







4.归并排序
4.1归并排序基本概念与思想:
概念:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
思想:
将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
4.2归并排序核心步骤:
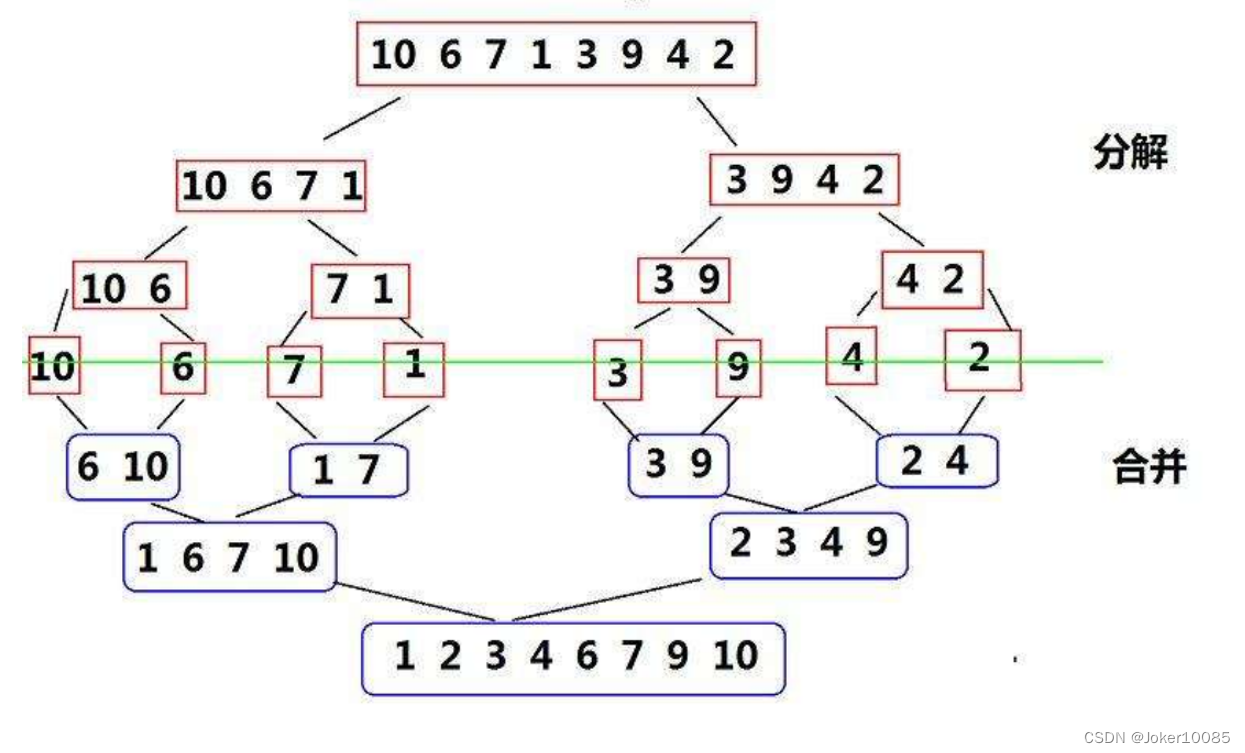
1.分解:
将待排序的数组从中间分成两半,递归地对这两半分别进行归并排序。
一直分解,直到每个子数组只包含一个元素,因为一个元素的数组自然是有序的。
2.解决:
当分解到最小子问题时,即每个子数组只有一个元素时,开始解决这些小问题。
解决的方式是合并(Merge)两个有序的子数组,从而得到一个更大的有序数组。
3.合并:
合并过程是归并排序的关键步骤。它将两个有序的子数组合并成一个有序的数组。
通常使用两个指针分别指向两个子数组的起始位置,然后比较两个指针所指向的元素,将较小的元素放入结果数组中,并移动该指针。
重复这个过程,直到一个子数组被完全合并到结果数组中,然后将另一个子数组的剩余元素直接复制到结果数组中。
4.3递归实现归并排序
在递归时要注意几个问题:
1. 在递归的时候需要保存两个区间的起始和终止位置,以便访问。
2. 当一个区间已经尾插完毕,那么直接将另外一个区间的数据依次尾插。
3. 两个区间的数据都尾插完毕至tmp数组时,需要将tmp数组的数据再次拷贝至原数组。
4. 在拷贝到原数组时需要注意尾插的哪一个区间就拷贝哪一个区间。
void _MergerSort(int* a, int begin, int end, int* tmp)
{
//递归截止条件
if (begin == end)
return;
//划分区间
int mid = (begin + end) / 2;
//[begin,mid] [mid+1,end]
//递归左右区间
_MergerSort(a, begin, mid, tmp);
_MergerSort(a, mid + 1, end, tmp);
//将区间保存
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
//取两个区间小的值尾插
//一个区间尾插完毕另一个区间直接尾插即可
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
//再将剩余数据依次尾插
//哪个区间还没有尾插就尾插哪一个
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
//再重新拷贝至原数组
//尾插的哪个区间就将哪个区间拷贝
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
//归并排序
void MergerSort(int* a, int n)
{
//先创建一个数组
int* tmp = (int*)malloc(sizeof(int) * n);
_MergerSort(a, 0, n - 1, tmp);
//释放
free(tmp);
}4.4非递归实现归并排序
4.4.1目的
由于递归代码在数据太多时可能会因为递归太深出现问题,所以我们也需要写出它们所对应的非递归版本的排序代码
4.4.2实现思想
我们可以先一个数据为一组,然后两两进行排序,然后将排序完的整体结果再重新拷贝至原数组,这样子就完成了一次排序。
然后再将排序完的结果两个数据为一组,然后两两排序,然后将排序完的数据再拷贝至原数组,这样子就完成了第二次的排序。
然后将数据四个分为一组,两两进行排序,再将排序完的数据拷贝至原数组。
直到每组的数据超过或者等于数据的总长度即不需要在进行排序。

4.4.3实现代码
void Merge_Sort_2_Non_Recursion2(int* arr,int right, int* tem)
{
int gap = 1;
while (1)
{
for (int left = 0; left <=right; left += gap * 2)
{
int begin1 = left;
int begin2 = left + gap;
int end1 = begin1 + (gap-1);
int end2 = begin2 + (gap - 1);
if (end1 > right|| begin2 >right)
{
break;
}
if (end2 > right)
{
end2 = right;
}
int k = 0;
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
{
tem[k++] = arr[begin1++];
}
else
{
tem[k++] = arr[begin2++];
}
}
while (begin1 <= end1)
{
tem[k++] = arr[begin1++];
}
while (begin2 <= end2)
{
tem[k++] = arr[begin2++];
}
memmove(arr + left, tem, (end2 - left + 1) * 4);
}
gap *= 2;
if (gap > (right + 1))
{
break;
}
}
}
void Merge_Sort_Non_Recursion(int* arr,int right)
{
int* tem = (int*)malloc(sizeof(int) * right);
if (tem == NULL)
{
perror("malloc error");
}
Merge_Sort_2_Non_Recursion2(arr,right, tem);
}5.计数排序
5.1计数排序的概念与思想
概念:
计数排序是一个非基于比较的排序算法,该算法于1954年由 Harold H. Seward 提出。它的优势在于在对一定范围内的整数排序时,它的复杂度为Ο(n+k)(其中k是整数的范围),快于任何比较排序算法。当然这是一种牺牲空间换取时间的做法,而且当O(k)>O(n*log(n))的时候其效率反而不如基于比较的排序(基于比较的排序的时间复杂度在理论上的下限是O(n*log(n)), 如归并排序,堆排序)
思想:
利用数组的索引是有序的,通过将序列中的元素作为索引,其个数作为值放入数组,遍历数组来排序。
5.2计数排序的核心步骤
1、从无序数组中取出最大值max,新建一个长度为max+1的数组。
2、遍历无序数组,取其中元素作为新建数组的索引,存在一个则新数组该索引所在的值自增。
3、遍历新数组,当存在不为0的元素,取该元素的索引放入最终数组,并且该元素自减,直到为0,返回最终数组。
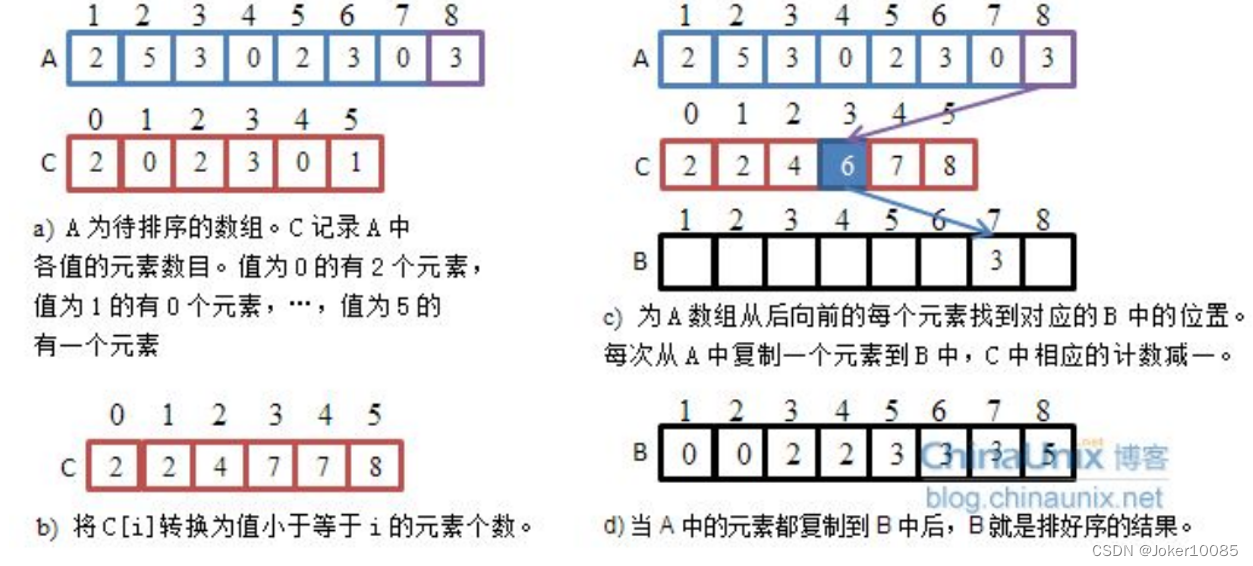
该方法存在的问题:
1、新建一个长度为max+1的数组会造成内存的浪费,比如元素为{400,405,410}则新建数组的长度为411,这会使前面的0 ~ 400索引没用,造成内存浪费。
2、其将元素作为键,将个数作为值放入新的数组中,但是如果存在相同的元素,我们只统计其个数,其顺序无法确定,是不稳定的。
解决方法:
1、问题1的解决方法是:取数组中的最大值max和最小值min,新建(max-min +1)长度的数组,数组的元素存放在新数组中的(arr[i]-min)索引处。
2、问题2的解决方法是:新建一个统计数组,其长度为(max-min +1),其索引存放的是新数组该索引之前元素的和,这个和表示的是该索引(该元素)在原数组中的排序顺序,就是排第几
5.3实现代码
void Count_Sort(int* a, int size)
{
int max = a[0];
int min = a[0];
int i;
for ( i = 0; i < size; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int range = max - min;
int* arr = NULL;
arr = (int*)malloc(sizeof(int) * (range + 1));
i = 0;
int j = 0;
for ( j = min; j <= max; j++)
{
arr[i] = j;
i++;
}
int* count = NULL;
count = (int*)malloc(sizeof(int) * (range + 1));
for (j = 0; j <i; j++)
{
count[j] = 0;
}
for (i = 0; i < size; i++)
{
if (a[i] == arr[a[i] - min])
{
count[a[i] - min]++;
}
}
int k = 0;
for (i = 0; i <=range; i++)
{
for (j = 0; j < count[i]; j++)
{
a[k]=arr[i];
k++;
}
}
}5.4、计数排序的总结
计数排序是非比较排序,时间复杂度是O(n+k),空间复杂度是O(k),是稳定算法。(n表示的是数组的个数,k表示的max-min+1的大小)
时间复杂度是O(n+k):通过上面的代码可知最终的计数算法花费的时间是3n+k,则时间复杂度是O(n+k)。
空间复杂度是O(k):如果出去最后的返回数组,则空间复杂度是2k,则空间复杂度是O(k)
稳定算法:由于统计数组可以知道该索引在原数组中排第几位,相同的元素其在原数组中排列在后面,其从原数组的后面遍历,其在最终数组中的索引也在后面,所以相同的元素其相对位置不会改变
根据特性,计数排序适合范围集中且范围不大的整型数组排序















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









