






 文章讲述了使用Python库如pdfplumber、pypdf2和tabula进行PDF转TXT的过程,特别关注了处理包含表格和图片的PDF时的困难,以及尝试使用OCR技术(如Tesseract)提取扫描件中的文本。提到的解决方案包括处理CSV文件和解决Tesseract安装问题。
文章讲述了使用Python库如pdfplumber、pypdf2和tabula进行PDF转TXT的过程,特别关注了处理包含表格和图片的PDF时的困难,以及尝试使用OCR技术(如Tesseract)提取扫描件中的文本。提到的解决方案包括处理CSV文件和解决Tesseract安装问题。
一、pdf(非扫描件转txt)
Python中有很多库支持pdf转txt,我尝试了pdfplumber,pypdf2,效果都是不错的。但是一旦pdf中有表格,或者有图片,转换的效果就不好。所以我尝试了用tabula库,这个库可以识别pdf中的表格,但是对于表格分隔两页,或者表格被文字环绕的情况,效果不好。
import csv
import pdfplumber
import tabula
import os
#这个程序用来将PDF转成txt格式,并提取出PDF中的表,但是对于pdf是图片的情况,无法处理。
# 提取PDF中的文本
def extract_text_from_pdf(pdf_path):
with pdfplumber.open(pdf_path) as pdf:
text_list = []
for page in pdf.pages:
page_text = page.extract_text()
words = page_text.split()
line = ''.join(words)
text_list.append(line)
text = '\n'.join(text_list)
return text
def extract_tables_from_pdf(pdf_path, output_dir):
# 读取PDF中的表格
tables = tabula.read_pdf(pdf_path, pages="all", multiple_tables=True)
# 逐一保存每张表格为CSV文件
for i, table in enumerate(tables):
output_path = os.path.join(output_dir, f"table_{i + 1}.csv")
table.to_csv(output_path, index=False)
# 将提取的文本保存到TXT文件
def save_text_to_txt(text, output_path):
with open(output_path, 'w', encoding='utf-8') as file:
file.write(text)
# 指定PDF文件路径
pdf_path = "C:\\Users\\Lenovo\\Desktop\\功能框架.pdf"
# 指定输出目录
output_dir = "output"
# 创建输出目录(如果不存在)
os.makedirs(output_dir, exist_ok=True)
# 提取表格并保存为单独的CSV文件
extract_tables_from_pdf(pdf_path, output_dir)
# 提取文本并保存到TXT文件
text = extract_text_from_pdf(pdf_path)
text_output_path = "output.txt"
save_text_to_txt(text, text_output_path)
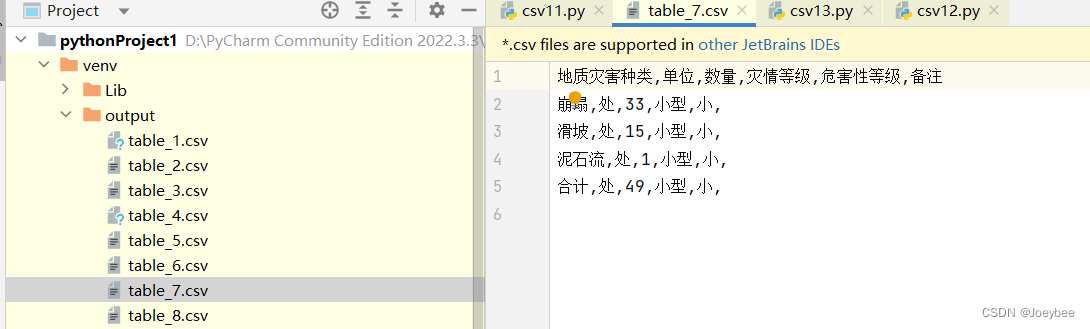
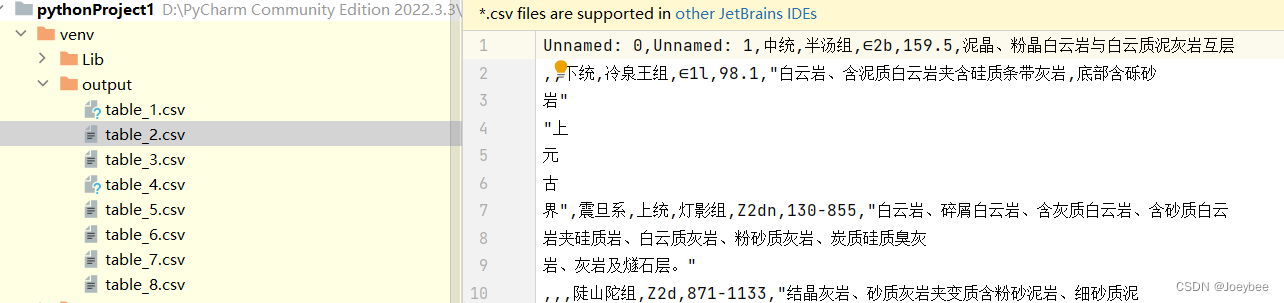
上述代码可以将pdf中的表格分别输出为csv文件,可以看到对于大型表格效果不好,对于小型表格效果不错。(感觉也可以尝试OCR的方法,把表提取出来)
二、处理表格
import os
import csv
# 指定CSV文件所在的目录
csv_dir = "output"
# 指定输出的TXT文件
output_txt_file = "output1.txt"
# 打开输出的TXT文件以写入模式
with open(output_txt_file, "w", encoding="utf-8") as txt_file:
# 遍历CSV文件目录
for csv_file in os.listdir(csv_dir):
if csv_file.endswith(".csv"):
csv_path = os.path.join(csv_dir, csv_file)
# 打开CSV文件以读取模式
with open(csv_path, "r", encoding="utf-8") as csv_content:
# 使用csv模块来处理CSV文件
csv_reader = csv.reader(csv_content)
# 读取表头
header = next(csv_reader)
# 遍历CSV文件的每一行
for row in csv_reader:
# 构建每一行的输出,结合表头和数据
output_line = ""
for i in range(len(header)):
output_line += f"{header[i]}:{row[i]},"
# 去除最后一个逗号并去掉换行符,然后加上句号
output_line = output_line.rstrip(",\n") + "。"
txt_file.write(output_line + "\n")
print(f"CSV文件的内容已保存到 {output_txt_file} 文件中。")
处理csv文件,csv文件的处理质量和csv文件的质量直接相关,只要生成的csv文件质量够好,通过提取数据加表头的方式,可以将一个表转换成一段可以被AI识别的话。
例如

这个表的效果不错,那么通过提取表头和数据可以把一行转换成一段话:
序号1,编号LJ-12,位置庐江县汤池镇果树村白云路,灾种崩塌,稳定程度稳定。
三、OCR方式提取pdf扫描件转txt
import pytesseract
from pdf2image import convert_from_path
# 指定输入的PDF文件和输出的TXT文件
pdf_file_path = "C:\\Users\\Lenovo\\Desktop\\T-CAGHP 023—2018突发地质灾害应急监测预警技术指南(试行).pdf"
txt_file_path = "output2.txt"
# 使用pdf2image库将PDF页面转换为图像
pages = convert_from_path(pdf_file_path)
# 初始化一个空字符串来保存提取的文本
extracted_text = ""
# 使用Tesseract OCR提取文本
for page in pages:
page_text = pytesseract.image_to_string(page, lang="chi_sim") # 使用英语语言模型,你可以根据需要选择其他语言
extracted_text += page_text
# 将提取的文本保存到TXT文件中
with open(txt_file_path, "w", encoding="utf-8") as txt_file:
txt_file.write(extracted_text)
print(f"图像PDF文件中的文本已提取并保存到 {txt_file_path} 文件中。")
需要安装pytesseract和pdf2image这两个库。
运行代码,然后就会报错:
pdf2image.exceptions.PDFInfoNotInstalledError: Unable to get page count. Is poppler installed and in PATH?
要解决这个问题,你需要安装Poppler并将其添加到系统的PATH中。这是Poppler的网址。
Poppler https://poppler.freedesktop.org/
https://poppler.freedesktop.org/
下载文件之后,解压,找到library目录下的bin目录,将bin目录的地址添加到计算机路径中。(添加到路径的方式:此电脑-属性-高级系统设置-环境变量-Path-新建-确定)
然后重启电脑,重新运行代码,继续报错:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
这时候我们就会明白,pytesseract就是一个调用OCR的接口,还需要下载OCR的软件,这个是下载软件的地址,可以挑一个下载。
Index of /tesseract (uni-mannheim.de)https://digi.bib.uni-mannheim.de/tesseract/我下载的是5.3.0版本,2022年12月的那个版本,下载之后,同样找到tesseract.exe文件,将他加入到Path中。重启电脑,运行代码,继续报错:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
这时候该怎么解决呢?参考了其他人的博客,以下是解决办法:
找到pytesseract库所在的文件夹。

打开pytesseract.py文件。
tesseract_cmd = r'E:\OCR\tesseract.exe'
numpy_installed = find_loader('numpy') is not None
if numpy_installed:
from numpy import ndarray
pandas_installed = find_loader('pandas') is not None修改tesseract_cmd,将它改成r'你OCR存放的地址,也就是tesseract.exe所在的地址'。
再次运行代码,成功跑通了,看一下效果。

可以看到有一些错别字,格式也比较乱,当然这和输入pdf文档的质量有很大关系。
文章到此为止啦,拜拜!

















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









