虽然 TCP/IP 也能做到 RDMA 要求的可靠性,但是它是以牺牲时延来达到的可靠,而 eRDMA 在技术上的突破点在于,既提供了类似于 TCP/IP 的可靠性,同时也有极佳的延迟表现。
弹性
eRDMA 简单易用,它一端对接的是用户熟悉的 VPC 网络,可以利用 VPC 提供的各种功能特性,能对接各种云上资源,获得资源弹性能力。
实现了 RDMA 上云,随开随用,不需要花费长时间部署。基于云上 Overlay 网络大规模部署,Overlay 网络可达的地方,RDMA 网络可达。
RDMA verbs 生态 100% 兼容
另一端,eRDMA 为 Application 提供的 ERI(Elastic RDMA Interface)接口也完全参照了 RDMA 上流行的验证接口,对接开放生态。
eRDMA 支持原生的 Verbs 接口的应用,实现对上层应用的无缝支持,来享受 RDMA 带来的性能收益,在整体性能方面都有了非常明显的提升,即使是 Spark 和 Redis 这类数据库应用,即使不用做过多的改造,它的性能也有非常明显提升。

AI/ML
谈到大规模集群的应用场景,不得不提机器学习训练场景。
从阿里云过去几年服务 AI 场景的实践来看,主要都是从网络加速层面优化机器学习训练过程,而非在机器学习框架和模型层面做优化。通过利用 AIACC 加速引擎来优化机器学习训练集群的通信效率,从而提升在云上做机器学习训练的效率。
安全硬件加速
持续加强硬件可信技术、VPC 东西向流量全加密、EBS 和本地盘虚拟化数据全量加密,基于硬件的 Enclave 技术等,是云厂商持续提升云业务竞争力的关键。
云可运维能力支撑
云计算的核心是 Service(服务化),从而实现用户对 IT 资源的免运维。而 IaaS 弹性计算可运维能力的核心是:
- 全业务组件的无损热升级能力
- 虚拟机的无损热迁移能力。
弹性裸金属支持
弹性裸金属在具体定义层面必须实现如下八项关键业务特征。同时,云计算弹性业务必然要求弹性裸金属、虚拟机、安全容器等计算资源的并池生产和调度。
CIPU 池化能力
考虑到通用计算和 AI 计算在网络、存储和算力等方面的需求差异巨大,CIPU 必须具备池化能力。通用计算通过 CIPU 池化技术,显著提升 CIPU 资源利用率,从而提升成本层面的核心竞争力;同时又能够在一套 CIPU 技术架构体系下,满足 AI 等高带宽业务需求。
计算虚拟化支撑
计算虚拟化和内存虚拟化的业务特性增强,云厂商均会对 CIPU 有不少核心需求定义。

















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









