






Python垃圾回收机制 字符编码概述 字符编码相关操作 代码操作文件
垃圾回收机制
引入
在使用python编程的时候,电脑会存储数据,需要对存储空间进行申请和释放。
而中间的操作都不需要程序员的操作是因为python会自动执行以上操作
一般编程语言的编写
申请内存空间的代码
name = John
释放内存空间的代码
Python编写代码
只需要正常编写,省去了申请和释放内存空间的步骤
name = John
'''这一切归功于python能在编程时动态的管理电脑内存'''
python的垃圾回收机制工作原理
- 引用计数
- 标记清除
- 分代回收
引用计数
name = 'John' #当前数据值John的引用计数为1
name1 = 'John' #当前数据值John的引用计数为2
del name1 #当前数据值John的引用计数为1
#当数据值的引用计数不为0的时候,表示该数据值还在使用,不删除
#当数据值的引用计数为0时,该数据值会被垃圾回收机制回收
'''引用计数存在一个坑''' >>> 循环引用
循环引用

运行结果
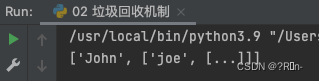
#上图中 两个变量都互相绑定了对方列表的新的索引值
del l1
del l2
#就算将两个变量解绑了对应的两个列表,
#但列表内的数据的引用计数不是0
#意味着回收机制识别不出这两个垃圾数据
'''这个现象被称为循环引用'''
那么该如何解决循环引用现象
这里我们就用到第二点’‘‘标记清除’’’
标记清除
这个方法就是通过将内存中程序产生的所有数据值
全部检查一遍是否存在循环引用来解决循环引用的问题
并将检测出存在的循环引用打上记号 然后一次性清除
分代回收
标记清除每间隔一段时间就需要将所有的数据排查一遍
这么做的资源消耗过大,所以就会有分代回收这一功能

以上为抽象分代回收流程图
为了减轻垃圾回收机制的资源消耗 python开发了三代管理
每一代管理比上一代管理时间间隔更长
字符编码
简介
*字符编码只针对文本文件,是文本文件才有的概念
*因为计算机内部存取数据的本质是:二进制(只能识别0和1)
所以人与计算机之间存在一个人类字符与数字的转换关系
于是就有'''字符编码表'''的存在,用于让计算机显示人类字符
发展史
- 阶段一(一家独大)
- 由于计算机是由美国人发明的,所以第一个编码表只能识别英文字符。(ASSCII码)
- 因为所有的英文字符加起来不超过127个,同时美国人考虑以后可能会增添新的字符以备不时之需,所以使用了八位二进制来记录
- 此时的计算机智能识别英文 不能识别其他文字
0000000(2的7次方等于128)00000000(八位)
A-Z 65-90
a-z 97-122
- 阶段二(群雄割据)
- 中国(GBK码):记录了中文字符,英文字符,数字的对应关系。并以 2bytes起步储存中文(生僻字会用更多字节),1bytes储存英文。
- 韩国(Euc_kr码)
- 日本(shift_JIS码)
此时的各国计算机文本文件无法直接交互,会出现乱码的现象
- 阶段三(天下统一)
- 万国码(unicode): 兼容万国字符
(所有字符全部使用2bytes起步储存)
这导致有时候不同语言的文本转换会产生巨大的文件大小差异- 于是就有了最后一个字符编码
- utf家族(unicode transformation format)
UTF是针对unicode的优化版本 其中使用频率最高的是utf8 内存使用的是兼容万国的万国码unicode,而硬盘使用的是utf来减少IO操作时间 - 万国码(unicode): 兼容万国字符
字符编码实操
如何解决乱码
用原存储文档时的编码解开
编码与解码
编码(人类的字符>>>计算机的字符)
将人类的字符按照指定的编码转换成计算机可以识别的数字
s1 = ' 学不die就往die里学'
res = s1.encode('utf8')
print(res, type(res))

解码(计算机的字符>>>人类的字符)
将计算机能够识别的数字按照指定的编码转成人类可以读懂的字符
res1 = res.decode('utf8')
print(res1)

解释器层面
要注意的是python2默认的编码是ASCII码
只需要在代码的开头 加上 # coding:utf8(文件头:告诉解释器要使用什么编码), 然后在所有字符串前
添加字母 u(定义字符串) 即可运行python3的代码
*将来在使用python2定义字符串的时候,务必将所有字符串前加u
字母u在字符串前的含义为 让python2解释器用 unicode存储字符串数据
*python3默认编码为utf8,不存在乱码的问题
文件操作
简介
文件可以理解为
操作系统展示给用户从而让用户可以操作计算机硬盘的方式之一。
文件操作就是通过编写代码让电脑自动操作文件的读写
如何用代码操作文件
首先新建一个文件 a.txt
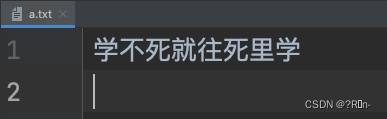
那么该如何写代码去读取这个文件呢
res = open('a.txt','r',encoding='utf8')
print(res.read()) #通过这个代码就可以读取目标文件

然后关闭文件
res.close()
打开代码内的具体参数为
open(文件路径,读写模式,字符编码)
这个open有两种方式使用
第一种
f = open() #用一个变量接收open方法
print(f.read()) #显示读取的文字
f.colse() #关闭
第二种
with open('a.txt', 'r', encoding='utf8') as f:
print(f.read()) #这个with语法的好处在于,当他的字代码运行结束后,会自动调用close()方法
以上f均为变量名,可以更换其他变量名
补充知识
可以通过在字符串前面添加'r'>>>resource 就可以取消字符串内的特殊含义
字符串前面加 f'{}' 格式化输出
u 让python2解释器用 unicode存储字符串数据
r 取消字符串内的特殊含义
'''如果编码是纯英文或数字 可以简写'''
res = 'John said no'
print(res.encode('utf8'))
print(b'John said no')















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









