







大家好,我是纪宁。
这篇文章介绍归并排序和计数排序。归并排序和计数排序是时间效率非常高的两款排序,但它们却也都有着各自的优缺点,因此使用场景也各不相同。
归并排序
归并排序(Merge Sort)是一种 分治 策略的排序算法。其基本思想是将待排序的序列分成两个有序的子序列,然后再将这两个子序列合并成一个有序的序列,从而达到排序的目的。
简单来说,就是数据多的序列排序比较复杂,那就将它分为多个有序的小序列,再进行合并,将两个有序表合并成一个有序表,称为二路归并。
递归排序无论递归还是非递归,都要开O(N)大小个空间,也是它的一个缺点,所以一般处理在磁盘中的外排序问题。
时间复杂度:O(N*logN)
磁盘中的外排序问题
磁盘中的外排序问题是指
需要对大量数据进行排序,但内存无法一次性容纳所有数据的情况。这时,需要将数据分为多个部分,每次读取一部分数据到内存中进行排序,最后将所有有序的部分进行合并,从而得到排序后的完整数据。外排序通常包括以下步骤:
将原始数据分为多个部分(通常称为“文件”),每个文件大小不超过内存容量。
对每个文件分别进行内部排序,通常采用快速排序、归并排序等算法。
将所有有序的文件进行归并排序,得到最终的有序数据。
在具体实现时,需要考虑数据的访问方式以及磁盘I/O的效率。通常采用多路归并和分区排序等技术来优化磁盘I/O的效率,并尽可能减少归并阶段的文件数量,以提高效率。
外排序问题通常出现在大数据处理、数据库系统等领域中,是处理大规模数据时不可避免的问题。
归并排序递归实现

具体过程如下:
- 将待排序序列二分为左右两个子序列,递归地对左右子序列进行归并排序;
- 将排好序的左右子序列合并成一个有序序列,具体步骤是将左右两个子序列的首元素进行比较,取较小的元素放入临时数组中,直到其中一个子序列的元素全部被取完,然后将剩余的元素依次放入临时数组中;
- 重复步骤2,直到左右两个子序列都放完,此时临时数组中就是排好序的序列。
先分解再合并
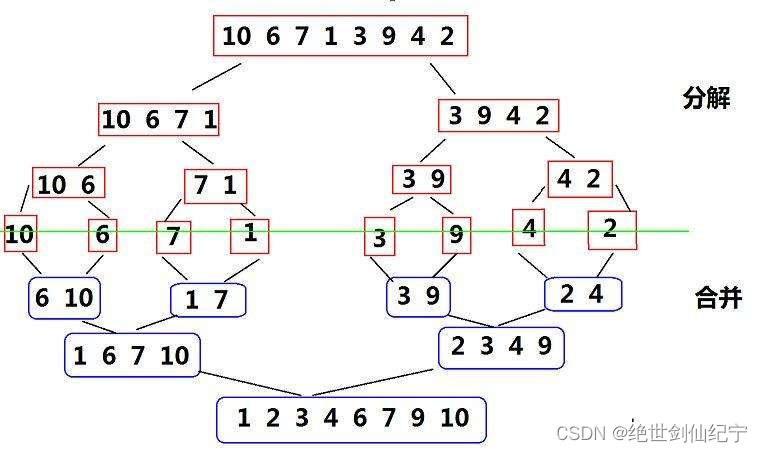
代码实现
void _MergeSortPart(int* a, int* tmp, int begin, int end)
{
if (begin >= end)
{
return;
}
int midi = (begin + end) / 2;
_MergeSortPart(a, tmp, begin, midi);
_MergeSortPart(a, tmp, midi+1, end);
int begin1 = begin, end1 = midi;
int begin2 = midi+1, end2 = end;
int index = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] > a[begin2])
{
tmp[index++] = a[begin2++];
}
else
{
tmp[index++] = a[begin1++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
memcpy(a+begin,tmp+begin,sizeof(int)*(end-begin+1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
}
_MergeSortPart(a, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
}
代码解释
归并排序使用递归实现,可以在递归函数开头设置一个条件 begin >= end,当这个条件不满足时,说明递归的每组只有一个数据了,返回后这两个只有一个数的区间进行归并后,拷贝回原数组,再次返回。这时候,就进入了右边的含有两个数的区间,再进行递归,不满足继续递归的条件时,就说明这个偏右的区间也都只有一个数据了,再返回,返回后偏右的区间中的这两个数进行归并,归并后再拷贝回原数组…如此往复,直到将所有的数据全部归并结束并拷贝回原数组。
这个过程比较复杂,大家就可以尝试使用 递归展开图 去理解。
归并排序非递归实现
非递归实现的思路就是直接在数组内部实现归并,定义一个变量 gap,表示每组要归并的元素个数,用 for 循环来控制归并的组数和位置,i 每次跳过 2*gap 个长度,相当于跳过了一组,即开始下一组的递归。这个层次所有组完成递归后,将 gap 变为原来的2倍,开始下一层次的递归,这一次层次每组的数据个数是原来的 2 倍…一直循环,直到 gap 大于数据个数。
但这里有个易错点:end1、begin2、end2可能出现的越界问题。首先,begin1 不可能越界,因为begin1等于i ,越界了就进不了循环;end1和begin2 都有越界的可能,因此判断 begin2 之后,如果越界,就直接停止这层循环(因为这一操作是对本组和一下组进行归并,end2 越界,说明绝对没有第二组,那也就不用进行递归); end2 如果越界的话,说明是有第二组,但第二组数据没有第一组多的情况,直接将end2 赋值为 end 即可解决问题!
void _MergeSortNonr(int* a, int* tmp, int begin, int end)
{
int gap = 1;//归并每组的元素个数
while (gap <= end)
{
for (int i = 0; i <= end; i += 2 * gap)
{
int index = 0;
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
if (begin2 > end)
{
break;
}
if (end2 > end)
{
end2 = end;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] > a[begin2])
{
tmp[index++] = a[begin2++];
}
else
{
tmp[index++] = a[begin1++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
memcpy(a+i, tmp+i, sizeof(int) * (end2 - i - 1));
}
gap *= 2;
}
}
计数排序
计数排序是一种非比较排序算法,它的原理是对一组数据进行计数,然后根据计数结果将数据排序。具体的操作过程如下:
-
找出待排序数组中的最大值max和最小值min。
-
创建一个大小为
max - min + 1的计数数组 count,用于存储每个元素出现的次数。 -
遍历待排序数组,统计每个元素出现的次数,并将计数结果存入 count 数组中。(数组元素自加的下标是在这个数组中以 数据n-min 为下标的位置 )
-
数组 count 元素下标 + min 就是原始数据的值,这个下标对应存储的数据,就是这个原始数据在原数组中出现的次数。
-
遍历 count 数组,遇到数据不为0的,就利用循环将原始数据(下标+min)拷贝至原数组,排序结束。
代码实现
void CountSort(int* a, int n)//计数排序
{
int max = a[0], min = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] > max)
max = a[i];
if (a[i] < min)
min = a[i];
}
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int) * range);
memset(count, 0, sizeof(int) * range);
for (int j = 0; j < n; j++)
{
count[a[j]-min]++;
}
int z = 0;
for (int j = 0; j < range; j++)
{
while (count[j]--)
{
a[z++] = j + min;
}
}
free(count);
}
时间复杂度:O(N+range)
空间复杂度:O(range)
计数排序缺点主要是空间复杂度比价严格
计数排序的应用场景包括但不限于:
对于元素取值范围比较小的数据集,如
成绩排名、年龄分组等的排名,在这种场景下计数排序往往有奇效!
作为其他排序算法的辅助算法,如基数排序的一部分。
对于存在重复元素的数据集,计数排序可以简单有效地去除重复项。















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









