



目录
一、引言
我们程序员在写代码时往往会有很多bug等待我们寻找调试。其实bug最开始的含义就是小虫子,那为什么会变成计算机老鼠过街人人喊打的bug呢?这里讲一个小故事。早期的计算机非常大,大概有两个足球场的大小,一天研究人员发现计算机结果不对,对计算机做了一个全检查,结果就是晶体管上有一只飞虫的尸体造成的计算机计算结果出现了问题。至此之后bug就变成了程序的错误。那我们到底该如何很好的发现bug并及时修改他们呢?论最快找到bug的方式当然是调试器和日志。但是调试器在很多时候都是有局限性的,是无法使用的。如果一个bug它是一个概率性bug,那我们用调试器一行一行的走读,它的概率如果是百分之一甚至更小,那我们单靠调试是不能确定代码bug的。那我们如果用日志器直接让代码执行三百遍,三千遍,三万遍,三十万遍。一定可以查到对应的bug信息的。
无论是调试还是日志,本质上都是观察程序执行的中间过程和中间结果。
我们程序员日常很多时候都在产生bug的同时减少或避免bug,在写代码创造新功能的同时与学习如何与bug休戚与共。那我们如何得知程序哪一行,或是那一条语句做了什么事情,在那块地方申请了一块资源,打开了什么文件等等可能出现问题的或者是可能申请失败的操作。另外也要知道那块代码出了问题的同时也要知道代码是哪位程序员写的,要求他将自己负责的内容再改改。这是日志的主要用途。
首先介绍一下日志的概念:程序运行过程中所记录的程序运行状态信息。
作用:记录了程序运行状态信息,以便于程序员能够随时根据状态信息,对系统的运行状态,进行分析。
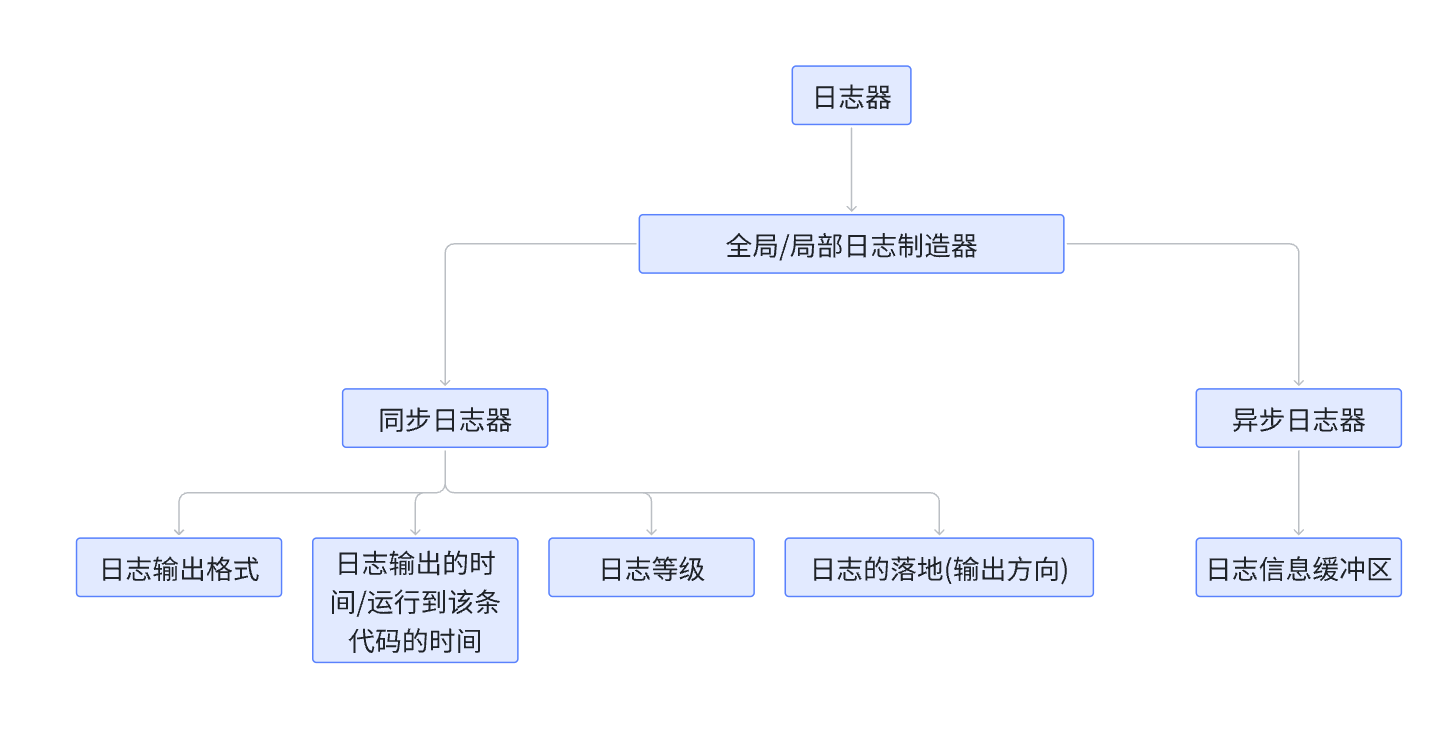
下面就是日志的一个思维导图:这是我们要实现的一个大体上的内容。一个项目的基本构思。
温馨提示: 本章继承与多态、智能指针、线程的概念运用较多,小编一定尽快更新好继承和多态、线程。
二、日志的一个简单的规划
日志等级:
首先我们要给日志器等级分类,便于我们在日志中区分那条日志消息重要程度。也应具有筛选功能,如果没有重点的看话,根本就对服务器运行状况一无所知,更不用说bug了。我们既然都已经日志分级了,我们也可以设置一个日志等级删选,当日志等级没有超过我们指定的日志等级时不输出到文件中,只保留大于和等于我们设立的日志等级的调试信息。
日志基本信息:
此外我们打印/输出的日志应该包含时间、日志器名字或者说使用者、调试信息。我们还可以设立自己的格式,以自己想设立的形式输出。
日志自定义格式:
我们可以使用C++输出流的概念,向输出流中添加字符串和格式化字符串。如果我们想替换格式字符串中的内容,我们可以将字符串以自己定义的字符串规则解析。
日志落地方向:
日志到底该往哪个地方输出(是打印、文件,还是一起,还是说往多个文件中输出)。我们可以使用前面的提到的std::vector,用std::vector来存储包含落地方向的类。但是打印输出和向文件输出毕竟还是不同的,我们可以指定一个输出的父类,让打印输出和向文件输出的子类去继承该父类。利用子类的指针和对象可以赋值给父类的继承规则。
同步日志器:
不知道大家有没有了解过线程的概念,我们平常写下的代码一行一行执行的模式使用的是单线程模式,多线程就是多个函数同时进行,减少影响主线程(也就是main函数的执行)。那同步日志器就是将日志器被main直接包含或是在包含的函数中。没有调用其他线程。如果日志器发生阻塞,会影响到主线程。
异步日志器:
简单来说就是多调用一个或是多个线程去执行日志器的输出。(详细小编再给大家做一期博客)
日志器的缓冲区以及刷新规则:
如果直接输出到指定文件,调试信息有一条就打出一条。那效率太慢了。因为频繁打开文件会造成比较大的时间上的损耗。等到快达到缓冲区的容量,再拿出来输出。
日志器管理:(例如全局日志器、局部日志器):
局部日志管理器、全局日志管理器管理好日志器,如果日志管理器析构了,那毫无疑问日志器也会跟着析构。
接下来我们来实现日志器。
温馨提示:大家每实现一个功能都要记得测试一下。
三、日志文件目录的建立、时间、信息
首先我们需要建立存储日志文件所在目录,如果存在就不用创建了,再获取时间,将时间放入信息中,如果将日志内的调试信息都打印出来,我相信以服务器的运行速度,可能看都看不清,所以我们一般都是在服务器中以日志文件的形式打印出来,但是打印出来也不是不可以。
我们先从时间开始,时间是比较简单获取的。直接用C语言中<time.h>中的time函数,因为使用到了多线程的概念所以我们在将time_t转化为struct tm结构体的同时,我们要使用localtime_r()函数,localtime()虽然使用起来很方便但实际上函数内获取到的时间struct tm*结构体指针是一个函数中的静态变量,如果使用该函数会存在线程安全的问题,试想一下如果一个线程使localtime()函数中struct tm*结构体指针刷新,那之前执行该函数的线程拿到的时间并不是准确,更确切来说拿到的时间不对。
虽然localtime()函数只需要我们进行传入time_t时间就能获取时间,很方便。但是为了准确,我们只能使用localtime_r()函数。
#include <iostream>
#include <ctime>
int main()
{
// localtime和localtime_r的使用。
time_t t = time(nullptr);
struct tm* ptm = localtime(&t);
struct tm ret;
localtime_r(&t,&ret);
return 0;
}日志信息包含时间、日志等级、调试信息、日志器名称、线程ID、文件名、行号。文件名和行号为了快速定位调试位置。线程ID是为了应对多线程。
日志文件目录用系统调用mkdir()。C++文件流的概念还有以创建+打开的模式创建文件。我们还是一级一级的创建目录(从最开始的文件目录开始创建)。我们还应该能有一个path函数给我们返回所要文件的路径。这个只要使用查找函数,从后往前查找'\\'和'/'(文件分隔符)(文件目录)就行了。建立文件夹时记得用path函数获得文件的路径。
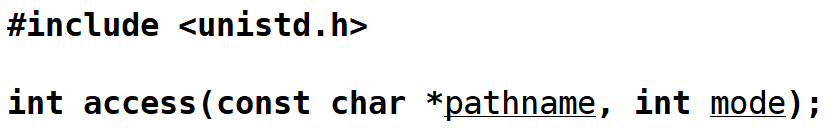

判断文件是否存在我们可以使用stat、access等一系列系统调用,fstat是用来查看文件状况的。
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
// 使用stat
struct stat st;
if(stat(pathname.c_str(),&st) == 0)
{
return true;
}
return false;#ifndef __UNTIL__HPP__
#define __UNTIL__HPP__
#include <iostream>
#include <string>
#include <ctime>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
namespace Logs
{
namespace Until
{
class Time
{
public:
// 获取时间
// 静态函数在只要使用类域限定加上::(不创建类)也可以调用。
// 例如Time::GetTime();
static time_t GetTime()
{
return time(nullptr);
}
};
class File
{
public:
// 利用access对象查看目录是否存在。
// 存在就不用创建了,不存在则创建。
static bool exists(const std::string& pathname)
{
// 判断文件是否存在。
// 也可以使用fstat、stat系统调用。
if(access(pathname.c_str(),F_OK) == 0)
{
return true;
}
return false;
}
// 文件路径
static std::string path(const std::string& pathname)
{
// 从最后开始找字符串中的某一个。
// '\\'就是\字符,因为\常常用作转义字符,与其他字符构成和格式化字符。
// 所以用'\\'表示\。
size_t pos = pathname.find_last_of("/\\");
if(pos == std::string::npos)
{
return std::string();
}
return pathname.substr(0,pos + 1);
}
static void createdirectory(const std::string& pathname)
{
size_t pos = 0, start = 0;
// ./abc/def/ghi.txt
while(start < pathname.size())
{
pos = pathname.find_first_of("/\\",start);
// 有可能只是一个单一的目录。不存在"/\\"。
if(pos == std::string::npos)
{
mkdir(pathname.c_str(),0777);
}
// 查看目录是否创建好了。
// 如果目录没有建好的话,则建好上一级目录。
// 就一个一个用地址建,不移动目录。
std::string parent_dir = pathname.substr(0,pos);
if(exists(parent_dir) == true)
{
start = pos + 1;
continue;
}
mkdir(parent_dir.c_str(),0777);
start = pos + 1;
}
}
};
}
}
#endif四、格式化字符串
既然我们要格式化字符串。肯定要自己定义占位符(%?),还要解析好字符串。占位符的输出对象可以通过unordered_map、map进行管理。另外还要有子格式。另外日志等级我们使用class enum的一个枚举类型搞定的,我们需要将枚举类型转为字符串便于输出打印。
代码中我们将一个输出类中的函数:
virtual void FomatPrint(std::ostream& out,const Message& msg) = 0;
设为虚函数,使子类中的函数实现重写,实现专门化。专药专治。因为子类中的格式略有差异,所以我们往往有一些类中初始化函数多一个初始化值。
我们将输出信息分为几个大类:
1.时间
2.消息
3.日志等级
4.文件名
5.缩进
6.换行
7.行号
8.线程ID
9.其他项
| %d | 时间 |
| %t | 线程ID |
| %c | 日志器名称 |
| %f | 文件名 |
| %l | 行号 |
| %p | 日志等级 |
| %T | 缩进 |
| %m | 消息 |
| %n | 换行 |
其他项就代表着只需要传递字符串就够了。class Formatter中的解析函数,是用来将上述出现的%?的占位符替换为有效信息。我们之后再在该基础上封装一层就可以得到我们熟悉的printf函数中所规定的占位符,我们通过系统调用将字符串以printf函数中所规定的占位符做处理(是为了更好的输出调试信息。),我们这里规定的占位符只是为了添加有用的日志信息。
#ifndef __FORMAT_HPP___
#define __FORMAT_HPP___
#include <iostream>
#include <sstream>
#include <ctime>
#include <cassert>
#include <string>
#include <memory>
#include <vector>
#include "Message.hpp"
#include "Level.hpp"
#include "Until.hpp"
namespace Logs
{
class FormatItem
{
public:
using Ptr = std::shared_ptr<FormatItem>;
virtual ~FormatItem() {};
virtual void FomatPrint(std::ostream& out,const Message& msg) = 0;
};
class MessageFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << msg._message;
}
};
class LevelFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
Level l;
out << l.To_String(msg._level);
}
};
class TimeFormatItem : public FormatItem
{
public:
TimeFormatItem(std::string format = "%H:%M:%S")
:_format(format)
{}
void FomatPrint(std::ostream& out,const Message& msg) override
{
struct tm t;
//struct tm* ctime = localtime_r(&(msg._ctime),&t);
time_t now = Until::Time::GetTime();
struct tm* ctime = localtime_r(&(now),&t);
char buffer[50];
strftime(buffer,sizeof(buffer),_format.c_str(),ctime);
out << buffer;
}
private:
std::string _format;
};
class FileFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << msg._file;
}
};
class LineFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << msg._line;
}
};
class LoggerFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << msg._logger;
}
};
class TidFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << msg._tid;
}
};
class TABFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << "\t";
}
};
class NewLineFormatItem : public FormatItem
{
public:
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << "\n";
}
};
class OtherFormatItem : public FormatItem
{
public:
OtherFormatItem(const std::string& str)
:_str(str)
{
;
}
void FomatPrint(std::ostream& out,const Message& msg) override
{
out << _str;
}
private:
std::string _str;
};
class Formatter
{
public:
using Ptr = std::shared_ptr<Formatter>;
Formatter(const std::string& pattern = "[%d{%H:%M:%S}[%t][%c][%f:%l][%p]%T%m%n]")
:_pattern(pattern)
{
// 必须解析成功,不然就不知道以何种形式返回。
// 不然就终止。
assert(parsePattern());
}
// 对msg进行格式化。
void format(std::ostream& out,const Message& msg)
{
for(auto item : _items)
{
item->FomatPrint(out,msg);
}
}
std::string format(const Message& msg)
{
std::stringstream ss;
ss << msg._ctime
<< Level::To_String(msg._level)
<< msg._file
<< msg._line
<< msg._message
<< msg._logger;
return ss.str();
}
// 对格式化规则字符串进行解析。
bool parsePattern()
{
std::string key, val ;
std::vector<std::pair<std::string , std::string>> fmt_order;
size_t pos = 0;
while(pos < _pattern.size())
{
// 非格式串字符。
if(_pattern[pos] != '%')
{
val.push_back(_pattern[pos]);
++pos;
continue;
}
// 就是普通的%%转义字符。
if(pos + 1 < _pattern.size() && _pattern[pos] != '%')
{
val.push_back(_pattern[pos]);
pos += 2;
continue;
}
// 接下来就一定是固定格式字符串。
++pos;
if(pos >= _pattern.size())
{
std::cout << "%%格式错误" << std::endl;
return false;
}
key.push_back(_pattern[pos]);
++pos;
// 没有值,可以不插入,避免浪费时间空间。
if(val.empty() == false)
{
fmt_order.push_back(std::make_pair("",val));
val.clear();
}
if(pos + 1 == _pattern.size() && _pattern[pos] == '{')
{
std::cout << "子格式串错误" << std::endl;
return false;
}
// 紧随格式化字符之后,有没有'{',如果有,则'}'之后,之前的数据是格式化字符的子格式。
if(pos < _pattern.size() && _pattern[pos] == '{')
{
++pos;
// 如果没有'}'说明这个格式有问题。
while(pos < _pattern.size() && _pattern[pos] != '}')
{
// 就是无需变化的格式串。
val.push_back(_pattern[pos]);
++pos;
}
if(pos == _pattern.size())
{
std::cout << "子格式错误" << std::endl;
return false;
}
}
// 怕还有其他的key、val没有保存。
fmt_order.push_back(std::make_pair(key,val));
key.clear();
val.clear();
}
// 保存所有格式。
for(auto& it : fmt_order)
{
_items.push_back(createItem(it.first,it.second));
}
return true;
}
// 根据不同的格式化字符串创建不同的个数话子项对象。
FormatItem::Ptr createItem(const std::string& key,const std::string& val)
{
if(key == "d") return std::make_shared<TimeFormatItem>(val);
if(key == "t") return std::make_shared<TidFormatItem>();
if(key == "c") return std::make_shared<LoggerFormatItem>();
if(key == "f") return std::make_shared<FileFormatItem>();
if(key == "l") return std::make_shared<LineFormatItem>();
if(key == "p") return std::make_shared<LevelFormatItem>();
if(key == "T") return std::make_shared<TABFormatItem>();
if(key == "m") return std::make_shared<MessageFormatItem>();
if(key == "n") return std::make_shared<NewLineFormatItem>();
return std::make_shared<OtherFormatItem>(val);
}
private:
std::string _pattern;
std::vector<FormatItem::Ptr> _items;
};
}
#endif
















 295
295


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








