







论文题目: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
论文地址: https://arxiv.org/pdf/2501.12948
论文发表于: arXiv 2025年1月
论文所属单位: DeepSeek
论文大体内容
本文提出DeepSeek-R1模型,主要是以DeepSeek-V3[4]基座模型的基础上进行优化,提升其推理能力。本文首先提出了DeepSeek-R1-Zero模型,探索仅用RL去提升推理能力,并进而提出DeepSeek-R1,拿到很好的效果。
Motivation
之前的工作都需要较多的监督数据进行SFT,本文尝试把SFT去掉,仅使用RL,探索模型的效果。
Contribution
①本文探索了纯RL的后训练,无需SFT,为后续这领域的发展铺平了道路。
②对大模型进行蒸馏,会比小模型进行RL拿到更好的效果。
1. DeepSeek-R1-Zero:对基座模型仅进行RL,来提升它的效果。
①RL算法采用了GRPO(Group Relative Policy Optimization)[1],这个算法在DeepSeek-Math[2]中首次提出。
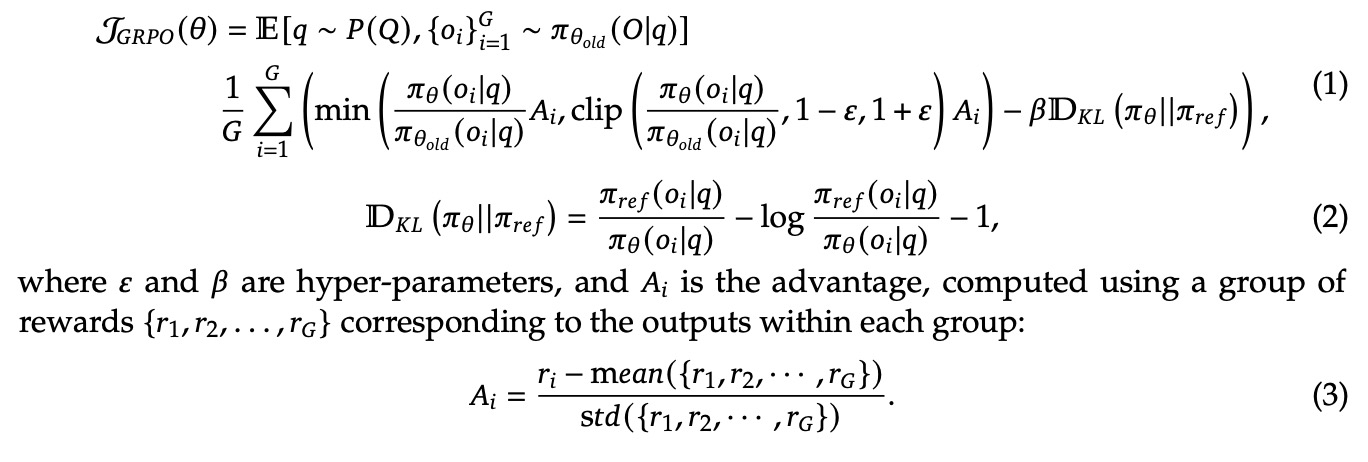
②采用rule based的reward model,包括准确性奖励(评估是否回答正确)和格式奖励(思考过程位于<think>和</think>标签之间)。
2. DeepSeek-R1-Zero的效果:效果对标OpenAI-o1。从训练的演进可以看到效果在不断提升。
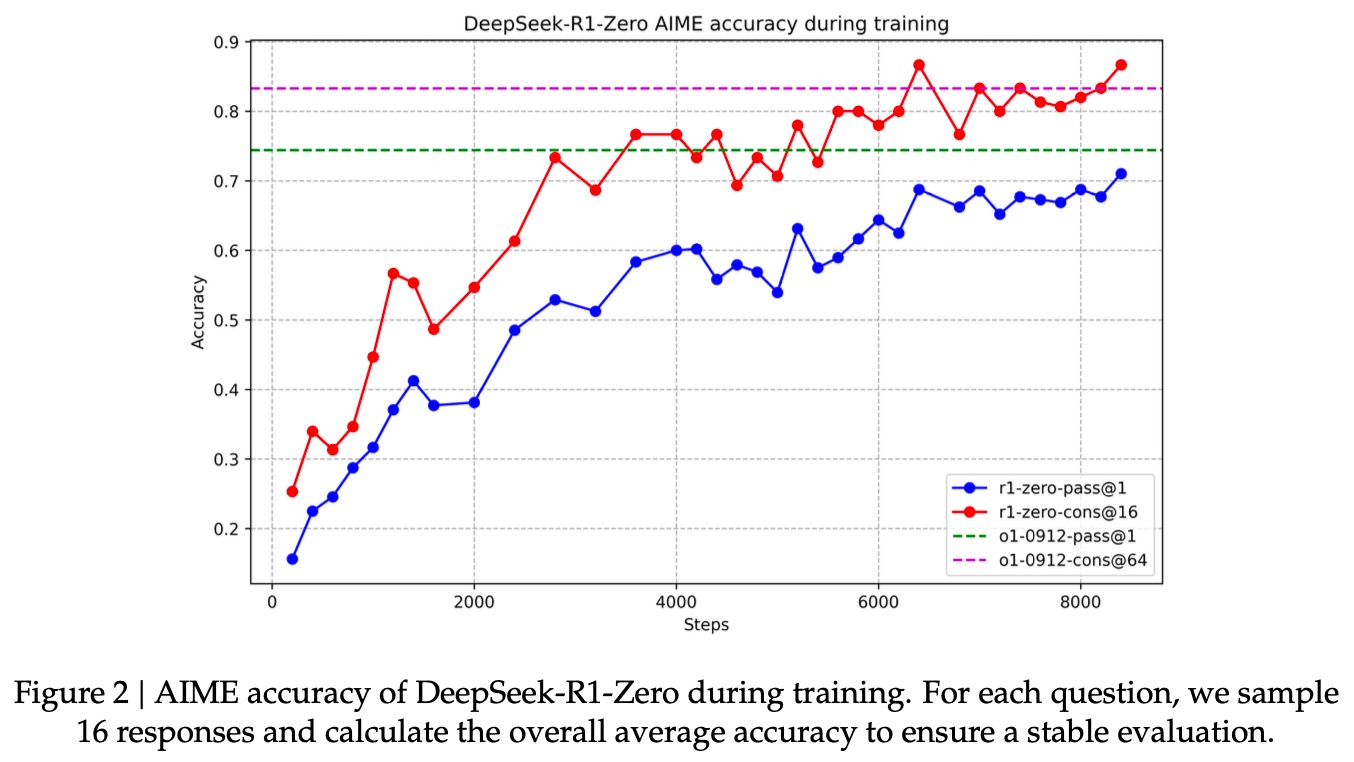
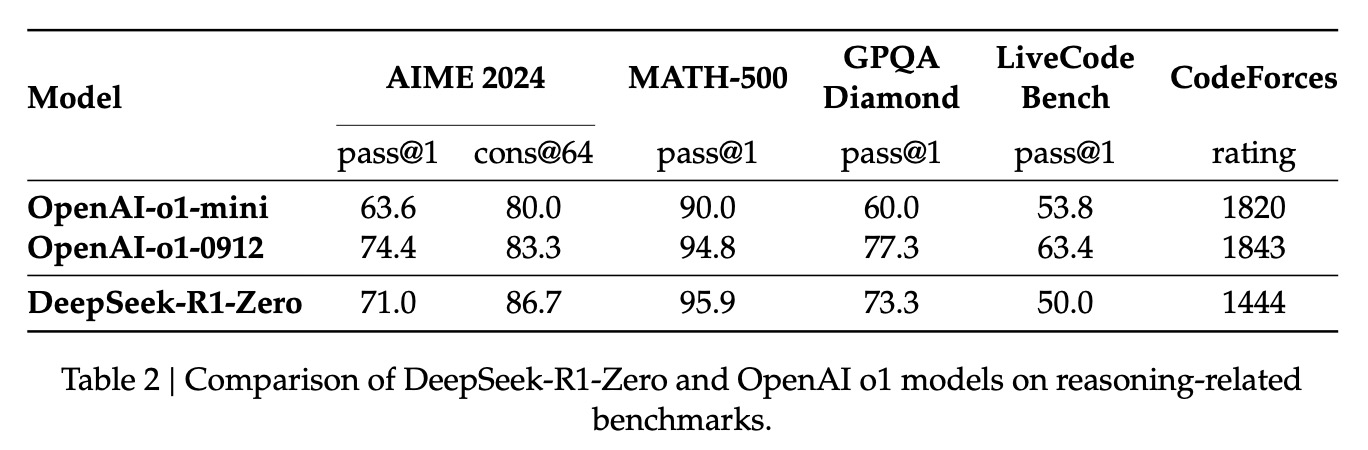
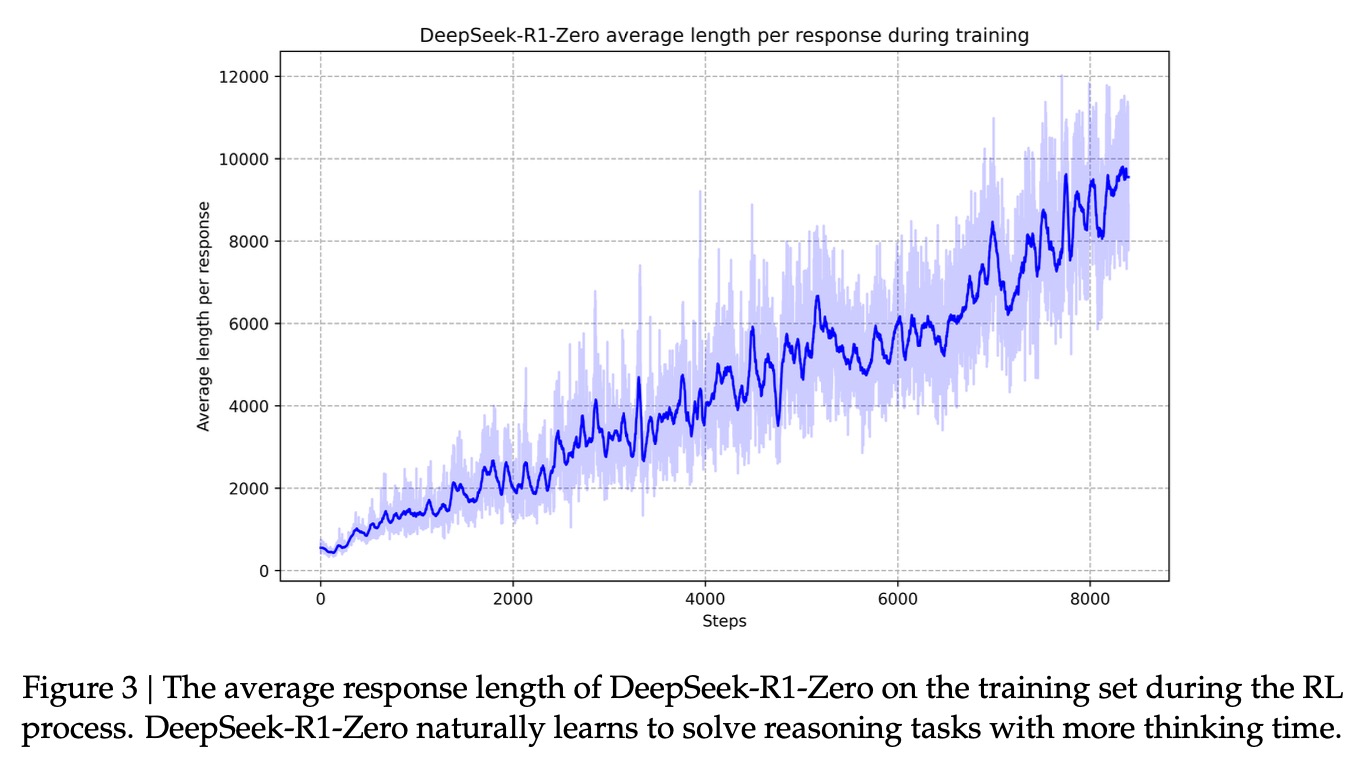
3. 观察DeepSeek-R1-Zero的「自我进化」过程,可以看到随着不断训练,它的输出长度会不断增加。这个代码模型的泛化、推理能力在不断增强。
4. DeepSeek-R1-Zero的Aha Moment,出现了拟人化语气的自我反思。

5. DeepSeek-R1-Zero的优缺点:
①优点:推理能力强,且通过RL自己探索出来了。
②缺点:可读性差、语言混合。
6. 为了解决DeepSeek-R1-Zero的缺点问题,本文提出了DeepSeek-R1。
①Cold Start:收集CoT的几千个实例用于RL的冷启,实例的可读性通过人工review去保障。
②RL引入语言一致性奖励,计算方式是统计目标语言在CoT中的占比,这样能降低语言混合,提升可读性,但同时也对性能有一些损失。
③使用RST(Rejection Sampling and Supervised Fine-Tunin)进行微调,包括推理数据(600k)和非推理数据(200k)
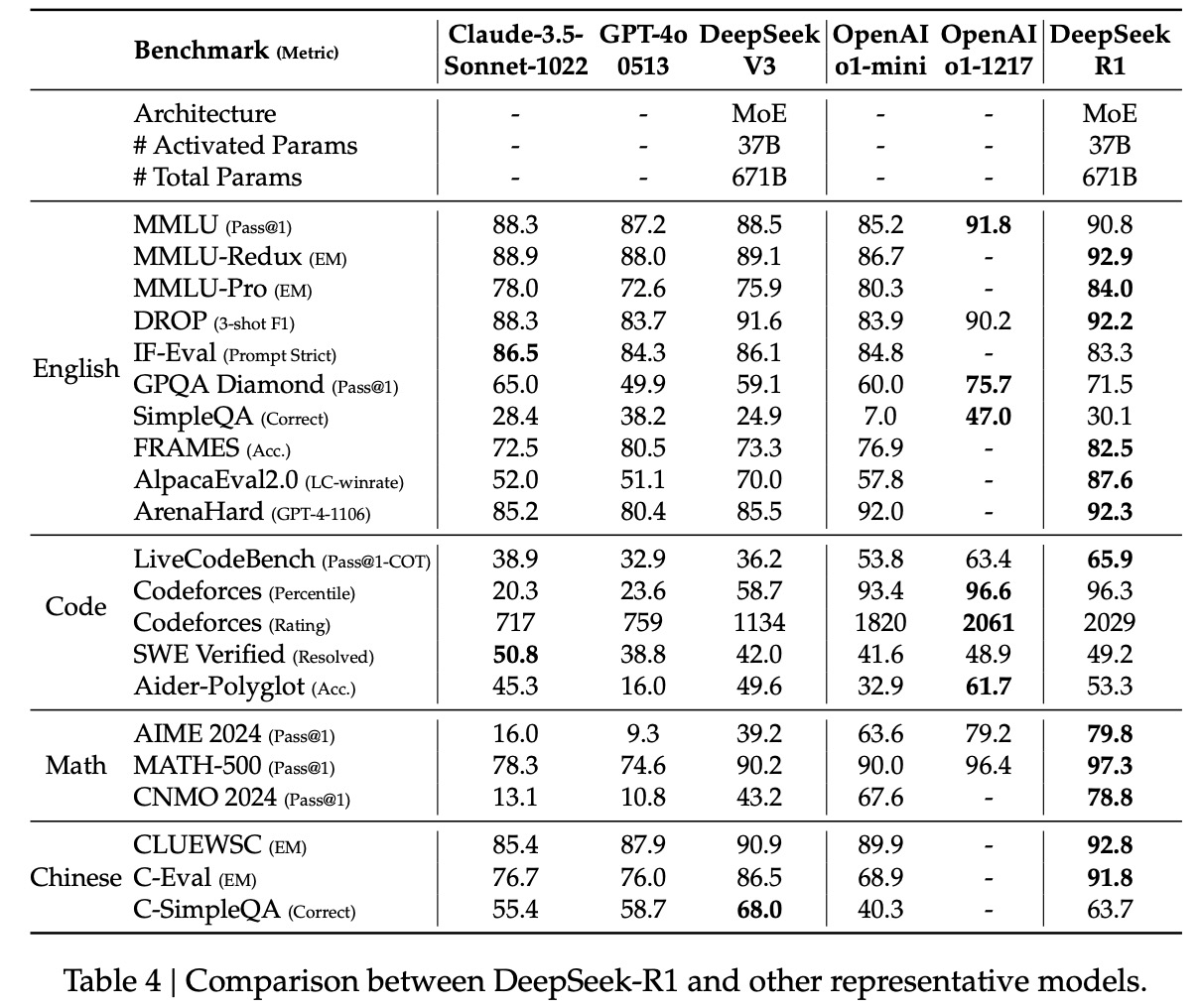
④评测效果如下图。
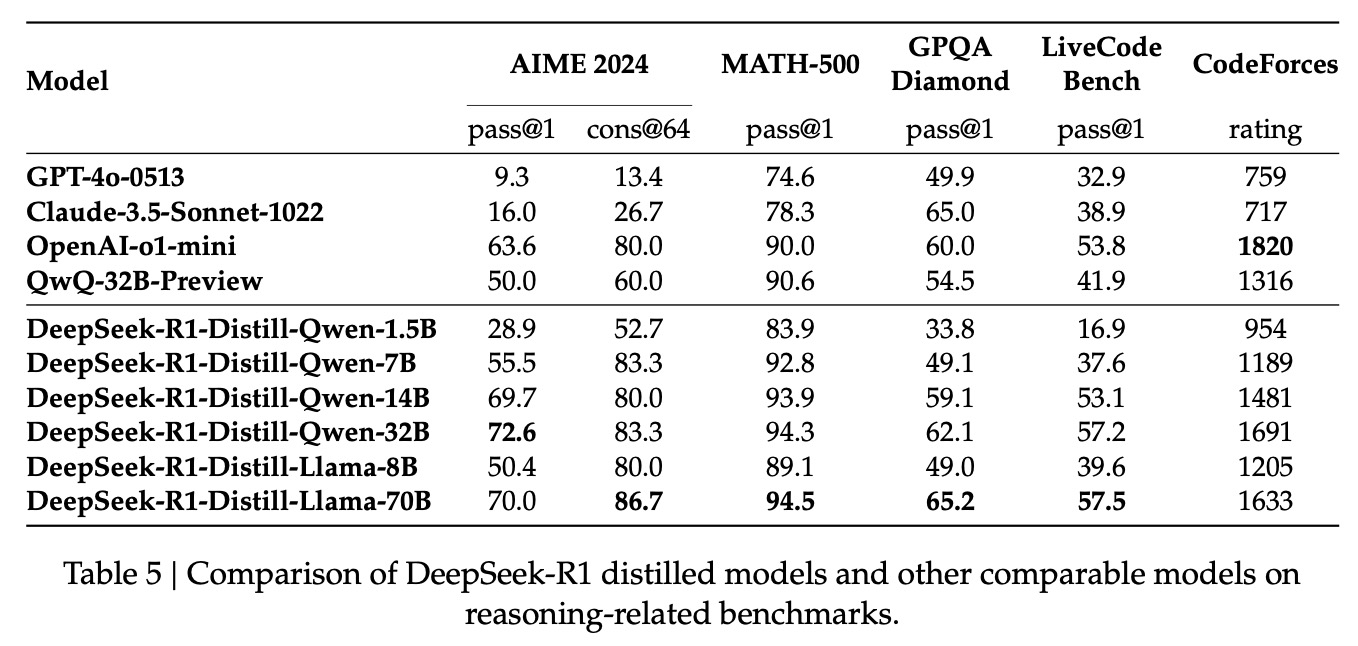
7. 蒸馏:本文对其它的开源模型,包括Qwen和LLaMa等,使用R1产出的SFT数据进行了SFT,发现小模型也能学习到推理能力,效果原地拔高。
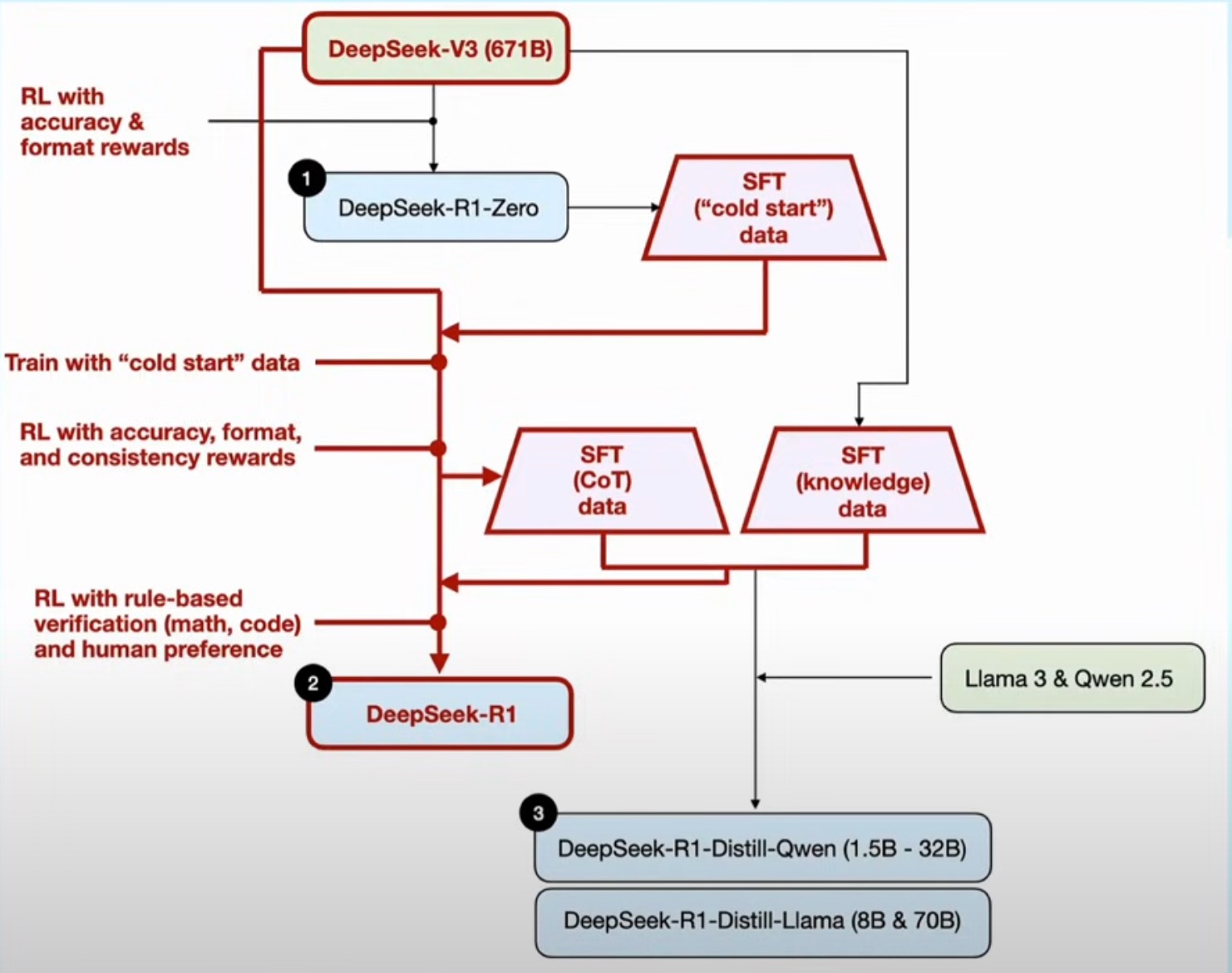
8. R1整体的训练pipeline[5]思路如下图。
参考资料
[1] 无需RL基础理解 PPO 和 GRPO:https://mp.weixin.qq.com/s/YHoDl99fyNe7MP03BoRc6g
[2] DeepSeek-Math:https://blog.csdn.net/John159151/article/details/147675280
[3] 逐篇讲解DeepSeek关键9篇论文及创新点——“勇敢者的游戏”:https://www.bilibili.com/video/BV1xuK5eREJi/
[4] DeepSeek-V3:https://blog.csdn.net/John159151/article/details/147402251
[5] 最好的致敬是学习:DeepSeek-R1 赏析:https://www.youtube.com/watch?v=2qyUi4TD6xA
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









